🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
| 大数据分析案例-基于随机森林算法预测人类预期寿命 |
| 大数据分析案例-基于随机森林算法的商品评价情感分析 |
| 大数据分析案例-用RFM模型对客户价值分析(聚类) |
| 大数据分析案例-对电信客户流失分析预警预测 |
| 大数据分析案例-基于随机森林模型对北京房价进行预测 |
| 大数据分析案例-基于RFM模型对电商客户价值分析 |
| 大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型 |
| 大数据分析案例-基于决策树算法构建员工离职预测模型 |
| 大数据分析案例-基于KNN算法对茅台股票进行预测 |
| 大数据分析案例-基于多元线性回归算法构建广告投放收益模型 |
| 大数据分析案例-基于随机森林算法构建返乡人群预测模型 |
1.项目背景
根据统计法和《全国人口普查条例》,我国以2020年11月1日零时为标准时点开展了第七次全国人口普查(以下简称七人普),主要目的是全面查清我国人口数量、结构、分布等方面情况,为完善我国人口发展战略和政策体系、制定经济社会发展规划、推动高质量发展提供准确统计信息支持。七人普全面采用电子化数据采集方式,实时直接上报数据,首次实现普查对象通过扫描二维码进行自主填报,强化部门行政记录和电力、手机等大数据应用,提高了普查工作质量和效率。七人普邀请钟南山、姚明担任宣传大使,“大国点名、没你不行”等宣传口号深入人心,加大了宣传力度。七人普坚持依法进行,认真落实普查方案的各项要求,实行严格的质量控制制度,建立健全普查数据追溯和问责机制,在31个省(自治区、直辖市)中随机抽取141个县的3.2万户进行了事后质量抽查,结果显示,七人普漏登率为0.05%,普查过程严谨规范,普查结果真实可靠。
(一)人口总量。全国人口[注]共141178万人,与2010年(第六次全国人口普查数据,下同)的133972万人相比,增加7206万人,增长5.38%,年平均增长率为0.53%,比2000年到2010年的年平均增长率0.57%下降0.04个百分点。数据表明,我国人口10年来继续保持低速增长态势。
(二)户别人口。全国共有家庭户49416万户,家庭户人口为129281万人;集体户2853万户,集体户人口为11897万人。平均每个家庭户的人口为2.62人,比2010年的3.10人减少0.48人。家庭户规模继续缩小,主要是受我国人口流动日趋频繁和住房条件改善年轻人婚后独立居住等因素的影响。
(三)人口地区分布。东部地区人口占39.93%,中部地区占25.83%,西部地区占27.12%,东北地区占6.98%。与2010年相比,东部地区人口所占比重上升2.15个百分点,中部地区下降0.79个百分点,西部地区上升0.22个百分点,东北地区下降1.20个百分点。人口向经济发达区域、城市群进一步集聚。
(四)性别构成。男性人口为72334万人,占51.24%;女性人口为68844万人,占48.76%。总人口性别比(以女性为100,男性对女性的比例)为105.07,与2010年基本持平,略有降低。出生人口性别比为111.3,较2010年下降6.8。我国人口的性别结构持续改善。
(五)年龄构成。0—14岁人口为25338万人,占17.95%;15—59岁人口为89438万人,占63.35%;60岁及以上人口为26402万人,占18.70%(其中,65岁及以上人口为19064万人,占13.50%)。与2010年相比,0—14岁、15—59岁、60岁及以上人口的比重分别上升1.35个百分点、下降6.79个百分点、上升5.44个百分点。我国少儿人口比重回升,生育政策调整取得了积极成效。同时,人口老龄化程度进一步加深,未来一段时期将持续面临人口长期均衡发展的压力。
(六)受教育程度人口。具有大学文化程度的人口为21836万人。与2010年相比,每10万人中具有大学文化程度的由8930人上升为15467人,15岁及以上人口的平均受教育年限由9.08年提高至9.91年,文盲率由4.08%下降为2.67%。受教育状况的持续改善反映了10年来我国大力发展高等教育以及扫除青壮年文盲等措施取得了积极成效,人口素质不断提高。
(七)城乡人口。居住在城镇的人口为90199万人,占63.89%;居住在乡村的人口为50979万人,占36.11%。与2010年相比,城镇人口增加23642万人,乡村人口减少16436万人,城镇人口比重上升14.21个百分点。随着我国新型工业化、信息化和农业现代化的深入发展和农业转移人口市民化政策落实落地,10年来我国新型城镇化进程稳步推进,城镇化建设取得了历史性成就。
(八)流动人口。人户分离人口为49276万人,其中,市辖区内人户分离人口为11694万人,流动人口为37582万人,其中,跨省流动人口为12484万人。与2010年相比,人户分离人口增长88.52%,市辖区内人户分离人口增长192.66%,流动人口增长69.73%。我国经济社会持续发展,为人口的迁移流动创造了条件,人口流动趋势更加明显,流动人口规模进一步扩大。
(九)民族人口。汉族人口为128631万人,占91.11%;各少数民族人口为12547万人,占8.89%。与2010年相比,汉族人口增长4.93%,各少数民族人口增长10.26%,少数民族人口比重上升0.40个百分点。民族人口稳步增长,充分体现了在中国共产党领导下,我国各民族全面发展进步的面貌。
人口问题始终是我国面临的全局性、长期性、战略性问题,七人普全面查清了我国人口数量、结构、分布等方面情况,准确反映了当前人口变化的趋势性特征,获得了大量宝贵的信息资源,我们正在抓紧对普查数据进行整理、分析和开发,后续会采取更多方式公布和共享普查成果,配合相关部门加强人口发展的前瞻性、战略性研究,最大程度发挥普查的作用,为推动高质量发展、有针对性地制定人口相关战略和政策、促进人口长期均衡发展提供强有力的统计信息支持。
2.项目简介
2.1研究目的及意义
人口普查是每个国家都要做的一件事,通过人口普查,我们可以分析一个国家或者某个地区的人口数据情况,构建模型,为评估每个地区的发展状况做准备。
2.2研究方法与思路
1.使用pandas导入数据并对数据进行基本的了解
2.使用matplotlib和seaborn对数据进行可视化分析
3.使用pandas对数据进行预处理
4.使用sklearn对数据集进行拆分并逻辑回归、决策树、随机森林模型
5.使用sklearn对模型进行评估
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
随机森林是一种有监督学习算法。就像它的名字一样,它创建了一个森林,并使它拥有某种方式随机性。所构建的“森林”是决策树的集成,大部分时候都是用“bagging”方法训练的。bagging 方法,即 bootstrapaggregating,采用的是随机有放回的选择训练数据然后构造分类器,最后组合学习到的模型来增加整体的效果。简而言之,随机森林建立了多个决策树,并将它们合并在一起以获得更准确和稳定的预测。其一大优势在于它既可用于分类,也可用于回归问题,这两类问题恰好构成了当前的大多数机器学习系统所需要面对的。
随机森林分类器使用所有的决策树分类器以及 bagging 分类器的超参数来控制整体结构。与其先构建 bagging分类器,并将其传递给决策树分类器,我们可以直接使用随机森林分类器类,这样对于决策树而言,更加方便和优化。要注意的是,回归问题同样有一个随机森林回归器与之相对应。
随机森林算法中树的增长会给模型带来额外的随机性。与决策树不同的是,每个节点被分割成最小化误差的最佳指标,在随机森林中我们选择随机选择的指标来构建最佳分割。因此,在随机森林中,仅考虑用于分割节点的随机子集,甚至可以通过在每个指标上使用随机阈值来使树更加随机,而不是如正常的决策树一样搜索最佳阈值。这个过程产生了广泛的多样性,通常可以得到更好的模型。
4.项目实施步骤
4.1理解数据
首先导入数据集并查看数据前五行
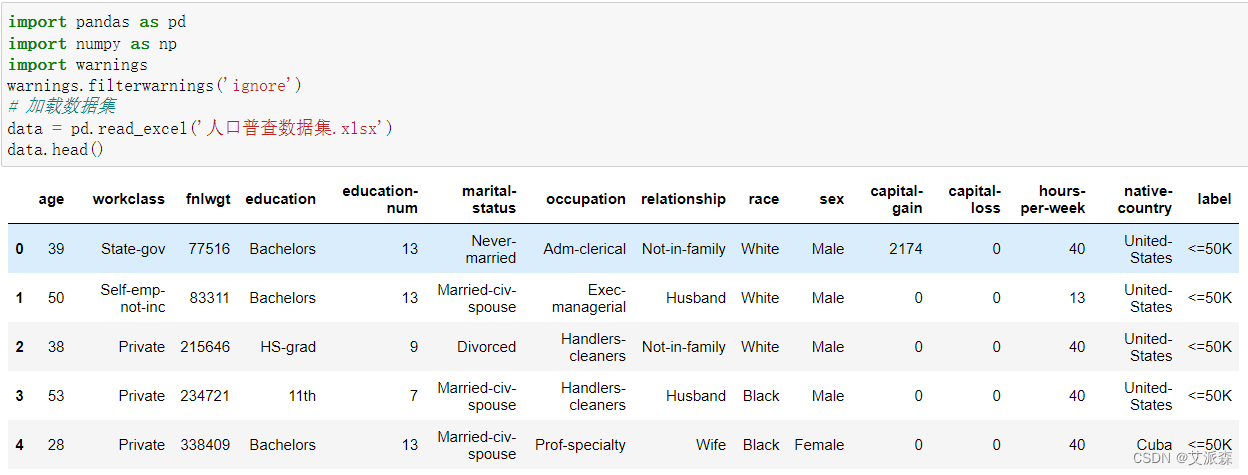
接着查看数据有多少行多少列

从结果中看出,原始数据集共有32561行,15列。
接着查看数据基本信息

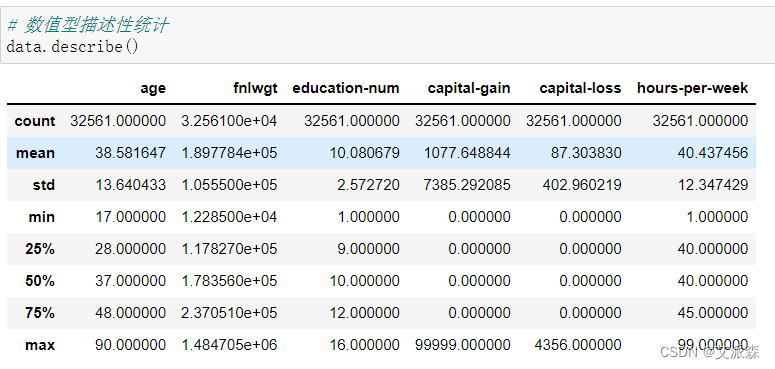
查看数值型描述性统计
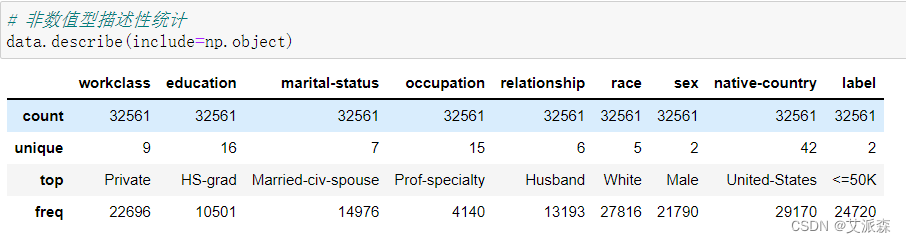
查看非数值型描述性统计
4.2探索性数据分析
对数据集中的男女比例进行可视化分析
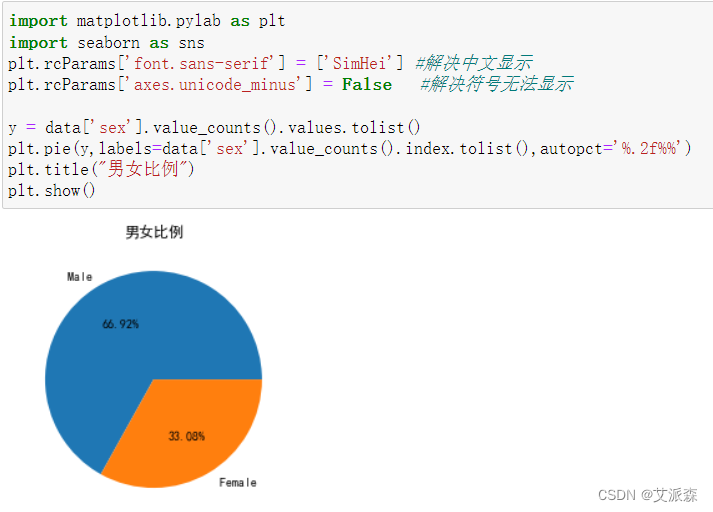
从结果看出,原始数据集中男性群体多于女性群体,说明该地区人口男女比例差距有点大。
对数据中年龄分布情况分析
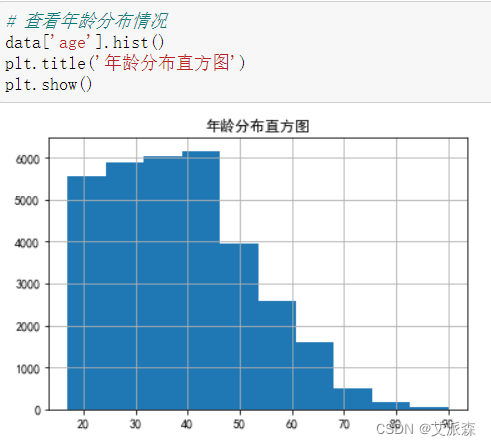
从图中看出,该地区人口主要为20-45岁之间的年轻人,说明该地区年轻人较多,经济发展比较活跃。
对数据中种族分布情况分析
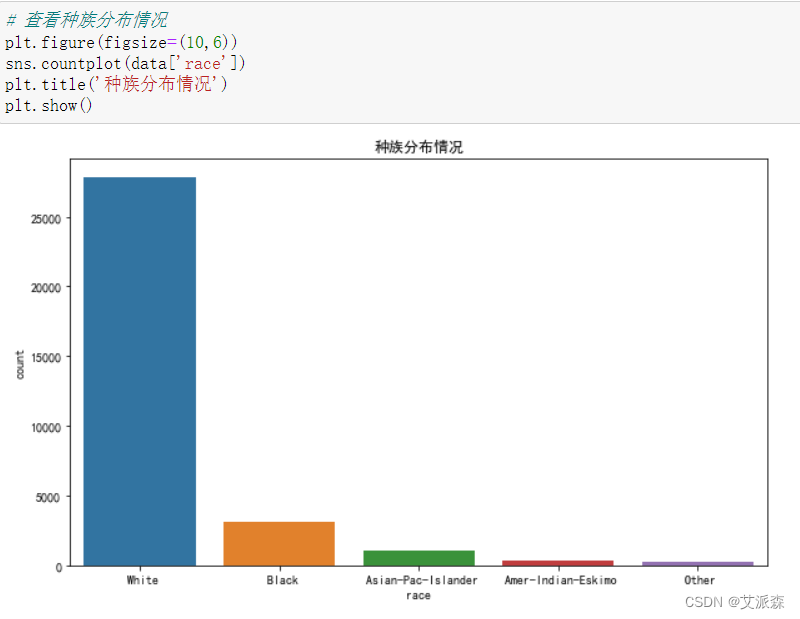
从图中看出,该地区绝大多数为白种人,其次是黑人。
查看数据标签分布
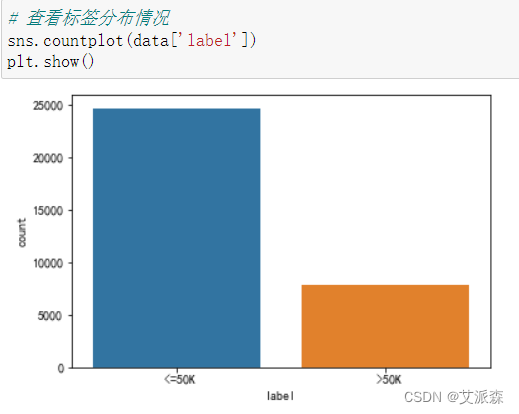
从图中看出,原始数据集中标签分布不均衡,需要进行欠采样或过采样处理。
4.3数据预处理
首先对缺失值和重复值进行删除
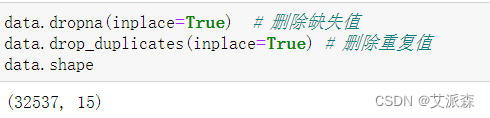
可以发现删除后的数据大小为32537行,比之前少了24条数据,说明这24条数据为异常数据。
接着对label标签进行编码处理并进行欠采样,最后得到0和1是一样大小的数据集。

最后对数据进行one-hot编码处理,将非数值型数据全部转换为数值型数据
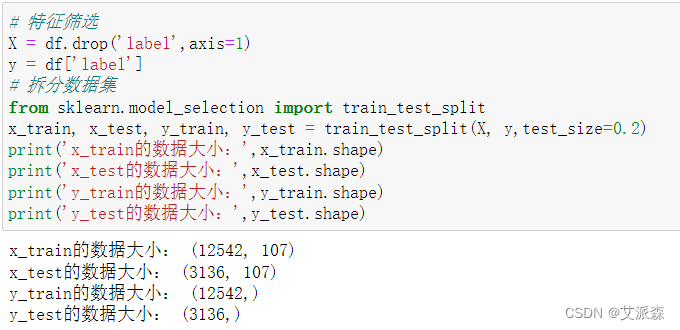
4.4特征工程
这里我们选取除了label这一列数据为特征变量,label为目标变量。接着对数据进行拆分,测试集比例为0.2。
4.5模型构建
首先构建逻辑回归模型
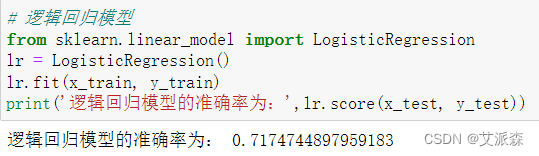
可以看出逻辑回归模型的准确率为0.71
接着构建决策树模型
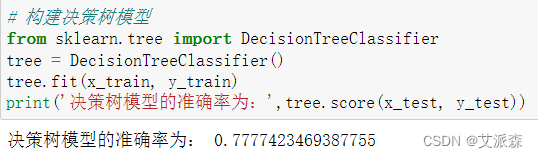
可以看出决策树模型的准确率为0.77
最后构建随机森林模型
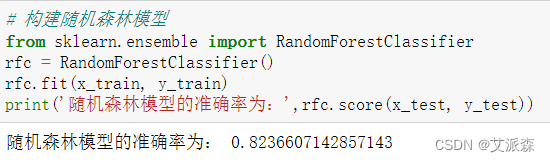
可以看出随机森林模型的准确率为0.82,比其他两个模型的准确率都高,所有应该选取随机森林作为最后的模型。
4.6模型评估
这里我们选取混淆矩阵、分类报告和ROC曲线作为模型评估指标
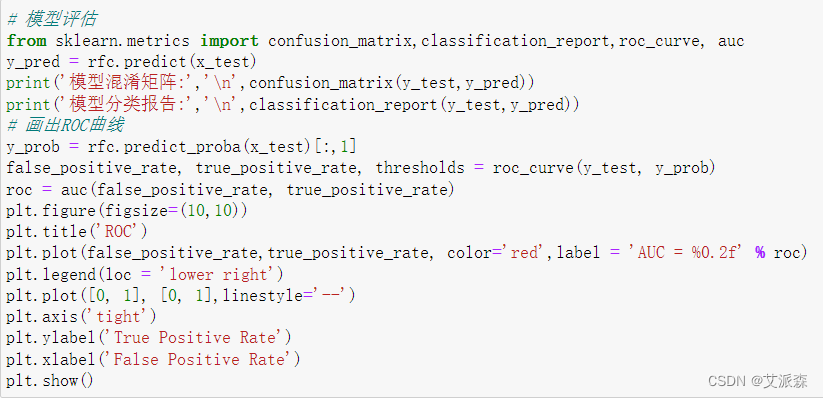
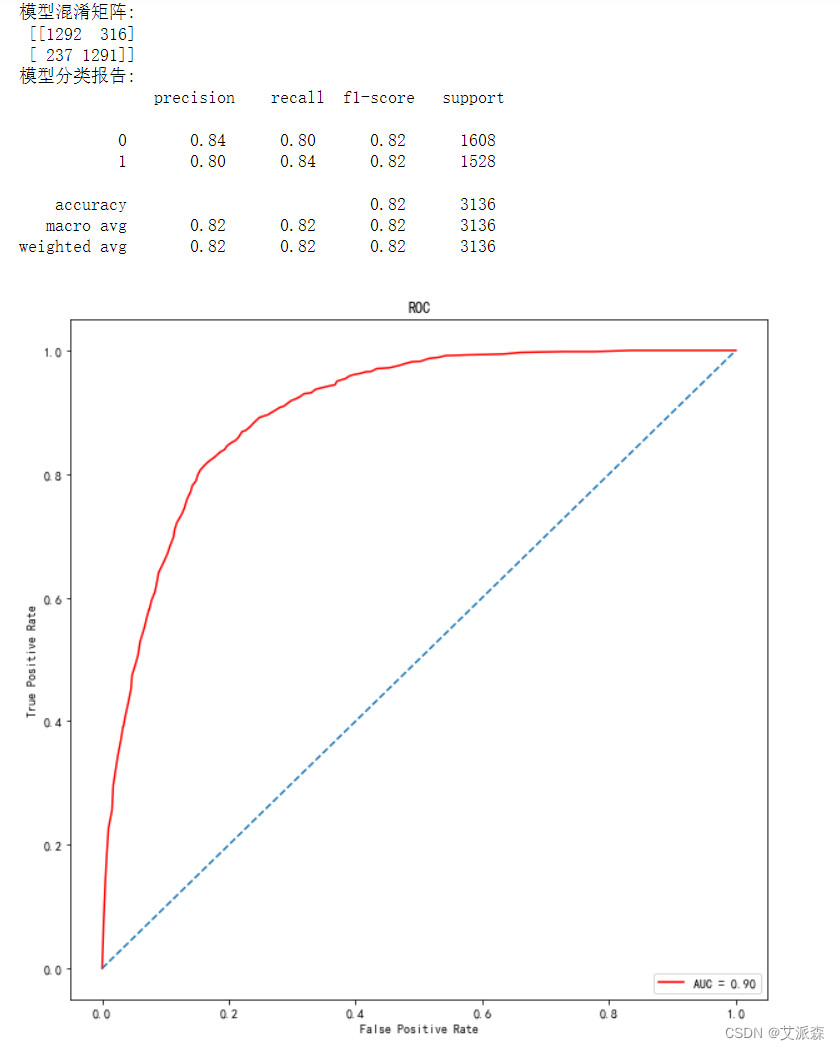
通过混淆矩阵,可看出模型在0分类上判断正确的个数为1292,判断错误的个数为316,在1分类上判断正确的个数为1291,判断错误的个数为237。从分类报告中可以看出模型在0和1分类上的精确率、召回率和F1值,最后就是画出ROC曲线得出AUC的值为0.90。
5.实验总结
通过本次人口普查数据分析,我们发现该地区的男女比例不均衡,20-45岁之间的年轻人居多,白种人为绝大多数。最后使用随机森林算法构建的薪资分类模型准确率为0.82,模型效果还不错,但是还有待提高。
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 加载数据集
data = pd.read_excel('人口普查数据集.xlsx')
data.head()
# 查看数据大小
data.shape
# 查看数据基本信息
data.info()
# 数值型描述性统计
data.describe()
# 非数值型描述性统计
data.describe(include=np.object)
import matplotlib.pylab as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
y = data['sex'].value_counts().values.tolist()
plt.pie(y,labels=data['sex'].value_counts().index.tolist(),autopct='%.2f%%')
plt.title("男女比例")
plt.show()
# 查看年龄分布情况
data['age'].hist()
plt.title('年龄分布直方图')
plt.show()
# 查看种族分布情况
plt.figure(figsize=(10,6))
sns.countplot(data['race'])
plt.title('种族分布情况')
plt.show()
# 查看标签分布情况
sns.countplot(data['label'])
plt.show()
data.dropna(inplace=True) # 删除缺失值
data.drop_duplicates(inplace=True) # 删除重复值
data.shape
# 对标签label进行编码处理
data['label'].replace(to_replace={' <=50K':0,' >50K':1},inplace=True)
# 对数据进行欠采样处理
n = len(data[data['label']==1])
new_data = pd.concat([data[data['label']==1],data[data['label']==0].sample(n)]) #数据拼接
new_data['label'].value_counts()
# 对数据进行one-hot编码处理
df = pd.get_dummies(new_data)
df.head()
# 特征筛选
X = df.drop('label',axis=1)
y = df['label']
# 拆分数据集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y,test_size=0.2)
print('x_train的数据大小:',x_train.shape)
print('x_test的数据大小:',x_test.shape)
print('y_train的数据大小:',y_train.shape)
print('y_test的数据大小:',y_test.shape)
# 逻辑回归模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(x_train, y_train)
print('逻辑回归模型的准确率为:',lr.score(x_test, y_test))
# 构建决策树模型
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
tree.fit(x_train, y_train)
print('决策树模型的准确率为:',tree.score(x_test, y_test))
# 构建随机森林模型
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(x_train, y_train)
print('随机森林模型的准确率为:',rfc.score(x_test, y_test))
# 模型评估
from sklearn.metrics import confusion_matrix,classification_report,roc_curve, auc
y_pred = rfc.predict(x_test)
print('模型混淆矩阵:','\n',confusion_matrix(y_test,y_pred))
print('模型分类报告:','\n',classification_report(y_test,y_pred))
# 画出ROC曲线
y_prob = rfc.predict_proba(x_test)[:,1]
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_prob)
roc = auc(false_positive_rate, true_positive_rate)
plt.figure(figsize=(10,10))
plt.title('ROC')
plt.plot(false_positive_rate,true_positive_rate, color='red',label = 'AUC = %0.2f' % roc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],linestyle='--')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()