学成在线项目开发技巧整理---第一部分
- 1.数据字典
- 2.http-client远程测试插件,可以保存测试数据
- 3.三种跨域解决
- 4.具有多层级数据查询思路
- 5.Mybaits分页插件原理
- 6.根据文件后缀解析出mime-type
- 7.大文件上传
- 8.Spring事务什么时候会失效
- 9.分布式文件系统MinIo
- 10.构建独立文件系统
- 11.断点续传实现
- 12. xxl-job分布式任务调度
- 13.使用Groovy实现热部署
- 14.xxl-job应用实例
- 15.视频编码解码工具FFmpeg
- 16.java调用外部程序
- 17.如何防止任务被重复执行
- 18.任务幂等性如何保证
视频项目链接: 学成在线
整理的是我个人认为偏生疏的知识点,不一定涉及的全面。
1.数据字典
在系统中某些选项是几个特定的值的一个或多个,并且随着还可以动态添加。比如支付方式,配送方式等。
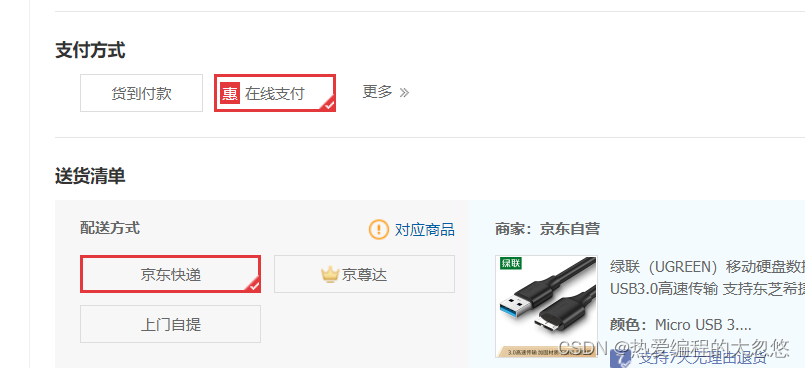
此时我们应该设计一个数据字典模块,在后台进行管理,然后前台要从后端查询。并且由于我们可能有多个类型,每个类型可能有多个选项。所以,后台数据库表设计就包含数据字典类型或数据字典明细两张表。具体设计如下:
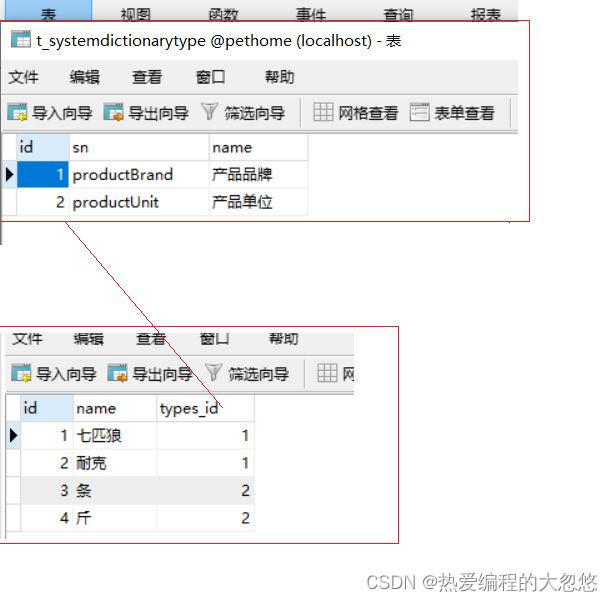
数据字典数据是经常查询并且很少修改的,我们可以给他缓存到redis中提升效率。
2.http-client远程测试插件,可以保存测试数据
1.安装相关插件

2.生成测试接口文件
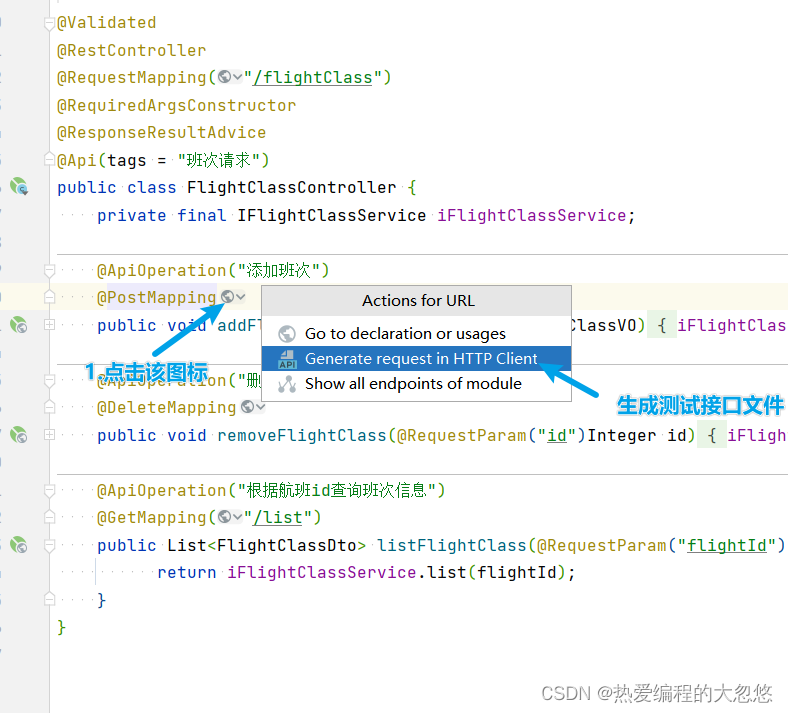
3.编写测试用例
### 查询航班
GET http://localhost:5200/flightClass/list?page=1&pageSize=2
Content-Type: application/json
{
"name": "大忽悠",
"age": 18
}
我们还可以将重复配置,如果服务器url抽取到环境配置文件中保存,然后在请求测试文件中引用环境变量中的值。
相比于Swagger来说,该测试插件可以保存测试用例数据,还是比较方便的。
IntelliJ IDEA 自带的 HTTP Client 接口调用插件
3.三种跨域解决
跨域是什么:
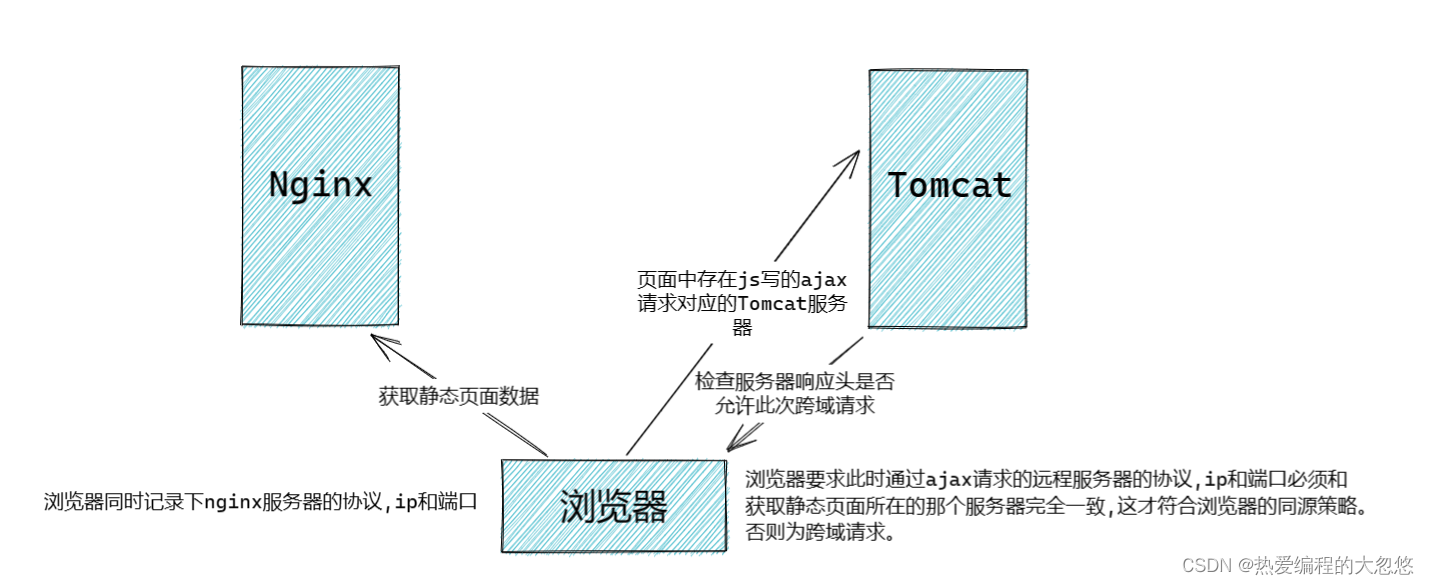
不同源会怎样:
- 不能访问cookie、localStorage、IndexDB
- 不能获取DOM、
- 不能发送Ajax请求。(实际上是不允许读取response,浏览器不会阻止你发送请求)
同源策略解决了哪些安全隐患:
- 共享cookie,恶意网站可以通过js获取用户其他网站的cookie。
- 获取DOM,通过iframe直接伪装其他站点(除了域名啥都一样怎么看出来),然后通过本地js操作DOM获取信息。
- 发送AJAX,当你访问一个恶意网站,网站js向淘宝发送登录请求,很多人的电脑里有cookie不需要账号密码就直接登陆上去了,这样再通过js解析返回的数据,就可以得到很多个人信息啦。
同源策略的目的:保证用户信息的安全,防止恶意网站窃取数据。
跨域解决方案:
- JSONP: 网页通过添加一个script元素,向服务器请求json数据, 这种做法不受同源策略限制; 服务器收到请求后,将数据放在一个指定名字的回调函数里传回来
function addScriptTag(src) {
var script = document.createElement('script');
script.setAttribute("type","text/javascript");
script.src = src;
document.body.appendChild(script);
}
window.onload = function () {
addScriptTag('http://example.com/ip?callback=foo');
}
function foo(data) {//这里的data就是服务器传回来的数据啦
console.log('Your public IP address is: ' + data.ip);
};
服务器收到请求,并返回如下数据:
foo({
"ip": "8.8.8.8"
});
- 在服务器端添加响应头: access-control-Allow-Orgin
简单请求如果跨域,浏览器直接给你加一个Origin的头信息
GET /cors HTTP/1.1 Origin: http://api.bob.com Host: api.alice.com Accept-Language: en-US Connection: keep-alive User-Agent: Mozilla/5.0...
如果Origin指定的源,不在许可范围内,服务器会返回一个正常的HTTP回应。浏览器发现,这个回应的头信息没有包含Access-Control-Allow-Origin字段(详见下文),就知道出错了,从而抛出一个错误,被XMLHttpRequest的onerror回调函数捕获。
注意,这种错误无法通过状态码识别,因为HTTP回应的状态码有可能是200。
如果Origin指定的域名在许可范围内,服务器返回的响应,会多出几个头信息字段。
Access-Control-Allow-Origin: http://api.bob.com
Access-Control-Allow-Credentials: true
Access-Control-Expose-Headers: FooBar
Content-Type: text/html;charset=utf-8
- nginx反向代理
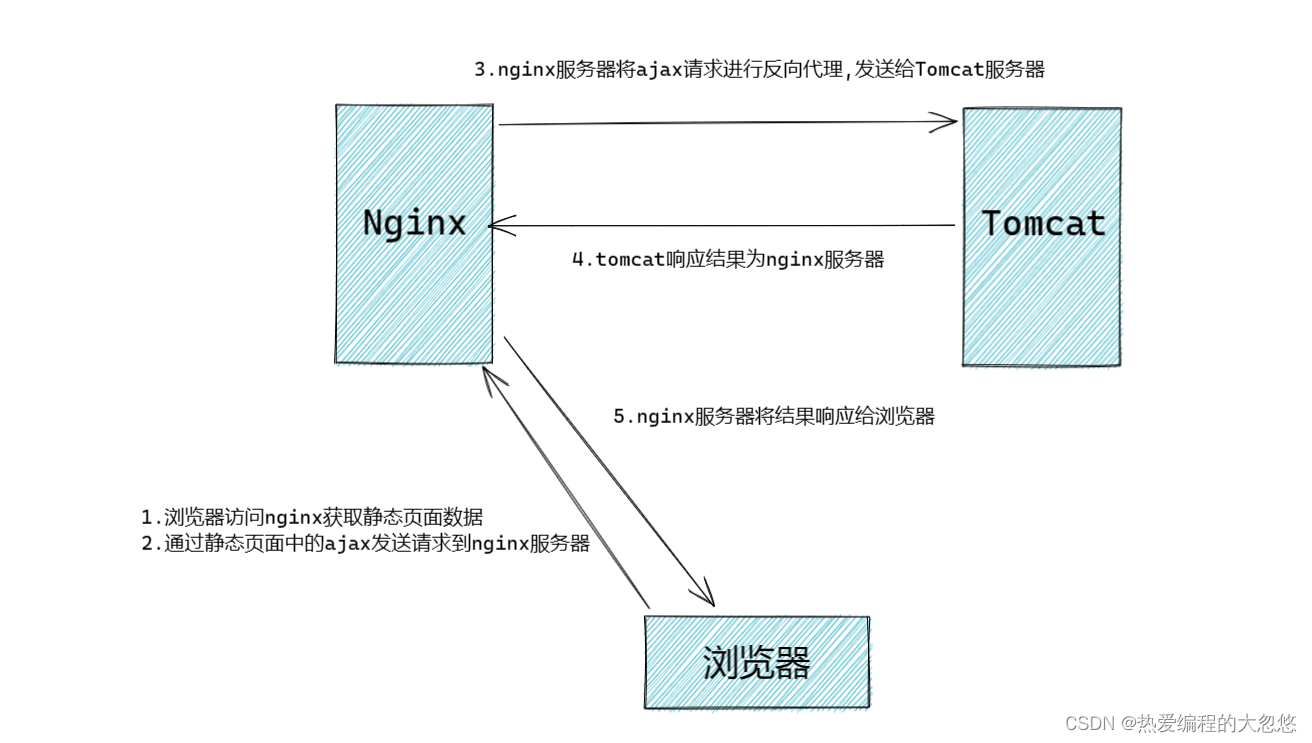
4.具有多层级数据查询思路
以评论表为例:
DROP TABLE IF EXISTS `comments`;
CREATE TABLE `comments` (
`id` int NOT NULL AUTO_INCREMENT,
`content` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`parent_id` int NOT NULL,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
) ENGINE = InnoDB AUTO_INCREMENT = 0 CHARACTER SET = 'utf8' COLLATE = 'utf8_general_ci' ROW_FORMAT = compact;
insert into comments(content,parent_id) VALUES('666',-1);
insert into comments(content,parent_id) VALUES('777',-1);
insert into comments(content,parent_id) VALUES('666的子评论66',1);
insert into comments(content,parent_id) VALUES('66的子评论6',3);
假设评论表只有两级,可以使用表自连接进行查询:
select two.* from comments one inner join comments two on one.id=two.parent_id where one.id=1;
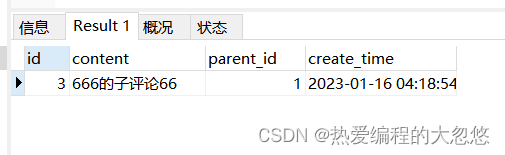
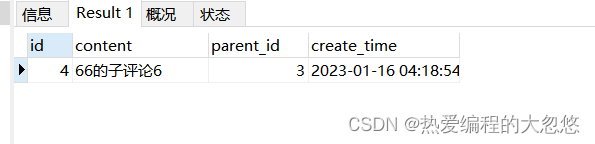
使用自连接查询三级评论:
select three.* from comments one
inner join comments two on one.id=two.parent_id
inner join comments three on two.id=three.parent_id
where one.id=1;
使用mysql专属的递归查询语句(mysql 8.0才会支持):
WITH recursive 表名 AS (
初始语句(非递归部分)
UNION ALL
递归部分语句
)
[ SELECT| INSERT | UPDATE | DELETE]
例子:

查询id为1下的所有子评论:
with recursive marks as (
select * from comments where id=1
union all
select c.* from comments c,marks m where m.id=c.parent_id
)
SELECT * FROM marks;
5.Mybaits分页插件原理
日后补充
6.根据文件后缀解析出mime-type
工具类github链接:
https://github.com/j256/simplemagic
简单使用演示:
- 引入依赖:
<dependency>
<groupId>com.j256.simplemagic</groupId>
<artifactId>simplemagic</artifactId>
<version>1.17</version>
</dependency>
ContentInfoUtil util = new ContentInfoUtil();
ContentInfo info1 = util.findMatch("C:\\Users\\zdh\\Desktop\\好书\\book\\boook\\01_Java\\JAVA 8实战.pdf");
System.out.println(info1.toString());
//ContentInfo info2 = util.findMatch(inputStream);
//ContentInfo info3 = util.findMatch(contentByteArray);

7.大文件上传
项目中如果需要使用文件存储,可以首先考虑免费开源的MinIo: http://docs.minio.org.cn/docs/
如果需要通过浏览器上传大文件到服务器,那么应该考虑使用分片上传,确保在上传掉线后,可以从上次断线后的分片开始上传,无需重新上传整个文件,具体思路如下:
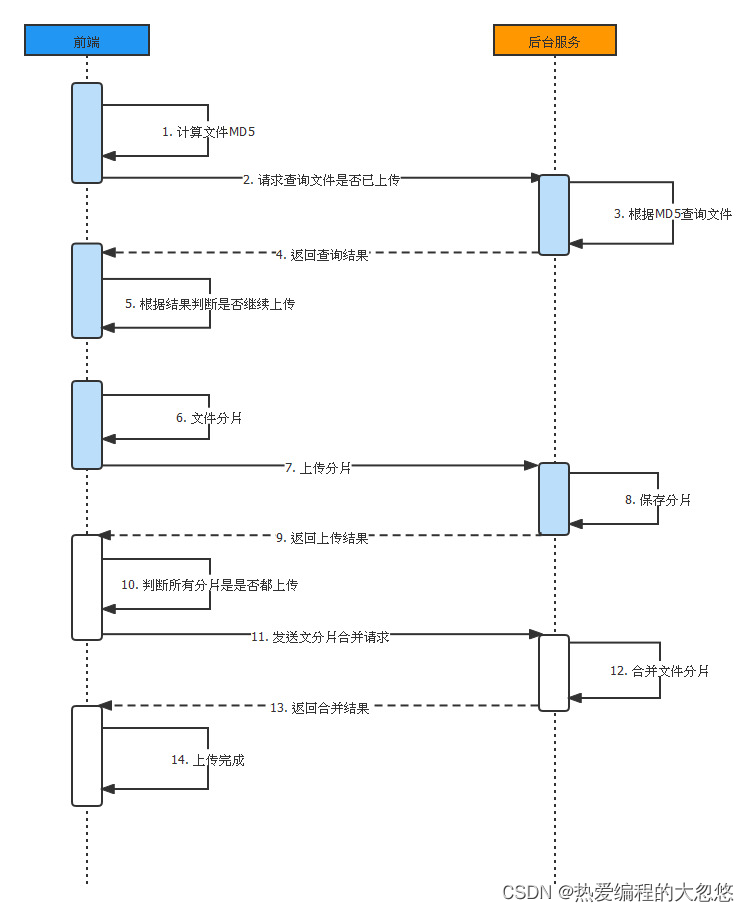
视频中给出的大文件上传过程:
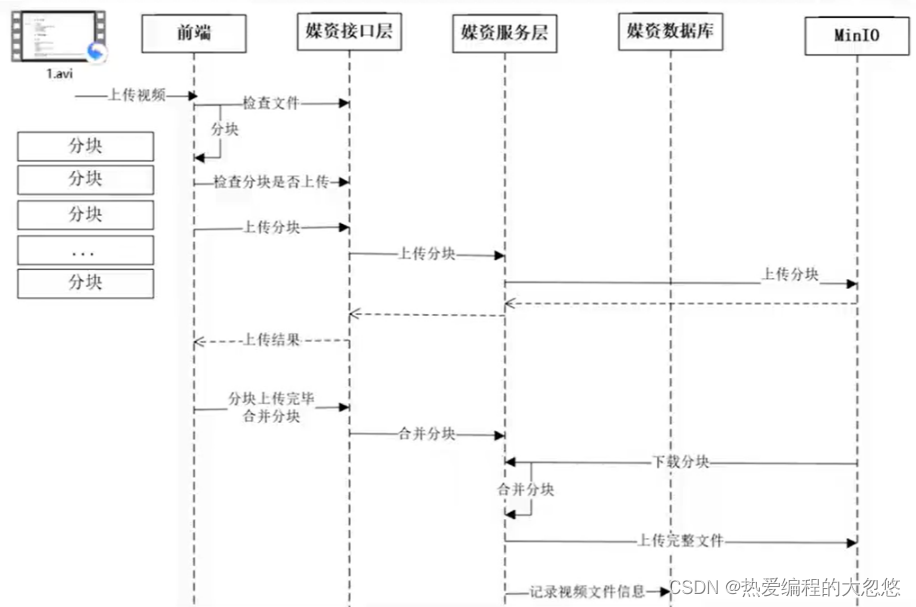
文件合并过程通常还需要在最后将文件信息保存到数据库中,这其中如果涉及对多个表的操作,需要添加@Transactional注解提供事务支持,但是注意事务囊括的方法尽量只包括数据库相关操作,而不包含IO操作,避免产生长事务。
长事务风险
注意: 在单体应用下,可以考虑边上传分片,边将分片数据写入临时文件中存储,当收到合并分块请求时,先校验临时文件md5是否与原文件一致,如果一致就上传到minIo,否则说明上传过程中出现文件损坏情况。
分布式情况下,不能采用写入临时文件的方案,因为存在多个应用实例,前端的上传分片请求通过负载均衡,不能保证每一次都转发给同一个应用实例处理。
8.Spring事务什么时候会失效
- 方法捕获异常没有抛出去
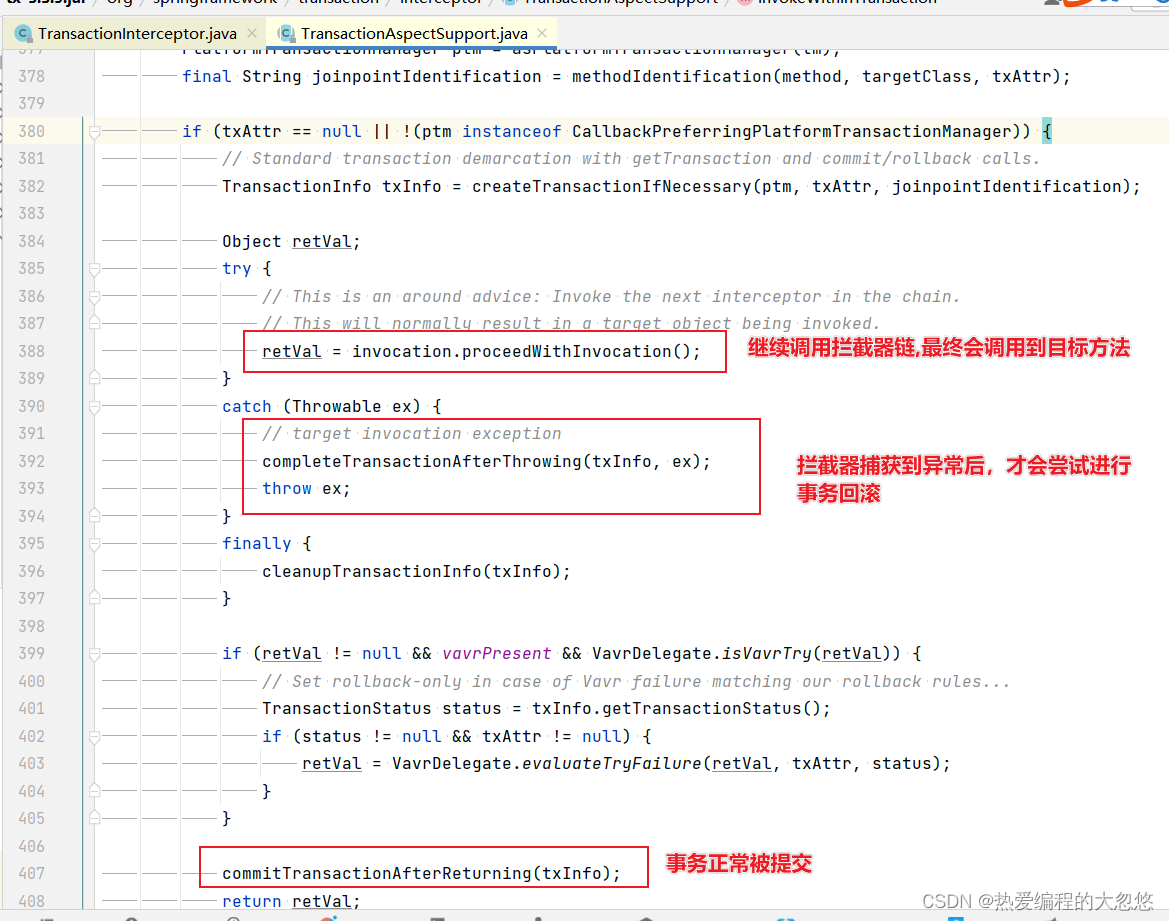
- 目标对象方法内调用自身其他方法,原因: 调用代理对象方法后,经历一系列事务拦截器,Async拦截器后,最终调用目标对象方法,但是目标对象方法内部又调用了自身的其他方法,因为调用的不是代理对象的方法,因此方法执行不会被代理。
- @Transactional注解标记的方法不是public的, 原因: 首先这里我们只需要考虑Cglib动态代理,一般只有目标对象本身传入的就是一个接口时,才会选择JDK动态代理
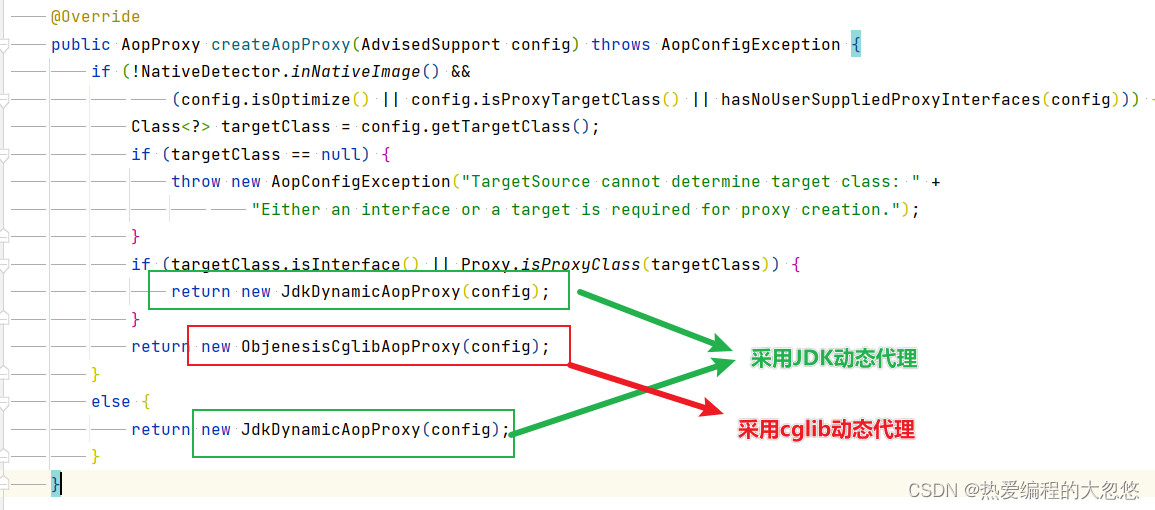
而cglib采用继承,子类重写父类方法的方式来实现代理增强,所以对于父类中的私有方法,子类是无法增强的,这是其中一方面原因。
spring 事务模块在源码中就限定死了只有public方法能够提供事务支持:
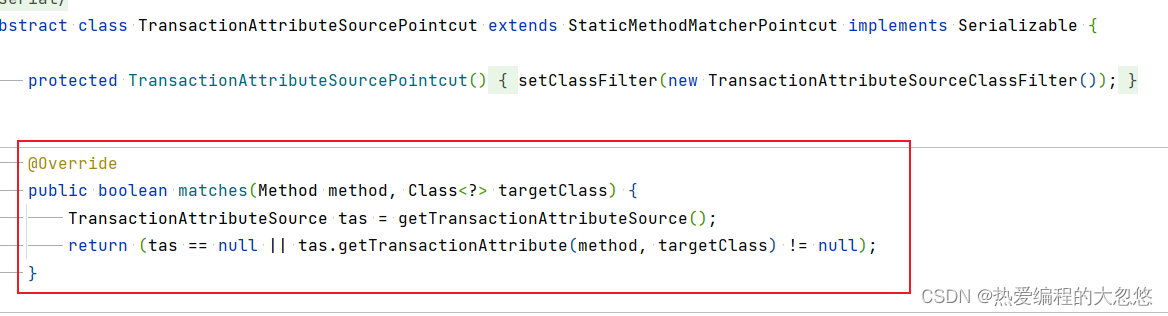
TransactionAttributeSourcePointcut是用来判断BeanFactoryTransactionAttributeSourceAdvisor是否能够应用于当前方法的,而其中判断的关键方法match,又是利用了TransactionAttributeSource的getTransactionAttribute方法来进行判断的。
getTransactionAttribute方法内部计算某个方法的事务属性时,一开始就限制死了:

publicMethodsOnly默认为true,我们可以更改为false,让protect方法也能享受事务支持。
spring事务模块源码解析
- 抛出的异常与rollbackfor指定的异常不匹配,默认rollback指定的异常为RuntimeException
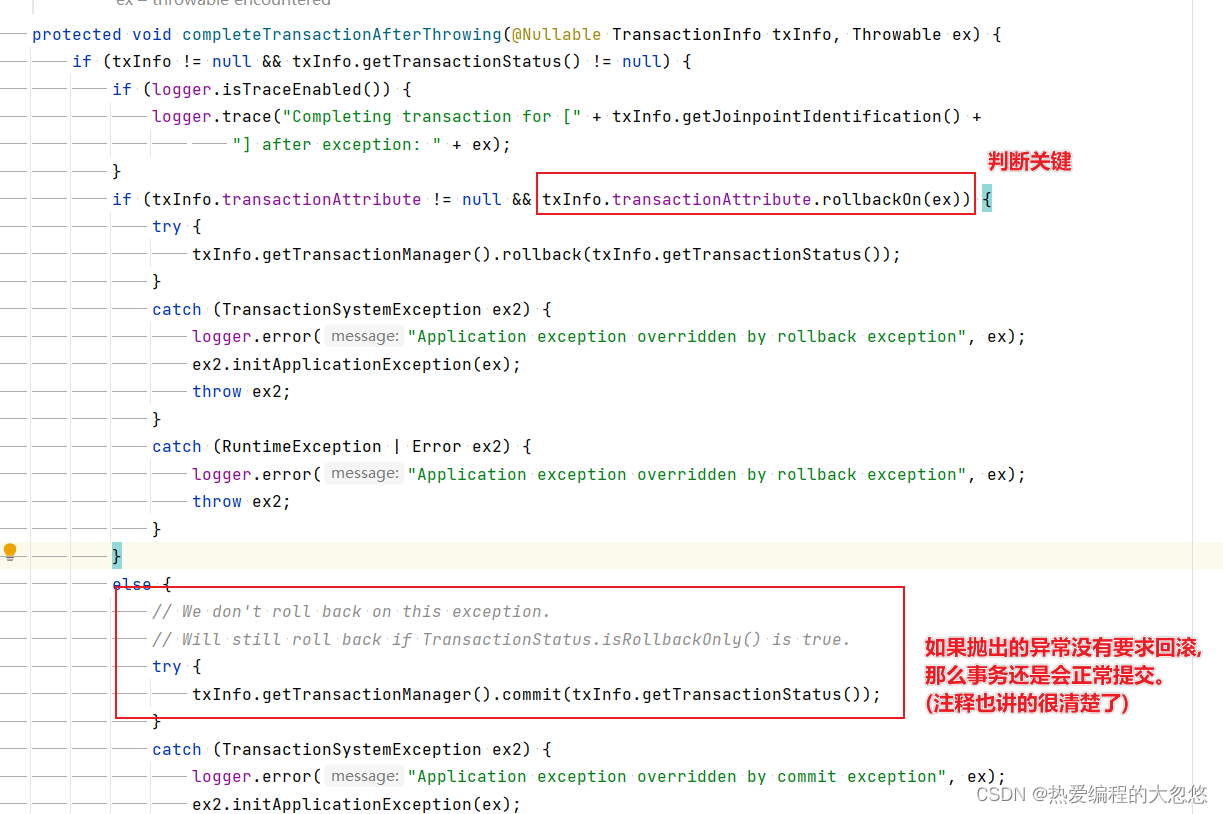
默认rollbackOn方法会回滚的异常:
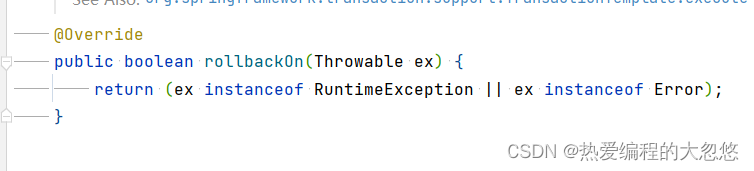
spring事务模块源码解析
- 数据库表底层采用的存储引擎本身不支持事务,例如mysql的MyISAM存储引擎
- Spring的传播行为也会导致事务失效,比如: PROPAGATION_NEVER,PROPAGATION_NOT_SUPPORTED

9.分布式文件系统MinIo
Minio 是个基于 Golang 编写的开源对象存储套件,虽然轻量,却拥有着不错的性能。
MINIO 有几个概念比较重要:
- Object:存储到 Minio 的基本对象,如文件、字节流,Anything…
- Bucket:用来存储 Object 的逻辑空间。每个 Bucket 之间的数据是相互隔离的。对于客户端而言,就相当于一个存放文件的顶层文件夹。
- Drive:即存储数据的磁盘,在 MinIO 启动时,以参数的方式传入。Minio 中所有的对象数据都会存储在 Drive 里。
- Set: 即一组 Drive 的集合,分布式部署根据集群规模自动划分一个或多个 Set ,每个 Set 中的 Drive 分布在不同位置。一个对象存储在一个 Set 上。(For example: {1…64} is divided into 4 sets each of size 16.)
- 一个对象存储在一个Set上
- 一个集群划分为多个Set
- 一个Set包含的Drive数量是固定的,默认由系统根据集群规模自动计算得出
- 一个SET中的Drive尽可能分布在不同的节点上
Set /Drive 的关系
Set /Drive 这两个概念是 MINIO 里面最重要的两个概念,一个对象最终是存储在 Set 上面的。
我们来看下边 MINIO 集群存储示意图,每一行是一个节点机器,这有 32 个节点,每个节点里有一个小方块我们称之 Drive,Drive 可以简单地理解为一个硬盘。
图中,一个节点有 32 个 Drive,相当于 32 块硬盘。
Set 是另外一个概念,Set 是一组 Drive 的集合,图中,所有蓝色、橙色背景的Drive(硬盘)的就组成了一个 Set.
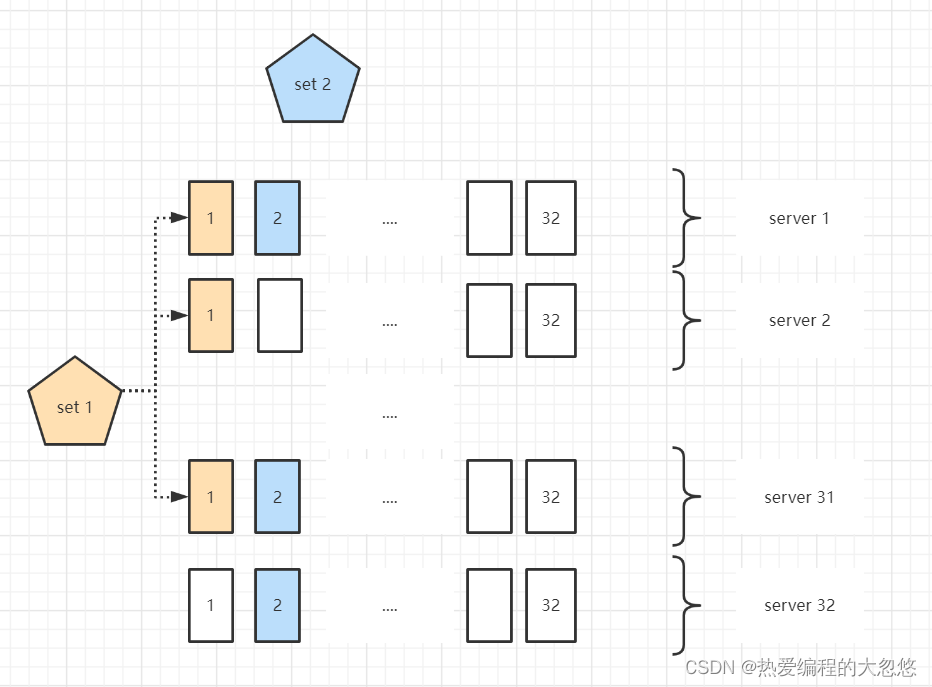
MIINO如何写入对象?
MINIO 是通过数据编码,将原来的数据编码成 N 份,N 就是一个 Set 上面 Drive 的数量,后面多次提到的 N 都是指这个意思。
上图中,一个 Set 上面 Drive 的数量,是3.
对象被编码成N份之后,把每一份,写到对应的 Drive 上面,这就是把一个对象存储在整个 Set 上。
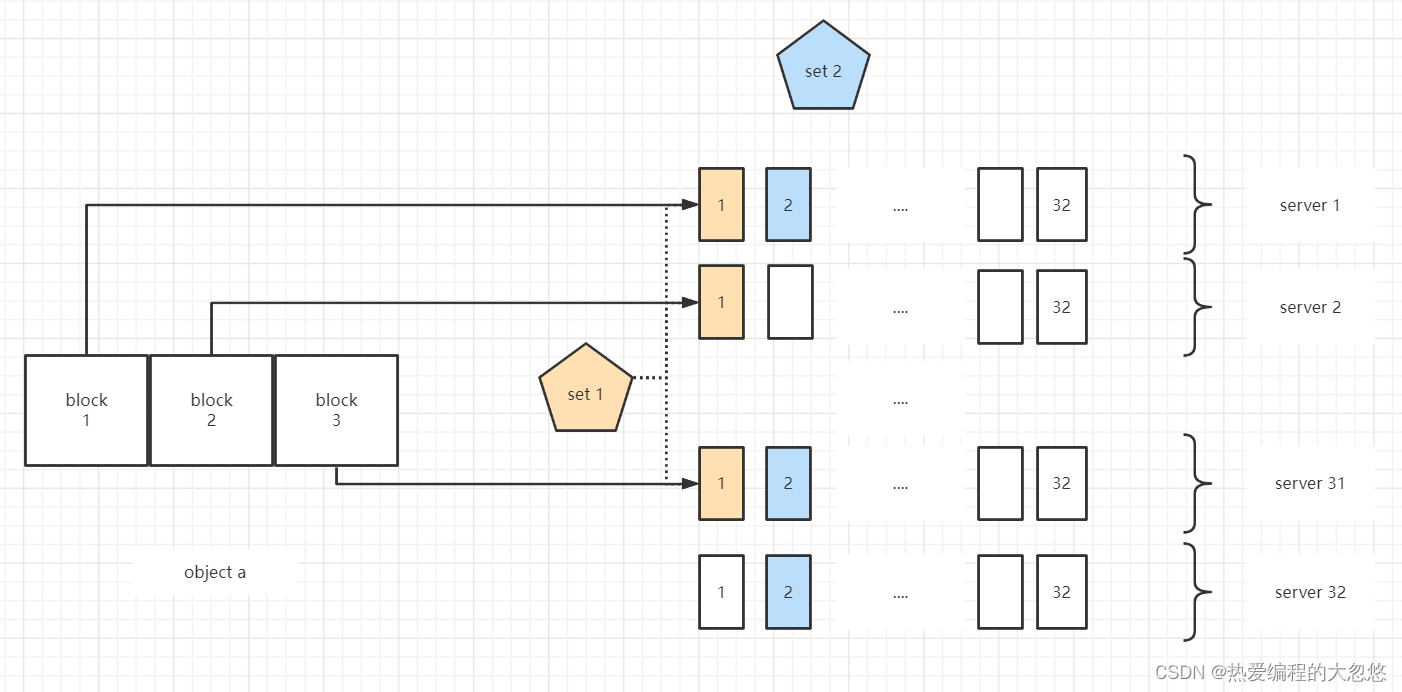
一个集群包含多个 Set,每个对象最终存储在哪个 Set 上是根据对象的名称进行哈希,然后影射到唯一的 Set 上面,这个方式从理论上保证数据可以均匀的分布到所有的 Set 上。
根据的观测,数据分布的也非常均匀,一个 Set 上包含多少个 Drive 是由系统自动根据集群规模算出来的,当然,也可以自己去配置。
一个 Set 的 Drive 系统会考虑尽可能把它放在多的节点上面,保证它的可靠性。
MinIO的数据高可靠
Minio使用了Erasure Code 纠删码和 Bit Rot Protection 数据腐化保护这两个特性,所以MinIO的数据可靠性做的高。
- Erasure Code纠删码
纠删码(Erasure Code)简称EC,是一种数据保护方法,它将数据分割成片段,把冗余数据块扩展、编码,并将其存储在不同的位置,比如磁盘、存储节点或者其它地理位置。
从数据函数角度来说,纠删码提供的保护可以用下面这个简单的公式来表示:n = k + m。变量“k”代表原始数据或符号的值。变量“m”代表故障后添加的提供保护的额外或冗余符号的值。变量“n”代表纠删码过程后创建的符号的总值。
举个例子,假设n=16,代表有16块磁盘,另外,有10份原始文件一模一样,称为k,16 = 10 +m,这个m就是可以恢复的校验块个数,所以m是6,任意6个不可用,原始文件都可以恢复,极端情况,10个原始文件坏掉6个,靠4个原始的加上6个校验块,可以把坏掉的6个原始文件恢复,这个用到数学行列式矩阵知识,不做展开。
MinIO的编码方式,将一个对象编码成若干个数据块和校验块,我们简称为Erasure Code码,这个是编码的类型,这种编码的类型,还需要算法来实现,minio 采用的是 Reed-Solomon算法。
MinIO使用Reed-Solomon算法,该算法把对象编码成若干个数据块和校验块。
Reed-Solomon算法的特点:
- 低冗余
- 高可靠
为了表述方便,把数据块和校验块统称为编码块,之后我们可以通过编码块的一部分就能还原出整个对象。
…
完整查看此篇文章介绍
10.构建独立文件系统
- 项目中存在很多需要上传文件的地方,因此我们需要构建一个独立的文件服务负责上传,下载等功能,负责对文件进行统一管理。
- 创建单独的文件服务,提供以下接口:
- 上传接口
- 下载接口
- 图库接口
- 文件库接口
- 删除文件接口
- 文件的存储和瞎子可以是由MinIo实现
- 使用Nginx+MinIo组成一个文件服务器,通过访问Nginx,由nginx代理将请求转发到Minio集群去浏览,下载文件
- 创建专门的表或者数据库对文件信息进行统一持久化存储
minio分布式方案实现
minio 分布式解决方案
11.断点续传实现
1.前端对文件进行分块
2.前端使用多线程上传分片,上传前给服务器发送消息验证当前分片是否已经上传。
3.所有分片上传完毕后,发送合并分片请求,校验文件的完整性。 (上传的分片应该具备顺序标记)
4.前端给服务器传一个MD5值,服务器合并文件后,利用MD5值计算是否与源文件一致。如果不一致,说明文件需要重新上传。
分片文件清理问题:
- 在数据库中有一张文件表记录minIo中存储的文件信息
- 文件开始上传时会写入文件表,状态为上传中,上传完成会更新状态为上传完成
- 当一个文件传了一半不再上传了,说明该文件没有上传完成,通过定时任务去查询文件表中的记录,如果文件距离上次上传结束超过24小时,则可以考虑清除MinIo中相关的分片数据
12. xxl-job分布式任务调度
xxl-job相较于Quartz容易很多,建议大家拉取源码,阅读doc文档进行学习:
xxl-job官网
xxl-job gitee源码仓库链接
xxl-job github源码仓库链接
Quartz框架学习
13.使用Groovy实现热部署
在xxl-job中,所有的任务都要实现IJobHandler接口,它的web Glue方式就是基于Groovy实现的。
Groovy实现热部署原理可以参考此篇文章
14.xxl-job应用实例
项目中在视频格式转换这块使用xxl-job做分布式任务调度工具,负责异步完成视频异步处理调度任务,具体逻辑如下:
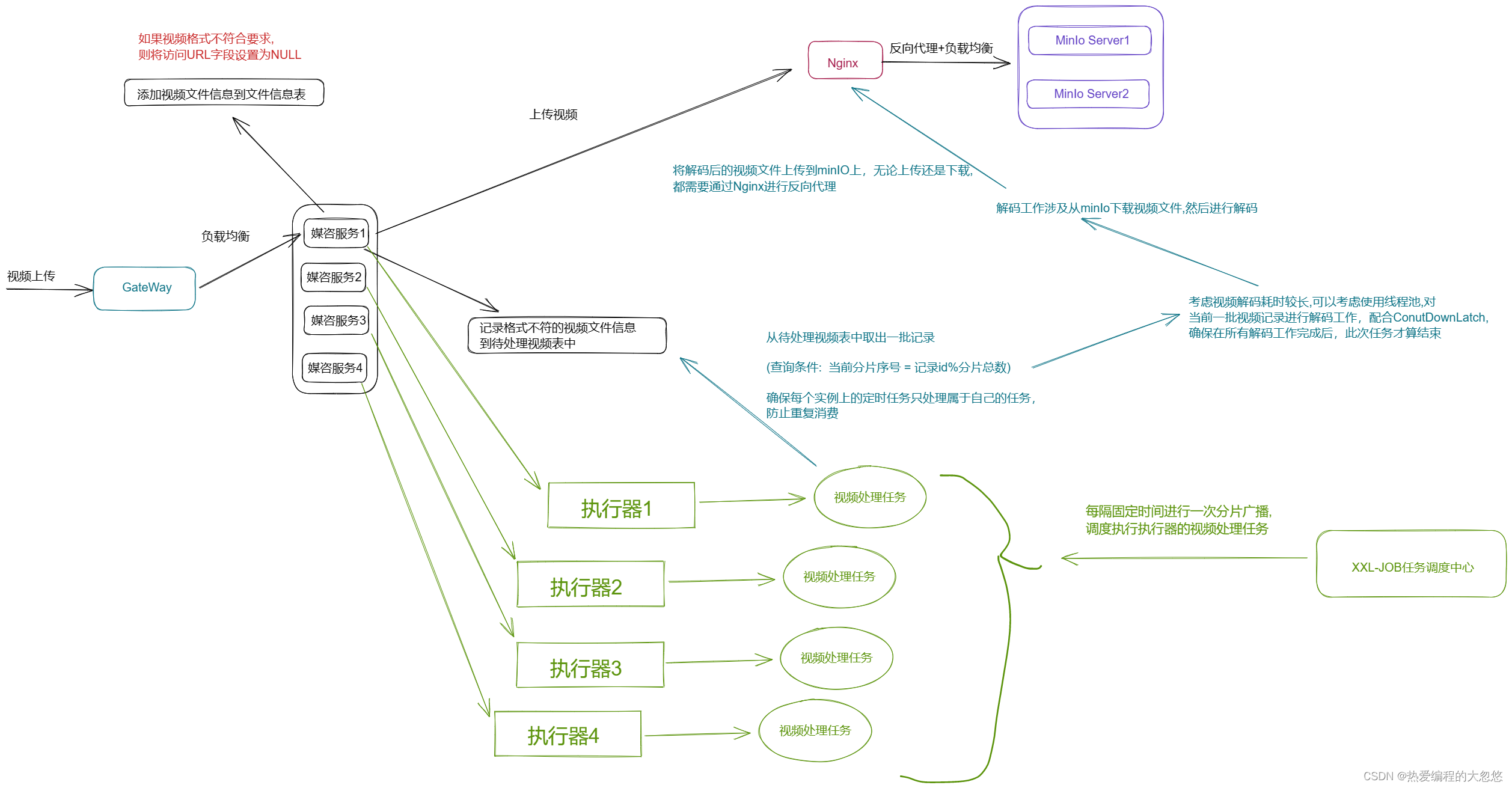
具体视频处理任务的步骤如下:
1.从待处理视频表中查询出一批记录
2.挨个遍历每条记录,将每个视频的解码工作都包装为一个任务提交到线程池执行
3.具体解码工作又包含:
3.1 我们需要给待处理视频表添加一个状态字段,来判断当前视频处理状态,防止重复处理,保证幂等性
3.2 判断当前记录状态是否为已经处理,如果不是则继续处理
3.3 从记录中取出文件相关信息,从MinIo下载文件到本地
3.4 利用工具类对视频进行解码
3.5 将转换后的视频上传MinIo
3.6 更新状态,这个过程包含如下步骤:
3.6.1 更新记录的状态为处理完毕
3.6.2 更新文件信息表中对应视频的URL字段
3.6.3 将当前处理完毕的任务添加到历史任务表中
3.6.4 删除待处理视频表中该条记录
15.视频编码解码工具FFmpeg

ffmpeg工具下载
使用演示:

成功将test.mp4文件转换为了test.gif:

16.java调用外部程序
processBuilder类使用科普
processBuilder
ProcessBuilder processBuilder = new ProcessBuilder();
//将标准输入流和错误输入流合并,通过标准输入流读取信息
processBuilder.redirectErrorStream(true);
//构建命令执行参数
processBuilder.command("fmpeg-master-latest-win64-gpl\\bin\\ffmpeg.exe",
"-i", "test.mp4", "test.gif");
//命令开始执行,返回对应的进程对象
Process res = processBuilder.start();
//读取进程的输入流,将程序执行过程中产生的输出信息打印出来
try(BufferedReader r=new BufferedReader(new InputStreamReader(res.getInputStream()))){
String line=null;
while((line=r.readLine())!=null){
System.out.println(line);
}
}
17.如何防止任务被重复执行
1)调度中心按分片广播的方式去下发任务
2)执行器收到作业分片广播的参数:分片总数和分片序号,计算任务id除以分片总数得到一个余数,如果余数等于分片序号这时就去执行这个任务,这里保证了不同的执行器执行不同的任务。
3)配置调度过期策略为“忽略”,避免同一个执行器多次重复执行同一个任务
4)配置任务阻塞处理策略为“丢弃后续调度”,注意:丢弃也没事下一次调度就又可以执行了
5)另外还要保证任务处理的幂等性,执行过的任务可以打一个状态标记已完成,下次再调度执行该任务判断该任务已完成就不再执行
18.任务幂等性如何保证
幂等性描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果。幂等性是为了解决重复提交问题,比如:恶意刷单,重复支付等。
解决幂等性常用的方案:
1)数据库约束,比如:唯一索引,主键索引,同一个主键不可能两次都插入成功。
2)乐观锁,常用于数据库,更新数据时根据乐观锁状态去更新。
3)唯一序列号,请求前生成唯一的序列号,携带序列号去请求,执行时在redis记录该序列号表示以该序列号的请求执行过了,如果相同的序列号再次来执行说明是重复执行。
本项目在数据库视频处理表中添加处理状态字段,视频处理完成更新状态为完成,执行视频处理前判断状态是否完成,如果完成则不再处理。 (方法二在不同场景下的体现)