基于pytorch_lightning测试resnet18不同激活方式在CIFAR10数据集上的精度
- 一.曲线
- 1.train_acc
- 2.val_acc
- 3.train_loss
- 4.lr
- 二.代码
本文介绍了如何基于pytorch_lightning测试resnet18不同激活方式在CIFAR10数据集上的精度
特别说明:
1.NoActive:没有任何激活函数
2.SparseActivation:只保留topk的激活,其余清零,topk通过训练得到[初衷是想让激活变得稀疏]
3.SelectiveActive:通过训练得到使用的激活函数
可参考的代码片段:
1.pytorch_lightning 如何使用
2.pytorch如何替换激活函数
3.如何对自定义权值做衰减
一.曲线
1.train_acc
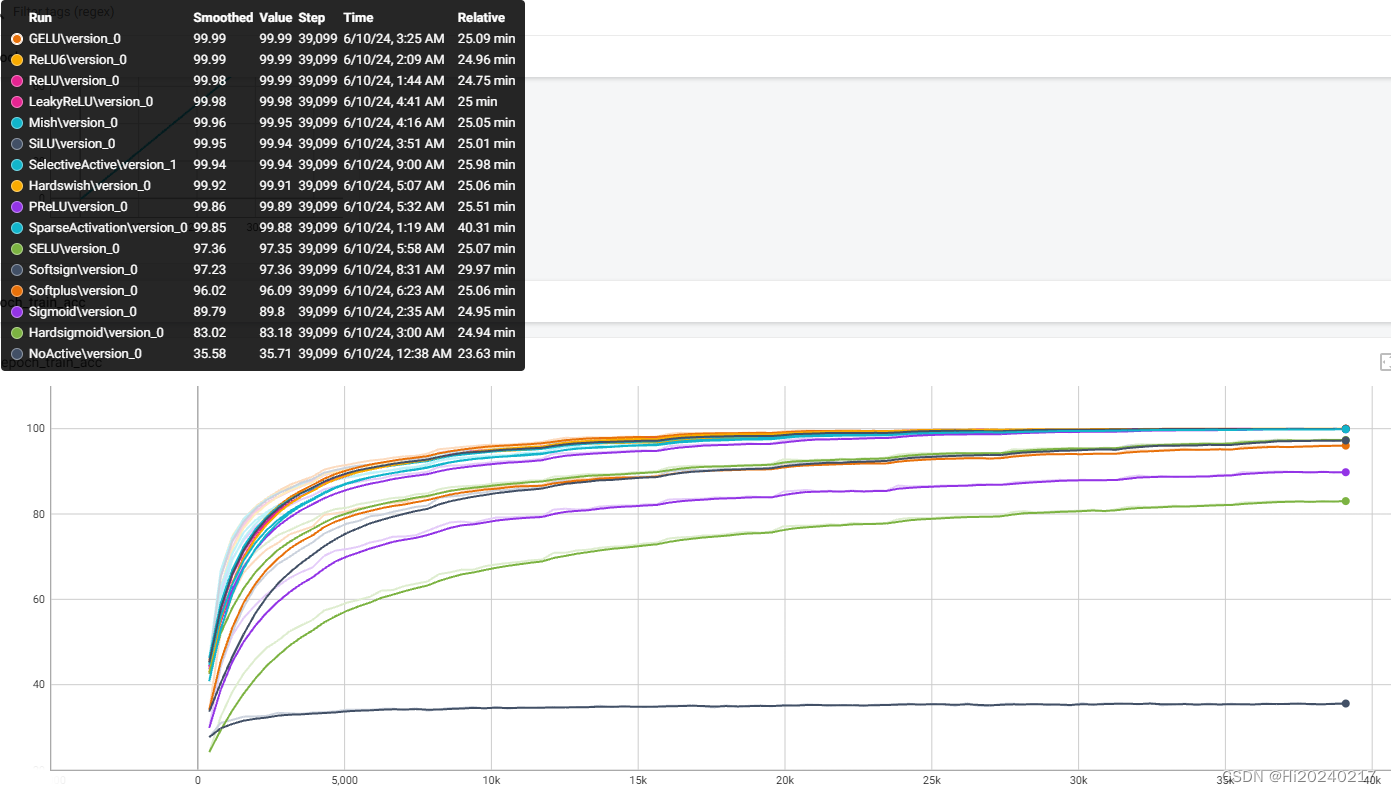
2.val_acc
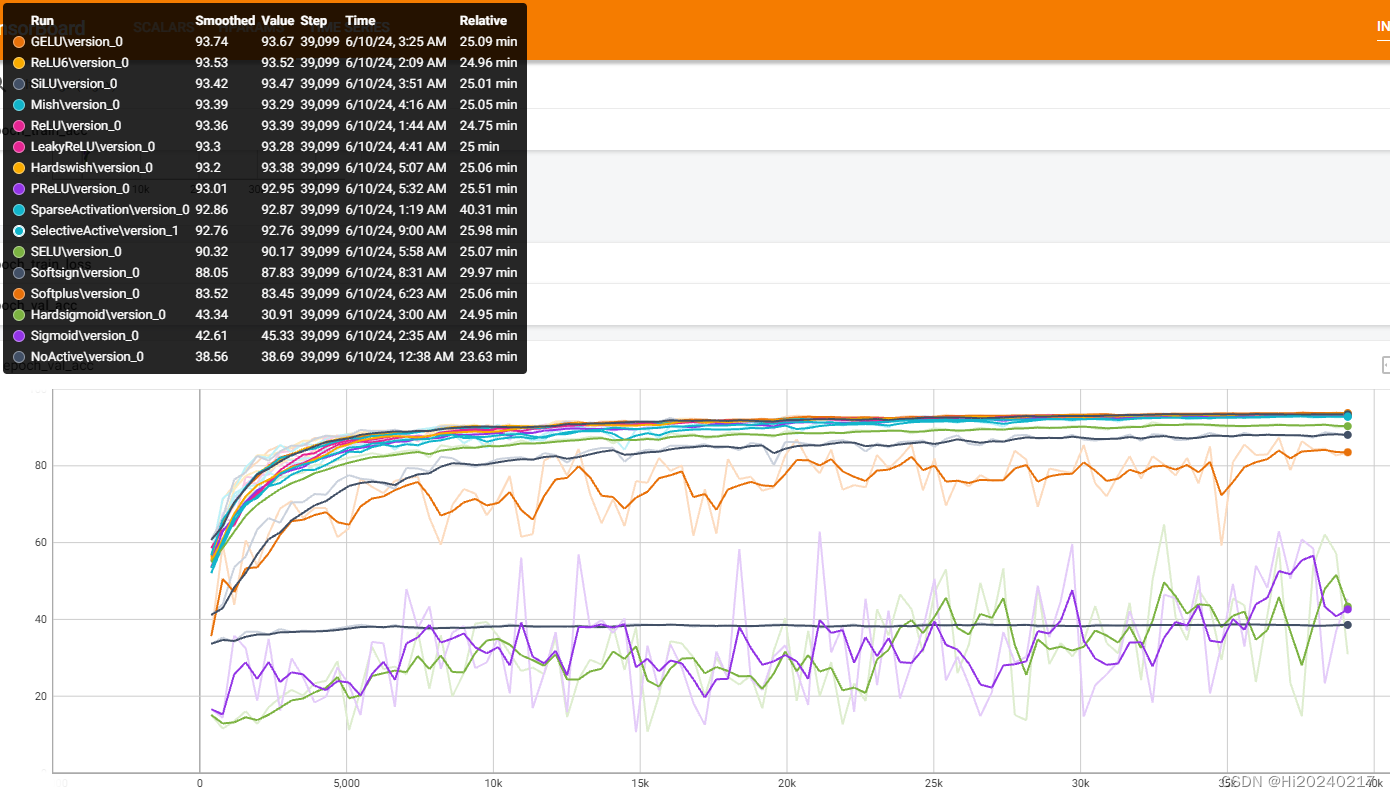
3.train_loss

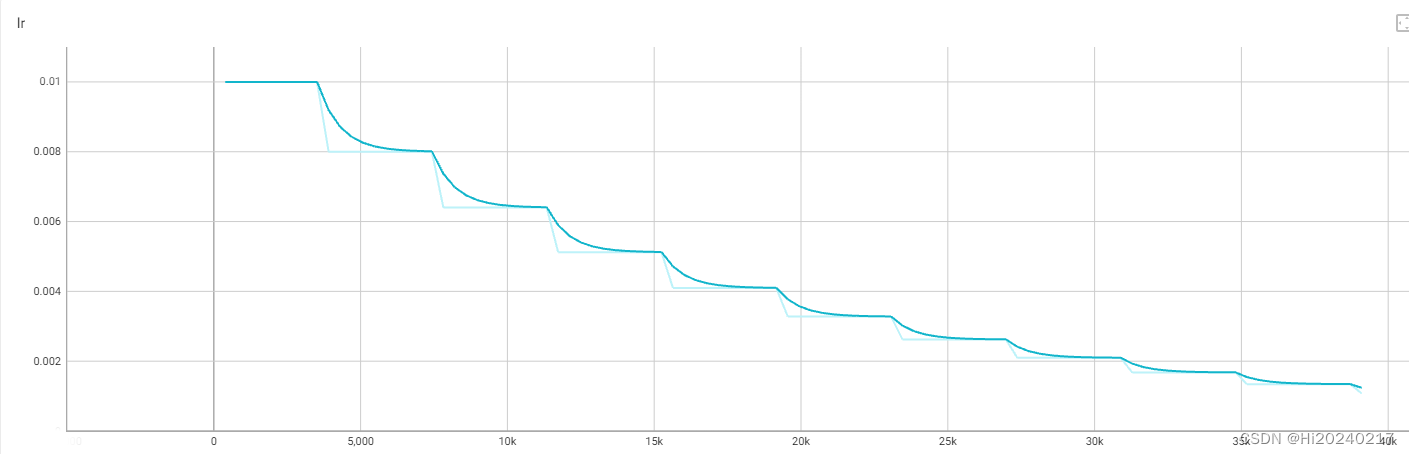
4.lr
二.代码
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import CosineAnnealingWarmRestarts
import pytorch_lightning as pl
from torch.utils.data import DataLoader
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
import os
import numpy as np
from pytorch_lightning.loggers import TensorBoardLogger
#torch.set_float32_matmul_precision('medium')
class ResidualBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
self.act=nn.ReLU()
def forward(self, x):
out = self.left(x)
out += self.shortcut(x)
out = self.act(out)
return out
class ResNet(nn.Module):
def __init__(self, ResidualBlock, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2)
self.fc = nn.Linear(512, num_classes)
self.dropout=nn.Dropout(0.5)
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.dropout(out)
out = self.fc(out)
return out
class SparseActivation(nn.Module):
act_array=[x.cuda() for x in [nn.ReLU(),
nn.ReLU6(),
nn.Sigmoid(),
nn.Hardsigmoid(),
nn.GELU(),
nn.SiLU(),
nn.Mish(),
nn.LeakyReLU(),
nn.Hardswish(),
nn.PReLU(),
nn.SELU(),
nn.Softplus(),
nn.Softsign()]]
def __init__(self,args):
super(SparseActivation, self).__init__()
self.input_weights = nn.Parameter(torch.randn(1)).cuda()
self.act=SparseActivation.act_array
self.act_weights = nn.Parameter(torch.randn(len(self.act))).cuda()
self.args=args
def forward(self, x):
index=self.args.act
if index>=0:
index=index-1
if index==-1:
prob=F.softmax(self.act_weights,dim=0)
_, index = torch.topk(prob, 1, dim=0)
x=self.act[index](x)
if self.args.sparse==0:
return x
input=x.flatten(1)
input_weights = torch.sigmoid(self.input_weights)
topk = input.size(1)*input_weights
topk=topk.int()
topk_vals, topk_indices = torch.topk(input, topk, dim=1)
mask = torch.zeros_like(input).scatter(1, topk_indices, topk_vals)
return mask.reshape(x.shape)
class LitNet(pl.LightningModule):
def __init__(self, args):
super(LitNet, self).__init__()
self.save_hyperparameters()
self.args = args
self.resnet18 = ResNet(ResidualBlock)
self.criterion = nn.CrossEntropyLoss()
self.ws=[]
self.replace_activation(self.resnet18,nn.ReLU, SparseActivation,self.ws)
def replace_activation(self,module, old_activation, new_activation,ws):
for name, child in module.named_children():
if isinstance(child, old_activation):
op=new_activation(self.args)
ws.append(op.input_weights)
setattr(module, name,op)
else:
self.replace_activation(child, old_activation, new_activation,ws)
def forward(self, x):
return self.resnet18(x)
def on_train_epoch_start(self):
self.train_total_loss=[]
self.train_total_acc=[]
def on_train_epoch_end(self):
self.log('epoch_train_loss', np.mean(self.train_total_loss))
self.log('epoch_train_acc', np.mean(self.train_total_acc))
self.log("lr",self.optimizer.state_dict()['param_groups'][0]['lr'])
def training_step(self, batch, batch_idx):
data, target = batch
output = self(data)
loss = self.criterion(output, target)
l2_reg = torch.tensor(0.).cuda()
l2_lambda=0.001
for param in self.ws:
l2_reg += torch.norm(param+4)
loss += l2_lambda * l2_reg
self.log('iter_train_loss', loss)
_, predicted = torch.max(output.data, 1)
correct = (predicted == target).sum()
acc = 100. * correct / target.size(0)
self.train_total_loss.append(loss.item())
self.train_total_acc.append(acc.item())
return loss
def on_validation_epoch_start(self):
self.val_total_loss=[]
self.val_total_acc=[]
def on_validation_epoch_end(self):
self.log('epoch_val_loss', np.mean(self.val_total_loss))
self.log('epoch_val_acc', np.mean(self.val_total_acc))
def validation_step(self, batch, batch_idx):
data, target = batch
output = self(data)
_, predicted = torch.max(output.data, 1)
correct = (predicted == target).sum()
acc = 100. * correct / target.size(0)
loss = self.criterion(output, target)
self.val_total_loss.append(loss.item())
self.val_total_acc.append(acc.item())
def test_step(self, batch, batch_idx):
data, target = batch
output = self(data)
loss = self.criterion(output, target)
self.log('test_loss', loss)
return loss
def configure_optimizers(self):
self.optimizer = optim.SGD(self.parameters(), lr=self.args.lr, momentum=0.9,weight_decay=5e-4)
self.scheduler = optim.lr_scheduler.StepLR(self.optimizer,step_size=10,gamma = 0.8)
return [self.optimizer],[self.scheduler]
class CIFAR10DataModule(pl.LightningDataModule):
def __init__(self, batch_size):
super().__init__()
self.batch_size = batch_size
def setup(self, stage=None):
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
self.train = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
self.test = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
def train_dataloader(self):
return DataLoader(self.train, batch_size=self.batch_size,shuffle=True,num_workers=2,persistent_workers=True)
def val_dataloader(self):
return DataLoader(self.test, batch_size=self.batch_size,shuffle=False,num_workers=2,persistent_workers=True)
def test_dataloader(self):
return DataLoader(self.test, batch_size=self.batch_size)
def main():
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=128, metavar='N',help='input batch size for training (default: 64)')
parser.add_argument('--epochs', type=int, default=100, metavar='N',help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',help='learning rate (default: 1.0)')
parser.add_argument('--act', type=int, default=-1,help='learning rate (default: 1.0)')
parser.add_argument('--sparse', type=int, default=0,help='learning rate (default: 1.0)')
args = parser.parse_args()
cifar10_data = CIFAR10DataModule(batch_size=args.batch_size)
log_dir = "lightning_logs"
args.sparse=0 #不开启稀疏
args.act=0 #自适应激活
model = LitNet(args)
logger = TensorBoardLogger(save_dir=log_dir, name="SelectiveActive")
trainer = pl.Trainer(logger=logger,devices=1,max_epochs=args.epochs,val_check_interval=1.0,gradient_clip_val=0.9, gradient_clip_algorithm="value")
trainer.fit(model, cifar10_data)
args.sparse=0 #不开启稀疏
args.act=-1 #不用激活
model = LitNet(args)
cifar10_data = CIFAR10DataModule(batch_size=args.batch_size)
logger = TensorBoardLogger(save_dir=log_dir, name="NoActive")
trainer = pl.Trainer(logger=logger,devices=1,max_epochs=args.epochs,val_check_interval=1.0,gradient_clip_val=0.9, gradient_clip_algorithm="value")
trainer.fit(model, cifar10_data)
args.sparse=1
args.act=-1 #不用激活,开启稀疏
model = LitNet(args)
logger = TensorBoardLogger(save_dir=log_dir, name="SparseActivation")
trainer = pl.Trainer(logger=logger,devices=1,max_epochs=args.epochs,val_check_interval=1.0,gradient_clip_val=0.9, gradient_clip_algorithm="value")
trainer.fit(model, cifar10_data)
for idx,act_name in enumerate(SparseActivation.act_array):
name=act_name.__class__.__name__
print(name)
args.act=idx+1
args.sparse=0
model = LitNet(args)
logger = TensorBoardLogger(save_dir=log_dir, name=name)
trainer = pl.Trainer(logger=logger,devices=1,max_epochs=args.epochs,val_check_interval=1.0,gradient_clip_val=0.9, gradient_clip_algorithm="value")
trainer.fit(model, cifar10_data)
if __name__ == '__main__':
main()