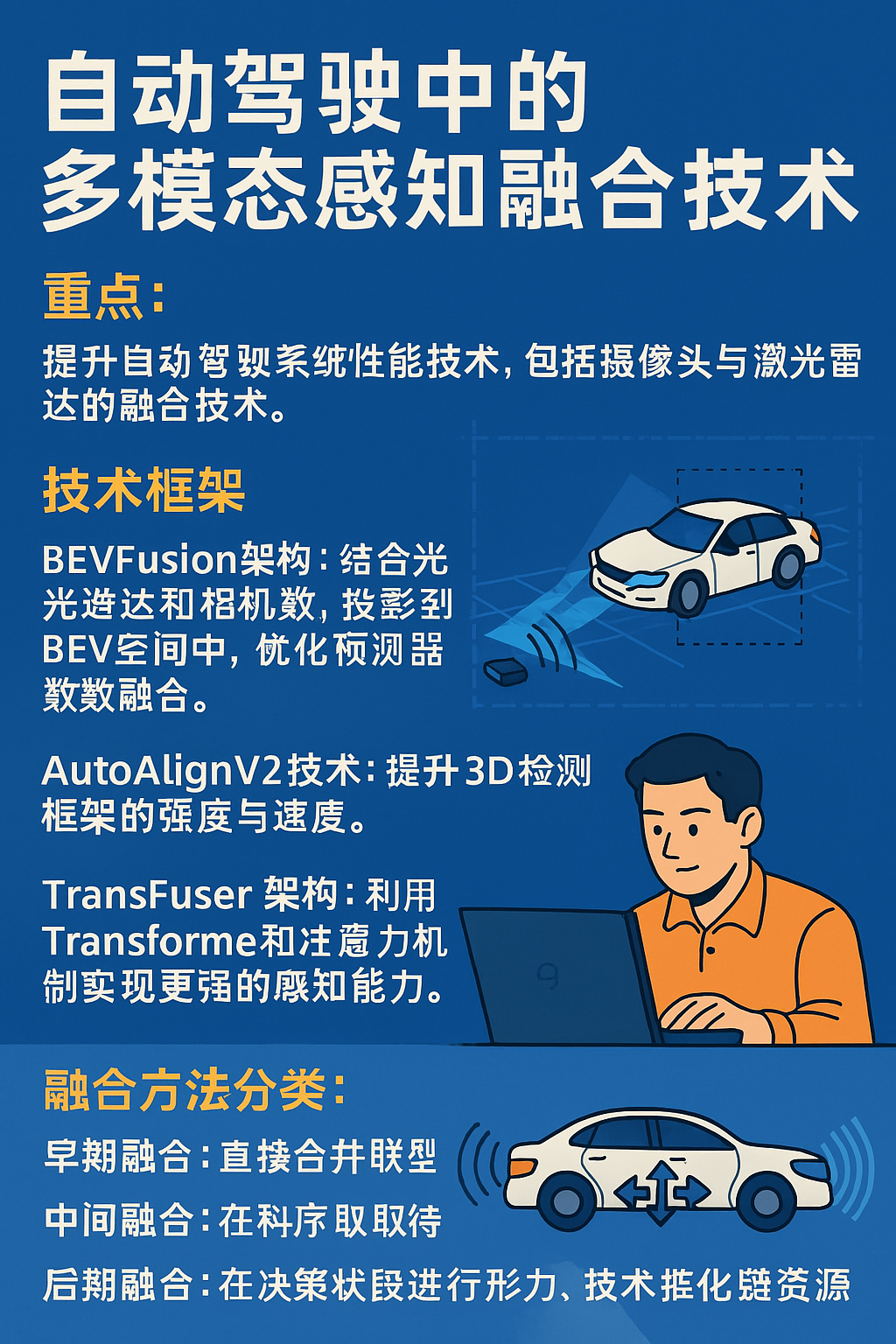
学习记录还原:在本次实验中,我基于 Stable Diffusion v1.5模型,通过一系列优化方法提升生成图像的质量,最终实现了图像质量的显著提升。实验从基础的 Img2Img 技术入手,逐步推进到参数微调、DreamShaper 模型和 ControlNet 的应用,最终优化了图像细节和结构一致性。以下是实验的详细过程。
两效果图:

1. 实验环境
为了确保实验可复现,以下是实验所用的环境配置:
-
操作系统:Windows 10
-
GPU:NVIDIA GeForce RTX 4070(8GB 显存)
-
Python 版本:3.11
-
深度学习框架:PyTorch 1.12.1

-
核心库:
-
diffusers==0.29.2 -
transformers==4.44.2 -
opencv-python==4.10.0.84
-
-
模型:
-
基础模型:
runwayml/stable-diffusion-v1-5 -
优化模型:
Lykon/dreamshaper-8 -
ControlNet:
lllyasviel/sd-controlnet-canny
-
2. 优化一:Img2Img 技术

优化动机与原因
基础的 Stable Diffusion 模型在生成图像时,细节和结构一致性较弱,尤其是在服装生成任务中,难以保留原始结构。通过引入 Img2Img 技术,可以在生成过程中保留更多原始图像的结构信息,提升一致性。
优化思路
以原始服装图像作为输入,结合文本提示,生成与原图结构相似但具有新细节的图像。通过调整 strength 参数,平衡原图结构保留与生成创意之间的关系。
优化过程
-
代码实现:
from diffusers import StableDiffusionImg2ImgPipeline pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16) init_image = Image.open(image_path).convert("RGB") image = pipe(prompt, image=init_image, strength=0.75, num_inference_steps=50).images[0] -
参数调整:设置
strength=0.75,使生成图像在保留原图结构的基础上,融入提示词描述的细节。
结果
Img2Img 技术有效提升了图像的结构一致性,但细节表现仍然不足,整体质量有待提高。
3. 优化二:微调 Stable Diffusion 参数
优化动机与原因
尽管 Img2Img 改善了结构一致性,但生成的图像细节和感知质量仍不理想。微调 Stable Diffusion 的生成参数可以进一步优化细节表现,提升图像的清晰度和真实感。
优化思路
通过增强提示词的描述性和调整生成参数(如 num_inference_steps 和 guidance_scale),提高图像的细节质量和与提示词的匹配度。
优化过程
-
提示词增强:
enhanced_prompt = f"{prompt}, highly detailed, realistic textures, sharp edges" -
参数调整:
image = pipe(enhanced_prompt, negative_prompt="blurry, low resolution", num_inference_steps=75, guidance_scale=10.0).images[0]-
增加
num_inference_steps至 75,提升生成过程的精细度。 -
设置
guidance_scale=10.0,增强提示词对生成结果的引导作用。
-
结果
参数微调后,图像细节和清晰度有所提升,但结构一致性仍然有限,整体效果仍未达到最佳。
4. 优化三:DreamShaper 模型
优化动机与原因
基础模型在细节和美感上的表现存在局限,尤其在服装生成中难以生成高质量的纹理和人物细节。DreamShaper 模型(Lykon/dreamshaper-8)在细节生成上的表现优异,是进一步优化的选择。
优化思路
替换基础模型为 DreamShaper,结合优化后的提示词和参数设置,提升图像的细节表现和视觉美感。
优化过程
-
模型加载:
from diffusers import StableDiffusionPipeline model_id = "Lykon/dreamshaper-8" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16) -
图像生成:
image = pipe(enhanced_prompt, negative_prompt="blurry, low resolution", num_inference_steps=50, guidance_scale=7.5).images[0]
结果
DreamShaper 模型显著提升了图像的细节表现和感知质量,生成的服装纹理更加真实,但结构精确性仍需改进。
5. 优化四:SD v1.5 + ControlNet
优化动机与原因
尽管 DreamShaper 在细节上表现出色,但服装的轮廓和结构一致性仍不完美。ControlNet 通过引入边缘图约束,能够有效提升生成图像的结构精确性,特别适用于服装生成任务。
优化思路
使用 Canny 边缘检测生成控制图像,结合 Stable Diffusion v1.5 和 ControlNet,约束生成过程以保留服装的轮廓和结构。
优化过程
-
ControlNet 集成:
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16) pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16) -
边缘图生成与图像生成:
canny_image = cv2.Canny(cv2.imread(image_path, cv2.IMREAD_GRAYSCALE), 100, 200) image = pipe(prompt, image=canny_image, controlnet_conditioning_scale=1.0).images[0]
结果
ControlNet 的引入显著提升了图像的结构一致性和细节质量,服装轮廓更加精确,整体效果最佳。


DreamShaper


6. 总结
通过四次优化,我逐步提升了 Stable Diffusion 生成图像的质量:
-
Img2Img:奠定了结构一致性的基础,但细节不足。
-
参数微调:增强了细节和清晰度,但结构仍需优化。
-
DreamShaper:显著提升了细节和美感,表现优于基础模型。
-
SD v1.5 + ControlNet:通过边缘约束,实现了结构与细节的全面提升。
最终,ControlNet 在服装生成任务中展现了最优效果,兼顾结构精确性和感知质量。
基础模型:
深度学习项目记录·Stable Diffusion从零搭建、复现笔记-CSDN博客
深度仔细记录:
基于 Stable Diffusion 的图像生成优化与评估:从 SDXL 到 ControlNet 的探索——项目学习记录-CSDN博客强相关:
Stable Diffusion+Pyqt5: 实现图像生成与管理界面(带保存 + 历史记录 + 删除功能)——我的实验记录(结尾附系统效果图)-CSDN博客