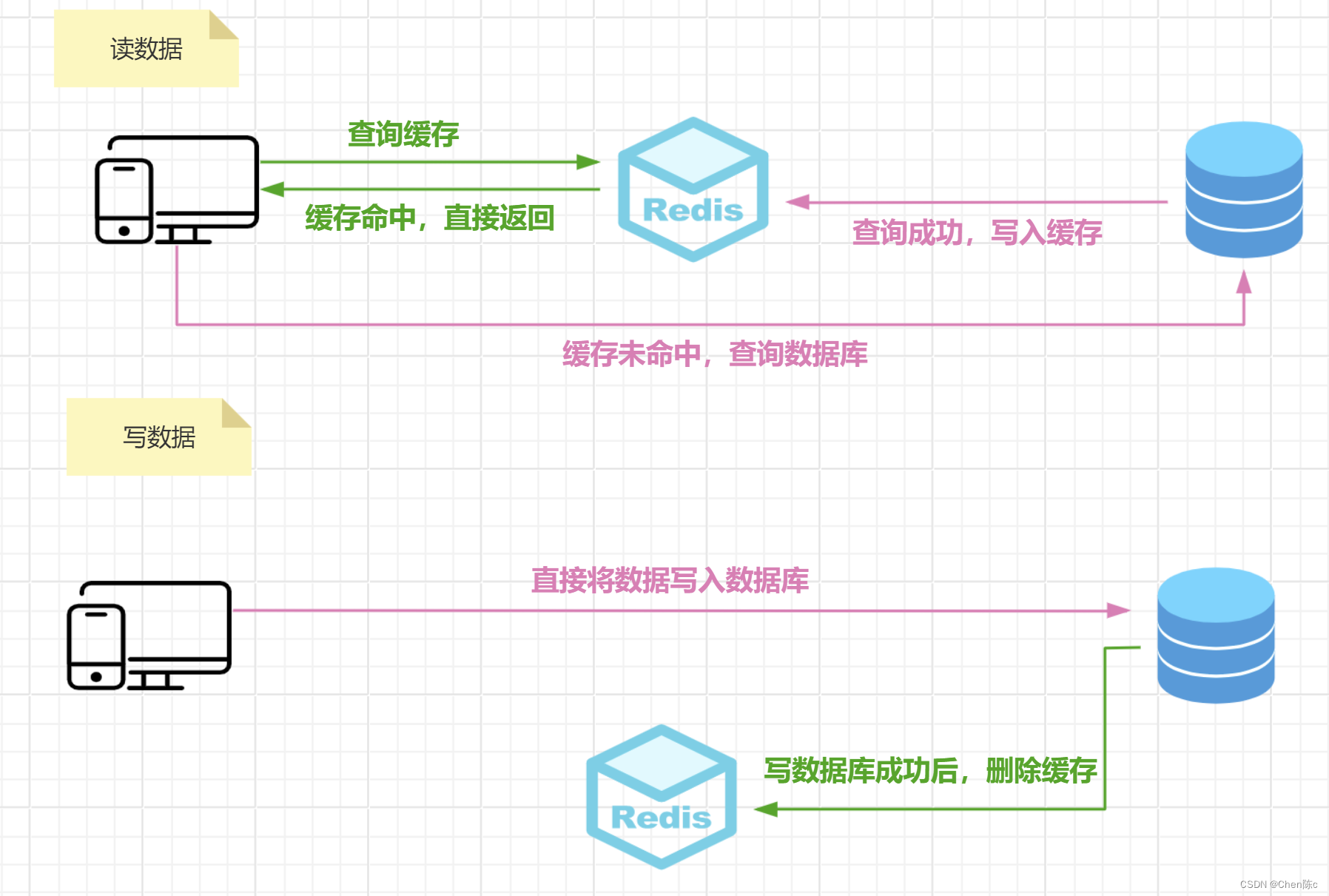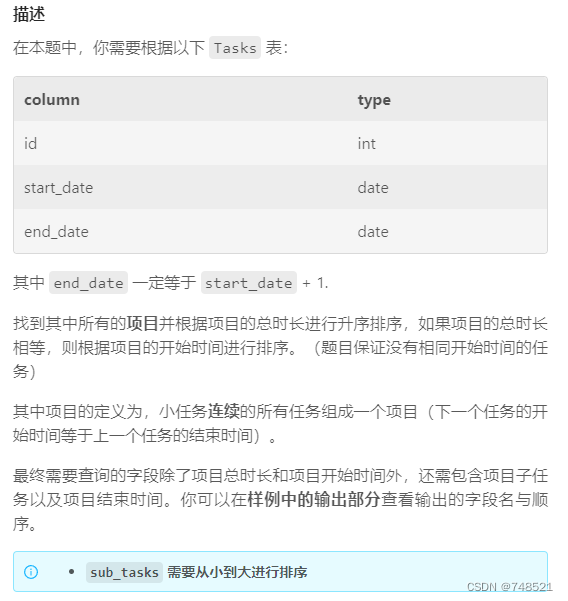
这条 SQL 查询用于从 Tasks 表中计算项目的相关信息,并根据项目的总时长进行排序。具体来看,这段查询的目的是将连续的任务分组为一个项目,并计算每个项目的总天数、子任务 ID 列表、项目的开始日期和结束日期。下面是对这条 SQL 查询的详细分析:
sql
SELECT
count(1) AS total_days,
GROUP_CONCAT(id) AS sub_tasks,
min(start_date) AS proj_start,
max(end_date) AS proj_end
FROM
Tasks
GROUP BY
DATE_sub(start_date, INTERVAL id DAY)
ORDER BY
total_days;
sql
复制代码
GROUP BY DATE_sub(start_date, INTERVAL id DAY)
这部分使用了一个技巧来将连续的任务分组为一个项目。它通过将每个任务的 start_date 减去任务的 id 作为一个分组条件,这样相同项目的任务将会有相同的分组值。
DATE_sub(start_date, INTERVAL id DAY):这个表达式将每个任务的 start_date 减去其 id 值所对应的天数,形成一个新的日期值。
GROUP BY:使用这个日期值作为分组键,将那些连续的任务(即它们的开始日期和结束日期紧邻在一起的任务)分到同一个组中。
2. SELECT 子句
sql
SELECT
count(1) AS total_days,
GROUP_CONCAT(id) AS sub_tasks,
min(start_date) AS proj_start,
max(end_date) AS proj_end
count(1) AS total_days:计算每个项目中的任务总数,这实际上是每个项目的持续天数。
GROUP_CONCAT(id) AS sub_tasks:将每个项目中的所有任务的 id 值连接成一个逗号分隔的字符串。
min(start_date) AS proj_start:获取每个项目中的最早开始日期,即项目的开始日期。
max(end_date) AS proj_end:获取每个项目中的最晚结束日期,即项目的结束日期。
3. ORDER BY total_days
sql
复制代码
ORDER BY total_days;
ORDER BY total_days:根据项目的总天数对结果进行升序排序。这意味着短期项目将首先出现在结果中。
示例数据及其应用
假设 Tasks 表的数据如下:
id start_date end_date
1 2021-08-01 2021-08-02
2 2021-08-02 2021-08-03
3 2021-08-04 2021-08-05
4 2021-08-05 2021-08-06
5 2021-08-07 2021-08-08
第一个项目由任务 1 和 2 组成,因为它们是连续的。
第二个项目由任务 3 和 4 组成,因为它们也是连续的。
第三个项目是任务 5,它是单独的一个任务。
使用上述查询,这些任务将被分组并计算其总天数、子任务 ID 列表、开始日期和结束日期。
查询结果示例
total_days sub_tasks proj_start proj_end
2 1,2 2021-08-01 2021-08-03
2 3,4 2021-08-04 2021-08-06
1 5 2021-08-07 2021-08-08
优化与改进
索引:确保在 start_date 列上有索引,以提高查询性能,尤其是在数据量较大的情况下。
GROUP_CONCAT:在连接子任务 ID 时,如果任务 ID 很多,可以设置 GROUP_CONCAT_MAX_LEN 以避免截断。
sql
复制代码
SET SESSION group_concat_max_len = 10000;
通过上述分析,我们了解了这条 SQL 查询的目的、运作方式及其各个组成部分的作用。此查询有效地将连续的任务分组为项目并计算所需的项目信息。