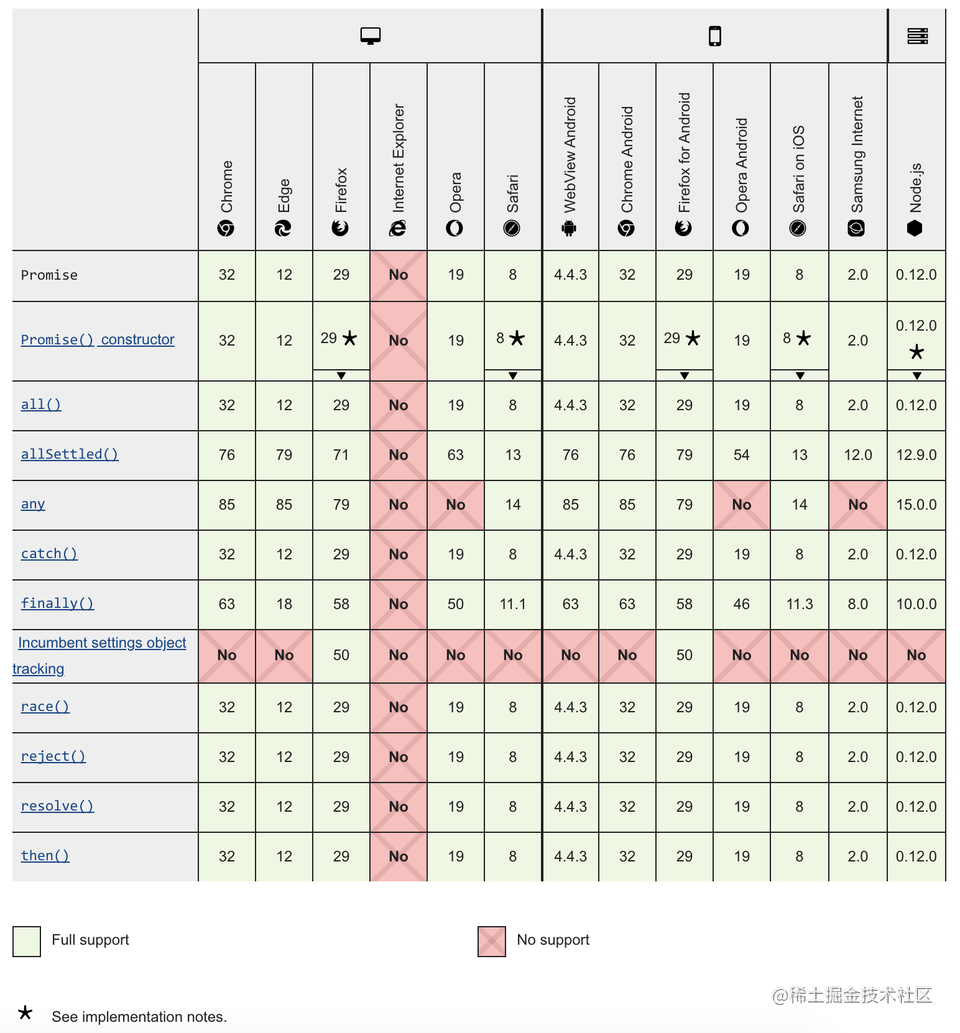
数据规模->时间复杂度
<=10^4 😮(n^2)
<=10^7:o(nlogn)
<=10^8:o(n)
10^8<=:o(logn),o(1)
内容
字符串/数组dp问题
动态规划中的双状态问题
lc 139【top100】:单词拆分
https://leetcode.cn/problems/word-break/
提示:
1 <= s.length <= 300
1 <= wordDict.length <= 1000
1 <= wordDict[i].length <= 20
s 和 wordDict[i] 仅有小写英文字母组成
wordDict 中的所有字符串 互不相同
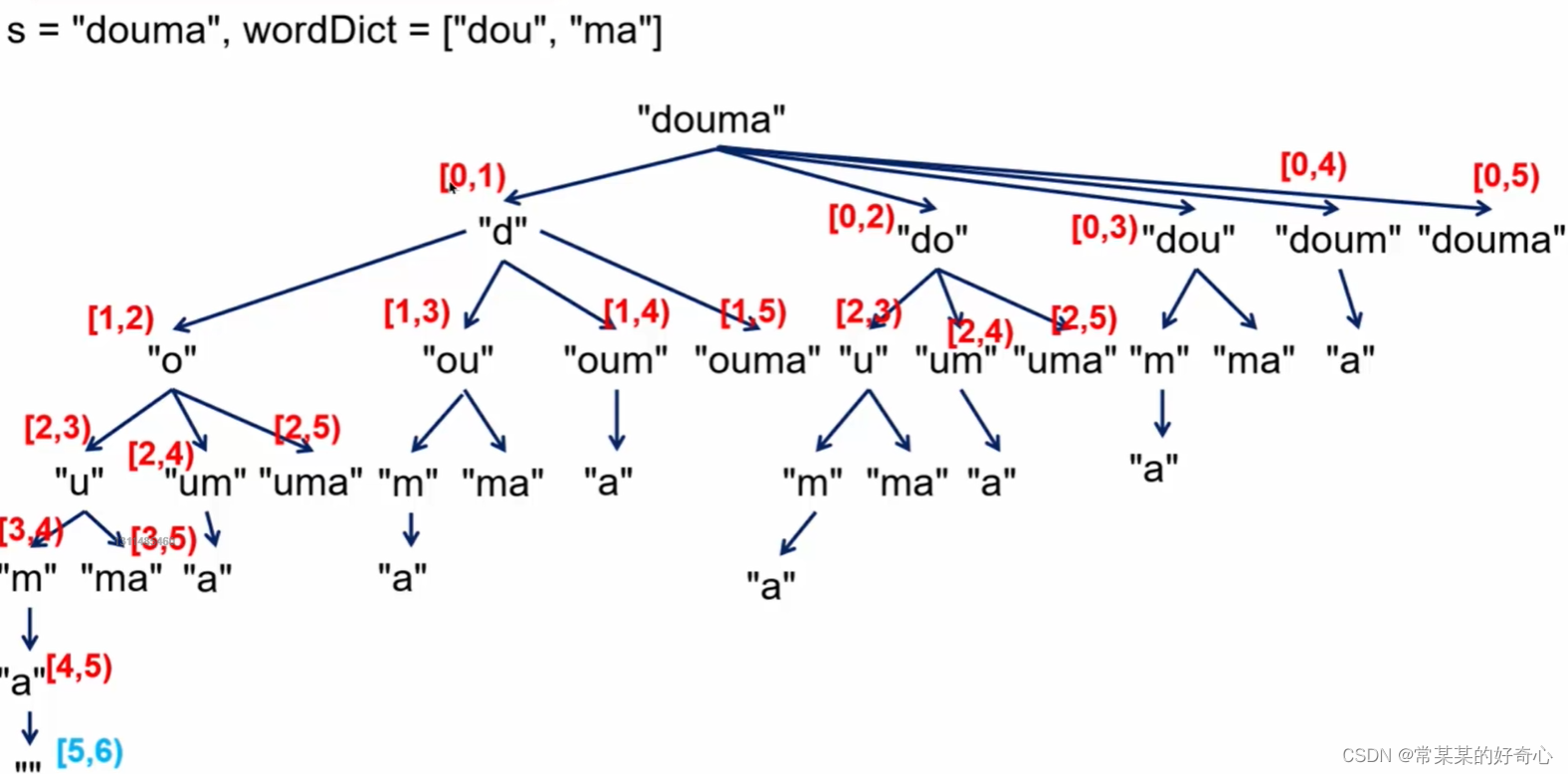
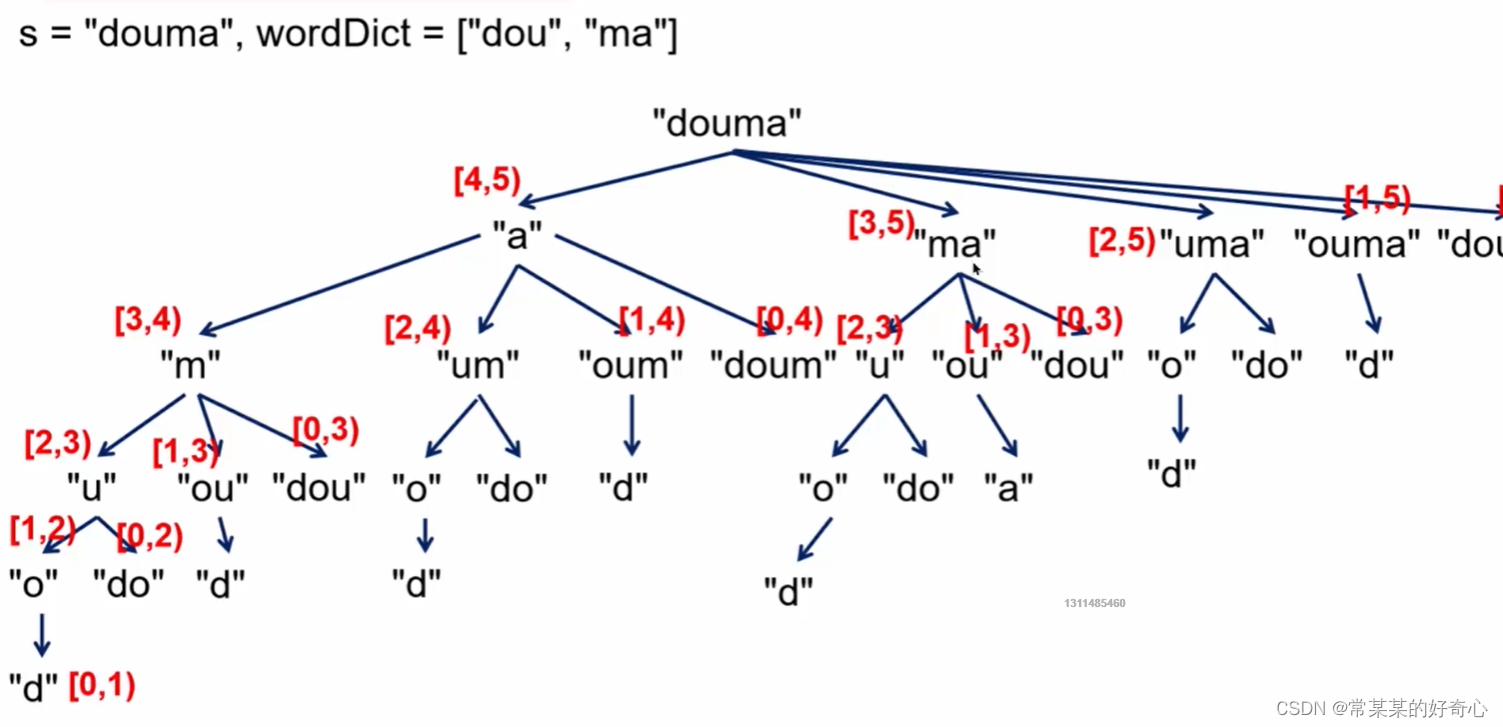
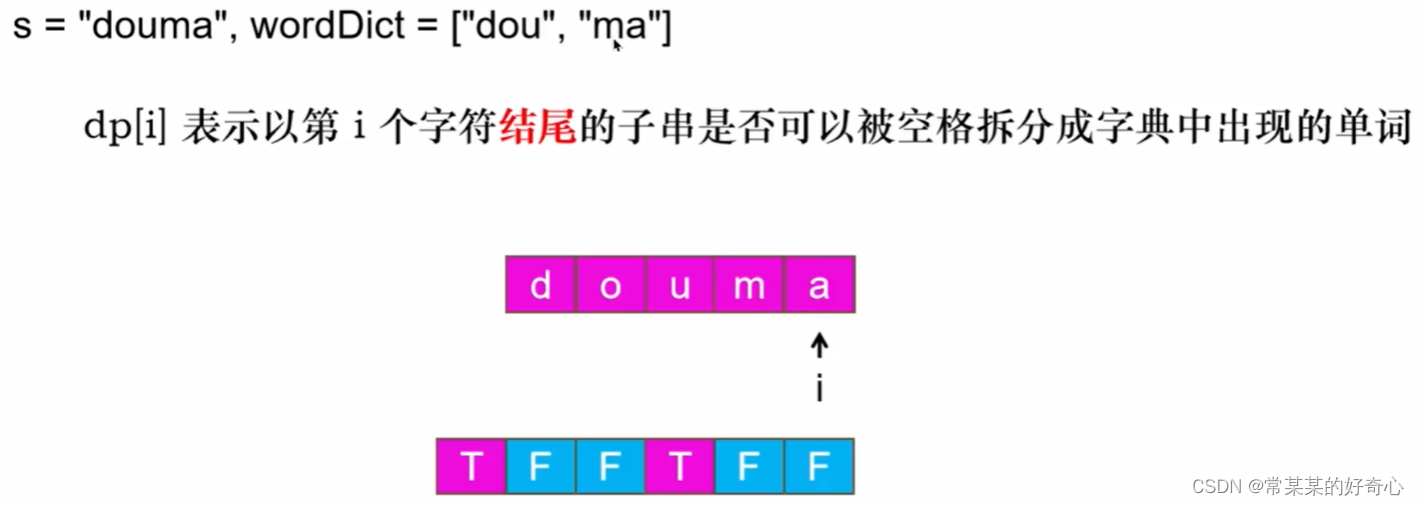
#方案一:dfs1+记忆化
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
word_dict=set(wordDict)
memo={}
#
def dfs(i):
if i==len(s):return True #[5,6),''空字符串
if i in memo:return memo[i]
#
for end in range(i+1,len(s)+1):
if s[i:end] not in word_dict:continue #剪枝
if dfs(end):
memo[i]=True
return True
memo[i]=False
return False
#
return dfs(0)
#方案二:dp1
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
word_dict=set(wordDict)
#dp[i] 表示以第 i 个字符开头的子串是否可以被空格拆分成字典中出现的单词
dp=[False]*(len(s)+1)
dp[len(s)]=True #表示''
#如果s[i, j)存在于字典中,且dp[j] == true 那么 dp[i] = true
for i in range(len(s)-1,-1,-1):#转移方向1
for j in range(i+1,len(s)+1):
if s[i:j] not in word_dict:continue
if dp[j]:dp[i]=True
return dp[0]
#方案三:dfs2+记忆化
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
word_dict=set(wordDict)
memo={}
#
def dfs(i):
if i==0:return True #[0,1) 取不到以[:0)结尾
if i in memo:return memo[i]
#
for start in range(i-1,-1,-1):
if s[start:i] not in word_dict:continue #剪枝
if dfs(start):#分支
memo[i]=True
return True
memo[i]=False
return False
#
return dfs(len(s))
#方案三:dp2
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
word_dict=set(wordDict)
dp=[False]*(len(s)+1)
dp[0]=True#''空字符串
for i in range(1,len(s)+1):#转移方向2
for j in range(i-1,-1,-1):
if s[j:i] not in word_dict:continue
if dp[j]:
dp[i]=True
return dp[len(s)]
lc 140:单词拆分 II
https://leetcode.cn/problems/word-break-ii/
提示:
1 <= s.length <= 20
1 <= wordDict.length <= 1000
1 <= wordDict[i].length <= 10
s 和 wordDict[i] 仅有小写英文字母组成
wordDict 中所有字符串都 不同
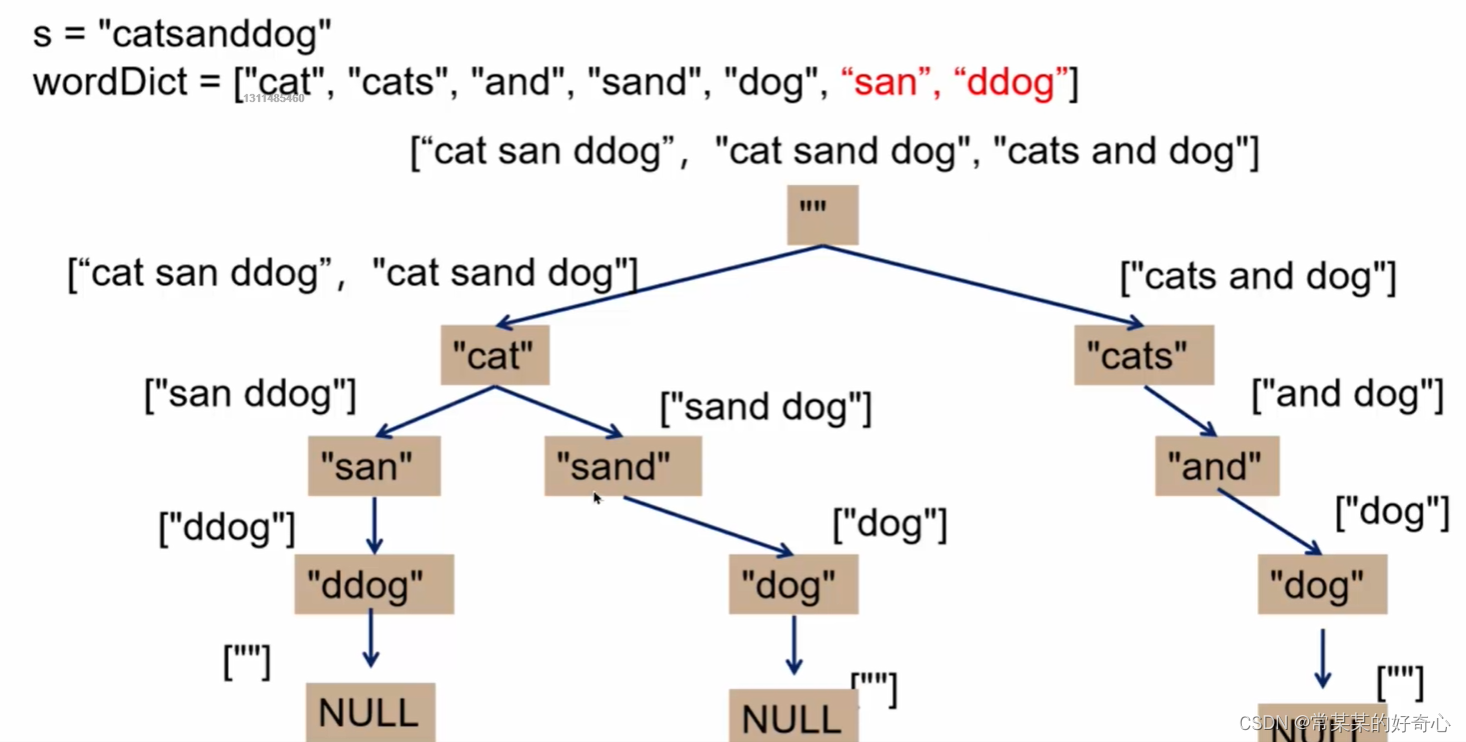
#dfs
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> List[str]:
word_dict=set(wordDict)
def dfs(i):
res=[]
if i==len(s):
res.append('')
return res
#
for end in range(i+1,len(s)+1):
if s[i:end] not in word_dict:continue
strs=dfs(end)
#
for st in strs:
split='' if st=='' else ' '
res.append(s[i:end]+split+st)#key:各单路径
return res
return dfs(0)
lc 91: 解码方法
https://leetcode.cn/problems/decode-ways/
提示:
1 <= s.length <= 100
s 只包含数字,并且可能包含前导零。
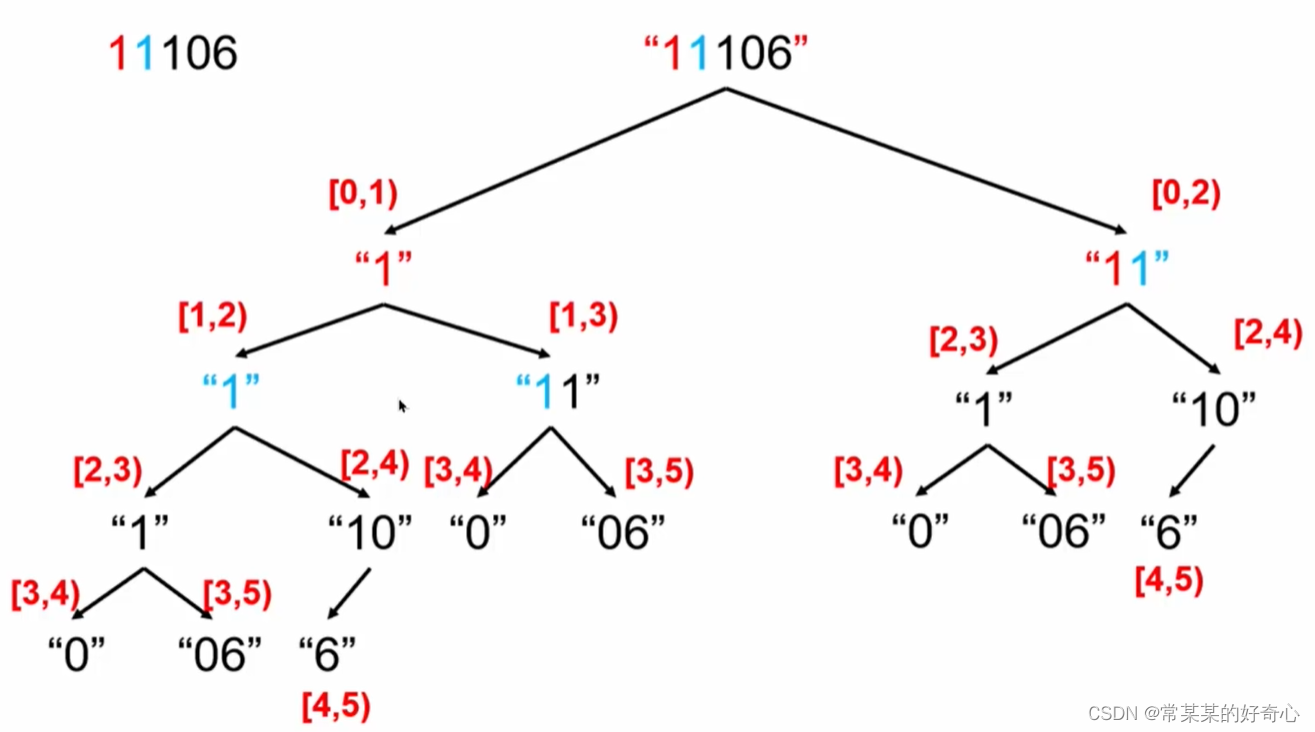
#dfs1
class Solution:
def numDecodings(self, s: str) -> int:
memo=[-1]*len(s)
def dfs(i):#以第i个字符开头的子串能解码的个数res
if i==len(s):return 1
if memo[i]!=-1:return memo[i] #取不到len(s)+1
#1)处理左子树
if s[i]=='0':return 0
res=0
res+=dfs(i+1)#end<i+1
#2)处理右子树
if i+2<=len(s):
ten=(ord(s[i])-ord('0'))*10
one=(ord(s[i+1])-ord('0'))
if one+ten<=26:
res+=dfs(i+2)
memo[i]=res
return res
return dfs(0)
#dp1
class Solution:
def numDecodings(self, s: str) -> int:
dp=[0]*(len(s)+1)
dp[len(s)]=1
#
for i in range(len(s)-1,-1,-1):
if s[i]!='0':
dp[i]+=dp[i+1]#key1
#
if i+2<=len(s):
ten=(ord(s[i])-ord('0'))*10
one=(ord(s[i+1])-ord('0'))
if one+ten<=26:
dp[i]+=dp[i+2]#key2
return dp[0]
#dfs2
#dp2
lc 32:最长有效括号【top100】
https://leetcode.cn/problems/longest-valid-parentheses/
提示:
0 <= s.length <= 3 * 10^4
s[i] 为 ‘(’ 或 ‘)’
#方案一:dp
class Solution:
def longestValidParentheses(self, s: str) -> int:
n=len(s)
if n<=1:return 0
dp=[0]*(n)
dp[0]=0
if s[0]=='(' and s[1]==')':dp[1]=2
#
res=dp[1]
for i in range(2,n):
if s[i]==')':
if s[i-1]=='(':
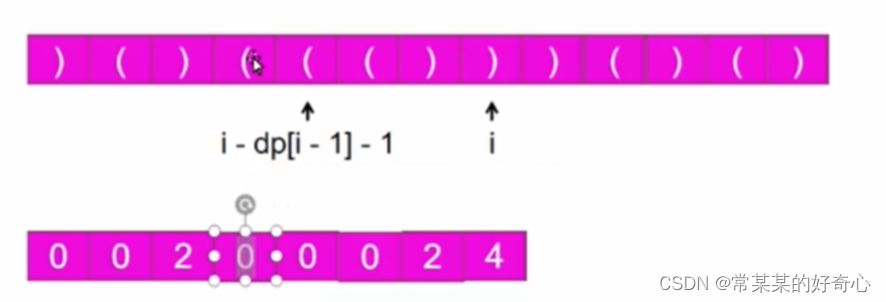
dp[i]=dp[i-2]+2#()(')'
elif i-dp[i-1]-1>=0 and s[i-dp[i-1]-1]=='(':#()(()')'
dp[i]=dp[i-1]+2+(dp[i-dp[i-1]-2] if i-dp[i-1]-2>=0 else 0)
res=max(res,dp[i])
return res
#方案二:栈
class Solution:
def longestValidParentheses(self, s: str) -> int:
n=len(s)
if n<=1:return 0
stack=deque()#或者用[]
#
res=0
stack.append(-1)
for i in range(n):
if s[i]=='(':stack.append(i)
elif s[i]==')':
stack.pop()
if not stack:stack.append(i)
else:
res=max(res,i-stack[-1])
return res
#方案三:双变量(最优空间)
#o(n),o(1)
class Solution:
def longestValidParentheses(self, s: str) -> int:
n=len(s)
if n<=1:return 0
#
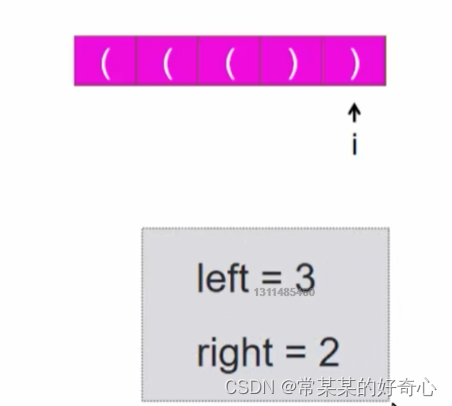
res=left=right=0
for i in range(n):
if s[i]=='(':left+=1
else:right+=1
#
if left==right:res=max(res,2*left)
elif left<right:left=right=0
left=right=0
for i in range(n-1,-1,-1):
if s[i]=='(':left+=1
else:right+=1
#
if left==right:res=max(res,2*left)
elif left>right:left=right=0
#
return res
lc 10【剑指 19】【top100】:正则表达式匹配
https://leetcode.cn/problems/regular-expression-matching/
提示:
1 <= s.length <= 20
1 <= p.length <= 30
s 只包含从 a-z 的小写字母。
p 只包含从 a-z 的小写字母,以及字符 . 和 *。
保证每次出现字符 * 时,前面都匹配到有效的字符
class Solution:
def isMatch(self, s: str, p: str) -> bool:
m,n=len(s),len(p)
dp=[[False]*(n+1) for _ in range(m+1)]
dp[0][0]=True
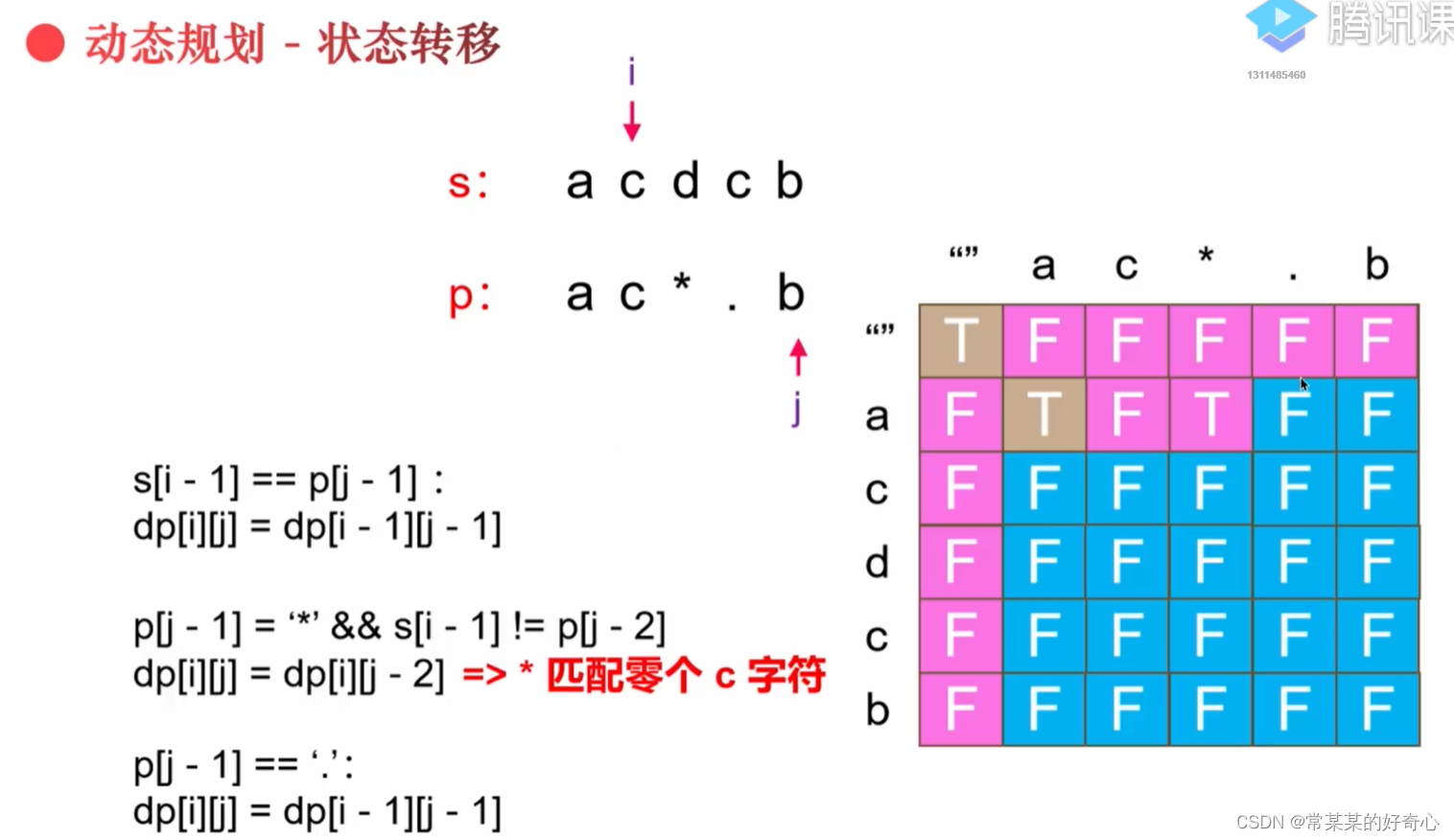
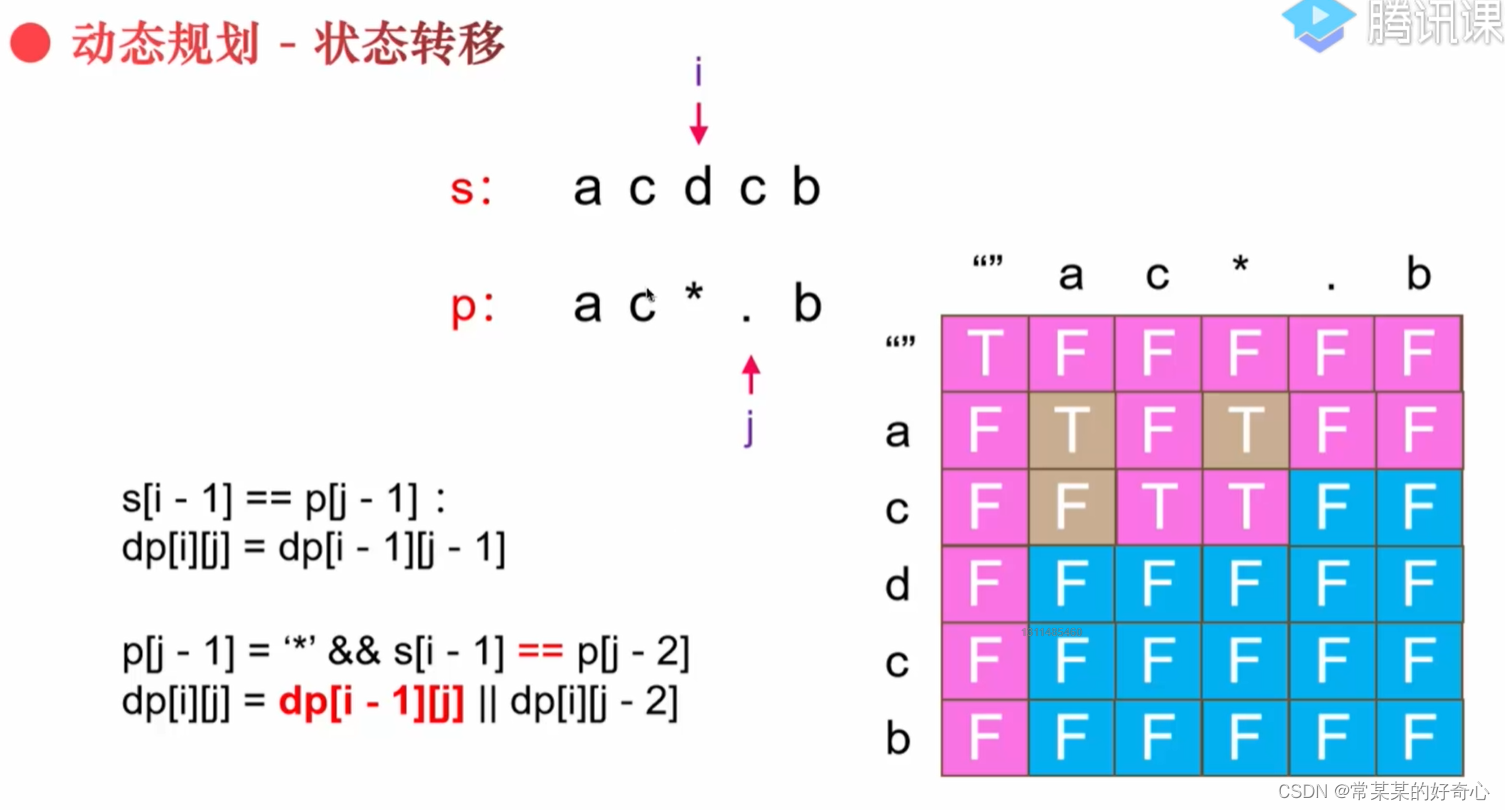
for j in range(1,n+1):
if p[j-1]=='*' and (j<=2 or dp[0][j-2]):#"aa""a*"
dp[0][j]=True
#
for i in range(1,m+1):
for j in range(1,n+1):
if s[i-1]==p[j-1] or p[j-1]=='.':
dp[i][j]=dp[i-1][j-1]
elif p[j-1]=='*':
if s[i-1]==p[j-2] or p[j-2]=='.':#注意".*"的情况
dp[i][j]=dp[i][j-2] or dp[i-1][j]
else:
dp[i][j]=dp[i][j-2]
return dp[m][n]
lc 718:最长重复子数组
https://leetcode.cn/problems/maximum-length-of-repeated-subarray/
提示:
1 <= nums1.length, nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 100
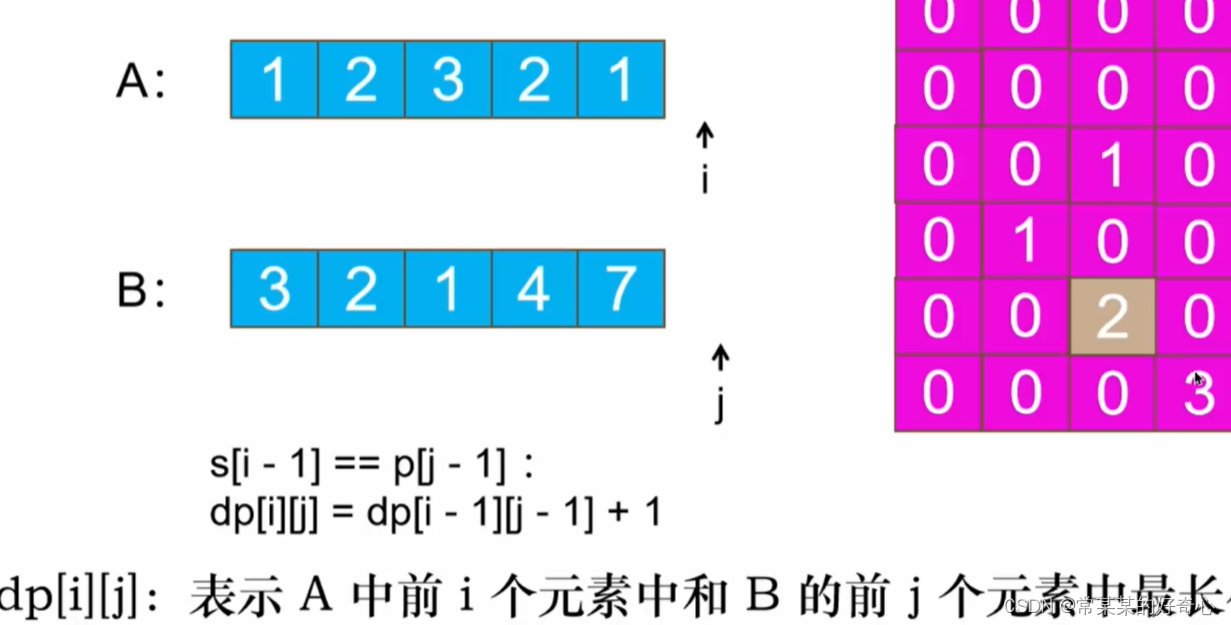
class Solution:
def findLength(self, nums1: List[int], nums2: List[int]) -> int:
m,n=len(nums1),len(nums2)
dp=[[0]*(n+1) for _ in range(m+1)]
res=0
for i in range(1,m+1):
for j in range(1,n+1):
if nums1[i-1]==nums2[j-1]:
dp[i][j]=dp[i-1][j-1]+1
res=max(res,dp[i][j])
return res
lc 354:俄罗斯套娃信封问题
https://leetcode.cn/problems/russian-doll-envelopes/
提示:
1 <= envelopes.length <= 10^5
envelopes[i].length == 2
1 <= wi, hi <= 10^5
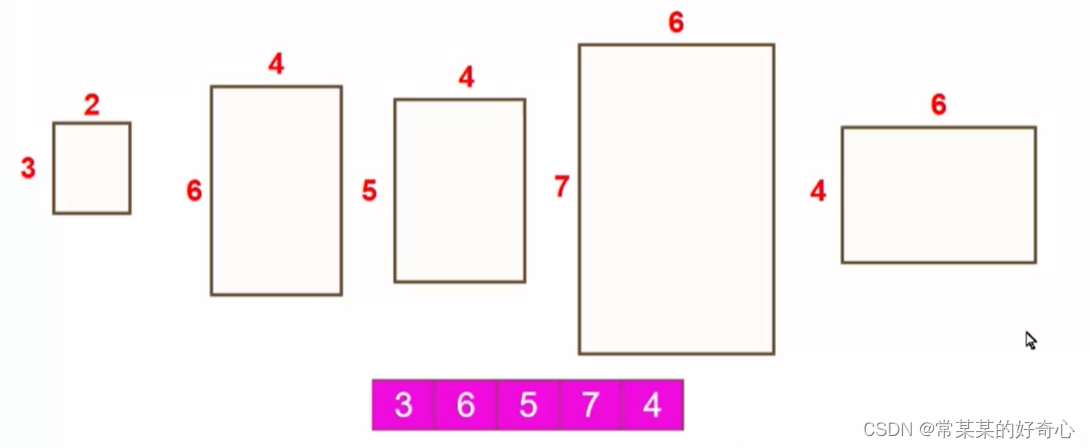
#dp:o(n^2)超时
#二分法:o(nlogn)
#当另一个信封的宽度和高度都比这个信封大的时候
class Solution:
def maxEnvelopes(self, envelopes: List[List[int]]) -> int:
m=len(envelopes)
envelopes.sort(key=lambda x:(x[0],-x[1]))#key1:宽度递增,高度递减(防止同高度信封的多次利用)
#
res=[]#res用于存储所有可套娃信封的高度值
res.append(envelopes[0][1])
#key2
for i in range(1,m):
curr_hi=envelopes[i][1]
if curr_hi>res[-1]:
res.append(curr_hi)
else:#有益于增加总套数
index=bisect.bisect_left(res,curr_hi)#加入同宽度,次高度的信封
res[index]=curr_hi
return len(res)
lc 152【top100】:乘积最大子数组
https://leetcode.cn/problems/maximum-product-subarray/
提示:
1 <= nums.length <= 2 * 10^4
-10 <= nums[i] <= 10
nums 的任何前缀或后缀的乘积都 保证 是一个 32-位 整数

#dp
class Solution:
def maxProduct(self, nums: List[int]) -> int:
m=len(nums)
dp_max=[0]*m
dp_min=[0]*m
#
dp_min[0]=dp_max[0]=res=nums[0]
for i in range(1,m):
dp_max[i]=max(dp_max[i-1]*nums[i],max(nums[i],dp_min[i-1]*nums[i]))
dp_min[i]=min(dp_min[i-1]*nums[i],min(nums[i],dp_max[i-1]*nums[i]))
res=max(res,dp_max[i])
#
return res
lc 376:摆动序列
https://leetcode.cn/problems/wiggle-subsequence/
提示:
1 <= nums.length <= 1000
0 <= nums[i] <= 1000
进阶:
你能否用 O(n) 时间复杂度完成此题?
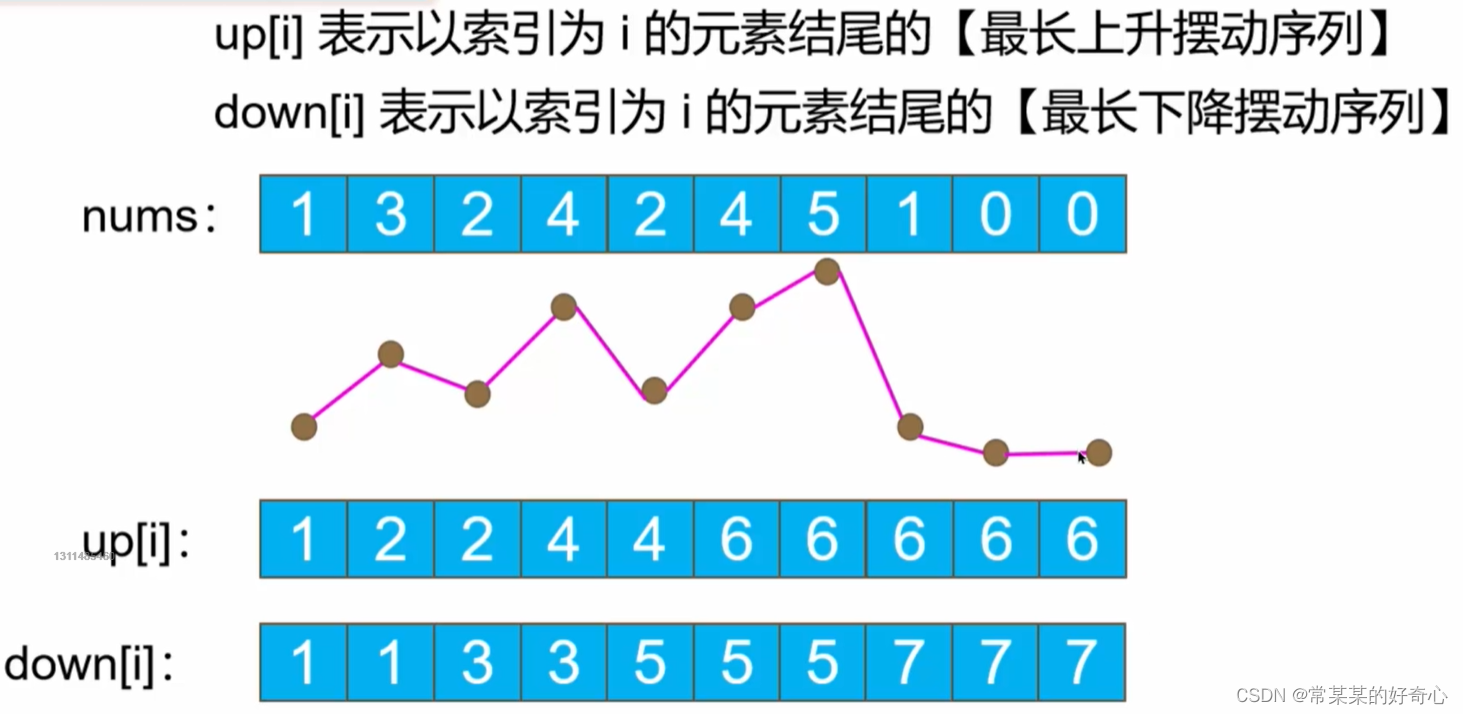
#方案一:dp
class Solution:
def wiggleMaxLength(self, nums: List[int]) -> int:
n=len(nums)
if n<2:return n
#
up,down=[0]*n,[0]*n#注意up=down=[0]*n,地址一直,写法错误
up[0]=down[0]=1
for i in range(1,n):
if nums[i]>nums[i-1]:
down[i]=down[i-1]
up[i]=down[i-1]+1
elif nums[i]<nums[i-1]:
up[i]=up[i-1]
down[i]=up[i]+1
else:
down[i]=down[i-1]
up[i]=up[i-1]
return max(up[n-1],down[n-1])
#方案二:dp+压缩
class Solution:
def wiggleMaxLength(self, nums: List[int]) -> int:
n=len(nums)
if n<2:return n
#
up=down=1
for i in range(1,n):
if nums[i]>nums[i-1]:
up=down+1
elif nums[i]<nums[i-1]:
down=up+1
return max(up,down)