与基于寄存器的指令集架构相比,基于栈的指令集架构不依赖于硬件,因此可移植性更好,跨平台性更好 因为栈结构的特性,永远都是先处理栈顶的第一条指令,因此大部分指令都是零地址指令,所以指令集更小 虽然指令集更小,但是同样的一步操作,比基于寄存器所需的指令更多,性能也相对慢 public class Demo01 {
private void test1 ( ) {
int i = 10 ;
i = ++ i;
}
}
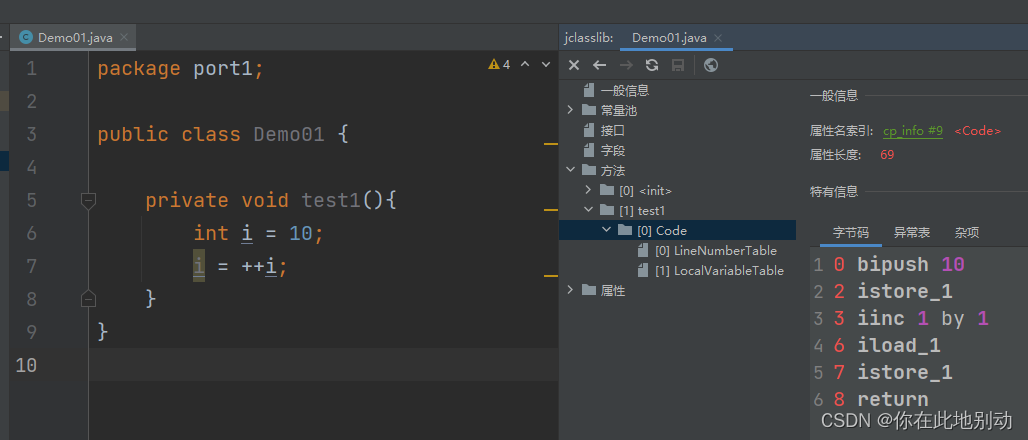
根据加号在前就等于“先加加再带入计算”的常识,i的结果必然是11 现在再从指令来看到底是经历了什么样的操作才变成了11:
0 bipush 10 -- 将10 压入操作数栈
2 istore_1 -- 将栈顶数字10 存入局部变量表索引为1 的位置(索引为0 的位置放的是this )
3 iinc 1 by 1 -- * * * 将局部变量表中索引为1 的位置的数(也就是10 )直接加1 * * *
6 iload_1 -- * * * 将局部变量表中索引为1 的位置的数(现在是11 )压入操作数栈 * * *
7 istore_1 -- * * * 将栈顶数字11 存入局部变量表索引为1 的位置 * * *
8 return -- 返回11
public class Demo01 {
private void test1 ( ) {
int i = 10 ;
i = i++ ;
}
}
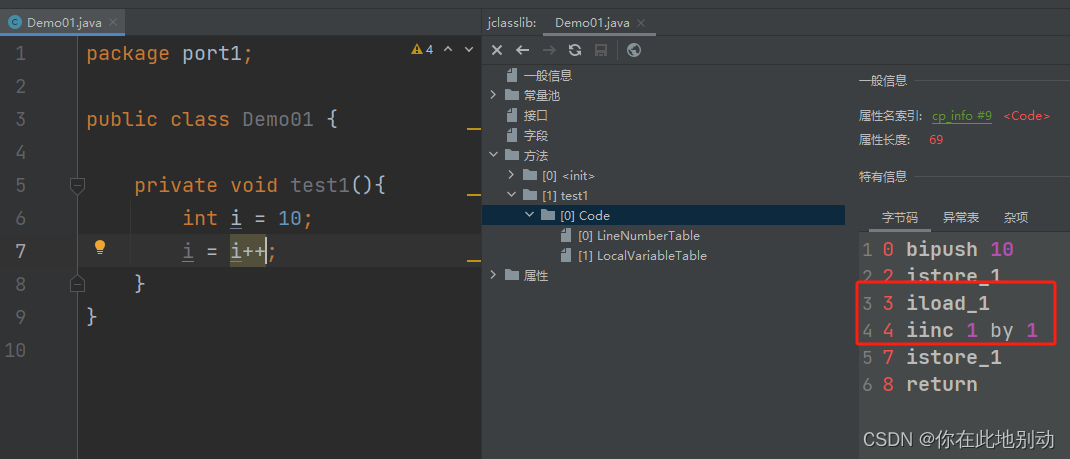
根据加号在后就等于“先带入计算再加加”的常识,i的结果必然是10 现在再从指令来看到底是经历了什么样的操作才变成了10:
0 bipush 10 -- 将10 压入操作数栈
2 istore_1 -- 将栈顶数字10 存入局部变量表索引为1 的位置(索引为0 的位置放的是this )
3 iload_1 -- * * * 将局部变量表中索引为1 的位置的数(现在是10 )压入操作数栈 * * *
4 iinc 1 by 1 -- * * * 将局部变量表中索引为1 的位置的数(也就是10 )直接加1 * * *
7 istore_1 -- * * * 将栈顶数字10 存入局部变量表索引为1 的位置 * * *
8 return -- 返回10
最主要的区别就是图片的红框处以及解释中的星号标注处,i++的时候,读入操作数栈的是没有进行加1的值,而++i的时候,读入操作数栈的是加过1的值 ++i的时候是先把局部变量表中的10加成了11,然后把11读取到操作数栈,然后再覆盖回局部变量表,所以最后返回了11i++的时候是把10读取到了操作数栈,然后把局部变量表中的10加成了11,但是下一步又用操作数栈的10 覆盖了局部变量表中的11,所以最后返回了10