import os
import fiftyone as fo
import fiftyone.zoo as foz
import yaml
classes = [
'Person', # 人 - 0
'Car', # 轿车 - 1
'Taxi', # 出租车 - 2
'Ambulance', # 救护车 - 3
'Bus', # 公共汽车 - 4
'Bicycle', # 自行车 - 5
'Motorcycle', # 摩托车 - 6
'Dog', # 狗 - 7
'Cat', # 猫 - 8
'Mouse', # 老鼠 - 9
'Backpack', # 背包 - 10
'Glasses', # 眼镜 - 11
'Hat', # 帽子 - 12
'Helmet', # 头盔 - 13
'Traffic light', # 交通信号灯 - 14
'Knife', # 刀 - 15
'Mobile phone', # 移动电话 - 16
'Umbrella' # 伞 - 17
# 手持物 - 18
# 烟雾 - 19
# 火焰 - 20
]
# 构建类别索引映射
class_to_index = {cls: idx for idx, cls in enumerate(classes)}
def filter_samples_by_label(dataset, target_label):
# 创建一个新数据集来保存筛选后的样本
filtered_dataset = fo.Dataset()
# 遍历原数据集
for sample in dataset:
# 保留与target_label匹配的检测框
filtered_detections = [d for d in sample.ground_truth.detections if d.label == target_label]
# 如果样本中还有匹配的检测框,创建样本副本并添加到新数据集中
if filtered_detections:
new_sample = sample.copy()
new_sample.ground_truth.detections = filtered_detections
filtered_dataset.add_sample(new_sample)
return filtered_dataset
def update_txt_file_class_indices(class_name):
labels_dir = os.path.join("/yolov5/open-images-v7", class_name, 'labels/val')
dataset_yaml = os.path.join("/yolov5/open-images-v7", class_name, 'dataset.yaml')
os.remove(dataset_yaml)
if os.path.exists(labels_dir):
for filename in os.listdir(labels_dir):
if filename.endswith('.txt'):
filepath = os.path.join(labels_dir, filename)
# 读取并处理.txt文件
with open(filepath, 'r') as file:
lines = file.readlines()
# 更新类别索引
updated_lines = []
for line in lines:
parts = line.strip().split()
if len(parts) >= 5: # 假设每行至少有5个元素(class index在第0个位置)
class_idx_str = parts[0] # 原类别索引(可能是名称也可能是数字)
try:
updated_class_idx = str(class_to_index[class_name])
except ValueError:
# 如果转换失败,则按类别名称补全
updated_class_idx = class_name
parts[0] = updated_class_idx
updated_lines.append(' '.join(parts) + '\n')
# 写回更新后的行
with open(filepath, 'w') as file:
file.writelines(updated_lines)
print(f"{class_name}类别的所有.txt文件的索引已更新。")
for class_name in classes:
dataset = foz.load_zoo_dataset(
"open-images-v7",
split="train", # train validation test
label_types=["detections"], # "detections", "segmentations", "points"
classes=[class_name],
max_samples=100000, # 筛选前十万个样本
shuffle=True,
only_matching=True, # 指定仅下载符合条件的图片
num_workers=1, # 指定进程数为1
dataset_name="base_100000",
dataset_dir=f"/open-images-v7"
)
filtered_dataset = filter_samples_by_label(dataset, class_name)
if filtered_dataset.count() == 0:
print(f"No samples found for class: {class_name}")
continue
print(f"{class_name}类别的样本数量为:{filtered_dataset.count()}")
# 导出这个筛选后的数据集
result = filtered_dataset.export(
export_dir=f"/yolov5/open-images-v7/{class_name}/",
dataset_type=fo.types.YOLOv5Dataset,
label_field="ground_truth",
)
update_txt_file_class_indices(class_name)
data_yaml_content = {
'train': '/yolov5/open-images-v7',
'val': '/yolov5/open-images-v7',
'test': '', # 可以根据实际情况填写测试集路径
'nc': len(classes), # 类别数量
'names': classes # 类别名称列表
}
with open('/yolov5/open-images-v7/data.yaml', 'w') as f:
yaml.dump(data_yaml_content, f, default_flow_style=False)
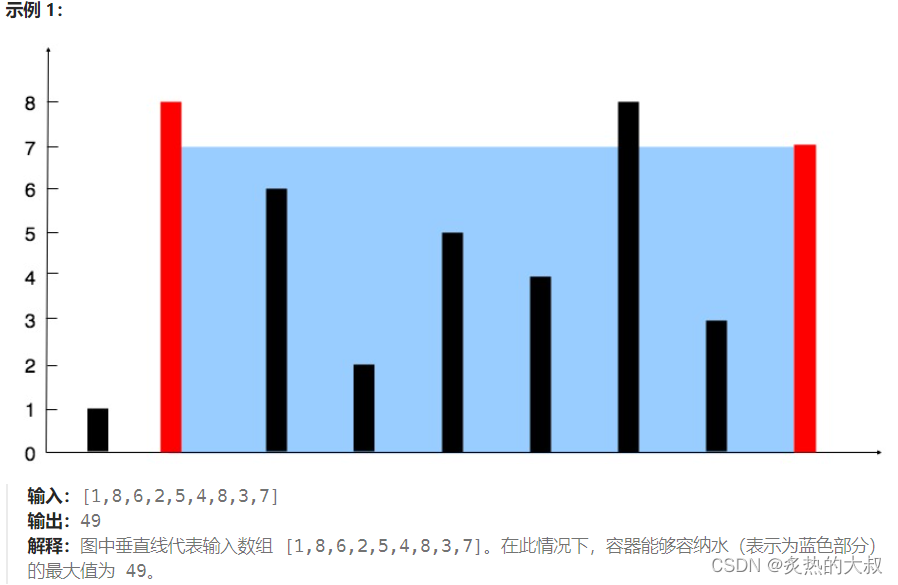
下载10万张样本 ( 如果测试可以将max_samples值调小)

下载后生成的文件目录结构如下:
数据转换后按类别划分为多个文件 如下: