目录
前言 (链接放在评论区)(链接放在评论区)(链接放在评论区)
目的 (链接放在评论区)(链接放在评论区)(链接放在评论区)
思路 (链接放在评论区)(链接放在评论区)(链接放在评论区)
代码实现
1. 用 openpyxl 库便捷创建 xlsx 文件用于保存信息
2. 伪装请求头,访问目标 URL
3. 请求文本传入PyQuery进行初始化
4. 遍历 rank-list 的 li 节点,拿取每一条的详细信息
5. 写入文件
完整代码
运行效果
总结
前言
上一节我们学习了PyQuery的语法,这节进行实战,抓取某站(链接放在评论区)的热搜排行榜作为练手。
涉及的库:openpyxl requests (logging) PyQuery
目的
抓取小电视热搜排行榜的详细信息(包括全站排行榜Top100的排名、视频主题、链接、播放量、弹幕量以及UP主名)并另存到文件(链接放在评论区)
思路
1. 用 openpyxl 库便捷创建 xlsx 文件用于保存信息
2. 伪装请求头,访问目标 URL
3. 请求文本传入PyQuery进行初始化
4. 遍历 rank-list 的 li 节点,拿取每一条的详细信息
5. 写入文件
代码实现
1. 用 openpyxl 库便捷创建 xlsx 文件用于保存信息
导包
from pyquery import PyQuery as pq
import requests
import logging
import openpyxl初始化工作表
wb = openpyxl.Workbook() # 初始化工作簿对象
sheet = wb.active # 获取活动的工作表
# 添加列名
sheet.append(['rank', 'title', 'link', 'bicon_play', 'bicon_barrage', 'creator'])
# 日志输出配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')这里还添加了一行日志输出的配置,可以在控制台显示录入了什么信息,便于我们快速纠错。
2. 伪装请求头,访问目标 URL
# 伪装请求头
headers = {
"Origin": "见评论区",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
}
# 目标URL
url = '见评论区'
resp = requests.get(url, headers=headers).text
3. 请求文本传入PyQuery进行初始化
# request请求获取的文本传入PyQuery初始化
doc = pq(resp)4. 遍历 rank-list 的 li 节点,拿取每一条的详细信息
(通过观察页面源代码发现的,不熟悉的小伙伴移步专栏以前发布过的实战文章)
给一个比较详细的案例吧:传送门
# 获取class=rank-list 下所有li节点内容
# 遍历li节点
con1 = doc('.rank-list li')
for item in con1.items():
rank = item('.num').text() # 排名
title = item('.content .info a:first-child').text() # 视频标题
link = 'https:' + item('.content .info a').attr('href') # 视频链接
# creator = item('.content .info .detail a span').text() # UP主
creator, bicon_play, bicon_barrage = item('.content .info .detail span').text().split(' ')5. 写入文件
sheet.append([rank, title, link, bicon_play, bicon_barrage, creator])
logging.info([rank, title, link, bicon_play, bicon_barrage, creator])
wb.save(filename='11_Rank_data.xlsx')添加行,输出日志。
完整代码
# Created at UESTC
# Author: Vector Kun
# Time: 2023/1/25 14:32
from pyquery import PyQuery as pq
import requests
import logging
import openpyxl
wb = openpyxl.Workbook() # 初始化工作簿对象
sheet = wb.active # 获取活动的工作表
# 添加列名
sheet.append(['rank', 'title', 'link', 'bicon_play', 'bicon_barrage', 'creator'])
# 日志输出配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 伪装请求头
headers = {
"Origin": "见评论区",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
}
# 目标URL
url = '见评论区'
# request请求获取的文本传入PyQuery初始化
resp = requests.get(url, headers=headers).text
doc = pq(resp)
# 获取class=rank-list 下所有li节点内容
# 遍历li节点
con1 = doc('.rank-list li')
for item in con1.items():
rank = item('.num').text() # 排名
title = item('.content .info a:first-child').text() # 视频标题
link = 'https:' + item('.content .info a').attr('href') # 视频链接
# creator = item('.content .info .detail a span').text() # UP主
creator, bicon_play, bicon_barrage = item('.content .info .detail span').text().split(' ')
# print(bicon_play, bicon_view, creator) # 排名
sheet.append([rank, title, link, bicon_play, bicon_barrage, creator])
logging.info([rank, title, link, bicon_play, bicon_barrage, creator])
wb.save(filename='11_Rank_data.xlsx')
运行效果
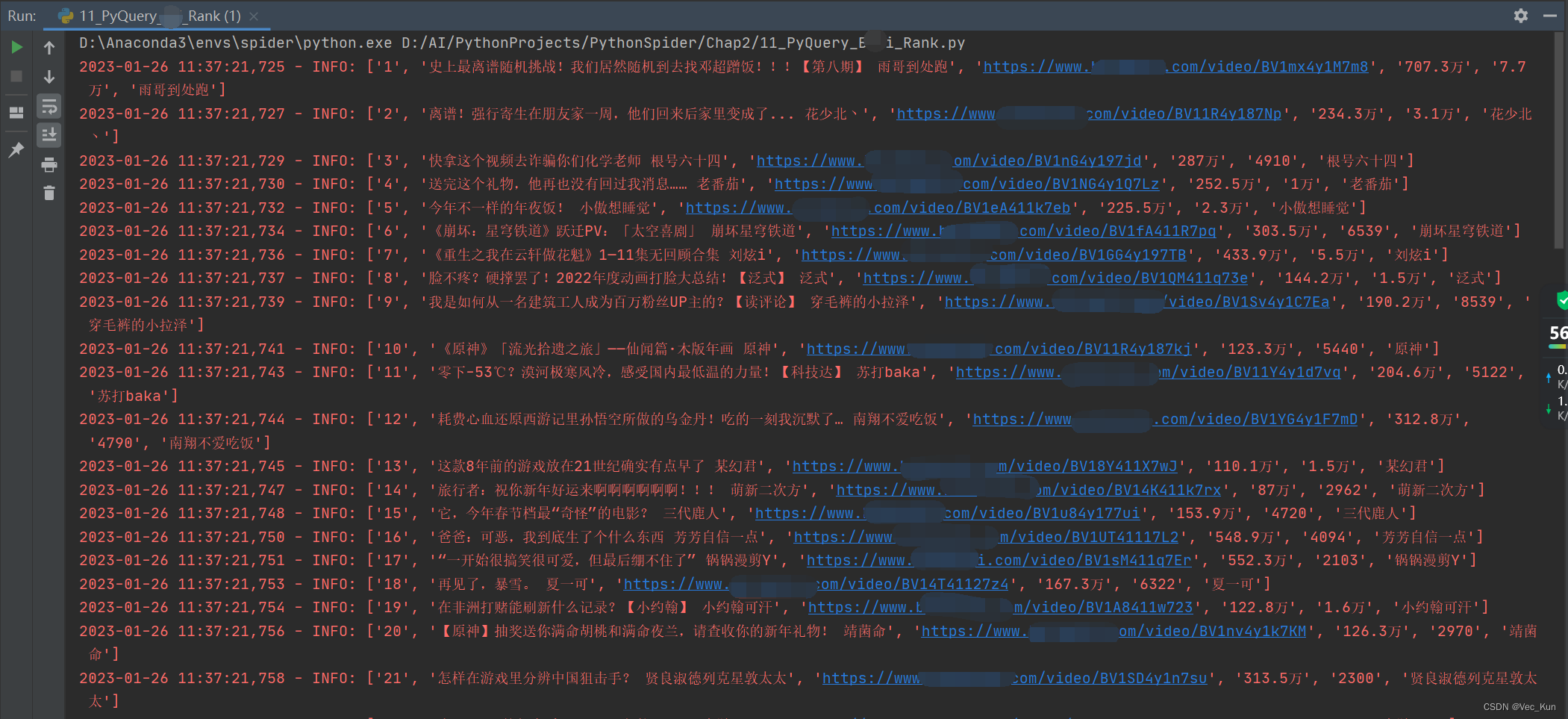
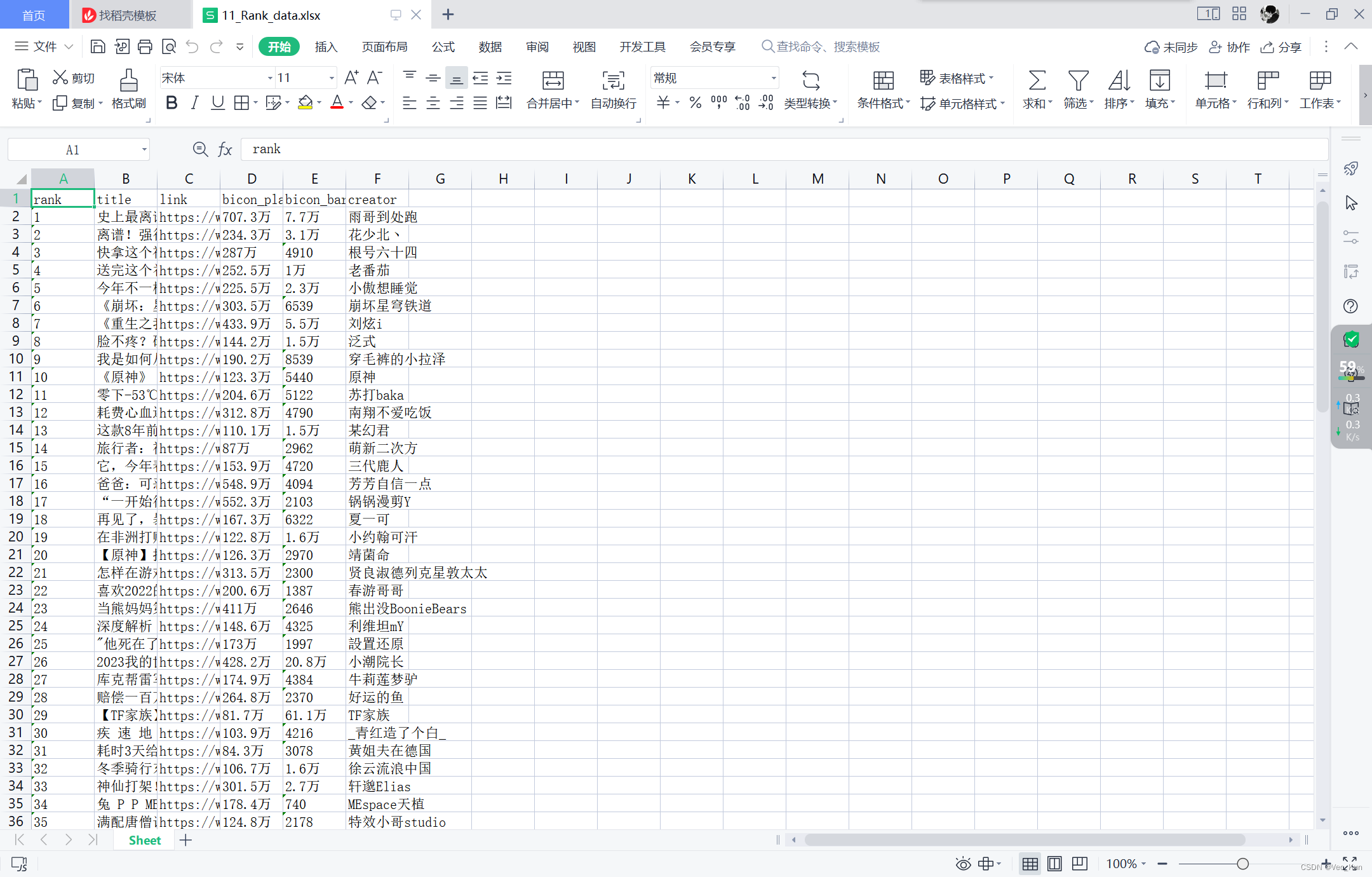
可以看到成功在控制台输出了日志信息并且将全站排行榜Top100的排名、视频主题、链接、播放量、弹幕量以及UP主名输入到了xlsx文件中。
总结
本节我们对PyQuery进行了实战,实现了抓取某站全站排行榜Top100的详细信息。