1、HTML语义化?
对于开发者而言,语义化标签有着更好的页面结构,有利于代码的开发编写和后期的维护。
对于用户而言,当网络卡顿时有良好的页面结构,有利于增加用户的体验。
对于爬虫来说,有利于搜索引擎的SEO优化,利于网站有更靠前的排名。
2、盒模型?
盒模型分为两类,一是标准盒模型,二是怪异盒模型。一般我们的盒子默认是标准盒模型。
形成标准盒模型的条件box-sizing:content-box, 元素总宽度 = 内容的width + padding(左右) + border(左右) + margin(左右);
形成怪异盒模型的条件是box-sizing:border-box,元素总宽度 = 内容的width + margin(左右)(这里的width包含了padding(左右)和border(左右)的值)。
3、浮动?
关于浮动:
1.浮动的例子:常用于图片,可以实现文字环绕图片
2.浮动的特点:脱离文档流,容易造成盒子塌陷,影响其他元素的排列
3.解决塌陷问题:
①父元素中添加overflow:hidden; 其实是bfc块级元素格式化上下文
②建立空白div,添加clear
③在父级添加伪元素::after{ content : ’ ', clear : both , display : table}
4、样式优先级
|important和行间样式另说
x:ID选择器
y:class、属性、伪类
z:元素、伪元素
最末通配符
5、CSS尺寸设置的单位
得分点 px、rem、em、vw、vh 标准回答
px:pixel像素的缩写,绝对长度单位,它的大小取决于屏幕的分辨率,是开发网页中常常使用的单位。
em:相对长度单位,在 font-size 中使用是相对于父元素的字体大小,在其他属性中使用是相对于自身的字体大小,如 width。如当前元素的字体尺寸未设置,由于字体大小可继承的原因,可逐级向上查找,最终找不到则相对于浏览器默认字体大小。
rem:相对长度单位,相对于根元素的字体大小,根元素字体大小未设置,使用浏览器默认字体大小。
vw:相对长度单位,相对于视窗宽度的1%。
vh:相对长度单位,相对于视窗高度的1%。 加分回答 rem应用:在移动端网页开发中,页面要做成响应式的,可使用rem配合媒体查询或者flexible.js实现。原理是通过媒体查询或者flexible.js,能够在屏幕尺寸发生改变时,重置html根元素的字体大小,页面中的元素都是使用rem为单位设置的尺寸,因此只要改变根元素字体大小,页面中的其他元素的尺寸就自动跟着修改
vw应用:由于vw被更多浏览器兼容之后,在做移动端响应式页面时,通常使用vw配合rem。原理是使用vw设置根元素html字体的大小,当窗口大小发生改变,vw代表的尺寸随着修改,无需加入媒体查询和flexible.js,页面中的其他元素仍使用rem为单位,就可实现响应式。
6、BFC
关于BFC:
1.定义:块级格式化上下文,独立的渲染区域,不会影响边界外的元素
2.形成条件:①浮动 ②非静态定位static ③overflow: hidden; ④display: table
3.布局规则:
①区域内容box从上到下排列
②box垂直方向的距离由margin决定
③同一个BFC内 box的margin会重叠
④BFC不会与float元素重叠
⑤BFC计算高度也会计算float元素
4.解决的问题:
①解决浮动元素重叠问题
②解决父元素高度塌陷问题
③解决margin重叠问题
7、未知宽高元素水平垂直居中
- 利用margin:0 auto水平居中
- 设置元素相对父级定位
position:absolute;left:50%;right:50%,让自身平移自身高度50% (margin负值也可以,就是写法有点老)transform: translate(-50%,-50%);,这种方式兼容性好,被广泛使用的一种方式 - 设置元素的父级为弹性盒子
display:flex,设置父级和盒子内部子元素水平垂直都居中justify-content:center; align-items:center,这种方式代码简洁,但是兼容性ie 11以上支持,由于目前ie版本都已经很高,很多网站现在也使用这种方式实现水平垂直居中 - 设置元素的父级为网格元素
display: grid,设置父级和盒子内部子元素水平垂直都居中justify-content:center; align-items:center,这种方式代码简介,但是兼容性ie 10以上支持 - 设置元素的父级为表格元素
display: table-cell,其内部元素水平垂直都居中text-align: center;vertical-align: middle;,设置子元素为行内块display: inline-block;,这种方式兼容性较好
8、JS数据类型有哪些
Number、String、Boolean、BigInt、Symbol、Null、Undefined、Object、8种
标准回答
JS数据类型分为两类:
一类是基本数据类型,也叫简单数据类型,包含7种类型,分别是Number 、String、Boolean、BigInt、Symbol、Null、Undefined。
另一类是引用数据类型,也叫复杂数据类型,通常用Object代表,普通对象,数组,正则,日期,Math数学函数都属于Object。
数据分成两大类的本质区别:基本数据类型和引用数据类型它们在内存中的存储方式不同。
基本数据类型是直接存储在栈中的简单数据段,占据空间小,属于被频繁使用的数据。
引用数据类型是存储在堆内存中,占据空间大。引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址,当解释器寻找引用值时,会检索其在栈中的地址,取得地址后从堆中获得实体。
加分回答
Symbol是ES6新出的一种数据类型,这种数据类型的特点就是没有重复的数据,可以作为object的key。
数据的创建方法Symbol(),因为它的构造函数不够完整,所以不能使用new Symbol()创建数据。由于Symbol()创建数据具有唯一性,所以 Symbol() !== Symbol(), 同时使用Symbol数据作为key不能使用for获取到这个key,需要使用Object.getOwnPropertySymbols(obj)获得这个obj对象中key类型是Symbol的key值。
let key = Symbol(‘key’);
let obj = { [key]: ‘symbol’};
let keyArray = Object.getOwnPropertySymbols(obj); // 返回一个数组[Symbol(‘key’)]
obj[keyArray[0]] // ‘symbol’
BigInt也是ES6新出的一种数据类型,这种数据类型的特点就是数据涵盖的范围大,能够解决超出普通数据类型范围报错的问题。
使用方法:
-整数末尾直接+n:647326483767797n
-调用BigInt()构造函数:BigInt(“647326483767797”)
注意:BigInt和Number之间不能进行混合操作

9、null和undefined到底有什么区别
null表示no object, null 其实属于自己的类型 Null,而不属于Object类型,typeof 之所以会判定为 Object 类型,是因为JavaScript 数据类型在底层都是以二进制的形式表示的,二进制的前三位为 0 会被 typeof 判断为对象类型,而 null 的二进制位恰好都是 0 ,因此,null 被误判断为 Object 类型。 对象被赋值了null 以后,对象对应的堆内存中的值就是游离状态了,GC 会择机回收该值并释放内存。
undefined表示no value,表示一个变量初始状态值
10、有几种方法判断变量的类型
JavaScript有4种方法判断变量的类型,分别是typeof、instanceof、Object.prototype.toString.call()(对象原型链判断方法)、 constructor (用于引用数据类型)
1、typeof:常用于判断基本数据类型,对于引用数据类型除了function返回’function‘,其余全部返回’object’。
2、instanceof:主要用于区分引用数据类型,检测方法是检测的类型是否在当前实例的原型链上,用其检测出来的结果都是true,不太适合用于简单数据类型的检测,检测过程繁琐且对于简单数据类型中的undefined, null, symbol检测不出来。
缺点是
①改变对象原型为数组原型
const obj={}
Object.setPrototypeOf(obj, Array.prototype)//改变对象原型,true
②iframe
iframe会在页面生成独立的一套documents还有window
const Array1=window.array;
const iframe=document.querySelector('iframe')
const Array2=iframe.contentWindow.Array
Array1===Array2//false
//会导致
const arr =new Array2()
//arr instanceof Array//false,因为读的是window里面的Array而不是iframe里的Array
数组是一个特殊存储结构的对象
3、constructor:用于检测引用数据类型,检测方法是获取实例的构造函数判断和某个类是否相同,如果相同就说明该数据是符合那个数据类型的,这种方法不会把原型链上的其他类也加入进来,避免了原型链的干扰。
4、Object.prototype.toString.call():适用于所有类型的判断检测,Object.prototype.toString 表示一个返回对象类型的字符串,call()方法可以改变this的指向,那么把Object.prototype.toString()方法指向不同的数据类型上面,返回不同的结果
function(arr){
return Object.prototype.toString.call(arr)==='[object Array]'
}
现在判断会有缺陷,以下obj返回true,可以手动修改值
const obj={
[Symbol.toStringTag]:'Array'
}
数组判断最好用Array.isArray,判断有没有经过Array的构造函数
11、数组去重
第一种方法:利用对象属性key排除重复项:遍历数组,每次判断对象中是否存在该属性,不存在就存储在新数组中,并且把数组元素作为key,设置一个值,存储在对象中,最后返回新数组。这个方法的优点是效率较高,缺点是占用了较多空间,使用的额外空间有一个查询对象和一个新的数组
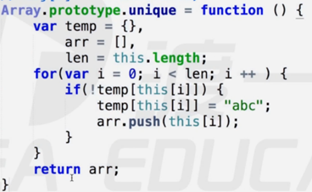
第二种方法:利用Set类型数据无重复项:new 一个 Set,参数为需要去重的数组,Set 会自动删除重复的元素,再将 Set 转为数组返回。这个方法的优点是效率更高,代码简单,思路清晰,缺点是可能会有兼容性问题
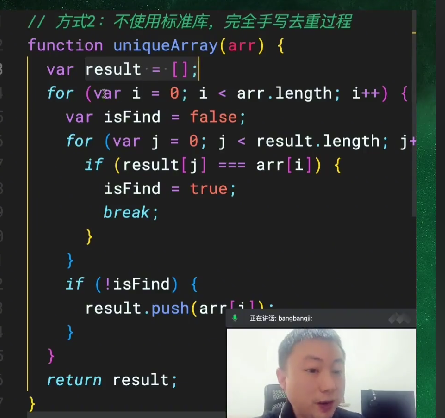
第三种方法:filter+indexof 去重:这个方法和第一种方法类似,利用 Array 自带的 filter 方法,返回 arr.indexOf(num) 等于 index 的num。原理就是 indexOf 会返回最先找到的数字的索引,假设数组是 [1, 1],在对第二个1使用 indexOf 方法时,返回的是第一个1的索引0。这个方法的优点是可以在去重的时候插入对元素的操作,可拓展性强。
const array = [1, 2, 3, 4, 5, 6, 7, 8, 9, 4, 5, 6, 7, 9,]
const newArr = array.filter((item, i, arr) => {
return arr.indexOf(item) === i
})
console.log(newArr);// 打印 [1, 2, 3, 4, 5, 6, 7, 8, 9]
第四种方法:这个方法比较巧妙,从头遍历数组,如果元素在前面出现过,则将当前元素挪到最后面,继续遍历,直到遍历完所有元素,之后将那些被挪到后面的元素抛弃。这个方法因为是直接操作数组,占用内存较少。
第五种方法:reduce +includes去重:这个方法就是利用reduce遍历和传入一个空数组作为去重后的新数组,然后内部判断新数组中是否存在当前遍历的元素,不存在就插入到新数组中。这种方法时间消耗多,内存空间也有额外占用。
var arr = [1,2,3,3,2,1,4]
arr.reduce((acc, cur) => {
if (!(acc.includes(cur))) {
acc.push(cur)
}
return acc
}, [])
// [1, 2, 3, 4]
加分回答
以上五个方法中,在数据低于10000条的时候没有明显的差别,高于10000条,第一种和第二种的时间消耗最少,后面三种时间消耗依次增加,由于第一种内存空间消耗比较多,且现在很多项目不再考虑低版本浏览器的兼容性问题,所以建议使用第二种去重方法,简洁方便。
map数组对象去重
12、伪数组和数组的区别
得分点
属性要为索引(数字)属性,必须有length属性,类型是object,可以使用for in遍历

伪数组的常见场景:
- 函数的参数arguments,实参列表
- 原生js获取DOM:document.querySelector(‘div’) 等
加分回答
伪数组转换成真数组方法
- Array.prototype.slice.call(伪数组)
- [].slice.call(伪数组)
- Array.from(伪数组) 转换后的数组长度由
length属性决定。索引不连续时转换结果是连续的,会自动补位。
13、map 和 forEach 的区别
map创建新数组,处理速度比forEach快,而且返回一个新的数组,方便链式调用其他数组新方法
forEach()不修改原数组、forEach()方法返回undefined
14、es6中箭头函数
消除函数二义性(另一个ES6做的是class);
面向对象的函数往往有两个含义,一个是指令序列(按某种顺序执行),一个是创建实例;
过去JS调用函数有a()还有new a(),这是设计缺陷,所以出现了在命名上作区分,比如构造函数命名大写,但不是强约束力,有些构造函数可以Number()也可以new Number(),Date也是;
class A{ }
new A()
const a=()=>{}
a()*//1、不能用new去调用
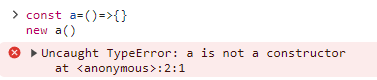
1、不能用new去调用
2、箭头函数没有this,因为箭头函数代表指令序列,跟面向对象没有关系,this是来自面向对象里面的概念
3、箭头函数没有原型(没有arguments,不能使用new,不能作为构造函数, 没有原型和super,不能使用yield关键字,因此箭头函数不能用作Generator 函数。不能返回直接对象字面量),为了消除二义性,因为箭头函数代表指令序列,跟面向对象无关,不需要创建实例,而原型跟实例密切相关,跟指令序列无关,原型是实现面向对象的手段
箭头函数的不适用场景:
- 定义对象上的方法 当调用
dog.jumps时,lives并没有递减。因为this没有绑定值,而继承父级作用域。 var dog = { lives: 20, jumps: () => { this.lives–; } } - 不适合做事件处理程序 此时触发点击事件,this不是button,无法进行class切换 var button = document.querySelector(‘button’); button.addEventListener(‘click’, () => { this.classList.toggle(‘on’); });
15、事件扩展符用过吗(…),什么场景下
得分点
等价于apply的方式、将数组展开为构造函数的参数、数组字符串连接、浅拷贝
标准回答
展开语法可以在函数调用/数组构造时,将数组表达式或者string在语法层面展开;还可以在构造字面量对象时, 将对象表达式按key-value的方式展开。
常见的场景:等价于apply的方式、将数组展开为构造函数的参数、字面量数组或字符串连接不需要使用concat等方法了、构造字面量对象时,进行浅克隆或者属性拷贝
16、闭包
得分点
变量背包、作用域链、局部变量不销毁、函数体外访问函数的内部变量、内存泄漏、内存溢出、形成块级作用域、柯里化、构造函数中定义特权方法、Vue中数据响应式Observer
标准回答
闭包 一个函数和词法环境的引用捆绑在一起,这样的组合就是闭包(closure)。一般就是一个函数A,return其内部的函数B,被return出去的B函数能够在外部访问A函数内部的变量,这时候就形成了一个B函数的变量背包,A函数执行结束后这个变量背包也不会被销毁,并且这个变量背包在A函数外部只能通过B函数访问。
闭包形成的原理:作用域链,当前作用域可以访问上级作用域中的变量 闭包解决的问题:能够让函数作用域中的变量在函数执行结束之后不被销毁,同时也能在函数外部可以访问函数内部的局部变量。
闭包带来的问题:由于垃圾回收器不会将闭包中变量销毁,于是就造成了内存泄露,内存泄露积累多了就容易导致内存溢出。
闭包的应用,能够模仿块级作用域,能够实现柯里化,在构造函数中定义特权方法、Vue中数据响应式Observer中使用闭包等。
17、JS变量提升
得分点
Var声明的变量声明提升、函数声明提升、let和const变量不提升
标准回答
变量提升是指JS的变量和函数声明会在代码编译期,提升到代码的最前面。 变量提升成立的前提是使用Var关键字进行声明的变量,并且变量提升的时候只有声明被提升,赋值并不会被提升,同时函数的声明提升会比变量的提升优先。 变量提升的结果,可以在变量初始化之前访问该变量,返回的是undefined。在函数声明前可以调用该函数。
加分回答
使用let和const声明的变量是创建提升,形成暂时性死区,在初始化之前访问let和const创建的变量会报错。
1、污染全局
一旦var声明后,该变量将会挂载到全局window上,let不会
2、块级作用域
3、重复声明
另,前面用var后面用let也是会报错的
4、暂时性死区(TDZ)
let、const都会提升,
在翻阅MDN文档时,发现中文翻译,原文会砍半
let虽然提升了,但是做了个处理,在提升的第一行和声明语句前,形成了暂时性死区,
在暂时性死区内,是不能访问的
18、this指向

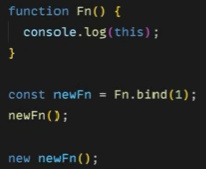
 Fn()不等于newFn()
Fn()不等于newFn()
可以扩展箭头函数
得分点
全局执行上下文、函数执行上下文、this严格模式下undefined、非严格模式window、构造函数新对象本身、普通函数不继承this、箭头函数无this,可继承 标准回答 this关键字由来:在对象内部的方法中使用对象内部的属性是一个非常普遍的需求。但是 JavaScript 的作用域机制并不支持这一点,基于这个需求,JavaScript 又搞出来另外一套 this 机制。 this存在的场景有三种全局执行上下文和函数执行上下文和eval执行上下文,eval这种不讨论。在全局执行环境中无论是否在严格模式下,(在任何函数体外部)this 都指向全局对象。在函数执行上下文中访问this,函数的调用方式决定了 this 的值。在全局环境中调用一个函数,函数内部的 this 指向的是全局变量 window,通过一个对象来调用其内部的一个方法,该方法的执行上下文中的 this 指向对象本身。 普通函数this指向:当函数被正常调用时,在严格模式下,this 值是 undefined,非严格模式下 this 指向的是全局对象 window;通过一个对象来调用其内部的一个方法,该方法的执行上下文中的 this 指向对象本身。new 关键字构建好了一个新对象,并且构造函数中的 this 其实就是新对象本身。嵌套函数中的 this 不会继承外层函数的 this 值。 箭头函数this指向:箭头函数并不会创建其自身的执行上下文,所以箭头函数中的 this 取决于它的外部函数。
加分回答
箭头函数因为没有this,所以也不能作为构造函数,但是需要继承函数外部this的时候,使用箭头函数比较方便 var myObj = { name : “闷倒驴”, showThis:function(){ console.log(this); // myObj var bar = ()=>{ this.name = “王美丽”; console.log(this) // myObj } bar(); } }; myObj.showThis(); console.log(myObj.name); // “王美丽” console.log(window.name); // ‘’
19、说一说call apply bind的作用和区别?
得分点
bind改变this指向不直接调用、call和apply改变this指向直接调用、apply接收第二个参数为数组 、call用于对象的继承 、伪数组转换成真数组、apply用于找出数组中的最大值和最小值以及数组合并、bind用于vue或者react框架中改变函数的this指向 标准回答 call、apply、bind的作用都是改变函数运行时的this指向。 bind和call、apply在使用上有所不同,bind在改变this指向的时候,返回一个改变执行上下文的函数,不会立即执行函数,而是需要调用该函数的时候再调用即可,但是call和apply在改变this指向的同时执行了该函数。 bind只接收一个参数,就是this指向的执行上文。 call、apply接收多个参数,第一个参数都是this指向的执行上文,后面的参数都是作为改变this指向的函数的参数。但是call和apply参数的格式不同,call是一个参数对应一个原函数的参数,但是apply第二个参数是数组,数组中每个元素代表函数接收的参数,数组有几个元素函数就接收几个元素。
加分回答
call的应用场景: 对象的继承,在子构造函数这种调用父构造函数,但是改变this指向,就可以继承父的属性 function superClass () { this.a = 1; this.print = function () { console.log(this.a); } } function subClass () { superClass.call(this); // 执行superClass,并将superClass方法中的this指向subClass this.print(); } subClass(); 借用Array原型链上的slice方法,把伪数组转换成真数组 let domNodes = Array.prototype.slice.call(document.getElementsByTagName(“div”));
apply的应用场景: Math.max,获取数组中最大、最小的一项 let max = Math.max.apply(null, array); let min = Math.min.apply(null, array); 实现两个数组合并 let arr1 = [1, 2, 3]; let arr2 = [4, 5, 6]; Array.prototype.push.apply(arr1, arr2); console.log(arr1); // [1, 2, 3, 4, 5, 6]
bind的应用场景 在vue或者react框架中,使用bind将定义的方法中的this指向当前类
20、new会发生什么?
得分点
创建空对象、为对象添加属性、把新对象当作this的上下文、箭头函数不能作为构造函数
标准回答 new 关键字会进行如下的操作:
- 创建一个空的简单JavaScript对象(即
{}); - 为步骤1新创建的对象添加属性
__proto__,将该属性链接至构造函数的原型对象 ; - 将步骤1新创建的对象作为
this的上下文 ; - 如果该函数没有返回对象,则返回
this。
加分回答 new关键字后面的构造函数不能是箭头函数。
21、defer和async区别?
资源提示符
rel后的总共有
async
defer
preload
prefetch
prerender
preconnect
前两个是附着在script元素上的
遇到script暂停解析,通过另一个网络线程,去远程获取js文件,再去执行js,完成同步代码后,继续解析dom。主线程会有空窗期。一般js写在body元素末尾,保证dom解析完后执行js,现在有两个更好的办法:
遇到script,去远程获取js文件,不会暂停解析
1、async
这个不一定dom全部加载完成
2、defer
有点像DOMContentLoaded,主线程把dom元素全部解析完成后,再去运行js。这个一定是dom完成了
async和defer发生时间是在DOMContentLoaded之前
<script type="module">
他的资源提示符默认就是defer
<link rel="preload">
link元素上的资源提示符,preload和prefetch
async和defer是拿资源并且要执行,preload和prefetch是拿资源但是不执行,可以拿任何资源js css和图片
1、preload
不会阻塞dom解析,会有缓存,优先级很高,这个资源马上会用到,发出的网络请求时间很早

2、prefetch
优先级低,会在空闲的时候去取

其他页面用到的,preload,自身页面用到的prefetch,闲着也是闲着
22、promise(尚未,太多)
23、JS实现异步的方法
得分点
回调函数、事件监听、setTimeout、Promise、生成器Generators/yield、async/awt
标准回答
所有异步任务都是在同步任务执行结束之后,从任务队列中依次取出执行。 回调函数是异步操作最基本的方法,比如AJAX回调,
回调函数的优点是简单、容易理解和实现,缺点是不利于代码的阅读和维护,各个部分之间高度耦合,使得程序结构混乱、流程难以追踪(尤其是多个回调函数嵌套的情况),而且每个任务只能指定一个回调函数。此外它不能使用 try catch 捕获错误,不能直接 return Promise包装了一个异步调用并生成一个Promise实例,当异步调用返回的时候根据调用的结果分别调用实例化时传入的resolve 和 reject方法,then接收到对应的数据,做出相应的处理。Promise不仅能够捕获错误,而且也很好地解决了回调地狱的问题,缺点是无法取消 Promise,错误需要通过回调函数捕获。
Generator 函数是 ES6 提供的一种异步编程解决方案,Generator 函数是一个状态机,封装了多个内部状态,可暂停函数, yield可暂停,next方法可启动,每次返回的是yield后的表达式结果。优点是异步语义清晰,缺点是手动迭代Generator 函数很麻烦,实现逻辑有点绕
async/awt是基于Promise实现的,async/awt使得异步代码看起来像同步代码,所以优点是,使用方法清晰明了,缺点是awt 将异步代码改造成了同步代码,如果多个异步代码没有依赖性却使用了 awt 会导致性能上的降低,代码没有依赖性的话,完全可以使用 Promise.all 的方式。
加分回答
JS 异步编程进化史:callback -> promise -> generator/yield -> async/awt。 async/awt函数对 Generator 函数的改进,体现在以下三点:
- 内置执行器。 Generator 函数的执行必须靠执行器,而 async 函数自带执行器。也就是说,async 函数的执行,与普通函数一模一样,只要一行。
- 更广的适用性。 yield 命令后面只能是 Thunk 函数或 Promise 对象,而 async 函数的 awt 命令后面,可以跟 Promise 对象和原始类型的值(数值、字符串和布尔值,但这时等同于同步操作)。
- 更好的语义。 async 和 awt,比起星号和 yield,语义更清楚了。async 表示函数里有异步操作,awt 表示紧跟在后面的表达式需要等待结果。 目前使用很广泛的就是promise和async/awt
24、cookie sessionStorage localStorage 区别
得分点
数据存储位置、生命周期、存储大小、写入方式、数据共享、发送请求时是否携带、应用场景
标准回答
Cookie、SessionStorage、 LocalStorage都是浏览器的本地存储。
它们的共同点:都是存储在浏览器本地的
它们的区别:cookie是由服务器端写入的,而SessionStorage、 LocalStorage都是由前端写入的,cookie的生命周期是由服务器端在写入的时候就设置好的,LocalStorage是写入就一直存在,除非手动清除,SessionStorage是页面关闭的时候就会自动清除。cookie的存储空间比较小大概4KB,SessionStorage、 LocalStorage存储空间比较大,大概5M。Cookie、SessionStorage、 LocalStorage数据共享都遵循同源原则,SessionStorage还限制必须是同一个页面。在前端给后端发送请求的时候会自动携带Cookie中的数据,但是SessionStorage、 LocalStorage不会
加分回答 由于它们的以上区别,所以它们的应用场景也不同,Cookie一般用于存储登录验证信息SessionID或者token,LocalStorage常用于存储不易变动的数据,减轻服务器的压力,SessionStorage可以用来检测用户是否是刷新进入页面,如音乐播放器恢复播放进度条的功能。
25、如何实现可过期的localstorage数据?
得分点
惰性删除、定时删除
标准回答
localStorage只能用于长久保存整个网站的数据,保存的数据没有过期时间,直到手动去删除。所以要实现可过期的localStorage缓存的中重点就是:如何清理过期的缓存。 目前有两种方法,一种是惰性删除,另一种是定时删除。 惰性删除是指某个键值过期后,该键值不会被马上删除,而是等到下次被使用的时候,才会被检查到过期,此时才能得到删除。实现方法是,存储的数据类型是个对象,该对象有两个key,一个是要存储的value值,另一个是当前时间。获取数据的时候,拿到存储的时间和当前时间做对比,如果超过过期时间就清除Cookie。 定时删除是指,每隔一段时间执行一次删除操作,并通过限制删除操作执行的次数和频率,来减少删除操作对CPU的长期占用。另一方面定时删除也有效的减少了因惰性删除带来的对localStorage空间的浪费。实现过程,获取所有设置过期时间的key判断是否过期,过期就存储到数组中,遍历数组,每隔1S(固定时间)删除5个(固定个数),直到把数组中的key从localstorage中全部删除。
加分回答 LocalStorage清空应用场景:token存储在LocalStorage中,要清空
26、token 能放在cookie中吗?
得分点
能、不设置cookie有效期、重新登录重写cookie覆盖原来的cookie
标准回答
能。 token一般是用来判断用户是否登录的,它内部包含的信息有:uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,token 的前几位以哈希算法压缩成的一定长度的十六进制字符串) token可以存放在Cookie中,token 是否过期,应该由后端来判断,不该前端来判断,所以token存储在cookie中只要不设置cookie的过期时间就ok了,如果 token 失效,就让后端在接口中返回固定的状态表示token 失效,需要重新登录,再重新登录的时候,重新设置 cookie 中的 token 就行。
加分回答
token认证流程 1. 客户端使用用户名跟密码请求登录 2. 服务端收到请求,去验证用户名与密码 3. 验证成功后,服务端签发一个 token ,并把它发送给客户端 4. 客户端接收 token 以后会把它存储起来,比如放在 cookie 里或者 localStorage 里 5. 客户端每次发送请求时都需要带着服务端签发的 token(把 token 放到 HTTP 的 Header 里) 6. 服务端收到请求后,需要验证请求里带有的 token ,如验证成功则返回对应的数据


27、axios的拦截器原理及应用
得分点
请求(request)拦截器、响应(response)拦截器、Promise控制执行顺序、每个请求带上相应的参数、返回的状态进行判断(token是否过期)
标准回答
axios的拦截器的应用场景: 请求拦截器用于在接口请求之前做的处理,比如为每个请求带上相应的参数(token,时间戳等)。 返回拦截器用于在接口返回之后做的处理,比如对返回的状态进行判断(token是否过期)。 xios为开发者提供了这样一个API:拦截器。拦截器分为 请求(request)拦截器和 响应(response)拦截器。 拦截器原理:创建一个chn数组,数组中保存了拦截器相应方法以及dispatchRequest(dispatchRequest这个函数调用才会真正的开始下发请求),把请求拦截器的方法放到chn数组中dispatchRequest的前面,把响应拦截器的方法放到chn数组中dispatchRequest的后面,把请求拦截器和相应拦截器forEach将它们分unshift,push到chn数组中,为了保证它们的执行顺序,需要使用promise,以出队列的方式对chn数组中的方法挨个执行。
加分回答
Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 node.js 中。从浏览器中创建 XMLHttpRequests,从 node.js 创建 http 请求,支持 Promise API,可拦截请求和响应,可转换请求数据和响应数据,可取消请求,可自动转换 JSON 数据,客户端支持防御 XSRF
28、创建ajax过程
得分点 new XMLHttpRequest()、设置请求参数open()、发送请求request.send()、响应request.onreadystatechange
标准回答
创建ajax过程:
- 创建XHR对象:new XMLHttpRequest()
- 设置请求参数:request.open(Method, 服务器接口地址);
- 发送请求: request.send(),如果是get请求不需要参数,post请求需要参数request.send(data)
- 监听请求成功后的状态变化:根据状态码进行相应的处理。 XHR.onreadystatechange = function () { if (XHR.readyState == 4 && XHR.status == 200) { console.log(XHR.responseText); // 主动释放,JS本身也会回收的 XHR = null; } };
加分回答
POST请求需要设置请求头
readyState值说明
0:初始化,XHR对象已经创建,还未执行open
1:载入,已经调用open方法,但是还没发送请求
2:载入完成,请求已经发送完成
3:交互,可以接收到部分数据
创建ajax过程:
- 创建XHR对象:new XMLHttpRequest()
- 设置请求参数:request.open(Method, 服务器接口地址);
- 发送请求: request.send(),如果是get请求不需要参数,post请求需要参数request.send(data)
- 监听请求成功后的状态变化:根据状态码进行相应的处理。 XHR.onreadystatechange = function () { if (XHR.readyState == 4 && XHR.status == 200) { console.log(XHR.responseText); // 主动释放,JS本身也会回收的 XHR = null; } };
加分回答
POST请求需要设置请求头
readyState值说明
0:初始化,XHR对象已经创建,还未执行open
1:载入,已经调用open方法,但是还没发送请求
2:载入完成,请求已经发送完成
3:交互,可以接收到部分数据
4:数据全部返回 status值说明 200:成功 404:没有发现文件、查询或URl 500:服务器产生内部错误