参考Flink从入门到入土(详细教程)
参考flink的默认窗口触发机制
参考彻底搞清Flink中的Window
参考官方Python API文档
1 IDEA中运行Flink
从Flink 1.11版本开始, PyFlink 作业支持在 Windows 系统上运行,因此您也可以在 Windows 上开发和调试 PyFlink 作业了。
1.1 环境配置
pip3 install apache-flink==1.15.3
CMD>set PATH查看环境变量
CMD>set JAVA_HOME查看环境变量
JAVA_HOME=D:\Java\jdk
1.2 Python API
官方Python API文档
根据需要的抽象级别的不同,有两种不同的API可以在PyFlink中使用:
(1)PyFlink Table API允许你使用类似于SQL或者在Python中处理表格数据的方式编写强大的关系查询。
(2)PyFlink DataStream API允许你对Flink的核心组件state和time进行细粒度的控制,以便构建更复杂的流处理应用。
2 PyFlink Table API
参考如何在Apache Flink中使用Python API?
2.1 Python Table API程序的基本结构
所有的 Table API 和 SQL 程序,不管批模式,还是流模式,都遵循相同的结构。
1. 创建 TableEnvironment
2. 创建 source 表
3. 创建 sink 表
4. 查询 source 表,同时执行计算
通过 Table API 创建一张表:
或者通过 SQL 查询语句创建一张表:
5. 将计算结果写入给 sink 表
将 Table API 结果表数据写入 sink 表:
或者通过 SQL 查询语句来写入 sink 表:
# -*- coding:utf-8 -*-
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1. 创建 TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2. 创建(SQL表)datagen
table_env.execute_sql("""
CREATE TABLE datagen (
id INT,
data STRING
) WITH (
'connector' = 'datagen',
'fields.id.kind' = 'sequence',
'fields.id.start' = '1',
'fields.id.end' = '10'
)"""
)
# 3. 创建(SQL表)print
table_env.execute_sql("""
CREATE TABLE print (
id INT,
data STRING
) WITH (
'connector' = 'print'
)"""
)
# 4、将(SQL表)datagen转换成(Table API表)source_table
# 方式一:
source_table = table_env.from_path("datagen")
# 方式二:通过SQL查询语句创建
# source_table = table_env.sql_query("SELECT * FROM datagen")
# 5、 查询(Table API表)source_table,同时执行计算
result_table = source_table.select(source_table.id + 1, source_table.data)
# 6. 将(Table API表)result_table的数据写入(SQL表)print
# 方式一:
result_table.execute_insert("print").wait()
# 方式二:通过SQL查询语句来写入
# table_env.execute_sql("INSERT INTO print SELECT * FROM datagen").wait()
2.2 第一步:创建TableEnvironment
TableEnvironment 是 Table API 和 SQL 集成的核心概念。
from pyflink.table import EnvironmentSettings, TableEnvironment
# create a streaming TableEnvironment流模式
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# or create a batch TableEnvironment批模式
env_settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)
2.3 第二步:创建表
Table是 Python Table API的核心组件。Table对象由一系列数据转换操作构成,但是它不包含数据本身。 相反,它描述了如何从数据源中读取数据,以及如何将最终结果写出到外部存储等。
表可以被打印、优化并最终在集群中执行。
表也可以是有限流或无限流,以支持流式处理和批处理场景。
一个 Table 实例总是与一个特定的 TableEnvironment 相绑定。
注意:不支持在同一个查询中合并来自不同TableEnvironments的表,例如join或者union它们。
2.3.1 通过列表类型的对象创建
(1)使用一个列表对象创建一张表
# -*- coding:utf-8 -*-
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、创建 批 TableEnvironment
env_settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)
# 2、使用一个列表对象创建一张(Table API表)table
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')])
table.execute().print()
结果如下:
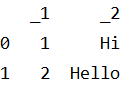
(2)创建具有指定列名的表
# -*- coding:utf-8 -*-
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、创建 批 TableEnvironment
env_settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建具有指定列名的表
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
table.execute().print()
结果如下:

(3)手动指定表模式
默认情况下,表结构是从数据中自动提取的。
如果自动生成的表模式不符合你的要求,你也可以手动指定:
# -*- coding:utf-8 -*-
from pyflink.table import EnvironmentSettings, TableEnvironment
from pyflink.table import DataTypes
# 1、创建 批 TableEnvironment
env_settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建具有指定列名的表
table1 = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
# 默认情况下,“id” 列的类型是 64 位整型
print("默认情况下id列的类型为{}".format(table1.get_schema().get_field_data_type("id")))
# 3、指定表模式
table2 = table_env.from_elements([(1, 'Hi'), (2, 'Hello')],
DataTypes.ROW([DataTypes.FIELD("id", DataTypes.TINYINT()),
DataTypes.FIELD("data", DataTypes.STRING())]))
print("指定id列的类型为{}".format(table2.get_schema().get_field_data_type("id")))
结果如下:
默认情况下id列的类型为BIGINT
指定id列的类型为TINYINT
2.3.2 通过DDL创建
可以通过 DDL 语句创建表,它代表一张从指定的外部存储读取数据的表:
# -*- coding:utf-8 -*-
from pyflink.table import EnvironmentSettings, TableEnvironment
# 创建 流 TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 创建(SQL表)random_source
table_env.execute_sql("""
CREATE TABLE random_source (
id BIGINT,
data TINYINT
) WITH (
'connector' = 'datagen',
'fields.id.kind'='sequence',
'fields.id.start'='1',
'fields.id.end'='3',
'fields.data.kind'='sequence',
'fields.data.start'='4',
'fields.data.end'='6'
)
""")
# (SQL表)random_source转换成(Table API表)table
table = table_env.from_path("random_source")
table.execute().print()
结果如下:

2.3.3 通过Catalog创建
TableEnvironment 维护了一个使用标识符创建的表的catalogs映射。
Catalog中的表既可以是临时的,并与单个Flink会话生命周期相关联,也可以是永久的,跨多个Flink会话可见。
通过SQL DDL创建的表和视图, 例如 “create table …” 和 “create view …",都存储在catalog中。
可以通过SQL直接访问catalog中的表。
如果你要用 Table API 来使用 catalog 中的表,可以使用 “from_path” 方法来创建 Table API 对象:
# -*- coding:utf-8 -*-
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、创建 流 TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建Table API表
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
# 3、准备 catalog,将 Table API 表注册到 catalog 中
table_env.create_temporary_view('source_table', table)
# 4、从 catalog 中获取 Table API 表
new_table = table_env.from_path('source_table')
new_table.execute().print()
结果如下:

2.4 第三步:查询
2.4.1 Table API查询
Table对象有许多方法,可以用于进行关系操作。 这些方法返回新的Table对象,表示对输入Table应用关系操作之后的结果。
这些关系操作可以由多个方法调用组成,例如 table.group_by(…).select(…)。
(1)一个简单的Table API查询
# -*- coding:utf-8 -*-
from pyflink.table import EnvironmentSettings, TableEnvironment, DataTypes
from pyflink.table.expressions import col
# 通过 batch table environment 来执行查询
env_settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)
# 创建表
orders = table_env.from_elements(
[('Jack', 'FRANCE', 10),('Rose', 'ENGLAND', 30),('Jack', 'FRANCE', 20)],
["name","country","revenue"])
# 查询所有来自法国客户的收入
revenue = orders.select(col("name"), col("country"), col("revenue")) \
.where(col("country") == 'FRANCE')
revenue.execute().print()
结果如下:

2.4.2 SQL查询
Flink 的 SQL 基于 Apache Calcite,它实现了标准的 SQL。
SQL 查询语句使用字符串来表达。
SQL 文档描述了 Flink 对流和批处理所支持的 SQL。
下面示例展示了一个简单的 SQL 聚合查询:
from pyflink.table import EnvironmentSettings, TableEnvironment
# 通过 stream table environment 来执行查询
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
table_env.execute_sql("""
CREATE TABLE random_source (
id BIGINT,
data TINYINT
) WITH (
'connector' = 'datagen',
'fields.id.kind'='sequence',
'fields.id.start'='1',
'fields.id.end'='8',
'fields.data.kind'='sequence',
'fields.data.start'='4',
'fields.data.end'='11'
)
""")
table_env.execute_sql("""
CREATE TABLE print_sink (
id BIGINT,
data_sum TINYINT
) WITH (
'connector' = 'print'
)
""")
table_env.execute_sql("""
INSERT INTO print_sink
SELECT id, sum(data) as data_sum FROM
(SELECT id / 2 as id, data FROM random_source)
WHERE id > 1
GROUP BY id
""").wait()
结果如下:

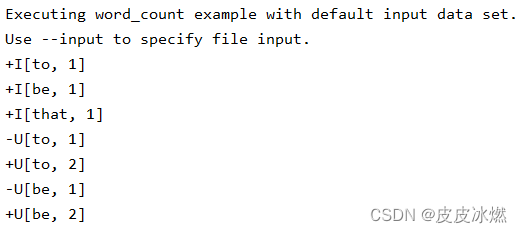
上述输出展示了 print 结果表所接收到的 change log。
change log 的格式为:
{subtask id}> {消息类型}{值的字符串格式}
例如,“2> +I(4,11)” 表示这条消息来自第二个 subtask,
其中 “+I” 表示这是一条插入的消息,
"(4, 11)” 是这条消息的内容。
“-U” 表示这是一条撤回消息 (即更新前),这意味着应该在 sink 中删除或撤回该消息。 “+U” 表示这是一条更新的记录 (即更新后),这意味着应该在 sink 中更新或插入该消息。
所以,从上面的 change log,我们可以得到如下结果:
(4, 11)
(2, 15)
(3, 19)
2.4.3 Table API 和 SQL 的混合使用
Table API 中的 Table 对象和 SQL 中的 Table 可以自由地相互转换。
(1)如何在 SQL 中使用 Table 对象
将Table API表转换成SQL表。
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、通过 stream table environment 来执行查询
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建一张(SQL表)sink来接收结果数据
table_env.execute_sql("""
CREATE TABLE table_sink (
id BIGINT,
data VARCHAR
) WITH (
'connector' = 'print'
)
""")
# 3、创建(Table API表)table
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
# 4、将(Table API表)table转换成SQL中的视图
table_env.create_temporary_view('table_api_table', table)
# 5、将(Table API表)table的数据写入结果表
table_env.execute_sql("INSERT INTO table_sink SELECT * FROM table_api_table").wait()
结果如下:
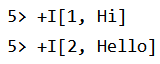
(2)如何在 Table API 中使用 SQL 表
将SQL表转换成Table API表。
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、通过 stream table environment 来执行查询
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建一张(SQL表) sql_source
table_env.execute_sql("""
CREATE TABLE sql_source (
id BIGINT,
data TINYINT
) WITH (
'connector' = 'datagen',
'fields.id.kind'='sequence',
'fields.id.start'='1',
'fields.id.end'='4',
'fields.data.kind'='sequence',
'fields.data.start'='4',
'fields.data.end'='7'
)
""")
# 3、将(SQL表)sql_source转换成(Table API表)table
table = table_env.from_path("sql_source")
# 或者通过SQL查询语句创建(Table API表)table
# table = table_env.sql_query("SELECT * FROM sql_source")
# 4、将表中的数据写出
table.execute().print()
结果如下:

2.5 第四步:结果输出
2.5.1 打印结果
可以通过 TableResult.print方法,将表的结果打印到标准输出中。该方法通常用于预览表的中间结果。
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、通过 stream table environment 来执行查询
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建(Table API表)source
source = table_env.from_elements([(1, "Hi", "Hello"),
(2, "Hello", "Hello")],
["a", "b", "c"])
# 3、将(Table API表)source转换成SQL中的视图
table_env.create_temporary_view('table_api_source', source)
# Get TableResult
table_result = table_env.execute_sql("select a + 1, b, c from table_api_source")
# Print the table
table_result.print()

该方式会触发表的物化,同时将表的内容收集到客户端内存中,所以通过 Table.limit 来限制收集数据的条数是一种很好的做法。
2.5.2 将结果数据收集到客户端
你可以使用TableResult.collect将Table的结果收集到客户端,结果的类型为迭代器类型。
以下代码展示了如何使用TableResult.collect()方法:
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、通过 stream table environment 来执行查询
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建(Table API表)source
source = table_env.from_elements([(1, "Hi", "Hello"),
(2, "Hello", "Hello")],
["a", "b", "c"])
# 3、将(Table API表)source转换成SQL中的视图
table_env.create_temporary_view('table_api_source', source)
# Get TableResult
table_result = table_env.execute_sql("select a + 1, b, c from table_api_source")
# 遍历结果
with table_result.collect() as results:
for result in results:
print(result)

注意:该方式会触发表的物化,同时将表的内容收集到客户端内存中,所以通过 Table.limit 来限制收集数据的条数是一种很好的做法。
2.5.3 将结果数据转换为DataFrame
可以调用to_pandas方法来 将一个Table对象转化成pandas DataFrame:
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、通过 stream table environment 来执行查询
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建(Table API表)source
# <class 'pyflink.table.table.Table'>
source = table_env.from_elements([(1, "Hi", "Hello"),
(2, "Hello", "Hello")],
["a", "b", "c"])
print(source.to_pandas())
# 3、将(Table API表)source转换成SQL中的视图
table_env.create_temporary_view('table_api_source', source)
# 4、Get TableResult
# <class 'pyflink.table.table_result.TableResult'>
# 'TableResult' object has no attribute 'to_pandas'
table_result = table_env.execute_sql("select a + 1, b, c from table_api_source")
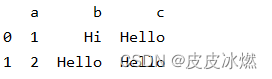
注意:该方式会触发表的物化,同时将表的内容收集到客户端内存中,所以通过 Table.limit 来限制收集数据的条数是一种很好的做法。
注意:并不是所有的数据类型都可以转换为 pandas DataFrames。
2.5.4 将结果写入到一张Sink表中
方式一:可以调用 execute_insert方法来将Table对象中的数据写入到一张 sink 表中:
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、通过 stream table environment 来执行查询
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建(SQL表)sink_table
table_env.execute_sql("""
CREATE TABLE sink_table (
id BIGINT,
data VARCHAR
) WITH (
'connector' = 'print'
)
""")
# 3、创建(Table API表)table
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
# 4、(Table API表)table的数据写入到(SQL表)sink_table中
table.execute_insert("sink_table").wait()

方式二:可以通过 SQL 来完成:
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、通过 stream table environment 来执行查询
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2、创建(SQL表)sink_table
table_env.execute_sql("""
CREATE TABLE sink_table (
id BIGINT,
data VARCHAR
) WITH (
'connector' = 'print'
)
""")
# 3、创建(Table API表)table
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
# 4、将(Table API表)table转换为(SQL表)table_source
table_env.create_temporary_view("table_source", table)
# 5、通过SQL语句写入
table_env.execute_sql("INSERT INTO sink_table SELECT * FROM table_source").wait()

2.5.5 将结果写入多张Sink表中
你也可以使用 StatementSet 在一个作业中将 Table 中的数据写入到多张 sink 表中:
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1、通过 stream table environment 来执行查询
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 准备 source 表和 sink 表
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
table_env.create_temporary_view("simple_source", table)
table_env.execute_sql("""
CREATE TABLE first_sink_table (
id BIGINT,
data VARCHAR
) WITH (
'connector' = 'print'
)
""")
table_env.execute_sql("""
CREATE TABLE second_sink_table (
id BIGINT,
data VARCHAR
) WITH (
'connector' = 'print'
)
""")
# 创建 statement set
statement_set = table_env.create_statement_set()
# 将 "table" 的数据写入 "first_sink_table"
statement_set.add_insert("first_sink_table", table)
# 通过一条 sql 插入语句将数据从 "simple_source" 写入到 "second_sink_table"
statement_set.add_insert_sql("INSERT INTO second_sink_table SELECT * FROM simple_source")
# 执行 statement set
statement_set.execute().wait()

3 Table API示例代码
Apache Flink提供Table API关系型API来统一处理流和批,即查询在无边界的实时流或有边界的批处理数据集上以相同的语义执行,并产生相同的结果。 Flink的Table API易于编写,通常能简化数据分析,数据管道和ETL应用的编码。
读取一个csv文件,处理后,将结果写到一个结果csv文件中。
3.1 基础代码
aa = map(lambda i: (i,), word_count_data)
for a in aa:
print(a)
输出如下:
('to be that',)
('to be ',)
#自定义函数
@udtf(result_types=[DataTypes.STRING()])
def split(line: Row):
for s in line[0].split():
yield Row(s)
3.2 整体代码
from pyflink.table import EnvironmentSettings, TableEnvironment
from pyflink.table import DataTypes
from pyflink.table.expressions import lit, col
from pyflink.table.udf import udtf
from pyflink.common import Row
word_count_data = ["to be that",
"to be "]
def word_count(input_path, output_path):
# 1、通过 stream table environment 来执行查询
# TableEnvironment是Python Table API作业的入口类。
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 所有数据写入一个文件中
table_env.get_config().set("parallelism.default", "1")
# 2、创建源表和结果表
# 使用TableEnvironment.execute_sql()方法,通过DDL语句来注册源表和结果表
# 准备 source 表和 sink 表
if input_path is not None:
# DDL语句
my_source_ddl = """
create table source (
word STRING
) with (
'connector' = 'filesystem',
'format' = 'csv',
'path' = '{}'
)""".format(input_path)
# 注册表
table_env.execute_sql(my_source_ddl)
# (SQL表)source转化为(Table API表)tab
tab = table_env.from_path("source")
else:
print("Executing word_count example with default input data set.")
print("Use --input to specify file input.")
tab = table_env.from_elements(map(lambda i: (i,), word_count_data),
DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())]))
if output_path is not None:
# DDL语句
my_sink_ddl = """
create table sink (
word STRING,
`count` BIGINT
) with (
'connector' = 'filesystem',
'format' = 'canal-json',
'path' = '{}'
)""".format(output_path)
# 注册表
table_env.execute_sql(my_sink_ddl)
else:
# DDL语句
my_sink_ddl = """
create table sink (
word STRING,
`count` BIGINT
) with (
'connector' = 'print'
)"""
# 注册表
table_env.execute_sql(my_sink_ddl)
@udtf(result_types=[DataTypes.STRING()])
def split(line: Row):
for s in line[0].split():
yield Row(s)
# compute word count
tab.flat_map(split).alias('word') \
.group_by(col('word')) \
.select(col('word'), lit(1).count) \
.execute_insert('sink') \
.wait()
# remove .wait if submitting to a remote cluster
if __name__ == "__main__":
word_count(None,None)
上面所有的操作,比如创建源表 进行变换以及写入结果表的操作都只是构建作业逻辑图,只有当 execute_insert(sink_name) 被调用的时候, 作业才会被真正提交到集群或者本地进行执行。



![blender导入骨骼动画方法[psa动作]](https://img-blog.csdnimg.cn/img_convert/b8661b5e02403f508bad863a0882b3c0.png)