HUAWEI – C++一面面经
公众号:阿Q技术站
来源:https://www.nowcoder.com/feed/main/detail/b8113ff340d7444985b32a73c207c826
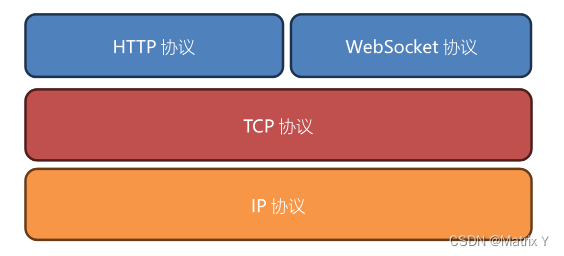
1、计网的协议分几层?分别叫什么?
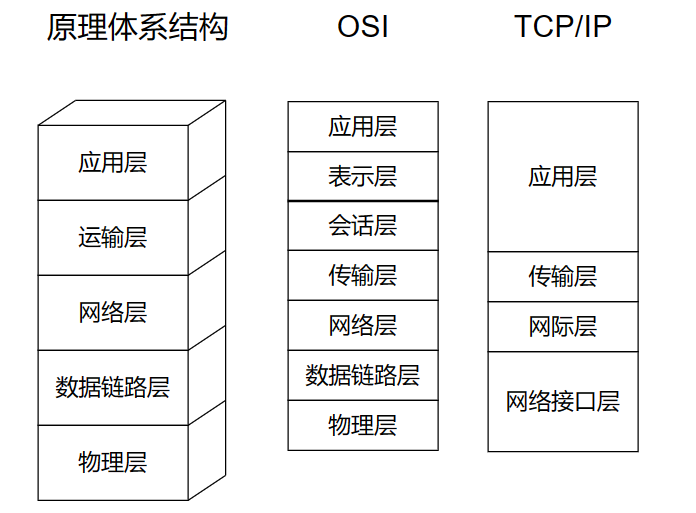
OSI七层模型
- 物理层 (Physical Layer): 负责物理设备之间的原始比特流传输,包括硬件设备、线缆、接口等。
- 数据链路层 (Data Link Layer): 提供节点到节点的数据传输,处理数据帧的错误检测和纠正,包括MAC地址和链路层协议(如以太网)。
- 网络层 (Network Layer): 负责路径选择和数据包的转发,使用IP地址进行数据传输(如IP协议)。
- 传输层 (Transport Layer): 提供端到端的通信服务,保证数据的可靠传输和顺序到达(如TCP和UDP协议)。
- 会话层 (Session Layer): 管理和维护应用程序之间的会话,控制会话的建立、维护和终止。
- 表示层 (Presentation Layer): 负责数据的翻译、加密和压缩,确保数据格式正确(如JPEG、MPEG)。
- 应用层 (Application Layer): 为应用程序提供网络服务接口,如HTTP、FTP、SMTP等协议。
TCP/IP四层模型
- 链路层 (Link Layer): 包括所有物理和数据链路层的功能,负责在本地网络上发送数据帧(如以太网协议)。
- 网络层 (Internet Layer): 负责逻辑寻址、路由选择和数据包转发,主要协议是IP。
- 传输层 (Transport Layer): 提供端到端的通信服务,主要协议是TCP和UDP。
- 应用层 (Application Layer): 包括OSI模型的会话层、表示层和应用层的功能,提供具体的应用服务(如HTTP、FTP、SMTP)。
2、tcp和udp属于哪一层?有什么区别?
TCP和UDP的区别
- 连接性:
- TCP: 面向连接的协议。在发送数据之前,需要先建立连接(三次握手),确保通信的可靠性。在数据传输完毕后,需要断开连接(四次挥手)。
- UDP: 无连接的协议。在发送数据之前不需要建立连接,直接发送数据,适用于需要快速传输的场景。
- 可靠性:
- TCP: 提供可靠的数据传输,通过确认机制(ACK)、重传机制、流量控制和拥塞控制,确保数据包按顺序、无误地到达对方。
- UDP: 不保证数据传输的可靠性,没有确认机制和重传机制,数据包可能会丢失、重复或乱序。
- 传输方式:
- TCP: 面向字节流的传输方式,数据以流的形式发送,数据可以被分割成多个小包传输,对方接收时按顺序组装。
- UDP: 面向数据报的传输方式,数据以独立的数据报(数据包)的形式发送,每个数据报都是一个独立的单元。
- 效率:
- TCP: 较为复杂的控制机制(如连接建立和断开、重传、确认等)增加了开销,传输效率相对较低,但保证了数据的可靠性。
- UDP: 无需建立连接,开销小,传输效率高,但不保证数据的可靠性。
- 使用场景:
- TCP: 适用于对数据传输可靠性要求较高的应用,如网页浏览(HTTP/HTTPS)、电子邮件(SMTP)、文件传输(FTP)。
- UDP: 适用于对实时性要求较高但对数据传输可靠性要求较低的应用,如视频会议、在线游戏、直播、DNS查询等。
具体应用举例
- TCP适用于对数据传输可靠性要求高的场景,如:
- 网页浏览(HTTP/HTTPS): 需要确保网页数据完整传输。
- 电子邮件(SMTP/POP3): 需要确保邮件内容不丢失。
- 文件传输(FTP): 需要确保文件完整性。
- UDP适用于对实时性要求高但对数据传输可靠性要求低的场景,如:
- 视频会议: 需要低延迟和高实时性,数据丢失或乱序不会严重影响体验。
- 在线游戏: 需要快速响应和低延迟,数据包的丢失可以通过游戏逻辑处理。
- 直播: 需要低延迟和高实时性,数据丢失可以容忍。
- DNS查询: 请求和响应都是单独的数据包,丢失后可以重新发送请求。
3、icmp在哪一层?
ICMP(Internet Control Message Protocol,互联网控制报文协议)位于网络层(Network Layer)。ICMP主要用于在网络设备之间传递控制信息和错误报告,以帮助诊断网络通信问题。
ICMP的功能和特点
- 错误报告: 当网络设备(如路由器)无法传递数据包时,ICMP用于报告错误。例如,如果路由器发现无法到达目标地址,它会发送一个ICMP“目的不可达”消息给源设备。
- 网络诊断: ICMP常用于网络诊断工具,如
ping和traceroute。- ping: 通过发送ICMP回显请求(Echo Request)包,并等待回显应答(Echo Reply)包,以检查目标设备是否可达以及测量往返时间。
- traceroute: 通过发送带有不同生存时间(TTL, Time to Live)值的ICMP包,逐跳地检查到目标设备的路径。
- 流量控制: ICMP可以用于流量控制,例如,当路由器或目标设备过载时,发送源抑制消息(Source Quench)以请求发送方降低数据包发送速率。
ICMP的消息类型
ICMP定义了多种类型的消息,每种消息都有特定的用途。常见的ICMP消息类型包括:
- 回显请求(Echo Request, 类型 8)**和**回显应答(Echo Reply, 类型 0): 用于
ping操作,检查设备的可达性。 - 目的不可达(Destination Unreachable, 类型 3): 当数据包无法到达目标地址时,发送此消息。
- 源抑制(Source Quench, 类型 4): 请求发送方降低发送数据的速率(已过时和不常用)。
- 重定向(Redirect, 类型 5): 当数据包可以通过更好的路径传递时,通知发送方更新其路由信息。
- 超时(Time Exceeded, 类型 11): 当数据包的TTL值变为0时,发送此消息,常用于
traceroute。
ICMP在网络层的角色
ICMP作为网络层的一部分,与IP协议密切相关。虽然ICMP不直接传输应用数据,但它提供了重要的网络控制和诊断功能,确保网络通信的顺畅和高效。
ICMP的应用
- 网络连通性检查: 通过
ping命令检测目标设备是否在线。 - 路径追踪: 通过
traceroute命令追踪到目标设备的网络路径。 - 故障排除: 当网络通信出现问题时,ICMP消息帮助诊断和定位问题。
- 流量管理: 控制数据流量,避免网络过载。
4、tcp通过什么保证稳定性?
1. 连接建立和终止
三次握手
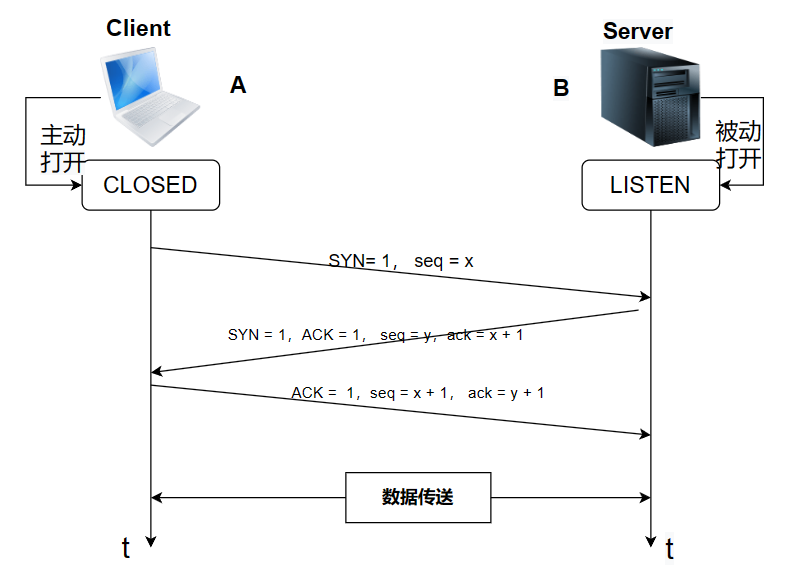
在建立连接之前,Client处于CLOSED状态,而Server处于LISTEN的状态。
- 第一次握手(SYN-1):
- 客户端发送一个带有 SYN 标志的 TCP 报文段给服务器,表示客户端请求建立连接。
- 客户端选择一个初始序列号(ISN)并将其放入报文段中,进入 SYN_SENT 状态。
- 第二次握手(SYN + ACK):
- 服务器收到客户端发送的 SYN 报文段后,如果同意建立连接,会发送一个带有 SYN 和 ACK 标志的报文段给客户端,表示服务器接受了客户端的请求,并带上自己的 ISN。
- 服务器进入 SYN_RCVD 状态。
- 第三次握手(ACK):
- 客户端收到服务器发送的 SYN+ACK 报文段后,会发送一个带有 ACK 标志的报文段给服务器,表示客户端确认了服务器的响应。
- 客户端和服务器都进入 ESTABLISHED 状态,连接建立成功,可以开始进行数据传输。
四次挥手
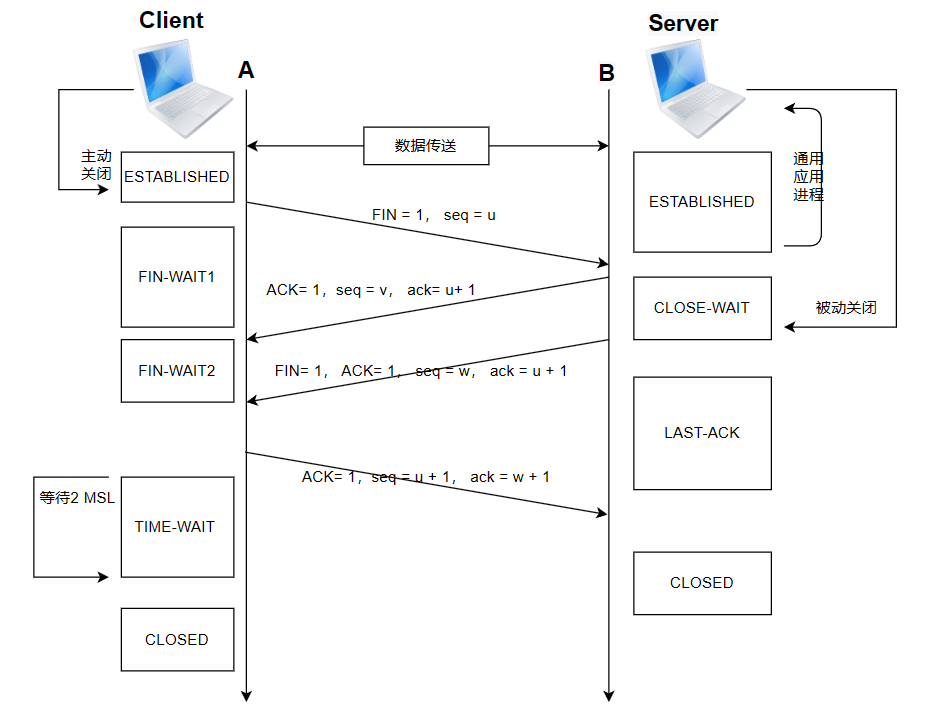
- 第一次挥手(FIN-1):
- 客户端发送一个 FIN 报文段给服务器,表示客户端已经没有数据要发送了,请求关闭连接。
- 客户端进入 FIN_WAIT_1 状态,等待服务器的确认。
- 第二次挥手(ACK):
- 服务器收到客户端的 FIN 报文段后,发送一个 ACK 报文段作为应答,表示已经接收到了客户端的关闭请求。
- 服务器进入 CLOSE_WAIT 状态,等待自己的数据发送完毕。
- 第三次挥手(FIN-2):
- 服务器发送一个 FIN 报文段给客户端,表示服务器也没有数据要发送了,请求关闭连接。
- 服务器进入 LAST_ACK 状态,等待客户端的确认。
- 第四次挥手(ACK):
- 客户端收到服务器的 FIN 报文段后,发送一个 ACK 报文段作为应答,表示已经接收到了服务器的关闭请求。
- 客户端进入 TIME_WAIT 状态,等待可能出现的延迟数据。
- 服务器收到客户端的 ACK 报文段后,完成关闭,进入 CLOSED 状态。
- 客户端在 TIME_WAIT 状态结束后,关闭连接,进入 CLOSED 状态。
2. 确认应答
TCP在数据传输过程中使用确认应答机制。接收方收到数据后,会发送一个ACK包给发送方,确认数据已经成功接收。如果发送方在一定时间内未收到ACK包,则会重传数据。
3. 重传机制
如果发送方未在指定时间内收到接收方的ACK包,则认为数据丢失或未到达,会重传数据。这通过以下方法实现:
- **超时重传:如果ACK在超时时间内未到达,则进行重传。
- **快速重传:如果连续收到三个重复的ACK,发送方会立即重传未确认的数据包。
4. 序列号
TCP为每个字节的数据分配一个序列号(Sequence Number)。序列号确保数据按顺序接收和重组。接收方通过序列号确认收到的数据,并向发送方发送ACK,指明下一个期望接收的字节序列号。
5. 滑动窗口
滑动窗口机制用于流量控制,控制发送方可以发送但未被接收方确认的最大数据量。接收方根据自身的接收能力动态调整窗口大小,通知发送方当前可以发送的最大数据量。这有助于避免发送方发送过多数据,导致接收方缓冲区溢出。
6. 拥塞控制
TCP使用多种算法来防止网络拥塞:
- **慢启动:发送方开始时发送少量数据,并随着ACK包的到达逐步增加发送窗口大小,直到达到网络的最佳速率或发生丢包。
- 拥塞避免:在发送窗口达到一定阈值后,进入拥塞避免阶段,逐步增加窗口大小,以避免网络拥塞。
- **快速恢复:在快速重传之后,发送方不会像慢启动一样从头开始,而是调整窗口大小,继续传输数据,以快速恢复正常传输速率。
7. 校验和
TCP在数据包中包含校验和,用于验证数据在传输过程中是否损坏。发送方计算数据包的校验和,接收方接收数据包后重新计算校验和,并与发送方的校验和进行比对,确保数据完整无误。
8. 连接保持
TCP支持连接保持机制,发送周期性的保持活动(Keep-Alive)消息,以确保连接在长时间没有数据传输时仍然有效。这有助于检测和处理长时间无活动的连接。
5、介绍一下快排?
基于分治策略,通常在平均情况下具有O(n log n)的时间复杂度。
快速排序的基本思想
- 选择基准:从待排序的数组中选择一个元素作为基准。
- 分区:重新排列数组,使得所有小于基准的元素放在基准的左边,所有大于基准的元素放在基准的右边。基准元素最终处于其正确的位置。
- 递归排序:对基准左边的子数组和右边的子数组递归地进行上述操作,直到子数组的大小为1或0,排序完成。
快速排序的步骤
-
选择基准:
可以选择第一个元素、最后一个元素、中间元素,或者随机选择一个元素作为基准。
-
分区:
通过交换元素,将小于基准的元素移到左边,大于基准的元素移到右边。
-
递归调用:
对分区后的子数组分别进行快速排序。
快速排序的实现
#include <iostream>
#include <vector>
using namespace std;
// 快速排序函数
vector<int> quicksort(vector<int>& arr) {
if (arr.size() <= 1) {
return arr; // 如果数组长度小于等于1,直接返回
} else {
int pivot = arr[arr.size() / 2]; // 选择中间元素作为基准
vector<int> left; // 存放小于基准的元素
vector<int> middle; // 存放等于基准的元素
vector<int> right; // 存放大于基准的元素
for (int x : arr) {
if (x < pivot) {
left.push_back(x); // 小于基准的元素放入 left
} else if (x == pivot) {
middle.push_back(x); // 等于基准的元素放入 middle
} else {
right.push_back(x); // 大于基准的元素放入 right
}
}
// 递归排序 left 和 right,并将结果合并
vector<int> sorted_left = quicksort(left);
vector<int> sorted_right = quicksort(right);
// 合并结果
vector<int> result;
result.insert(result.end(), sorted_left.begin(), sorted_left.end());
result.insert(result.end(), middle.begin(), middle.end());
result.insert(result.end(), sorted_right.begin(), sorted_right.end());
return result;
}
}
// 主函数
int main() {
vector<int> arr = {10, 7, 8, 9, 1, 5}; // 初始化待排序数组
vector<int> sorted_arr = quicksort(arr); // 调用快速排序函数
cout << "排序后的数组: "; // 输出排序结果
for (int x : sorted_arr) {
cout << x << " "; // 打印数组元素
}
cout << endl;
return 0;
}
分区方法的优化
Lomuto分区方案和Hoare分区方案是两种常见的分区方法:
- Lomuto分区方案:
- 使用数组最后一个元素作为基准。
- 从数组的第一个元素开始遍历,将小于基准的元素交换到数组的前部,最后将基准元素放到正确的位置。
#include <iostream>
#include <vector>
using namespace std;
// Lomuto 分区方案
int lomutoPartition(vector<int>& arr, int low, int high) {
int pivot = arr[high]; // 选择最后一个元素作为基准
int i = low; // i 指向比基准小的最后一个元素的索引
for (int j = low; j < high; ++j) {
if (arr[j] < pivot) { // 如果当前元素比基准小
swap(arr[i], arr[j]); // 交换元素
++i; // i 指向下一个位置
}
}
swap(arr[i], arr[high]); // 将基准放置到正确的位置
return i; // 返回基准的索引
}
// 快速排序函数
void quicksort(vector<int>& arr, int low, int high) {
if (low < high) {
int pi = lomutoPartition(arr, low, high); // 获取分区后的基准索引
quicksort(arr, low, pi - 1); // 递归排序基准左侧子数组
quicksort(arr, pi + 1, high); // 递归排序基准右侧子数组
}
}
// 主函数
int main() {
vector<int> arr = {10, 7, 8, 9, 1, 5}; // 初始化待排序数组
int n = arr.size(); // 获取数组大小
quicksort(arr, 0, n - 1); // 调用快速排序函数
cout << "排序后的数组: "; // 输出排序结果
for (int i = 0; i < n; ++i)
cout << arr[i] << " "; // 打印数组元素
cout << endl;
return 0;
}
-
Hoare分区方案:
-
使用数组第一个元素作为基准。
-
从数组的两端开始,找到左侧大于基准的元素和右侧小于基准的元素,然后交换它们。
-
#include <iostream>
#include <vector>
using namespace std;
// Hoare 分区方案
int hoarePartition(vector<int>& arr, int low, int high) {
int pivot = arr[low]; // 选择第一个元素作为基准
int left = low - 1; // 初始化左指针
int right = high + 1; // 初始化右指针
while (true) {
do {
left++; // 向右移动左指针
} while (arr[left] < pivot);
do {
right--; // 向左移动右指针
} while (arr[right] > pivot);
if (left >= right)
return right; // 返回右指针作为分区点
swap(arr[left], arr[right]); // 交换左指针和右指针所指的元素
}
}
// 快速排序函数
void quicksort(vector<int>& arr, int low, int high) {
if (low < high) {
int pi = hoarePartition(arr, low, high); // 获取分区后的基准索引
quicksort(arr, low, pi); // 递归排序基准左侧子数组
quicksort(arr, pi + 1, high); // 递归排序基准右侧子数组
}
}
// 主函数
int main() {
vector<int> arr = {10, 7, 8, 9, 1, 5}; // 初始化待排序数组
int n = arr.size(); // 获取数组大小
quicksort(arr, 0, n - 1); // 调用快速排序函数
cout << "排序后的数组: "; // 输出排序结果
for (int i = 0; i < n; ++i)
cout << arr[i] << " "; // 打印数组元素
cout << endl;
return 0;
}
快速排序的复杂度
- 平均时间复杂度: O(n log n)
- 最坏时间复杂度: O(n²)(在每次选择基准时,选择了数组的最小或最大值)
- 空间复杂度: O(log n)(由于递归调用栈)
快速排序的优缺点
优点:
- 平均情况下具有非常高的效率。
- 原地排序算法,空间复杂度较低。
缺点:
- 在最坏情况下(例如,选择的基准总是最大或最小值),时间复杂度为O(n²)。
- 递归调用可能导致栈溢出。
6、哈希算法?怎么避免哈希冲突?怎么保证尽可能均匀分布?
哈希算法是一种通过特定的计算方法将任意大小的数据映射到固定大小的值(通常称为哈希值或哈希码)的过程。
哈希算法的基本概念
- 哈希函数:一种将输入数据(键)映射为固定长度哈希值的函数。
- 哈希表:一种数据结构,通过哈希函数将键值对存储在数组中,以实现快速的数据查找和插入。
避免哈希冲突的方法
哈希冲突是指不同的输入数据经过哈希函数计算后得到了相同的哈希值。常见的解决哈希冲突的方法有以下几种:
- 链地址法(Separate Chaining):
- 在哈希表的每个桶(数组位置)中存储一个链表,所有映射到同一个哈希值的元素都存储在这个链表中。
- 插入、删除和查找操作需要遍历链表,效率取决于链表的长度。
#include <iostream>
#include <list>
#include <vector>
using namespace std;
class HashTable {
private:
vector<list<int>> table; // 哈希表,每个桶是一个链表
int size; // 哈希表大小
// 哈希函数,将键映射到桶索引
int hashFunction(int key) {
return key % size;
}
public:
// 构造函数,初始化哈希表
HashTable(int size) : size(size) {
table.resize(size); // 调整哈希表大小
}
// 插入操作,将键插入哈希表
void insert(int key) {
int index = hashFunction(key); // 计算哈希值
table[index].push_back(key); // 将键添加到对应的链表中
}
// 删除操作,从哈希表中删除键
void remove(int key) {
int index = hashFunction(key); // 计算哈希值
table[index].remove(key); // 从对应的链表中删除键
}
// 查找操作,判断键是否存在于哈希表中
bool search(int key) {
int index = hashFunction(key); // 计算哈希值
for (int i : table[index]) { // 遍历对应的链表
if (i == key) // 如果找到键,则返回 true
return true;
}
return false; // 否则返回 false
}
};
int main() {
HashTable ht(7); // 创建哈希表,大小为7
ht.insert(10); // 插入键值为10
ht.insert(20); // 插入键值为20
ht.insert(15); // 插入键值为15
ht.insert(7); // 插入键值为7
// 查找键值为10和21
cout << "Search 10: " << ht.search(10) << endl;
cout << "Search 21: " << ht.search(21) << endl;
ht.remove(10); // 删除键值为10
cout << "Search 10: " << ht.search(10) << endl; // 再次查找键值为10
return 0;
}
-
开放地址法(Open Addressing):
-
所有元素都存储在哈希表的数组中,当发生冲突时,按照一定的规则在数组的其他位置查找空闲位置进行存储。
-
常见的探测方法有线性探测、二次探测和双重哈希。
-
#include <iostream>
#include <vector>
using namespace std;
class HashTable {
private:
vector<int> table; // 哈希表的存储数组
int size; // 哈希表的大小
int EMPTY = -1; // 表示空位置的标记
int DELETED = -2; // 表示删除位置的标记
// 哈希函数,将键映射到数组索引
int hashFunction(int key) {
return key % size;
}
public:
// 构造函数,初始化哈希表
HashTable(int size) : size(size) {
table.resize(size, EMPTY); // 将哈希表初始化为全部为空位置
}
// 插入操作,将键插入哈希表
void insert(int key) {
int index = hashFunction(key); // 计算哈希值
while (table[index] != EMPTY && table[index] != DELETED) {
index = (index + 1) % size; // 线性探测,寻找下一个空位置
}
table[index] = key; // 将键插入到找到的空位置
}
// 删除操作,从哈希表中删除键
void remove(int key) {
int index = hashFunction(key); // 计算哈希值
while (table[index] != EMPTY) {
if (table[index] == key) {
table[index] = DELETED; // 将删除位置标记为 DELETED
return;
}
index = (index + 1) % size; // 继续寻找下一个位置
}
}
// 查找操作,判断键是否存在于哈希表中
bool search(int key) {
int index = hashFunction(key); // 计算哈希值
while (table[index] != EMPTY) {
if (table[index] == key)
return true; // 找到键,返回 true
index = (index + 1) % size; // 继续寻找下一个位置
}
return false; // 未找到键,返回 false
}
};
int main() {
HashTable ht(7); // 创建哈希表,大小为7
ht.insert(10); // 插入键值为10
ht.insert(20); // 插入键值为20
ht.insert(15); // 插入键值为15
ht.insert(7); // 插入键值为7
// 查找键值为10和21
cout << "Search 10: " << ht.search(10) << endl;
cout << "Search 21: " << ht.search(21) << endl;
ht.remove(10); // 删除键值为10
cout << "Search 10: " << ht.search(10) << endl; // 再次查找键值为10
return 0;
}
保证哈希值尽可能均匀分布的方法
-
选择合适的哈希函数:
- 一个好的哈希函数应该能将输入数据均匀地分布到哈希表的所有桶中。
- 哈希函数应尽量避免产生相同的哈希值。
-
使用质数表大小:
- 选择哈希表的大小为质数,可以减少哈希冲突。
- 质数能够有效地避免某些模式化的数据输入导致的冲突。
-
增大哈希表的大小:
增大哈希表的大小可以减少冲突的概率,但需要平衡空间利用率。
-
重哈希(Rehashing):
当哈希表的负载因子(已存储元素数与哈希表大小的比值)达到某个阈值时,重新构建哈希表,选择新的哈希函数并将所有元素重新插入。
-
使用复合哈希(Composite Hashing):
结合多个哈希函数生成哈希值,可以有效降低冲突率。
7、怎么实现多态?
在C++中,实现多态性通常通过虚函数(virtual function)和继承来实现。
- 定义:
- 多态是一种允许同一操作在不同对象上具有不同行为的能力。
- 多态通过两种方式实现:编译时多态(静态多态)和运行时多态(动态多态)。
- 目的:
- 提高代码的灵活性,使得代码可以处理多种不同类型的对象。
- 实现接口重用,同一接口可以被不同类实现,实现了多态。
- 优点:
- 代码更加灵活,可以适应不同的场景和需求。
- 通过接口编程,降低了代码的耦合度。
下面是一个简单的示例,演示如何使用虚函数和继承实现多态性:
#include <iostream>
using namespace std;
// 基类 Shape
class Shape {
public:
// 虚函数,用于计算形状的面积
virtual double getArea() const {
return 0;
}
};
// 派生类 Circle
class Circle : public Shape {
private:
double radius;
public:
Circle(double r) : radius(r) {}
// 重写基类的虚函数
double getArea() const override {
return 3.14 * radius * radius;
}
};
// 派生类 Rectangle
class Rectangle : public Shape {
private:
double length;
double width;
public:
Rectangle(double l, double w) : length(l), width(w) {}
// 重写基类的虚函数
double getArea() const override {
return length * width;
}
};
int main() {
Circle c(5);
Rectangle r(3, 4);
// 基类指针指向派生类对象
Shape* shape1 = &c;
Shape* shape2 = &r;
// 调用虚函数,实现多态
cout << "Circle Area: " << shape1->getArea() << endl;
cout << "Rectangle Area: " << shape2->getArea() << endl;
return 0;
}
8、设计模式,单例模式?
单例模式确保一个类只有一个实例,并提供一个全局访问点。
饿汉式单例(Eager Initialization)
饿汉式单例在类加载时就创建实例,线程安全,但如果实例初始化很重或者程序未使用到该实例,会造成资源浪费。
class Singleton {
private:
static Singleton instance; // 静态实例
// 私有构造函数,防止外部实例化
Singleton() {}
public:
// 禁用拷贝构造函数和赋值运算符
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
// 提供一个全局访问点
static Singleton& getInstance() {
return instance;
}
void doSomething() {
// 业务方法
}
};
// 初始化静态成员变量
Singleton Singleton::instance;
懒汉式单例(Lazy Initialization)
懒汉式单例在第一次调用 getInstance 时创建实例,节省资源,但需要注意线程安全问题。
非线程安全实现
class Singleton {
private:
static Singleton* instance;
Singleton() {}
public:
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton* getInstance() {
if (instance == nullptr) {
instance = new Singleton();
}
return instance;
}
void doSomething() {
// 业务方法
}
};
// 初始化静态成员变量
Singleton* Singleton::instance = nullptr;
线程安全实现(使用互斥锁)
#include <mutex>
class Singleton {
private:
static Singleton* instance;
static std::mutex mtx;
Singleton() {}
public:
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton* getInstance() {
std::lock_guard<std::mutex> lock(mtx);
if (instance == nullptr) {
instance = new Singleton();
}
return instance;
}
void doSomething() {
// 业务方法
}
};
// 初始化静态成员变量
Singleton* Singleton::instance = nullptr;
std::mutex Singleton::mtx;
双重检查锁定(Double-Checked Locking)
双重检查锁定是在懒汉式单例的基础上进一步优化,减少加锁的开销,但需要使用 volatile 关键字确保编译器不会对代码进行重排序。
#include <mutex>
class Singleton {
private:
static Singleton* instance;
static std::mutex mtx;
Singleton() {}
public:
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton* getInstance() {
if (instance == nullptr) {
std::lock_guard<std::mutex> lock(mtx);
if (instance == nullptr) {
instance = new Singleton();
}
}
return instance;
}
void doSomething() {
// 业务方法
}
};
// 初始化静态成员变量
Singleton* Singleton::instance = nullptr;
std::mutex Singleton::mtx;
使用 std::call_once 实现
C++11 引入的 std::call_once 可以保证只调用一次初始化代码,简化线程安全的单例实现。
#include <mutex>
class Singleton {
private:
static Singleton* instance;
static std::once_flag initFlag;
Singleton() {}
public:
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton* getInstance() {
std::call_once(initFlag, []() {
instance = new Singleton();
});
return instance;
}
void doSomething() {
// 业务方法
}
};
// 初始化静态成员变量
Singleton* Singleton::instance = nullptr;
std::once_flag Singleton::initFlag;
使用局部静态变量
C++11 之后,局部静态变量的初始化是线程安全的,可以利用这一特性简化单例实现。
class Singleton {
private:
Singleton() {}
public:
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton& getInstance() {
static Singleton instance;
return instance;
}
void doSomething() {
// 业务方法
}
};
9、手撕代码:本地IDE做,力扣中等题949 – 给定数字能组成的最大时间
思路
- 生成所有可能的排列。
- 对于每个排列,检查是否可以组成有效的时间。小时应小于24,分钟应小于60。
- 如果找到符合条件的时间,则比较它与当前最大时间的大小,并更新最大时间。
参考代码(ACM模式)
C++
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
string largestTimeFromDigits(vector<int>& arr) {
string ans = ""; // 存储最终结果的字符串
int maxTime = -1; // 存储最大时间的分钟表示
// 生成所有可能的排列
sort(arr.begin(), arr.end());
do {
int hour = arr[0] * 10 + arr[1]; // 将前两位数字组成小时数
int minute = arr[2] * 10 + arr[3]; // 将后两位数字组成分钟数
// 检查小时和分钟是否有效
if (hour < 24 && minute < 60) {
int currentTime = hour * 60 + minute; // 将时间转换为分钟表示
// 更新最大时间
if (currentTime > maxTime) {
maxTime = currentTime;
// 将数字转换为字符串格式,并按照 "HH:MM" 格式拼接
ans = to_string(arr[0]) + to_string(arr[1]) + ":" + to_string(arr[2]) + to_string(arr[3]);
}
}
} while (next_permutation(arr.begin(), arr.end())); // 生成下一个排列直到所有排列都遍历完
return ans; // 返回最大时间的字符串表示
}
};
int main() {
Solution sol;
vector<int> arr1 = {1, 2, 3, 4};
cout << "Input: [1, 2, 3, 4]" << endl;
cout << "Output: " << sol.largestTimeFromDigits(arr1) << endl;
vector<int> arr2 = {5, 5, 5, 5};
cout << "Input: [5, 5, 5, 5]" << endl;
cout << "Output: " << sol.largestTimeFromDigits(arr2) << endl;
vector<int> arr3 = {0, 0, 0, 0};
cout << "Input: [0, 0, 0, 0]" << endl;
cout << "Output: " << sol.largestTimeFromDigits(arr3) << endl;
vector<int> arr4 = {0, 0, 1, 0};
cout << "Input: [0, 0, 1, 0]" << endl;
cout << "Output: " << sol.largestTimeFromDigits(arr4) << endl;
return 0;
}
打遍天下无敌手!