本文来源公众号“天才程序员周弈帆”,仅用于学术分享,侵权删,干货满满。
原文链接:Stable Diffusion 解读(二):论文精读
【小小题外话】端午安康!
在上一篇文章天才程序员周弈帆 | Stable Diffusion 解读(一):回顾早期工作-CSDN博客中,我们梳理了基于自编码器(AE)的图像生成模型的发展脉络,并引出了Stable Diffusion的核心思想。简单来说,Stable Diffusion是一个两阶段的图像生成模型,它先用一个AE压缩图像,再在压缩图像所在的隐空间上用DDPM生成图像。在这篇文章中,我们来精读Stable Diffusion的论文:High-Resolution Image Synthesis with Latent Diffusion Models。
注意:如果你从未学习过扩散模型,Stable Diffusion并不是你应该的读的第一篇论文。请参照我的 上一篇文章天才程序员周弈帆 | Stable Diffusion 解读(一):回顾早期工作早期工作总结,至少在学会了DDPM后再来学习Stable Diffusion。
1 摘要与引言
论文摘要的大意如下:扩散模型的生成效果很好,但是,在像素空间上训练和推理扩散模型的计算开销都很大。为了在不降低质量与易用性的前提下用较少的计算资源训练扩散模型,我们在一个预训练过的自编码器的隐空间上使用扩散模型。相较以往的工作,在这种表示下训练扩散模型首次在减少计算复杂度和维持图像细节间达到几近最优的平衡点,极大地提升了视觉保真度。通过向模型架构中引入交叉注意力层,我们把扩散模型变成了强大而灵活的带约束图像生成器,它支持常见的约束,如文字、边界框,且能够以纯卷积方式实现高分辨率的图像合成。我们的隐扩散模型(latent diffusion model, LDM) 在使用比像素扩散模型少得多的计算资源的前提下,在各项图像合成任务上取得最优成果或顶尖成果。
整理一下。论文提出了一种叫LDM的图像生成模型。论文想解决的问题是减少像素空间扩散模型的运算开销。为此,LDM借助了VQVAE「先压缩、再生成」的想法,把扩散模型用在AE的隐空间上,在几乎不降低生成质量的前提下减少了计算量。另外,LDM还支持带约束图像合成及纯卷积图像超分辨率。
在上一篇回顾LDM早期工作的文章天才程序员周弈帆 | Stable Diffusion 解读(一):回顾早期工作中,我们已经理解了LDM想解决的问题及解决问题的思路。因此,在读完摘要后,我们接下来读文章时只需要关注LDM的两个创新点:
-
LDM的AE是怎么设计以达到压缩比例与质量的平衡的。
-
LDM怎么实现带约束的图像合成。
引言基本是摘要的扩写。首先,引言大致介绍了图像合成任务的背景,提及了扩散模型近期的突出表现。随后,引言介绍了本文想解决的主要问题:扩散模型的训练和推理太耗时了,需要在不降低效果的前提下减少扩散模型的运算量。最后,引言揭示了本工作的解决方法:使用类似VQGAN的两阶段图像生成方法。
引言的前两部分没有什么关键信息,而最后一部分介绍了本工作改进扩散模型的动机,值得一读。如下图所示,DDPM的论文展示了从不同去噪时刻的同一个噪声图像开始的不同生成结果,比如x_750指从时刻t=750的去噪图像开始,多次以不同随机数执行DDPM的反向过程,生成的多幅图像。LDM作者认为,DDPM的这一实验表明,扩散模型的图像生成分两个阶段:先是对语义进行压缩,再是对图像的感知细节压缩。正因此,随机对早期的噪声图像去噪,生成图像的内容会更多样;而随机对后期的噪声图像去噪,生成图像只是在细节上有所不同。LDM的作者认为,扩散模型的大量计算都浪费在了生成整幅图像的细节上,不如只让扩散模型描述比较关键的语义压缩部分,而让自编码器(AE)负责感知细节压缩部分。

引言在结尾总结了本工作的贡献:
-
相比之前按序列处理图像的纯Transformer的方法,扩散模型能更好地处理二维数据。因此,LDM生成隐空间图像时不需要那么重的压缩比例(比如DIV2K数据集上,LDM只需要将图像下采样4倍,而之前的纯Transformer方法要下采样8倍或16倍),图像在压缩时能有更高的保真度,整套方法能更高效地生成高分辨率图像。
-
在大幅降低计算开销的前提下在多项图像生成任务上取得了顶尖成果。
-
相比于之前同时训练图像压缩模型和图像生成模型的方法,该方法分步训练两个模型,训练起来更加简单。
-
对于有着稠密约束的任务(如超分辨率、补全、语义生成),该方法的模型能换成一个纯卷积版本的,且能生成边长为1024的图像。
-
该工作设计了一种通用的约束机制,该机制基于交叉注意力,支持多模态训练。作者训练了多种带约束的模型。
-
作者把工作开源了,并提供了预训练模型。
我们来整理一下这些贡献。读论文时,可以忽略第6条。第2条是成果,与方法设计无关。第1、3条主要描述了提出两阶段图像生成建模方法的贡献。第4条是把方法拓展到稠密约束任务的贡献。第5条是提出了新约束机制的贡献。所以,在学习论文的方法时,我们还是主要关注摘要里就提过的那两个创新点。在读完引言后,我们可以把阅读目标再细化一下:
-
LDM的AE是怎么设计以达到压缩比例与质量的平衡的。与纯基于Transformer的VQGAN相比,它有什么不同。
-
LDM怎么用交叉注意力机制实现带约束的图像生成。
2 相关工作
作者主要从两个角度回顾了早期工作:不同架构的图像生成模型与两阶段的图像合成方法。其回顾逻辑与本系列的第一篇文章天才程序员周弈帆 | Stable Diffusion 解读(一):回顾早期工作类似,在此就不过多介绍了。除了介绍早期工作外,作者重申了引言中的对比结果,强调了LDM相对于扩散模型的创新和相对于两阶段图像生成模型的创新。
3 方法
在方法章节中,作者先是大致介绍了使用LDM这种两阶段图像生成架构的优点,再分三部分详细介绍了论文的实现细节:图像压缩AE的实现、LDM的实现、约束的实现。开头的介绍和AE的实现相对比较重要,我们放在一起详细阅读;相对于DDPM,LDM几乎没有做任何修改,只是把要拟合的图片从真实图片换成了压缩图片,这一部分我们会快速浏览一遍;而添加约束的方法有所创新,我们会详细阅读一遍。
3.1 AE与两阶段图像生成模型
我们来先读3.1节,看一看AE的具体实现方法,再回头读第3节开头介绍的两阶段图像生成模型的优点。
LDM配套的图像压缩模型(论文中称之为"感知压缩模型")和VQGAN几乎完全一样。该压缩模型的原型是一个AE。普通的AE会用原图像和重建图像的重建误差(L1误差或者L2误差)来训练。在普通的AE的基础上,该压缩模型参考了GAN的误差设置方法,使用感知误差代替重建误差,并添加了基于patch的对抗误差。
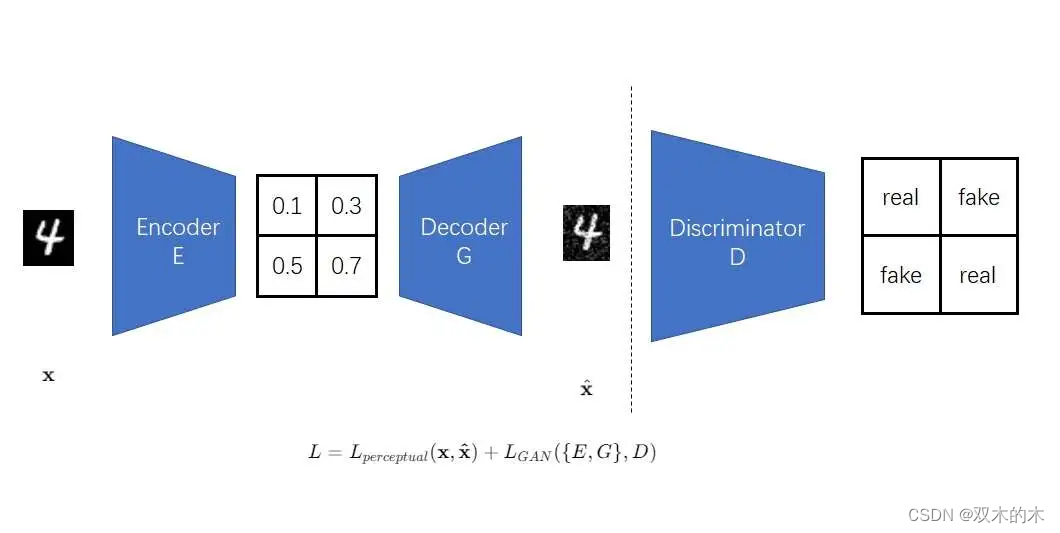
但该图像压缩模型的输出与VQGAN有所不同。我们先回忆一下VQGAN的原理。VQGAN的输出会接到Transformer里,Transformer的输入必须是离散的。因此,VQGAN必须要额外完成两件事:1)让连续输出变成离散输出;2)用正则化方法防止过拟合。为此,VQGAN使用了VQVAE里的向量离散化操作,该操作能同时完成这两件事。
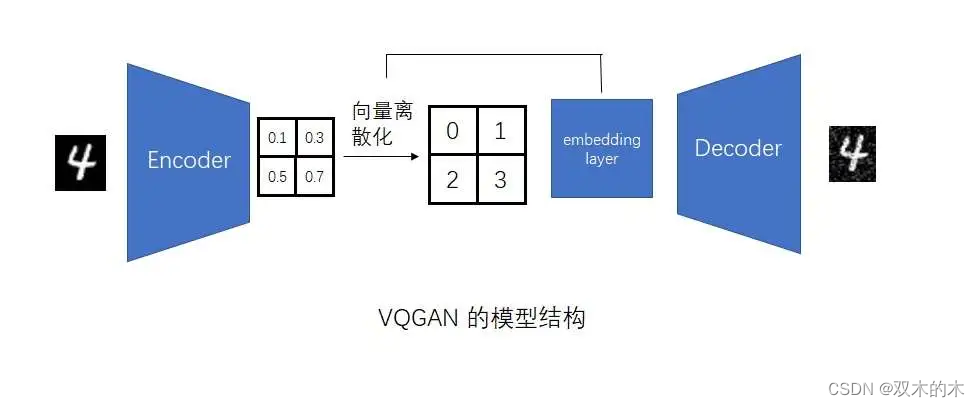
而LDM的压缩模型的输出会接入一个扩散模型里,扩散模型的输入是连续的。因此,LDM的压缩模型只需要额外完成使用正则化方法这一件事。该压缩模型不必像VQGAN一样非得用向量离散化来完成正则化。如我们在第一篇文章中讨论的,作者在LDM的压缩模型中使用了两种正则化方法:VQ正则化与KL正则化。前者来自于VQVAE,后者来自于VAE。
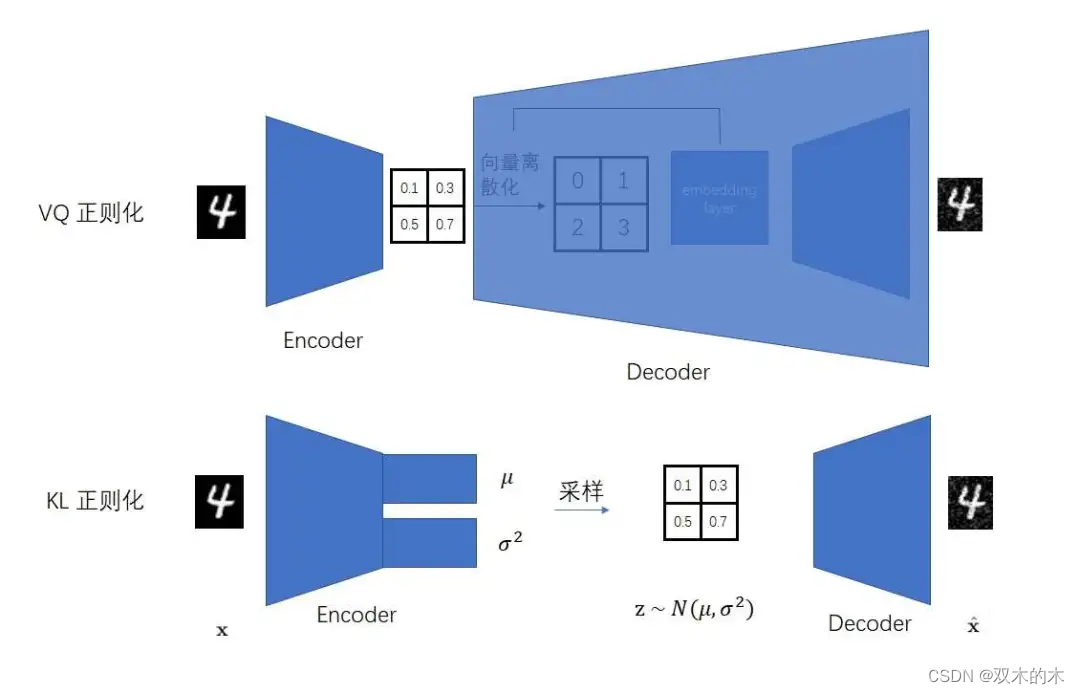
该压缩模型相较VQGAN有一项明显的优势。VQGAN的Transformer只能按一维序列来处理图像(通过把二维图像reshape成一维),且只能处理较小的压缩图像(16 x 16)。而本身用于二维图像生成的LDM能更好地利用二维信息,因此可以处理更大的压缩图像(64 x 64)。这样,LDM的压缩模型的压缩程度不必那么重,其保真度会比VQGAN高。
看完了3.1节,我们来回头看第3节开头介绍了LDM的三项优点:1)通过规避在高维图像空间上训练扩散模型,作者开发出了一个因在低维空间上采样而计算效率大幅提升的扩散模型;2)作者发掘了扩散模型中来自U-Net架构的归纳偏置(inductive bias),使得它们能高效地处理有空间结构的数据(比如二维图像),避免像之前基于Transformer的方法一样使用激进、有损质量的压缩比例;3)本工作的压缩模型是通用的,它的隐空间能用来训练多种图像生成模型。第一个优点是相对于DDPM。第二个是优点是相对于使用Transformer的VQGAN,我们在上一段已经分析过了。第三个优点是相对于之前那些换一个任务就需要换一个压缩模型的两阶段图像生成模型。
归纳偏置可以简单理解为某个学习算法对一类数据的优势。比如CNN结构适合处理图像数据。
3.2 隐扩散模型(LDM)

3.3 约束机制

根据论文中实验的设计,对于作用于全局的约束,如文本描述,使用交叉注意力较好;对于有空间信息的约束,如语义分割图片,则用拼接的方式较好。
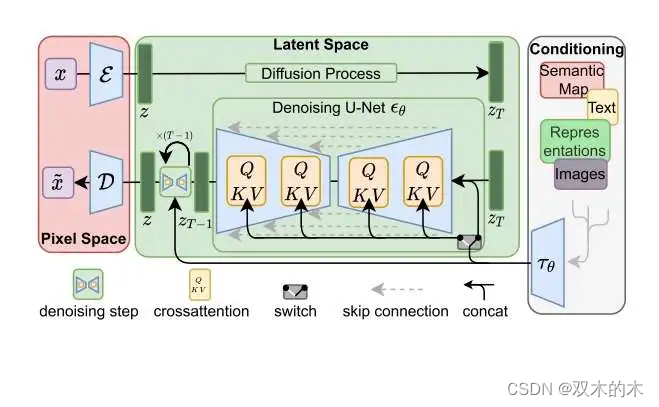
4 实验
在这一章里,作者按照介绍方法的顺序,依次探究了图像压缩模型、无约束图像生成、带约束图像合成的实验结果。我们主要关心前两部分的实验结果。
4.1 感知压缩程度的折衷
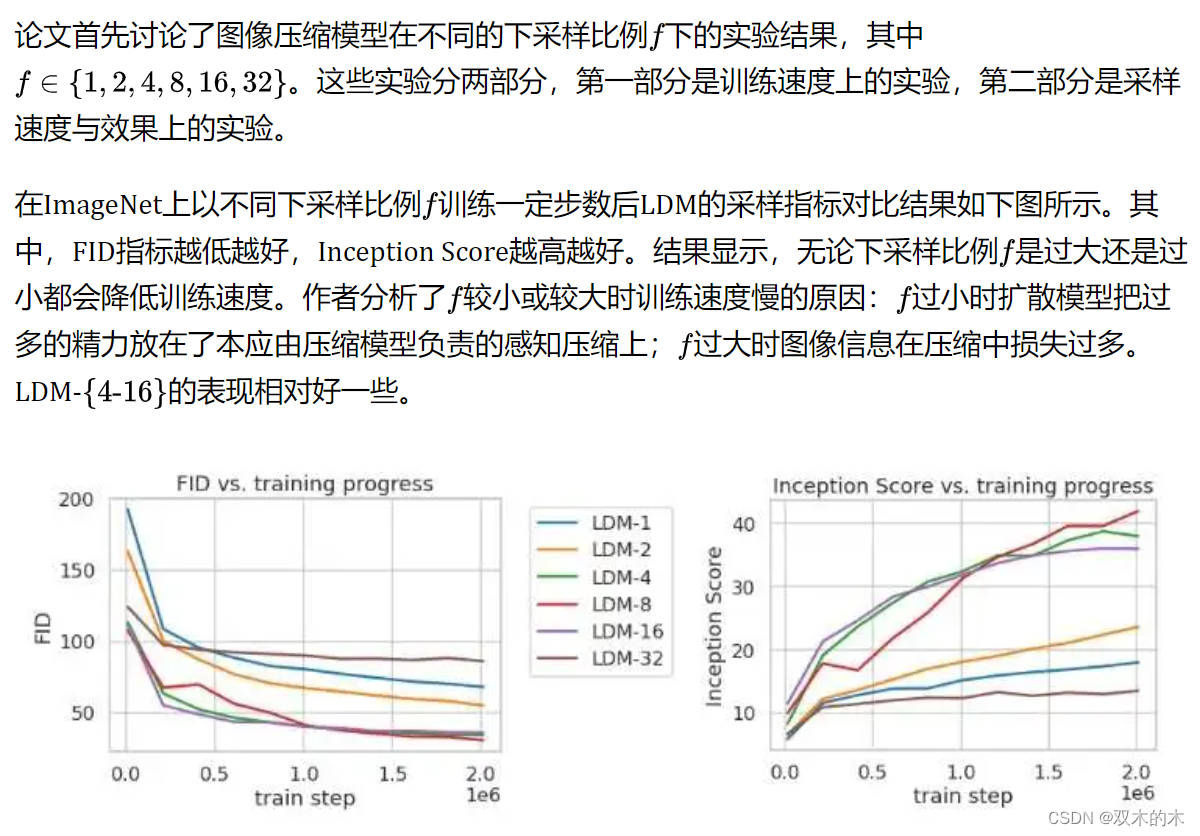
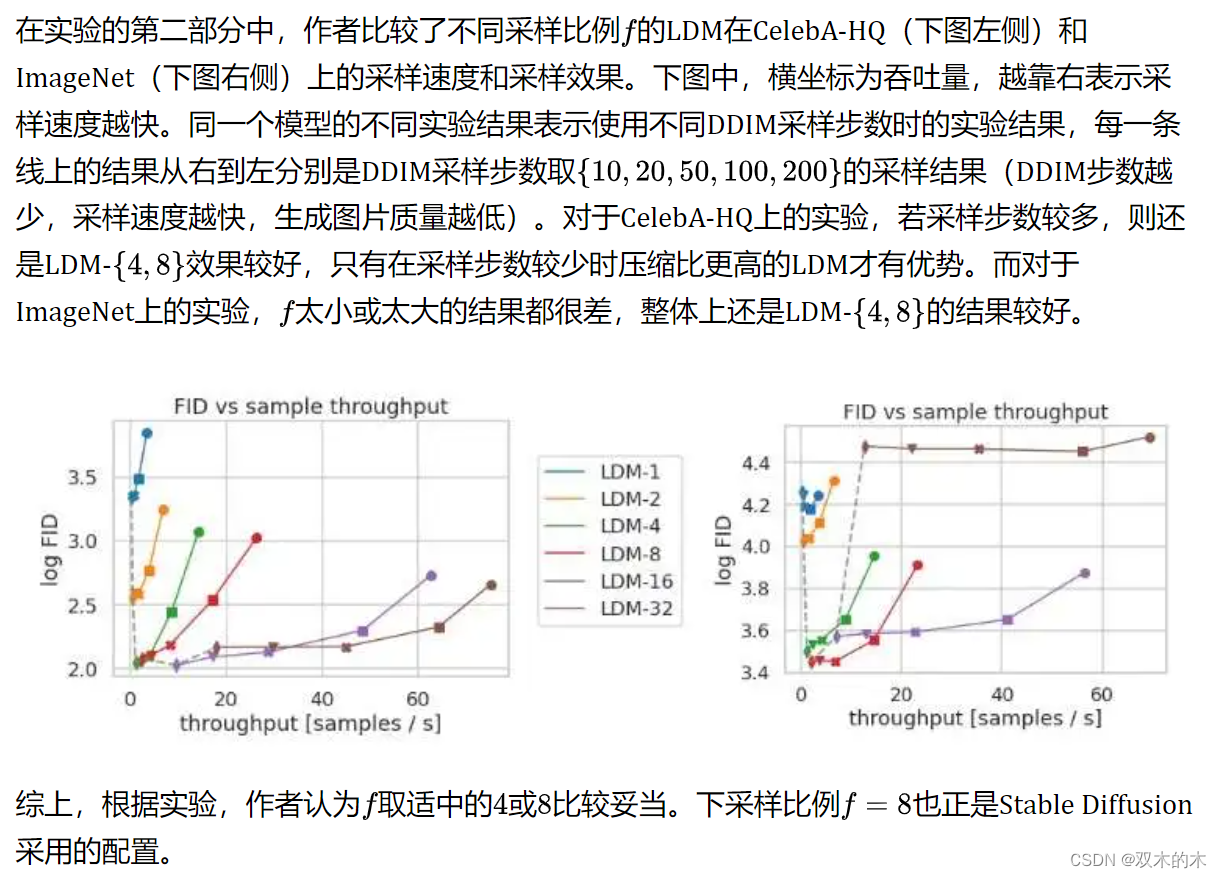
4.2 图像生成效果
在这一节中,作者在几个常见的数据集上对比了LDM与其他模型的无约束图像生成效果。作者主要比较了两类指标:表示采样质量的FID和表示数据分布覆盖率的精确率及召回率(Precision-and-Recall)。
在介绍具体结果之前,先对这个不太常见的精确率及召回率指标做一个解释。精确率及召回率常用于分类等有确定答案的任务中,分别表示所有被分类为正的样本中有多少是分对了的、所有真值为正的样本中有多少是被成功分类成正的。而无约束图像生成中的精确率及召回率的解释可以参加论文Improved Precision and Recall Metric for Assessing Generative Models。如下图所示,设真实分布为蓝色,生成模型的分布为红色,则红色样本落在蓝色分布的比例为精确率,蓝色样本落在红色分布的比例为召回率。简单来说,精确率能描述采样质量,召回率能描述生成分布与真实分布的覆盖情况。
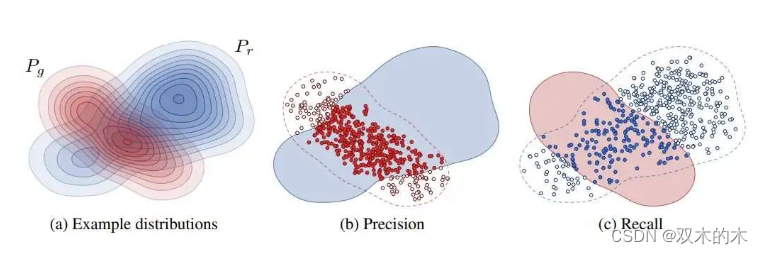
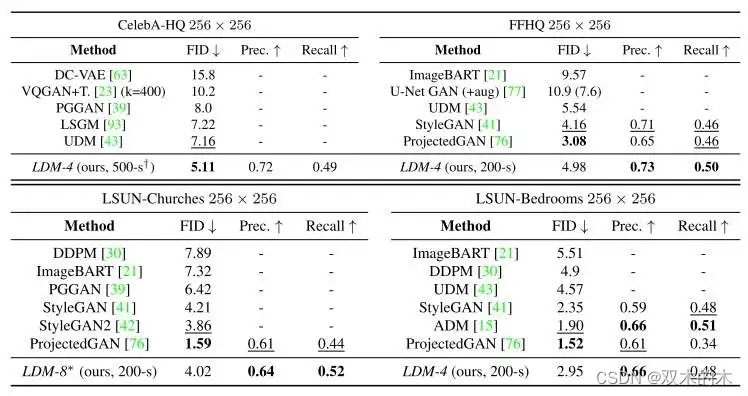
接下来,我们回头来看论文展示的无约束图像生成对比结果,如下图所示。整体上看,LDM的表现还不错。虽然在FID指标上无法超过GAN或其他扩散模型,但是在精确率和召回率上还是颇具优势。唯一没有被LDM战胜的是LSUN-Bedrooms上的ADM模型,但作者提到,相比ADM,LDM只用了一半的参数,且只需四分之一的训练资源。
4.3 带约束图像合成
这一节里,作者展示了LDM的文生图能力。论文中的LDM用了一个从头训练的基于Transformer的文本编码器,与后续使用CLIP的Stable Diffusion差别较大。这一部分的结果没那么重要,大致看一看就好。
本文的文生图模型是一个在LAION-400M数据集上训练的KL约束LDM。它的文本编码器是一个Transformer,编码后的特征会以交叉注意力的形式传入LDM。采样时,LDM使用了Classifier-Free Guidance。
Classifier-Free Guidance可以让输出图片更符合文本约束。这是一种适用于所有扩散模型的采样策略,并非要和LDM绑定,感兴趣可以去阅读相关论文。
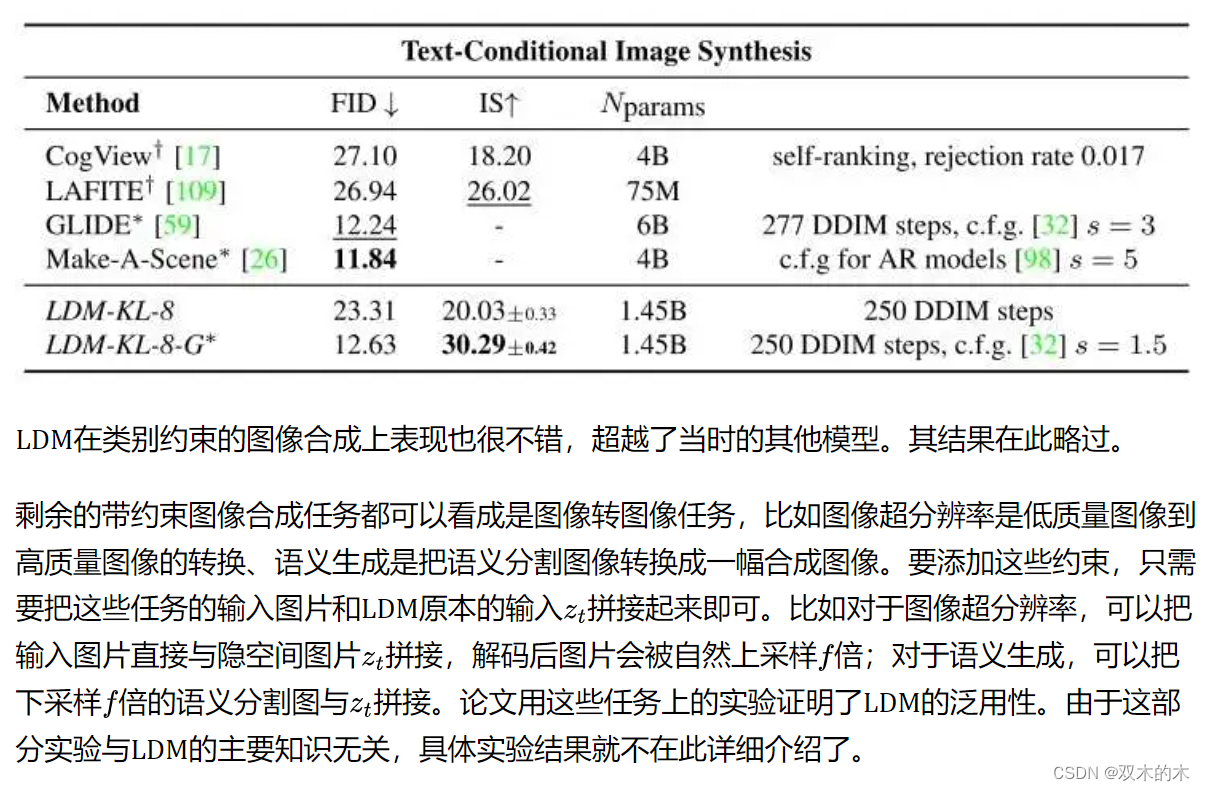
LDM与其他模型的文生图效果对比如下图所示。虽然这个版本的LDM并没有显著优于其他模型,但它的参数量是最少的。
5 总结
论文末尾探讨了LDM的两大不足。首先,尽管LDM的计算需求比其他像素空间上的扩散模型要少得多,但受制于扩散模型本身的串行采样,它的采样速度还是比GAN慢上许多。其次,LDM使用了一个自编码器来压缩图像,重建图像带来的精度损失会成为某些需要精准像素值的任务的性能瓶颈。
论文最后再次总结了此方法的贡献。LDM的主要贡献其实只有两点:在不损失效果的情况下用两阶段的图像生成方法大幅提升了训练和采样效率、借助交叉注意力实现了各任务通用的约束机制。这两个贡献总结得非常精准。之后的Stable Diffusion之所以大受欢迎,第一就是因为它采样所需的计算资源不多,大众能使用消费级显卡完成图像生成,第二就是因为它强大的文字转图片生成效果。
我们再从知识学习的角度总结一下LDM。LDM的核心知识是DDPM和VQGAN。如果你能看懂之前这两篇论文,那你一下子就能明白LDM是的核心思想是什么,看论文时只需要精读交叉注意力约束机制那一段即可,其他实验内容在现在看来已经价值不大了。由于近两年有大量基于Stable Diffusion开发的工作,相比论文,阅读源代码的重要性会大很多。我们会在下一篇文章里详细学习Stable Diffusion的官方源码和最常用的Stable Diffusion第三方实现——Diffusers框架。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。








![[spring] Spring MVC Thymeleaf(上)](https://img-blog.csdnimg.cn/direct/0f74df51be32439488b1a78fcbe5108a.png)

