猫狗识别
- 训练模型
- 导入需要的包
- 数据加载
- 数据预处理
- 加载数据集并返回对应的图像和标签
- 提取标签信息
- 创建训练和测试的数据加载器
- 图像分类
- CNN的卷积神经网络模型
- MYVGG的卷积神经网络模型
- AlexNet的卷积神经网络模型
- 训练过程
- 测试过程
- 定义了一个主函数
- 测试模型
- 导入需要的库
- 加载之前训练好的模型
- 加载新的测试图片并进行预处理
- 对图片进行预处理
- 对新图片进行预处理转换,并添加一个batch维度
- 使用训练好的模型进行推理
- 显示新的测试图片
- 运行结果:
训练模型
导入需要的包
import torch:导入PyTorch深度学习框架。from torch import optim:从torch模块中导入optim优化器,用于模型的优化。import torch.nn as nn:导入torch.nn模块,其中包含了神经网络的相关函数和类。from torch.autograd import Variable:从torch.autograd模块导入Variable类,用于封装张量并支持自动求导。from torchvision import transforms:从torchvision模块导入transforms,用于数据的预处理和增强。
from torch.utils.data import Dataset, DataLoader:从torch.utils.data模块导入Dataset和DataLoader类,用于自定义数据集和数据加载。
from PIL import Image:从PIL库中导入Image模块,用于处理图像数据。import torch.nn.functional as F:导入torch.nn.functional模块并给其命名为F,其中包含了一些常用的函数,如激活函数、损失函数等。
import torch
from torch import optim
import torch.nn as nn
from torch.autograd import Variable
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import torch.nn.functional as F
数据加载
接收一个路径
path,使用PIL库中的Image.open方法打开指定路径的图像文件,然后通过
convert('RGB')方法将图像转换为RGB格式。最后将转换后的图像返回。
def Myloader(path):
return Image.open(path).convert('RGB')
数据预处理
得到一个包含路径与标签的列表 该函数用于初始化数据并生成包含路径和标签的列表。函数会调用 find_label(path) 函数来获取路径
path 对应的标签。然后通过循环从 lens[0] 到 lens[1],依次生成包含路径和标签的列表项,将其添加到 data 列表中。
def init_process(path, lens):
data = []
name = find_label(path)
for i in range(lens[0], lens[1]):
data.append([path % i, name])
return data
加载数据集并返回对应的图像和标签
init 方法:类的初始化方法,接收三个参数 data、transform、loader,分别表示数据集、数据转换操作、数据加载器。在初始化过程中,将这三个参数保存在类的成员变量中。
getitem 方法:用于获取数据集中指定索引 item 的数据。首先从 self.data 中根据索引 item 获取图像路径 img 和标签 label。然后通过 self.loader 加载图像,并通过 self.transform
进行图像的转换操作。最后返回经过加载和转换后的图像 img 和对应的标签 label。len 方法:返回数据集的长度,即数据集中样本的数量。
class MyDataset(Dataset):
def __init__(self, data, transform, loder):
self.data = data
self.transform = transform
self.loader = loder
def __getitem__(self, item):
img, label = self.data[item]
img = self.loader(img)
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data)
提取标签信息
函数首先定义了两个变量first和last,分别用于记录标签字符串的起始位置和结束位置,并初始化为0。
然后通过循环遍历给定的路径字符串str,从末尾向前查找符号’%‘和’.‘,以及字符’c’或’d’和’/‘进行位置的提取。
最后根据提取的起始和结束位置,截取标签字符串name。 如果截取的标签字符串为’dog’,则返回标签值1;否则返回标签值0。
def find_label(str):
first, last = 0, 0
for i in range(len(str) - 1, -1, -1):
if str[i] == '%' and str[i - 1] == '.':
last = i - 1
if (str[i] == 'c' or str[i] == 'd') and str[i - 1] == '/':
first = i
break
name = str[first:last]
if name == 'dog':
return 1
else:
return 0
创建训练和测试的数据加载器
首先创建了一个图像转换操作transform,包括随机水平翻转、随机垂直翻转、调整大小为(256, 256)、转换为张量以及标准化的操作。
然后定义了四个路径变量path1、path2、path3、path4,分别表示训练集中猫的图像路径模板、训练集中狗的图像路径模板、测试集中猫的图像路径模板、测试集中狗的图像路径模板。
对每个路径使用init_process函数初始化数据,数据范围为[0, 500]和[1000,
1200],并将数据存储在相应的data1、data2、data3、data4列表中。组合一部分训练数据和标签数据,创建训练数据集train实例,剩余数据用于测试数据集test实例。
使用DataLoader类分别创建训练数据加载器train_data和测试数据加载器test_data,设置批量大小、是否打乱数据和工作进程数。最后返回训练数据加载器train_data和测试数据加载器test_data。
def load_data():
transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.3),
transforms.RandomVerticalFlip(p=0.3),
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))])
path1 = 'D:/probject/pythonProject1/pytorch/data/training_data/cats/cat.%d.jpg'
data1 = init_process(path1, [0, 500])
path2 = 'D:/probject/pythonProject1/pytorch/data/training_data/dogs/dog.%d.jpg'
data2 = init_process(path2, [0, 500])
path3 = 'D:/probject/pythonProject1/pytorch/data/testing_data/cats/cat.%d.jpg'
data3 = init_process(path3, [1000, 1200])
path4 = 'D:/probject/pythonProject1/pytorch/data/testing_data/dogs/dog.%d.jpg'
data4 = init_process(path4, [1000, 1200])
# 1300个训练
train_data = data1 + data2 + data3[0: 150] + data4[0: 150]
train = MyDataset(train_data, transform=transform, loder=Myloader)
# 100个测试
test_data = data3[150: 200] + data4[150: 200]
test = MyDataset(test_data, transform=transform, loder=Myloader)
train_data = DataLoader(dataset=train,
batch_size=10, shuffle=True, num_workers=0)
test_data = DataLoader(dataset=test,
batch_size=1, shuffle=True, num_workers=0)
return train_data, test_data
图像分类
CNN的卷积神经网络模型
这段代码定义了一个名为CNN的卷积神经网络模型,用于图像分类任务,并定义了其前向传播方法forward。
在__init__方法中,定义了卷积层conv1和conv2,池化层pool,以及全连接层output和dp1(Dropout层)。在forward方法中,对输入数据x进行前向传播计算,首先通过第一个卷积层conv1和池化层进行特征提取和下采样,然后经过第二个卷积层conv2和池化层继续提取特征和下采样。
接着将特征张量展平为一维向量,通过dp1(Dropout)进行正则化处理,最后通过全连接层output生成最终输出,其中output的输出维度是二分类(2个类别)。
# 三种网络择优选择其中一种即可
class CNN(nn.Module):
def __init__(self, num_classes=2):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 16, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.output = nn.Linear(16 * 64 * 64, 2)
self.dp1 = nn.Dropout(p=0.5)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
temp = x.view(x.size()[0], -1)
x = self.dp1(x)
output = self.output(temp)
return output, x
这段代码是一个定义了名为MYVGG的卷积神经网络模型,类似于VGG网络结构,用于图像分类任务。在该模型中,包括8个卷积层和池化层的组合,最后连接一个全连接层和Dropout层。
__init__方法中初始化了模型的网络层。每个卷积层后面跟着一个最大池化层。卷积核数量和大小逐渐增加,通过池化层逐步减小特征图的尺寸。
最后一个卷积层的输出经过展平操作后,经过一个Dropout层进行正则化处理。
输出通过全连接层output生成最终的分类结果。
forward方法定义了模型的前向传播过程。输入数据经过一系列的卷积、激活函数ReLU和池化操作,最终通过全连接层和Dropout层得到输出。
MYVGG的卷积神经网络模型
class MYVGG(nn.Module):
def __init__(self, num_classes=2):
super(MYVGG, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(64, 64, 3,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv3 = nn.Conv2d(64, 128, 3,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv4 = nn.Conv2d(128, 128, 3,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv5 = nn.Conv2d(128, 256, 3,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv6 = nn.Conv2d(256, 256, 3,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv7 = nn.Conv2d(256, 512, 3,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv8 = nn.Conv2d(512, 512, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.output = nn.Linear(512, num_classes)
self.dp1 = nn.Dropout(p=0.5)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.pool(F.relu(self.conv4(x)))
x = self.pool(F.relu(self.conv5(x)))
x = self.pool(F.relu(self.conv6(x)))
x = self.pool(F.relu(self.conv7(x)))
x = self.pool(F.relu(self.conv8(x)))
temp = x.view(x.size()[0], -1)
x = self.dp1(x)
output = self.output(temp)
return output, x
AlexNet的卷积神经网络模型
AlexNet的卷积神经网络模型,类似于AlexNet网络结构,用于图像分类任务。在该模型中,包括5个卷积层和池化层的组合,最后连接一个全连接层和Dropout层。
__init__方法中初始化了模型的网络层。每个卷积层后面跟着一个最大池化层。卷积核数量和大小逐渐增加,通过池化层逐步减小特征图的尺寸。
最后一个卷积层的输出经过展平操作后,经过一个Dropout层进行正则化处理。
输出通过全连接层output生成最终的分类结果。
forward方法定义了模型的前向传播过程。输入数据经过一系列的卷积、激活函数ReLU和池化操作,最终通过全连接层和Dropout层得到输出。
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet,self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv3 = nn.Conv2d(64, 128, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv4 = nn.Conv2d(128, 256, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv5 = nn.Conv2d(256, 512, 3)
self.pool = nn.MaxPool2d(2, 2)
self.output = nn.Linear(in_features=512 * 6 * 6,
out_features=2)
self.dp1 = nn.Dropout(p=0.5)
def forward(self,x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.pool(F.relu(self.conv4(x)))
x = self.pool(F.relu(self.conv5(x)))
temp = x.view(x.shape[0], -1)
x = self.dp1(x)
output = self.output(temp)
return output, x
训练过程
代码实现了一个简单的训练过程,包括数据加载、模型定义、优化器设置、损失函数定义、循环训练和参数保存等步骤。
train_loader, test_loader = load_data():加载训练和测试数据集。device = torch.device('cuda' if torch.cuda.is_available() else 'cpu'):检测是否有可用的GPU,将模型放到对应的设备上。
model = AlexNet().to(device):实例化AlexNet模型并将其移动到指定的设备上。optimizer = optim.Adam(model.parameters(), lr=0.00004):定义Adam优化器,并传入模型参数和学习率。
criterion = nn.CrossEntropyLoss().to(device):定义交叉熵损失函数,用于计算预测值和目标值之间的损失。训练循环中,遍历每个epoch和每个batch:
optimizer.zero_grad():梯度清零。output = model(data)[0]:通过模型进行前向传播。loss = criterion(output, target):计算损失值。
loss.backward():反向传播计算梯度。optimizer.step():更新模型参数。 打印每个迭代的训练损失信息。
通过torch.save()函数,模型在训练完成后会保存在指定路径下。
def train():
train_loader, test_loader = load_data()
epoch_num = 20
# GPU计算
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AlexNet().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.00004)
criterion = nn.CrossEntropyLoss().to(device)
for epoch in range(epoch_num):
for batch_idx, (data, target) in enumerate(train_loader, 0):
data, target = Variable(data).to(device), Variable(
target.long()).to(device)
optimizer.zero_grad() # 梯度清0
output = model(data)[0] # 前向传播
loss = criterion(output, target) # 计算误差
loss.backward() # 反向传播
optimizer.step() # 更新参数
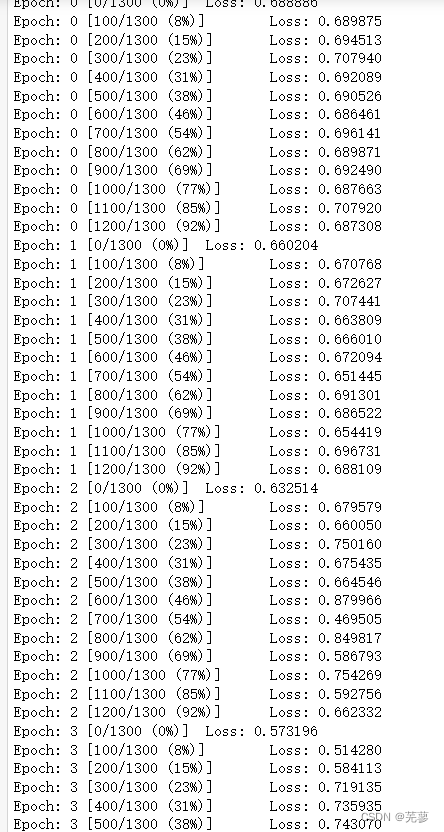
if batch_idx % 10 == 0:
print('Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
torch.save(model, 'D:/probject/pythonProject1/pytorch/cnn.pkl')
测试过程
用于评估训练好的模型在测试集上的准确率 test()函数首先加载训练和测试数据集,并检测可用的设备(GPU或CPU)。
model =torch.load('D:/probject/pythonProject1/pytorch/cnn.pkl'):加载之前训练好的模型。在测试循环中,遍历测试集中的每个数据样本: 将图像数据和标签移动到指定的设备上。 通过加载的模型进行前向传播,得到预测输出。
通过torch.max(outputs.data, 1)[1].data获取预测的类别。
统计总样本数total和预测正确的样本数current。最后,计算模型在测试集上的准确率,并打印输出。准确率的计算方式是正确预测的样本数除以总样本数,然后乘以100以得到百分比表示。
def test():
train_loader, test_loader = load_data()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('D:/probject/pythonProject1/pytorch/cnn.pkl') # load model
total = 0
current = 0
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)[0]
predicted = torch.max(outputs.data, 1)[1].data
total += labels.size(0)
current += (predicted == labels).sum()
print('Accuracy: %d %%' % (100 * current / total))
定义了一个主函数
用于执行训练和测试过程 train()和test()函数是前面解释过的训练和测试过程,分别进行模型训练和测试。
if __name__ == '__main__'::判断是否是主程序入口,即在作为主程序运行时执行以下代码。
train():首先执行训练过程。
test():之后执行测试过程,评估训练好的模型在测试集上的准确率。
if __name__ == '__main__':
train()
test()
运行结果:
测试模型
导入需要的库
torch:PyTorch深度学习框架。transforms:用于图像预处理的模块。Image:用于处理图像的PIL库。
torch.nn.functional as F:包含了各种神经网络的函数接口。
matplotlib.pyplot as plt:用于可视化的库。
import torch
from torchvision import transforms
from PIL import Image
import torch.nn.functional as F
import matplotlib.pyplot as plt
加载之前训练好的模型
# 加载模型
model = torch.load('D:/probject/pythonProject1/pytorch/cnn.pkl')
加载新的测试图片并进行预处理
# 加载新图片
new_image_path = 'noise.jpg' # 请替换为新图片的路径
img = Image.open(new_image_path).convert('RGB')
对图片进行预处理
transforms.Compose()定义了一系列的图像预处理操作,包括调整大小、转换为张量、归一化等。
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
对新图片进行预处理转换,并添加一个batch维度
img = transform(img)
img = img.unsqueeze(0) # 添加batch维度
使用训练好的模型进行推理
output, _ = model(img):使用模型进行前向传播,并获取输出结果。
通过torch.max(output, 1)[1].item()获取预测类别。
output, _ = model(img)
predicted_class = torch.max(output, 1)[1].item()
展示分类结果和图片
class_names = ['cat', 'dog']
print("Predicted class:", class_names[predicted_class])
显示新的测试图片
plt.imshow(img.squeeze().numpy().transpose((1, 2, 0)))
plt.show()
运行结果: