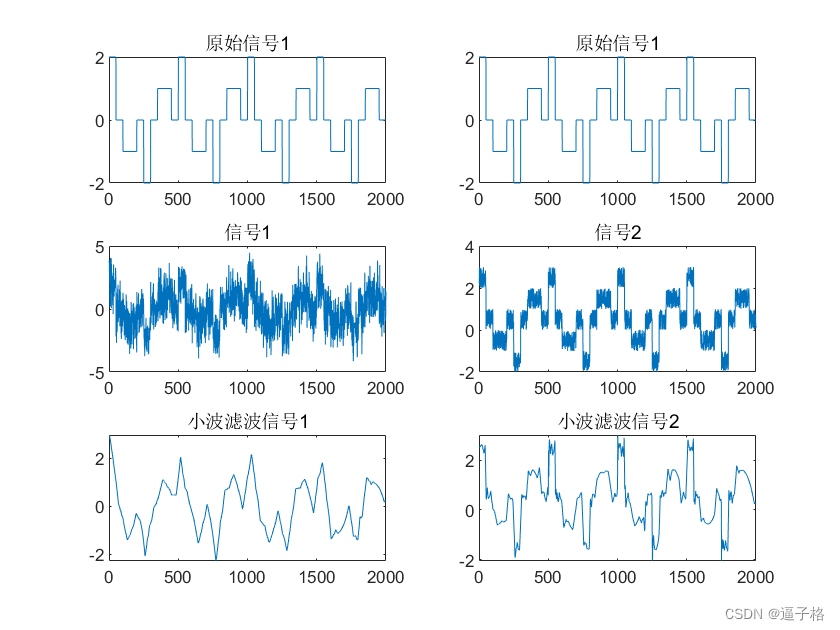
大型视觉-语言模型(LVLM)在图像字幕和视觉问答(VQA)等任务中表现出色。然而,受限于分辨率,这些模型在处理包含细微视觉内容的图像时面临挑战。
分辨率的限制严重阻碍了模型处理含有丰富细节的图像的能力。例如,在理解图表、表格和文档等类型的视觉内容时,细节的清晰度对于准确解读和生成语言描述至关重要。然而,当图像的分辨率不足时,这些细微的视觉信息可能会丢失,导致模型无法准确地捕捉和学习图像中的关键细节。
现有模型通常只能在一个预先设定的分辨率范围内工作,这限制了它们的适用性和灵活性。在现实世界的应用场景中,需要处理的图像分辨率千差万别,从低分辨率的缩略图到高分辨率的专业图像都有。如果模型不能适应不同分辨率的输入,就无法满足多样化的业务需求,也无法在更广泛的视觉任务中发挥作用。
固定分辨率的处理方式也意味着在面对超高清图像时,模型可能需要对输入图像进行压缩,从而丢失重要的视觉信息,或者在处理低分辨率图像时,模型的计算资源没有得到充分利用。
InternLM-XComposer2-4KHD模型正是在这样的背景下应运而生,它通过一系列创新的技术手段,显著提升了LVLM在高分辨率图像处理方面的能力。
方法
模型架构设计

InternLM-XComposer2-4KHD模型的架构设计是其高性能的关键因素之一。该模型的架构建立在InternLM-XComposer2的基础之上,进行了针对性的扩展和改进,以支持高达4K HD分辨率的图像处理。包括以下三个核心组成部分:
轻量级视觉编码器:OpenAI ViT-Large/14
视觉编码器的作用是将输入的图像转换为模型能够理解的特征表示。InternLM-XComposer2-4KHD使用了OpenAI的ViT-Large/14作为其视觉编码器。ViT,即Vision Transformer,是一种基于Transformer架构的视觉模型,它通过将图像分割成一系列的小块(patches),然后将这些小块线性嵌入到一个高维空间中,从而实现对图像的有效编码。ViT-Large/14表示使用了14层Transformer结构的较大型号ViT,这为模型提供了强大的视觉特征提取能力。
大语言模型:InternLM2-7B
语言模型是处理和生成文本的核心组件。InternLM-XComposer2-4KHD采用了InternLM2-7B作为其语言模型,这是一个拥有7亿参数的大型Transformer模型。这个模型不仅能够捕捉到语言的复杂结构和语义,还能够支持多模态任务中的文本生成和理解。通过与视觉编码器的输出相结合,InternLM2-7B能够提供对图像内容的深入理解和准确的语言描述。
部分LoRA对齐:特征对齐
为了实现视觉编码器和语言模型之间的有效对齐,InternLM-XComposer2-4KHD引入了部分LoRA(Low-Rank Adaptation)技术。LoRA是一种参数效率的适配方法,它通过对模型的一小部分参数进行调整,而不是对整个模型进行训练,从而实现对模型的优化。在InternLM-XComposer2-4KHD中,LoRA技术被用来对齐视觉特征和语言特征,确保了两种模态之间的信息能够有效地交互和整合。
这三个组件共同构成了InternLM-XComposer2-4KHD的架构,使其能够处理高分辨率的图像,并在多种视觉-语言任务中表现出色。通过这种设计,模型不仅能够理解和生成与图像内容紧密相关的语言描述,还能够在保持计算效率的同时,处理比以往任何模型都要高分辨率的图像输入。
动态图像分割策略
为了解决高分辨率图像的处理问题,该模型采用了动态图像分割策略。这一策略允许模型接收不同分辨率的图像输入,并能够根据图像的最大补丁数H动态调整图像的分割方式。具体来说,输入图像被调整并填充到一个以336×336大小为单位的网格中,同时保持图像的原始宽高比。这一过程确保了图像的细节信息不会因为固定的输入尺寸而丢失。
预训练阶段
在预训练阶段,模型使用了三种不同目标的数据集,以增强模型在一般语义对齐、世界知识对齐和视觉能力方面的性能。预训练使用了OpenAI CLIP ViT-L-14-336作为视觉编码器,并采用了动态图像分割策略中的‘HD-25’设置,以此来处理高分辨率的图像输入。
预训练过程涉及将图像分割成多个小块,并从每个块中提取特征。这些特征随后被合并,并与语言模型的输出相结合。训练过程中,模型学习将视觉特征与相应的文本描述相匹配,以此来理解图像内容及其对应的语言表述。
4KHD监督微调
在预训练之后,模型通过4KHD监督微调进一步增强了对高分辨率图像的理解能力。这一步骤特别针对OCR相关任务,这些任务对文本的清晰度和细节有更高的要求。微调过程中,模型采用了混合分辨率训练策略,对于需要极高分辨率的任务,如高清OCR问答,模型会使用‘HD-55’设置来输入4K(3840×1600)分辨率的图像。而对于其他任务,模型则采用了动态分辨率策略,以增强对输入分辨率变化的鲁棒性。
创新点说明
InternLM-XComposer2-4KHD模型的创新之处在于其对高分辨率图像的处理能力、动态分辨率适应性以及全局-局部格式的理解方法。这些创新点共同推动了大型视觉-语言模型(LVLM)在图像理解方面的进步,特别是在处理高分辨率和结构化图像的任务中。
模型的高分辨率处理能力是其最显著的创新之一。InternLM-XComposer2-4KHD能够处理高达4K HD分辨率的图像,这在当时的LVLM中是前所未有的。与只能处理较低分辨率图像的现有模型相比,该模型可以捕捉到更多的视觉细节,这对于理解图像中的复杂场景和细微元素至关重要。这种处理能力使得模型在高清OCR任务、详细文档扫描和复杂图表理解等方面具有显著优势。
模型采用了动态分辨率技术,可以根据输入图像的尺寸和宽高比,自动调整图像的分割方式。这种自适应分辨率的能力,使得模型可以灵活地处理不同分辨率的图像,而不需要对每种分辨率进行单独的训练或调整。此外,模型还能够自动配置补丁的数量和布局,这是通过在预训练的Vision Transformer(ViT)基础上进行的,ViT能够根据图像的内容和结构,动态地调整补丁的划分,从而优化模型对图像特征的提取。
模型引入了全局-局部格式的理解方法,这在处理结构化图像方面尤为重要。全局视图允许模型首先获取图像的整体上下文信息,而局部视图则使得模型能够分别处理图像的各个部分。通过动态图像分割策略,模型将图像分割成多个小块(patches),并分别提取每个小块的特征。这种结合全局和局部信息的方法,使得模型能够更全面地理解图像的结构和内容,特别是在理解文档、图表和表格等结构化图像时,这种方法显示出了其独特的优势。
实验结果
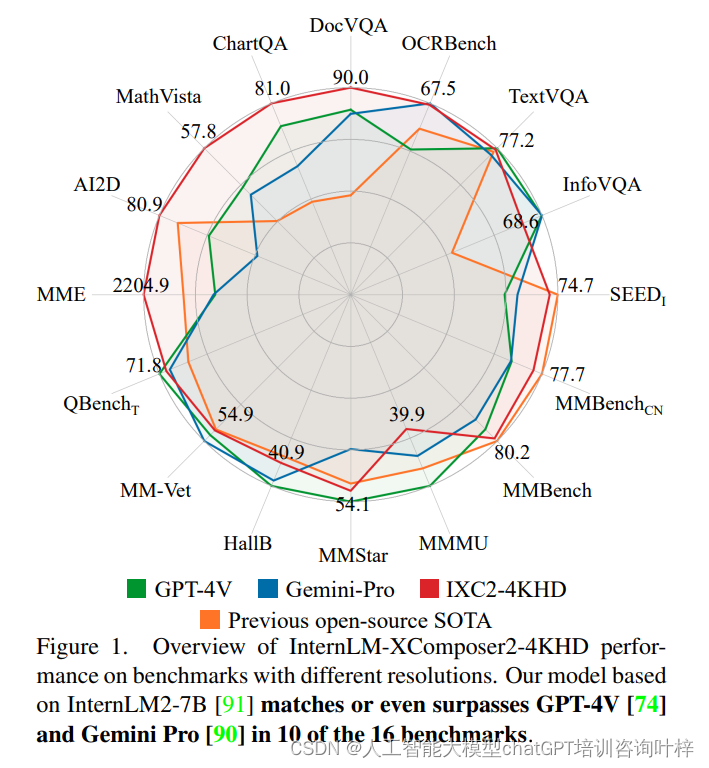
实验结果显示,InternLM-XComposer2-4KHD在10个基准测试中的表现达到了或超过了GPT4V和Gemini Pro。这一结果证明了InternLM-XComposer2-4KHD在处理高分辨率图像方面的显著优势。尤其是在高清OCR任务中,模型展现出了卓越的性能,这归功于其能够处理高达4K分辨率图像的能力。
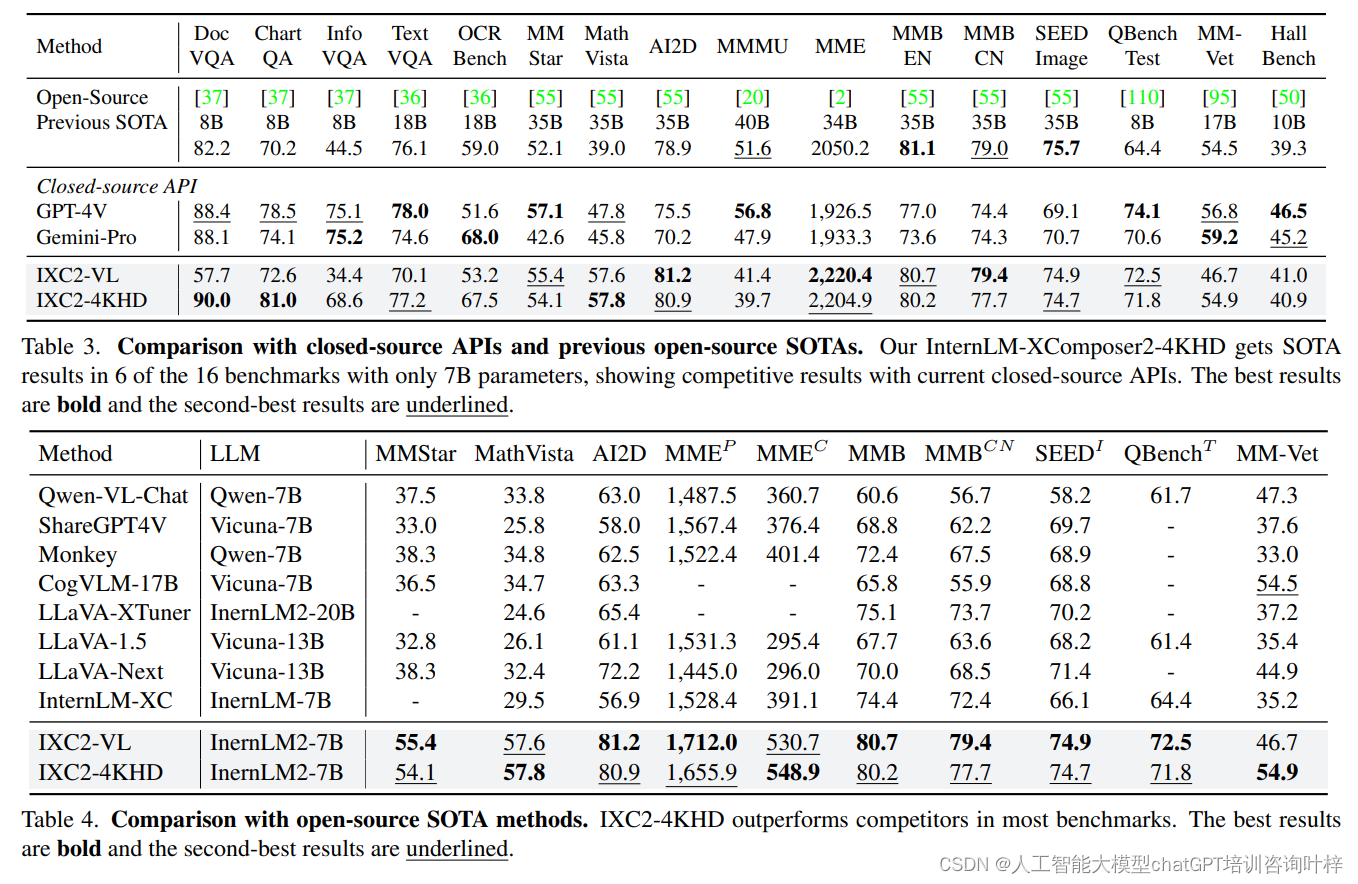
InternLM-XComposer2-4KHD与闭源API和先前开源SOTA模型的比较显示,InternLM-XComposer2-4KHD在多个基准测试中取得了SOTA结果,尤其是在DocVQA和ChartQA上,其性能超过了GPT-4V和Gemini-Pro。与开源SOTA方法进行了比较,显示了InternLM-XComposer2-4KHD在大多数基准测试中的优越性能。
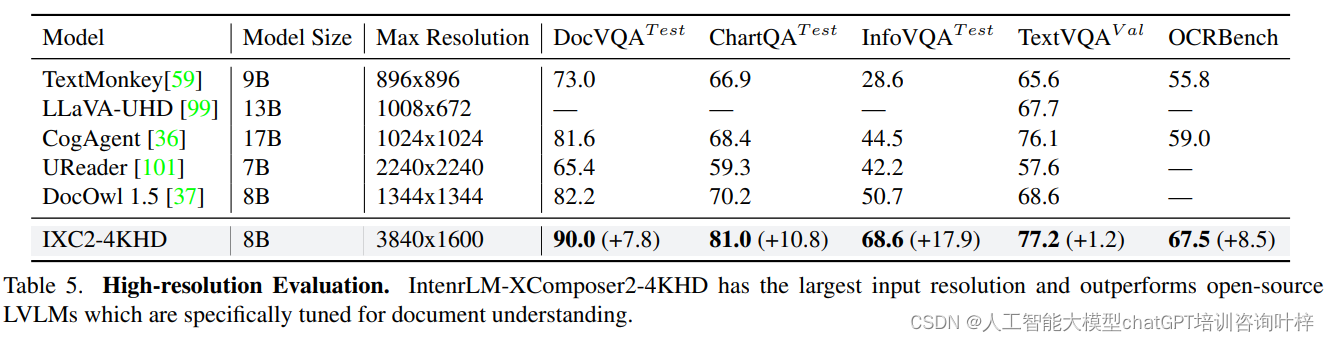
高分辨率任务的性能评估展示了InternLM-XComposer2-4KHD在处理高分辨率图像方面的显著优势,尤其是在OCR相关任务上。
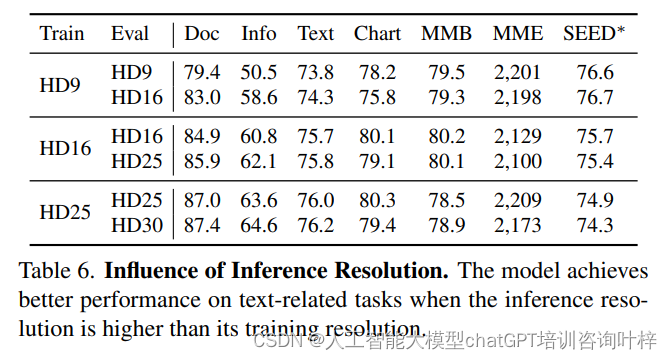
当推理时使用的图像分辨率高于训练时使用的分辨率时,模型在处理文本相关任务时的性能有所提升。例如,在InfographicVQA任务中,当从HD9(较低分辨率)切换到HD16(较高分辨率)进行推理时,模型的性能提升了8.1%,而无需额外的训练。这一发现指出,即使在训练阶段未达到最高分辨率,通过在推理阶段提高图像分辨率,模型仍能够更好地捕捉图像中的文本信息,从而提高其对文本的理解能力。
全局视图对于模型在多个基准测试中的性能至关重要。当全局视图被移除时,模型在所有基准测试中的表现都有所下降,例如在MMBench EN-Test中的性能下降了4.4%。这表明全局视图为模型提供了一个整体的图像上下文,有助于模型更好地理解和解释图像内容。

论文链接:https://arxiv.org/abs/2404.06512
Github 地址:https://github.com/InternLM/InternLM-XComposer