一、铺垫
1、HiveQL 在执行时会转化为各种计算引擎的能够运行的算子,这里以mr引擎为切入点,要想让HiveQL 的效率更高,就要理解HiveQL 是如何转化为MapReduce任务的
2、hive是基于hadoop的,分布式引擎采用mr、spark、tze,调度使用的yarn,分布式存储使用的hdfs,而一般大数据的性能瓶颈往往在带宽消耗和磁盘IO,cpu往往不是瓶颈。因此hive优化的焦点是如何降低作业的IO和带宽消耗。
MapReduce任务有如下特点:
每次作业都需要作业分配、初始化、上传配置、中间结果落盘、shuffle (消耗带宽)、结果输出
因此减少MapReduce作业的数量,并对MapReduce进行优化即可实现优化
二、MapReduce运行原理
《Hadoop-MapReduce使用说明》、《Hadoop-MapReduce-跟着日志理解整体流程》、《Hadoop-MapReduce-源码跟读-客户端篇》、《Hadoop-MapReduce-MRAppMaster启动篇》、《Hadoop-MapReduce-YarnChild启动篇》、《Hadoop-MapReduce-源码跟读-MapTask阶段篇》、《Hadoop-MapReduce-源码跟读-ReduceTask阶段篇》中已经进行了详细的描述,这里着重提一下Shuffle
Shuffle是指从Mapper的输出到Reducer输入的整个过程
它是制约MapReduce性能的关键因素,但也因为有了它才能让Hadoop可以在一些廉价的服务器上运行
Mapper中的map()会将数据计算所在分区后写入到环形缓冲区,环形缓冲区大小为 mapreduce.task.io.sort.mb=100MB 当环形缓冲区达到一定阈值,默认为 mapreduce.map.sort.spill.percent=0.8,即总缓冲区的80%时,将会启动新的线程将数据写入到HDFS临时目录中。这样设计的可以减少单条写磁盘带来的IO消耗,与关系型数据库中的批量提交思路相似。为了Reducer端可以按照顺序快速拉取数据,在溢写磁盘时会将数据进行排序后再写入临时文件,整个Map任务结束后会将临时文件合并成一个文件。(多个小文件不能更好的利用带宽)如果不进行排序归并,会导致Reducer端触发多次拉取数据,网络传输和磁盘搜索、读写都会增加。Map任务结束,Reducer端会启动拉取数据的线程。Reducer从HDFS临时目录拉取数据后,也会先缓存到缓冲区,当到达一定阈值,写入准备好的内存,数据量再大,再写入磁盘,再大就进行归并。
为什么不让Map端直接将数据推到Reduce端?这样即不用写磁盘,Reduce也不用启动线程了
Hadoop设计架构还要考虑健壮性,如果Reduce失败,Map端很难再推一次,而写入到HDFS临时目录,Reducer就可以再次拉取属于自己的数据
三、执行计划
通过执行计划可以了解HiveQL转化成相应计算引擎的执行逻辑,了解了执行逻辑可以让我们更容易找到HiveQL 的瓶颈和优化方式。也可以透彻理解很多现象:比如:看似相同的HiveQL 其实是不等价的,看似不相同的HiveQL ,其实是等价的。
Hive不同的版本生成执行计划的方式也是不同的,在Hive早期版本中使用的是基于规则的的方式生成执行计划。Hive1.4之后,引入了Apache Calcite ,使得Hive 可以基于成本代价来生成执行计划Cost based Optimizer。简称 CBO
这种方式能够结合Hive的元数据信息和Hive运行过程中收集的各类统计指标推测出一个更合理的执行计划
相关命令:
查看执行计划的基本信息 :explain
查看执行计划的扩展信息 :explain extended
查看由Calcite优化器生成的计划:explain cbo (hive 4.0.0开始支持)
查看HiveQL 数据输入依赖的信息 :explain dependency
查看HiveQL 操作相关权限的信息 :explain authorization
查看HiveQL 的向量化描述信息 :explain vectorization
示例:
set hive.execution.engine=mr;
explain select telno,sum(visit_num) from test.user_msg group by telno ;

explain extended select telno,sum(visit_num) from test.user_msg group by telno ;

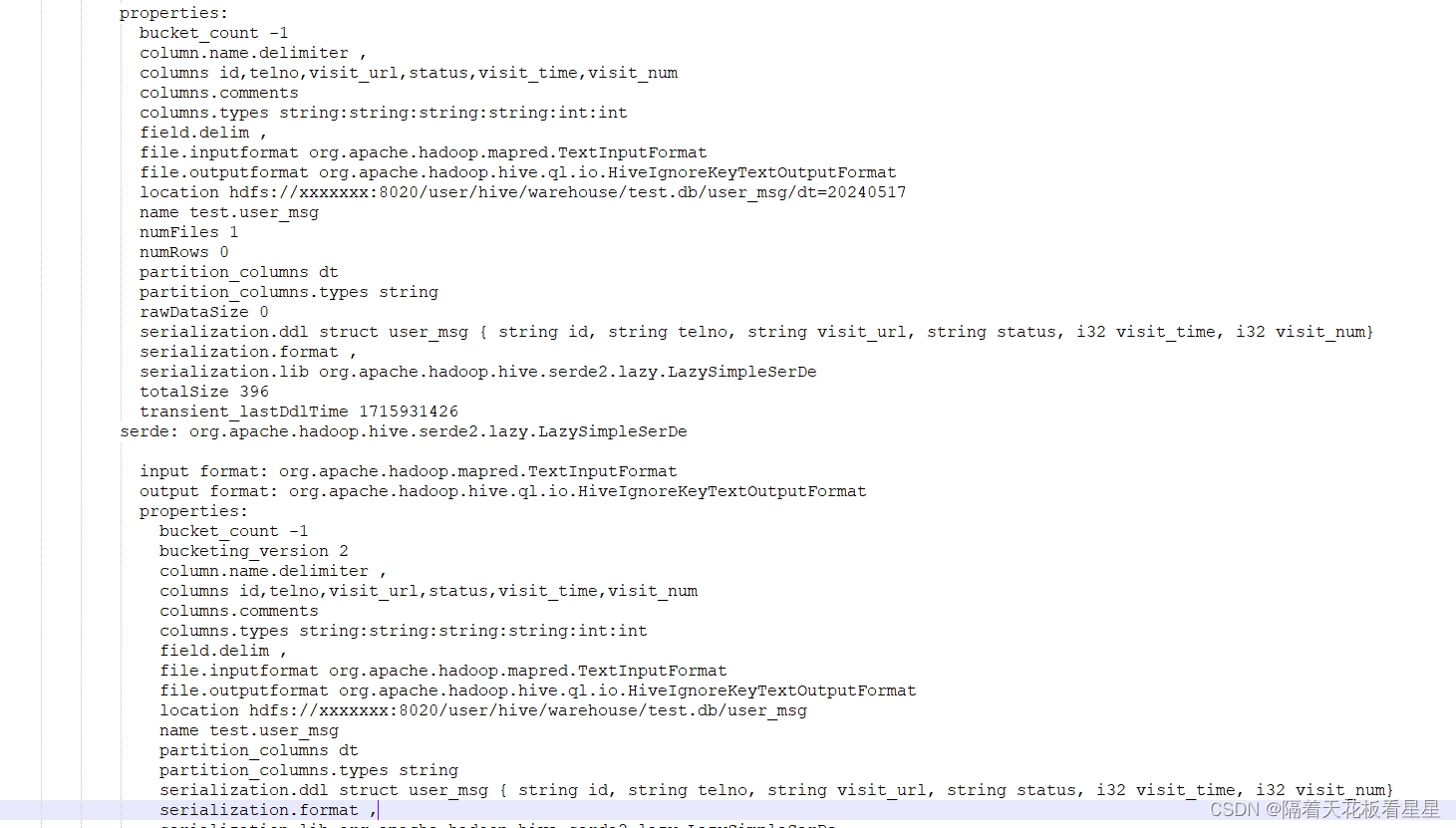
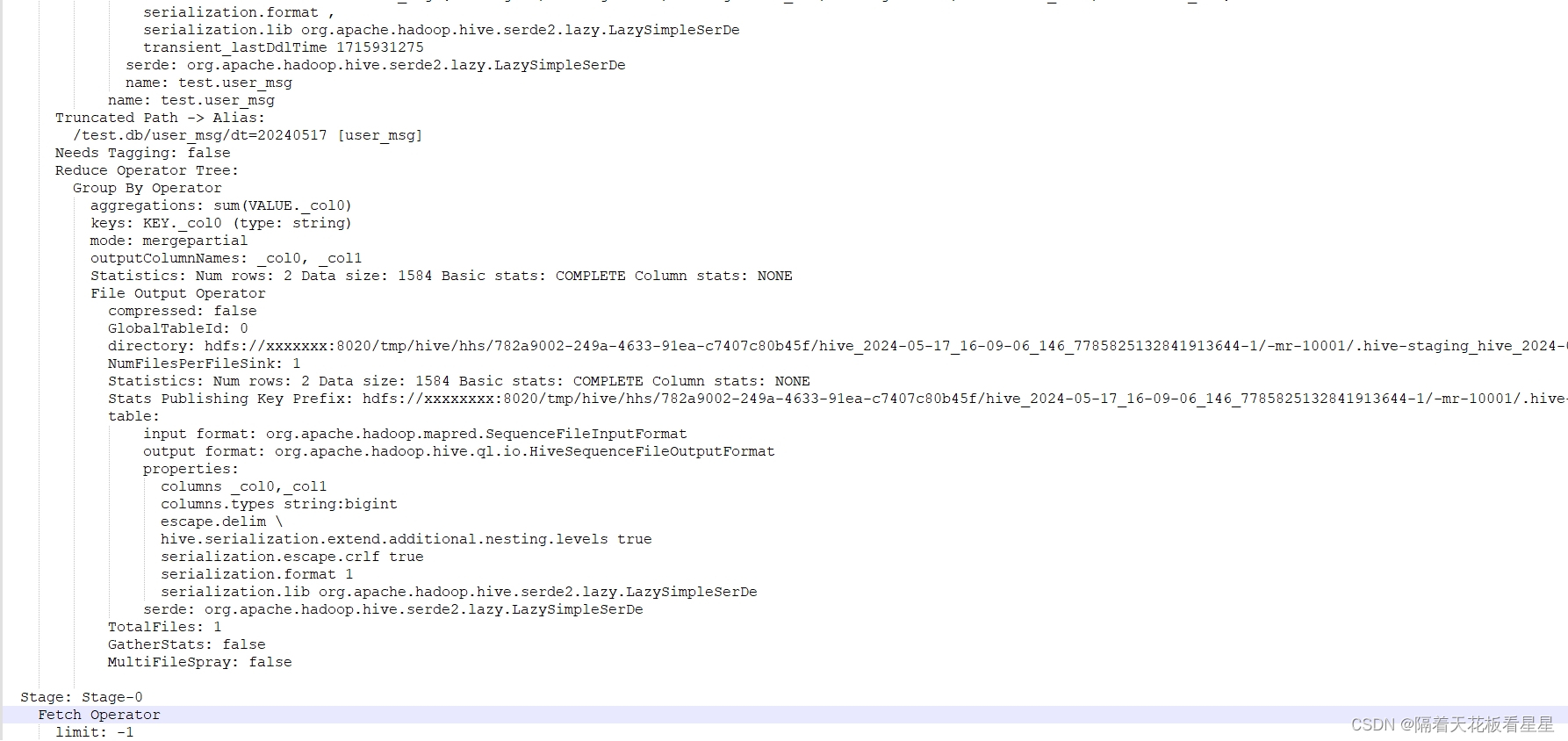
explain extended,顾名思义就是对explain的扩展,打印的信息会比explain更加丰富,包含以下三部分的内容。
1、抽象语法树(Abstract Syntax Tree,AST):是SQL转换成MapReduce或其他计算引擎的任务中的一个过程
2、作业的依赖关系图:即STAGE DEPENDENCIES,其内容和explain所展现的一样
3、每个作业的详细信息,即STAGE PLANS。在打印每个作业的详细信息时,explain extended会打印出更多的信息,除了explain打印出的内容,还包括每个表的HDFS读取路径,每个Hive表的表配置信息等
四、调优
1、HiveQL模式
HiveQL的的语法多种多样,但本质上可以分为以下三种:
过滤模式、聚合模式、连接模式
1.1、过滤模式
即对数据的过滤,从数据的颗粒度上又分为:数据行过滤、数据列过滤、文件过滤、目录过滤。具体又有以下几点:where子句过滤、having子句过滤、distinct命令过滤、表过滤、分区过滤、分桶过滤、索引过滤、列过滤。
1.1.1、where子句过滤
select * from test.user_msq where visit_num> 10 and status = 200 ;
对应的执行计划为:
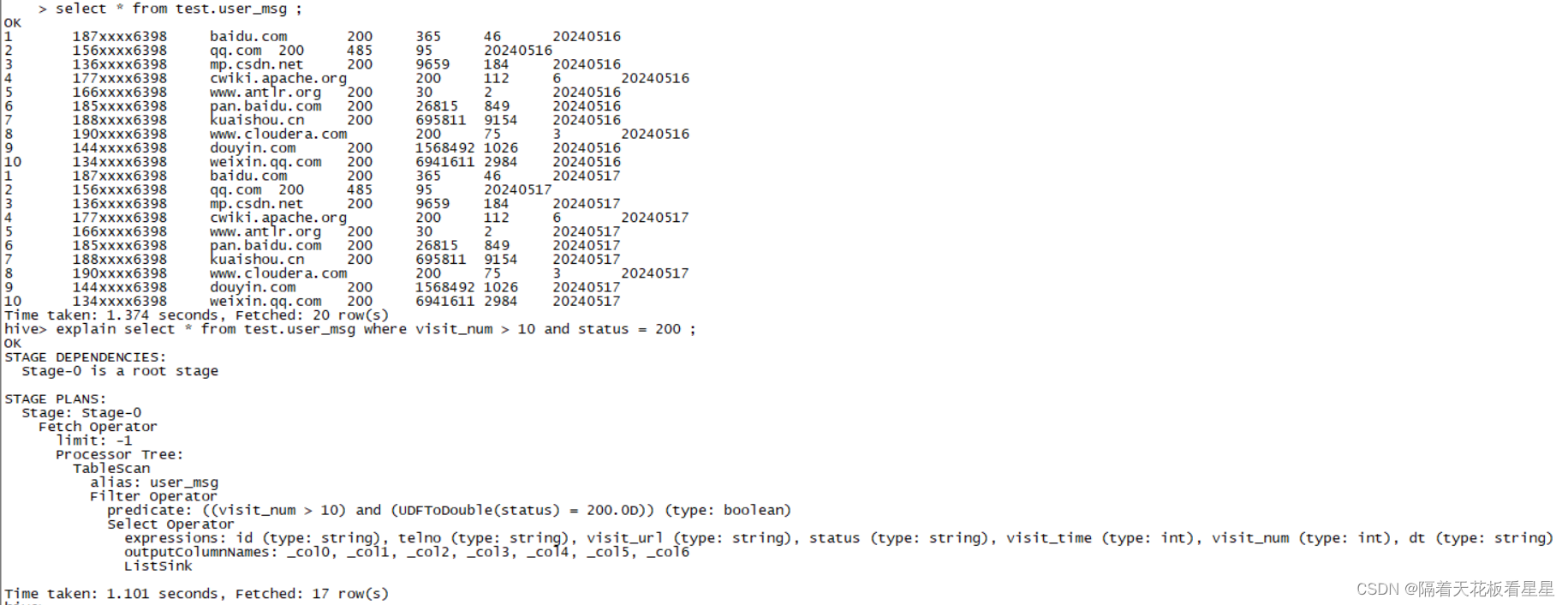
由于表中数太少,该HiveQL都不用转作业
我们新建一张表,扩增数据到100w后发现还是不会转作业,
上面使用的hive版本是3.1.2,下面用2.1.1查看下执行计划
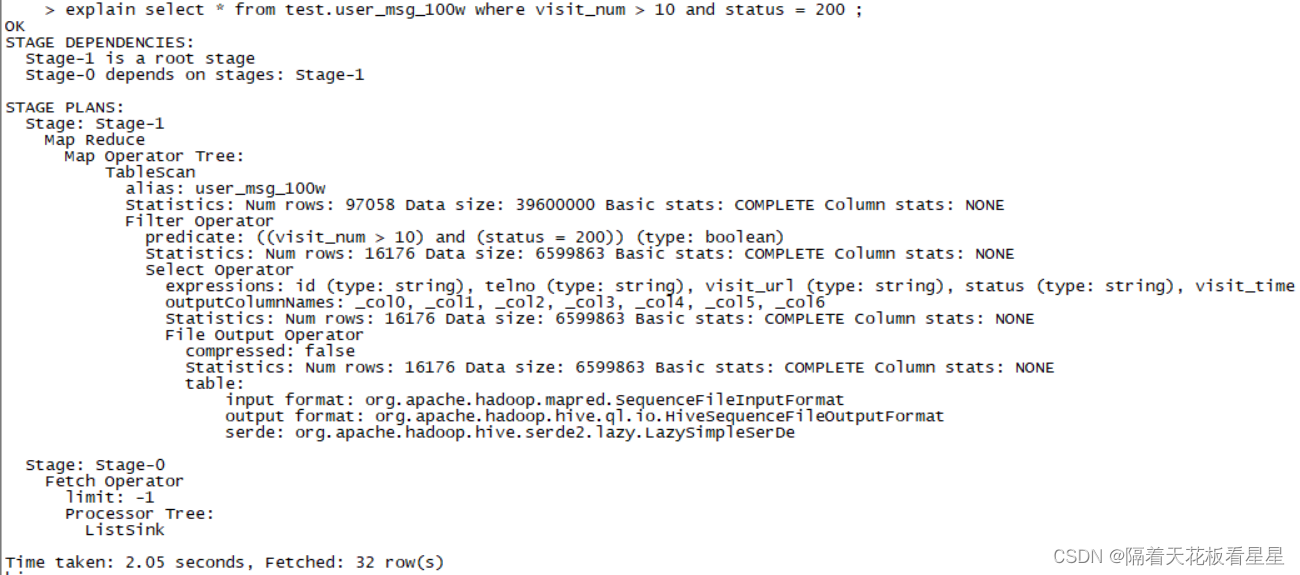
这时发现执行计划只用了MapReduce中的Map阶段就可以完成该任务
由此可见Hive3版本优化的还是挺好的
再来看Hive2中只用到了Map阶段,Map阶段会尽可能的将计算逻辑放到数据所在的节点进行计算,这时可以充分利用分布式的优点,过滤掉大量的数据,因为没有Reduce阶段也就少了很多Shuffle,这无疑是所有HiveQL中效率最高的情况
1.1.2、having子句过滤
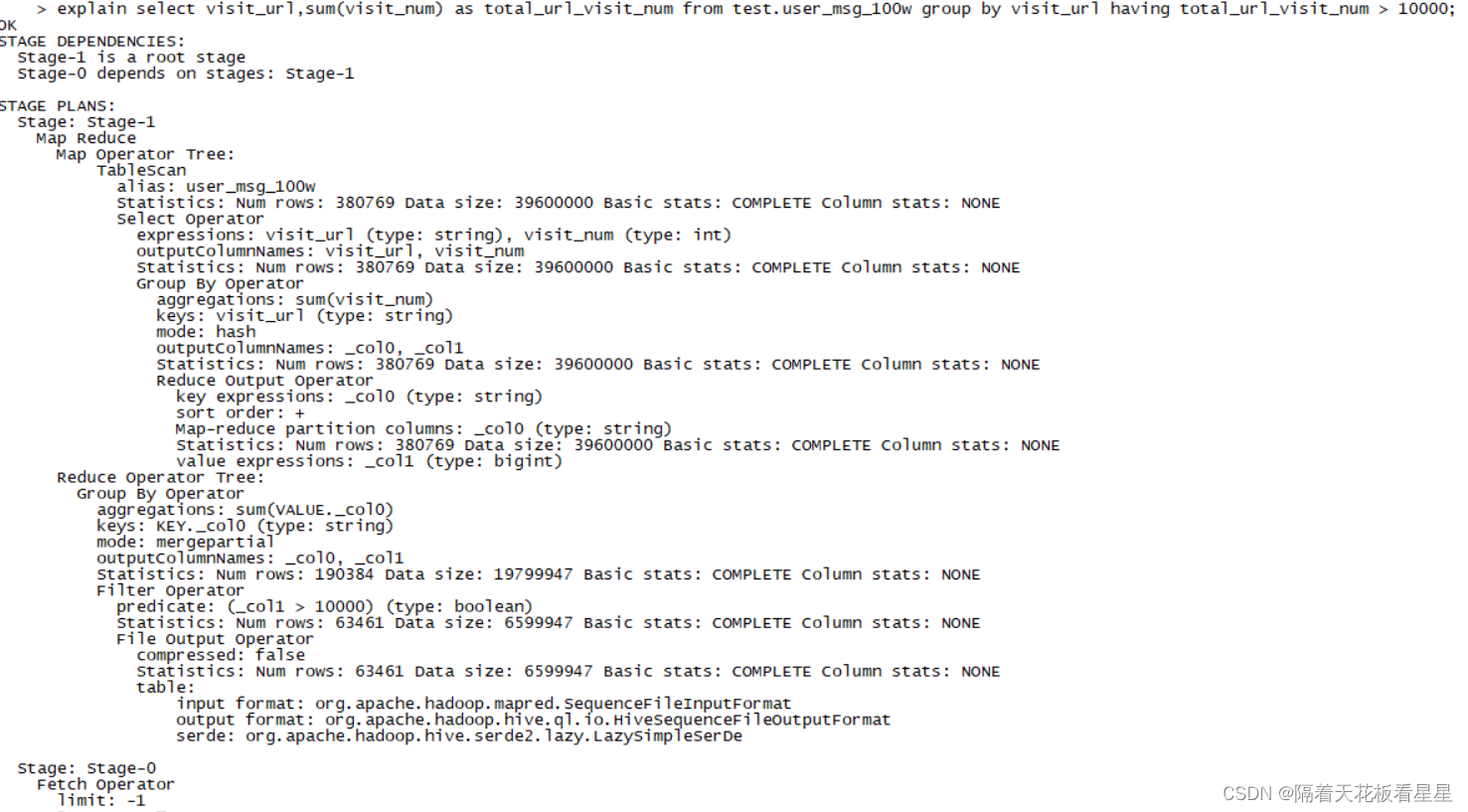
select visit_url,sum(visit_num) as total_url_visit_num from test.user_msg_100w group by visit_url having total_url_visit_num > 10000;
hive2的对应计划为:
hive3的对应计划为:
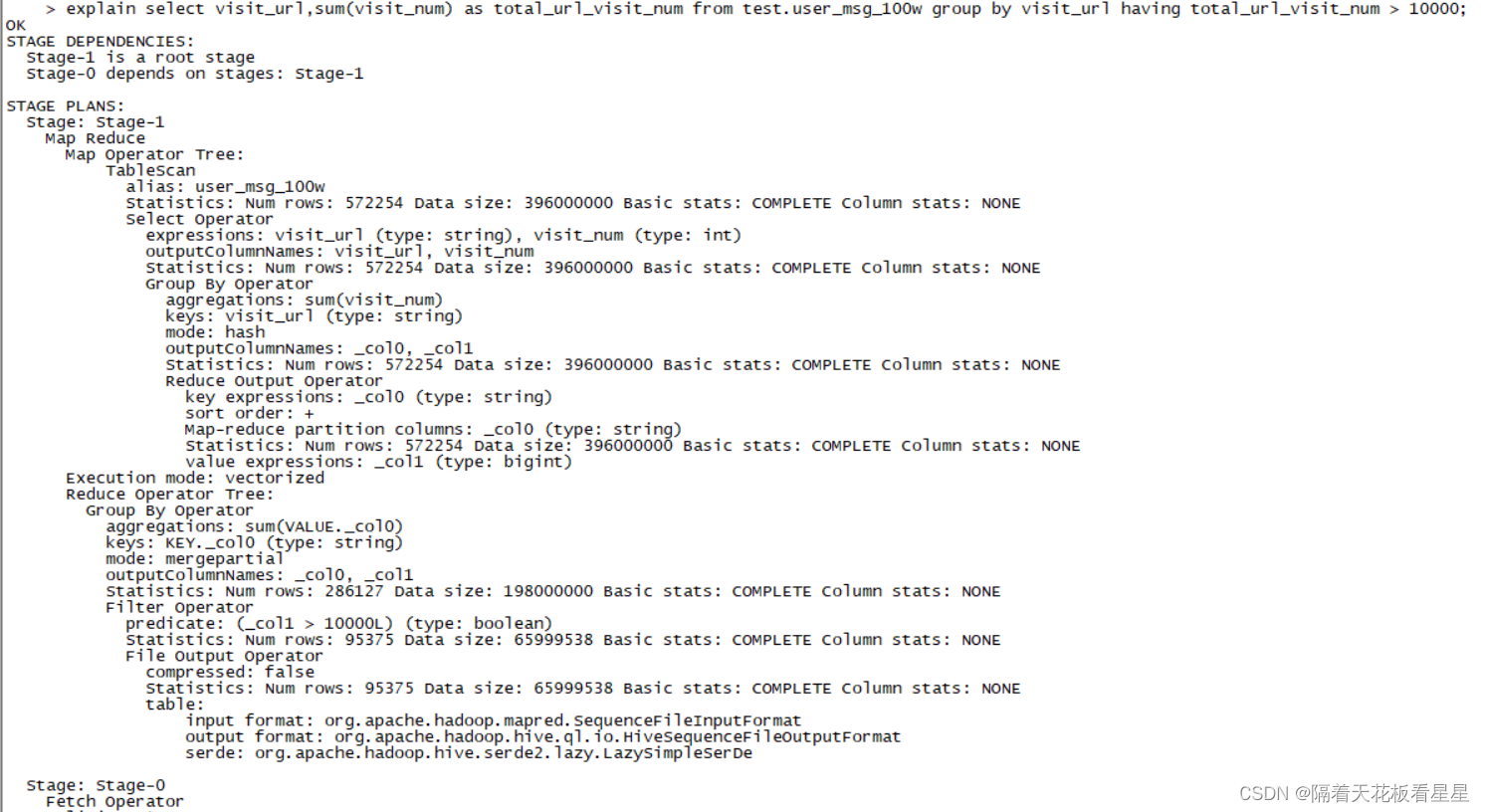
having子句过滤发生在数据聚合后,在MapReduce引擎中表示在Reduce 阶段进行having子句的条件过滤
1.1.3、distinct命令过滤
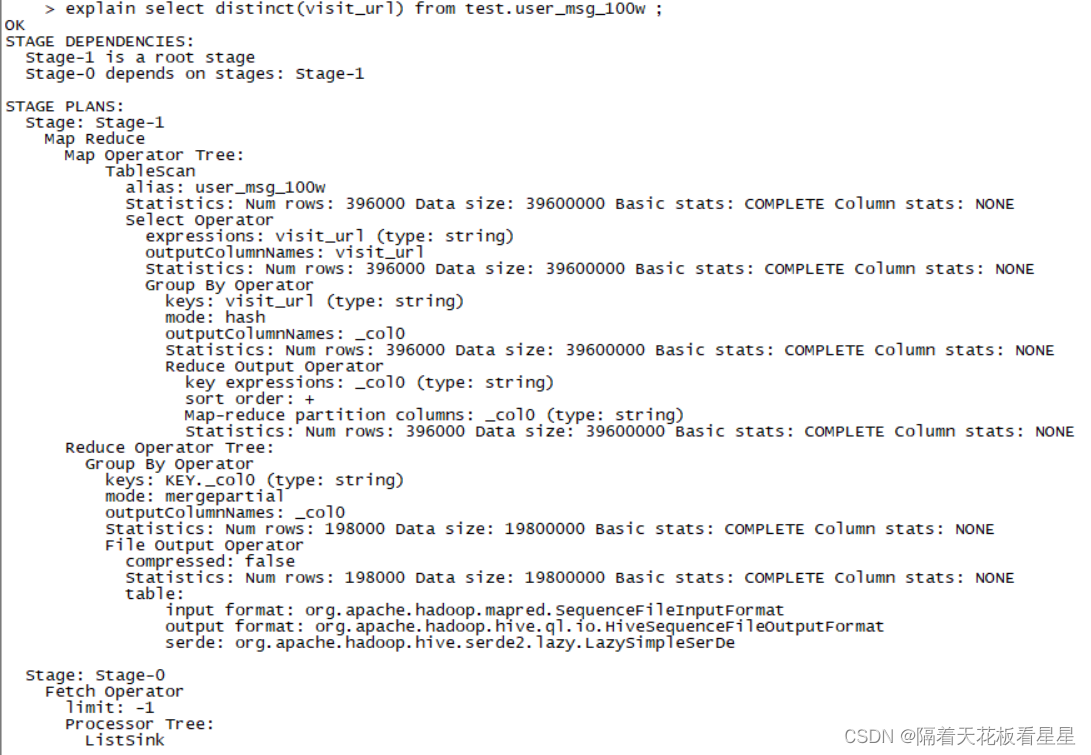
select distinct(visit_url) from test.user_msg_100w ;
hive2的对应计划为:
hive3的对应计划为:
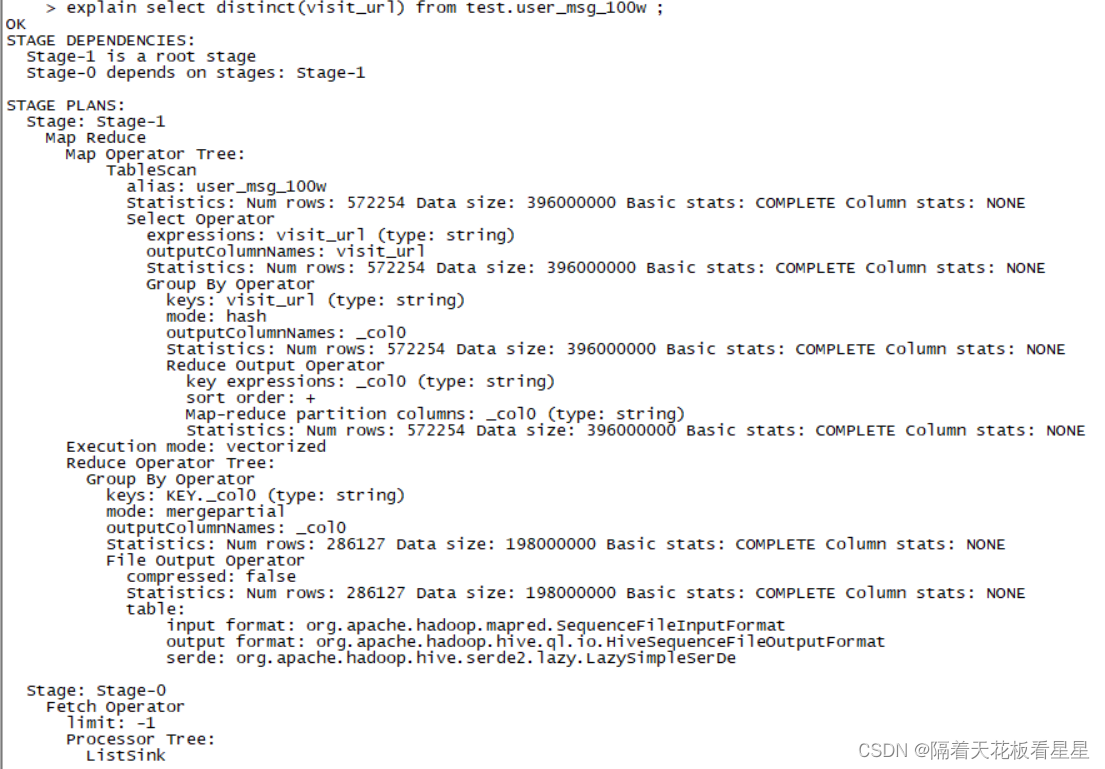
distinct子句用于列投影中过滤重复的数据,在Hive中其实也是发生在 Reduce阶段
从执行计划中看到distinct的处理用了Group By Operator
我们把sql修改成这样:
select visit_url from test.user_msg_100w group by visit_url ;
再看看对应的执行计划:
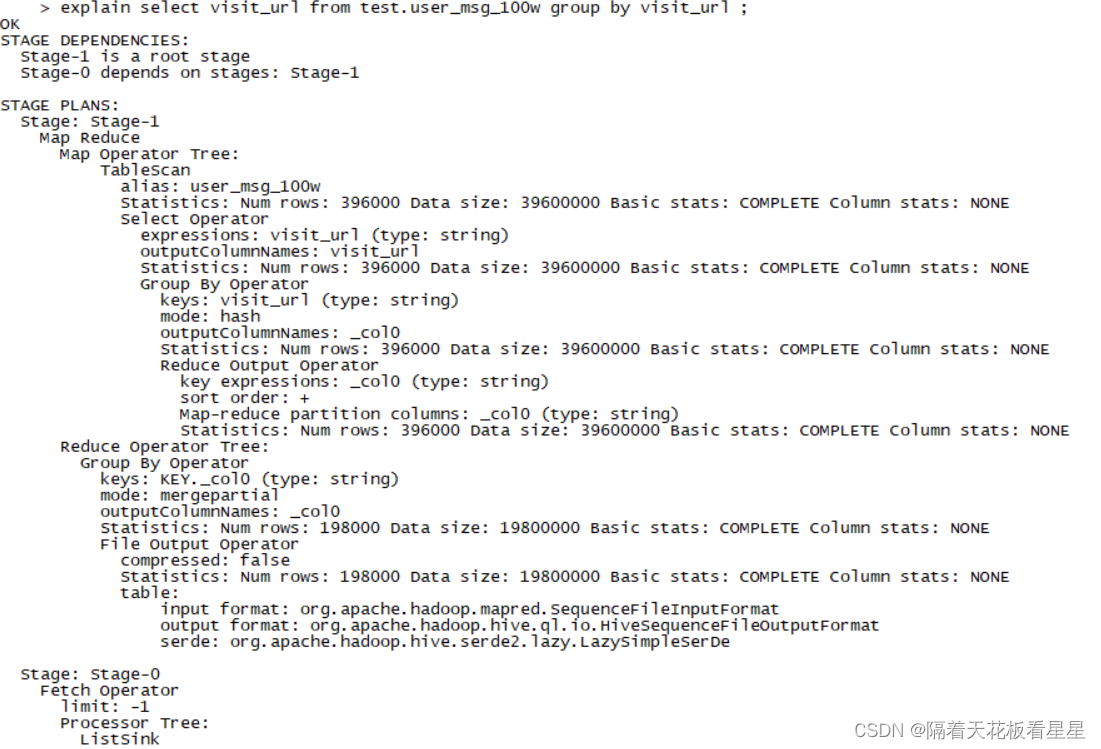
从执行计划中可以看到这两句HiveQL转化成的MapReduce是一样的
注意:使用分组聚合的方式不是Hive去重的唯一方式,有时Hive还会用Hash表进行去重
1.1.4、表过滤
表过滤是指过滤掉同一个SQL语句需要多次访问相同表的数据,将重复 的访问操作过滤掉并压缩成只读取一次。表过滤的常见操作就是使用multigroup-by语法替换多个查询语句求并集的句式。
第一条HiveQL:insert into test.user_msg_temp partition(dt='20240522')
select min(id) as id,telno,visit_url,status,max(visit_time),sum(visit_num) from test.user_msg_100w where dt = '20240521' group by telno,visit_url,status
union all
select min(id) as id,telno,visit_url,status,min(visit_time),sum(visit_num) from test.user_msg_100w where dt = '20240521' group by telno,visit_url,status ;
第二条HiveQL:from test.user_msg_100w
insert into test.user_msg_temp partition(dt='20240522')
select min(id) as id,telno,visit_url,status,max(visit_time),sum(visit_num) where dt = '20240521' group by telno,visit_url,status
insert into test.user_msg_temp partition(dt='20240521')
select min(id) as id,telno,visit_url,status,min(visit_time),sum(visit_num) where dt = '20240521' group by telno,visit_url,status ;
第一条HiveQL在HIive2.1.1和Hive.3.1.2中的执行计划是一样的:省略图如下

我们用图来表示下所有阶段的依赖关系
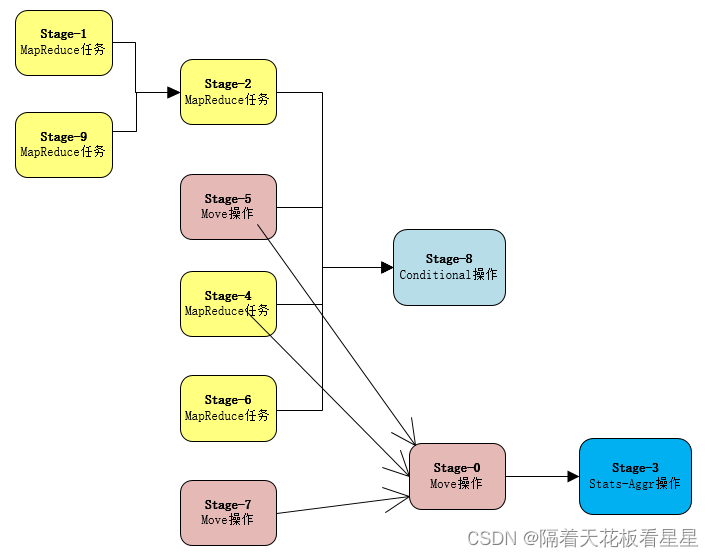
详解:
Stage-1:一个MapReduce任务,执行HiveQL为:
select min(id) as id,telno,visit_url,status,max(visit_time),sum(visit_num) from test.user_msg_100w where dt = '20240521' group by telno,visit_url,status
Stage-9:一个MapReduce任务,执行HiveQL为:
select min(id) as id,telno,visit_url,status,min(visit_time),sum(visit_num) from test.user_msg_100w where dt = '20240521' group by telno,visit_url,status ;
Stage-2:一个Map任务,执行任务为:
将Stage-1和Stage-9的结果进行Union操作
Stage-5:移动数据操作:执行任务为:
将目的路径设置为/user/hive/warehouse/test.db/user_msg_temp/dt=20240522/.hive-staging_hive_2024-05-22_16-10-09_015_8353010693764937166-1/-ext-10000
Stage-4:一个Map任务,执行任务为:
将结果输出到test.user_msg_temp的操作
Stage-6:一个Map任务,执行任务为:
将结果输出到test.user_msg_temp的操作
Stage-8:一个过滤操作,从执行计划上看,什么都没做,空任务
Stage-7:移动数据操作:执行任务为:
将目的路径设置为/user/hive/warehouse/test.db/user_msg_temp/dt=20240522/.hive-staging_hive_2024-05-22_16-10-09_015_8353010693764937166-1/-ext-10000
Stage-0:移动数据操作:执行任务为:
将临时目录的数据移动到指定分区
Stage-3:聚合操作:统计信息的收集
第二条HiveQL在HIive2.1.1和Hive.3.1.2中的执行计划是不同的
HIive2.1.1执行计划

Hive.3.1.2执行计划

1.1.5、分区过滤
分区过滤和普通的where子句过滤写法是一样的,但是作用阶段是不同的,where子句的过滤发生在Map阶段,对每行数据进行分割提取然后进行判断过滤,而分区过滤是发生在输入阶段对输入路径进行过滤,因为分区表的存储格式是以目录形式存在的,一个分区一个目录。
1.1.6、分桶过滤
分桶是将原来表或分区中的数据进行重新组织,就像原本是一池子水,你可以按照自定义的逻辑(比如水的清澈程度)分到每个桶里,桶的数量也是你自己决定。在Hive中桶就是具体的文件。
因此:分区是对目录的过滤,分桶是对文件的过滤
分桶的算法为:
桶号=mod(has(分桶列的值),4)
只需要传入你想要的桶的个数就可以了,hive会通过hash算法处理你分桶的列数据,并用取模的算法得到该条数据应该归属于哪个桶
如果在查询时where条件中包含分桶字段,会大大提升效率
1.1.7、索引过滤
Hive的索引在Hive3.0中已经被废弃,可以使用两种方式代替:
1、物化视图
2、使用ORC/Parquet的文件存储格式(比分桶的粒度更细)
1.1.8、列过滤
Hive和关系型数据库不同,它是以行为单位存取数据的,也就是select 中选择的字段再少也需要将一行数据进行读取、分割和提取。因此想要达到更好的效果就必须使用特殊的存储格式。在ORC/Parquet中存储了文件定义的Schema,Hive可以通过Schema直接读取表中的列,以达到列过滤的目的。
1.2、聚合模式
即数据的聚合,数据聚合意味着在处理数据过程中存在Shuffle的过程,这是我们应该特别注意的地方。
聚合模式即:将多行数据浓缩称一行或者几行的计算模式。会为后续依赖计算大大减少数据量,但是也容易带来不良性能,主要原因有两个:
1、数据倾斜
2、大量数据无法在前面计算,后面又需要它的计算结果
常见的聚合模式有:
1、distinct
如果开启hive.map.aggr=true map阶段会将目标字段进行过滤,reduce阶段进行
聚合去重
2、count计数
count(1)、count(*)、count(列名)都可以进行行数的统计。
count(列名) :如果列中有null的情况不会进行计数,且计算时需要将字节流转化
成对象的序列化和反序列化操作,针对列的统计
count(1) 和 count(*) 类似不会读取表中的数据,只会用到每一行在HDFS上的
偏移量,且每行都会计数,针对表的统计
当存储在hdfs上的数据为文本时,count(1)、count(*)性能表现好,但是当存储格式
为ORC文件时,三者都会读取索引中的统计信息,因此性能差异不大。
3、数值相关的聚合计算
例如:sum() max() min() avg() 等可计算中间结果的聚合模式
大部分数据在本地处理阶段被聚合成一个或少部分的数据,后面阶段可以在此中间
结果上进行计算。减少网络和下游节点处理的数据量
例如:collect_list() 等不可计算中间结果的聚合模式
1.3、连接模式
即表连接的操作,又分为有Shuffle的连接和无Shuffle的连接,注意:表连接常常是性能的瓶颈。
1、Repartition连接
发生在Shuffle 和 Reduce 阶段,一般不特别声明基本都是该连接。map阶段读取A表和B
表的数据,将相同的key发送到reduce进行关联
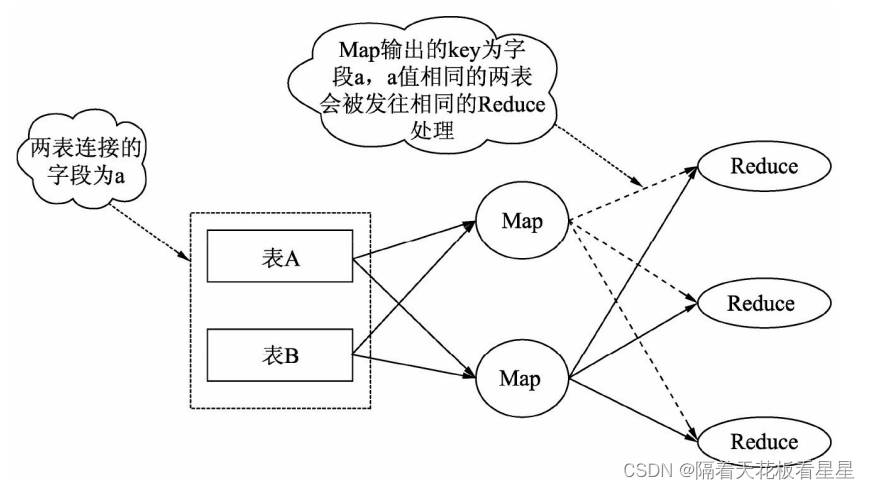
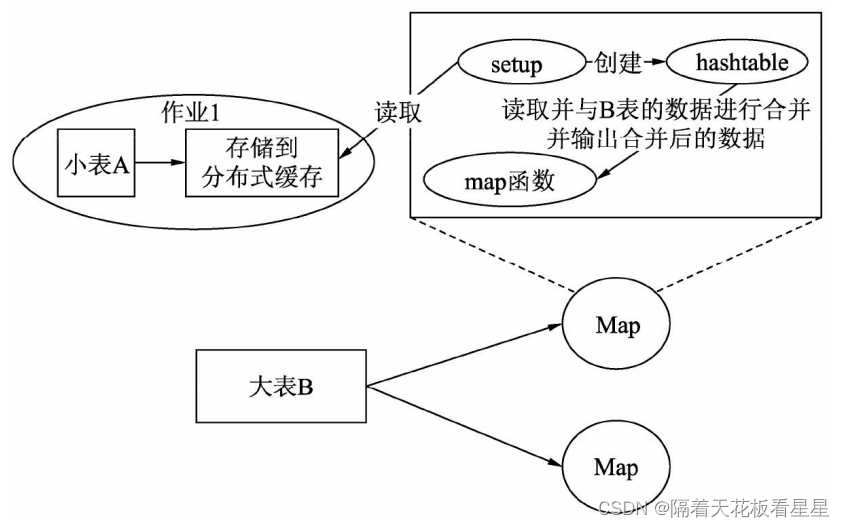
2、Replication连接
发生在Map 阶段,又称为 map join ,因此效率比较高,在map阶段就可以实现连接并
将不匹配的数据提前过滤,减少网络传输和下游的计数数据量。
map接口有三个函数 setup map clearup 其中 setup clearup 是在map阶段前后进行的
一次性操作。
示例:select /*+mapjoin(b) */ a.* from a inner join b on a.id = b.id ;
使用map join 的hive配置:
hive.auto.convert.join=true (表示是否 根据文件大小将普通的repartition连接
将化为Map的连接。)
hive.smalltable.filesize 默认值为25000000bytes
hive.mapjoin.smalltable.filesize 默认值为25000000bytes
两个配置表示的含义都是当小表的数据小于该配置指 定的阀值时,将尝试
使用普通repartition连接转化Map连接
hive.mapjoin.localtask.max.memory.usage:默认值为0.9。
表示小表保存到内存的哈希表的数据量最大可以占用到本地任务90%的内存
hive.mapjoin.followby.gby.localtask.max.memory.usage:默认值是0.55。
表示如果在MapJoin之后还有group by的分组聚合操作,本地任务最大可以
分配当前任务55%的内存给哈希表缓存数据
例如: select /*+mapjoin(b) */ a.id,count(1) from a inner join b on a.id = b.id
group by a.id
2、调整环境参数
开启map端聚合:
hive.map.aggr 默认值:true 还可以用子参数控制聚合
通常是指MapReduce端实现Combiner,Combiner会聚合Map端处理后的数据,它可以使Shuffle的数据量和磁盘IO的数据量减少Combiner可以自己实现也可以直接用Reducer类,(部分逻辑直接使用Reducer类会导致数据计算错误),所以已称为Map端的Reduce任务
原理:map端会默认拿10w行数据进行聚合,如果聚合比例小于设定的比例,默认为0.5
则不会触发聚合
hive.groupby.mapager.checkinterval = 100000
hive.map.aggr.hash.min.reduction = 0.5
hive.map.aggr.hash.percentmemory map端聚合使用内存的最大值
分析:map端的聚合目的时减少shffle,如果map端聚合的时间都大于shuffle的时间了,
也就没必要聚合了
压缩
mapred.output.compression.codec
mapred.output.compression
压缩同样可以减少Shuffle的数据量和磁盘IO,
但是压缩和解压缩也是需要耗时的,一般在大型作业中才开启
合并小文件
hive.merge.smallfiles.avgsize 默认值: 16MB
当输出的文件小于该值时,会启用一个MapReduce任务合并小文件
hive.merge.size.per.task 默认值: 256 MB
是每个任务合并后文件的大小,一般和HDFS中块的大小保持一致
控制运行模式
hive.optimize.countdistinct 默认值:true
Hive3.0 新增的配置,当启用时,去重和计数的作业会分成两个来处理这类sql
比如 count(distinct xx) 以达到减缓SQL数据倾斜的作用
开启并行
hive.exec.parallel 默认值:false
是否开启作业的并行
如果一个sql拆分称了两个 stage ,如果两个 stage 没有依赖关系,默认还是串行执行
如果开启该配置,且集群资源充足,会有效节省整体的时间
hive.exec.parallel.thread.num 默认值:8
表示一个作业最多支持的并行数量
开启本地模式
hive.exec.mode.local.auto 默认值:false
如果遇到数据量较小的任务,可以开启该配置
Hive会在单台机器上处理完所有的任务。但需要满足两个条件:
作业处理的数据量 < hive.exec.mode.local.auto.inputbytes.max 默认值 128MB
作业启动的任务数 < hive.exec.mode.local.auto.tasks.max 默认值 4
注意:只适用于测试HiveQL的正确性,因为只会读取本地机器上符合的数据
开启相关性优化
hive.optimize.correlation 默认值:false
打开配置可以减少重复的Shuffle 操作
比如 select t1.id sum(value) from t1 join t2 on ti.id = t2.id group by t1.id ;
join 和 group by 会产生两个 Shuffle, 且都是以 id 为 key
如果启用该配置,就会剔除一次不必要的 Shuffle
开启向量化查询
hive.vectorized.execution.enabled 默认值:false
在Hive中,矢量化存储是一种优化策略,它可以通过减少I/O操作来提高查询性能。
矢量化存储通常用于列式存储,如ORC格式。
标准查询执行系统一次处理一行,矢量化查询一次性处理1024行
从而减少CPU的指令执行次数和数据的加载次数。
也减少底层操作系统处理数据时的指令和上下文切换
开启严格模式
set hive.mapred.mode = strict; 默认为nonstrict 非严格模式
开启严格模式时,当我们执行某些查询时会有限制。比如:
1、对于分区表,where条件必须加上分区字段进行过滤
2、order by 语句必须包含limit输出限制
3、限制笛卡尔积的查询
3、语法调整
3.1、order by 语法优化
HiveQL中的order by与关系型数据库中的SQL方言中的一样,会将结果按某字段全局排序,
这会导致所有map端数据都进入一个reduce任务,是严重的数据倾斜,当数据量大时还会
导致机器宕机。
可以使用sort by 和 distribute by 组合进行优化
sort by ---对于单个reduce的数据进行排序
distribute by --分区排序,经常和sort by 结合使用
cluster by --相当于 sort by + distribute by (默认 asc 不能通过 asc desc 方式指定)