Redis常用的设计模式分为读,写,读写三种
一、概要说明
读操作
- Read Through Pattern 读穿透
写操作
以Redis统一视图为准:先更新缓存,后更新数据库。
-
Write Through Pattern 直写模式(首先将数据写入缓存,再将数据立即同步到数据库。)
-
Write Behind Pattern 写后模式(首先将数据写入缓存,再将数据异步的批量同步到数据库)
写操作不经过缓存。
- Write Around Pattern 绕写模式(数据直接写入数据库,不经过缓存)。
读写操作
- Cache Aside Pattern 旁路模式(缓存操作是由应用程序显式控制的,开发者可以根据特定业务需求来自定义管理缓存数据,更加灵活可控)
二、详细说明
1 读模式
1.1 Read Through Pattern
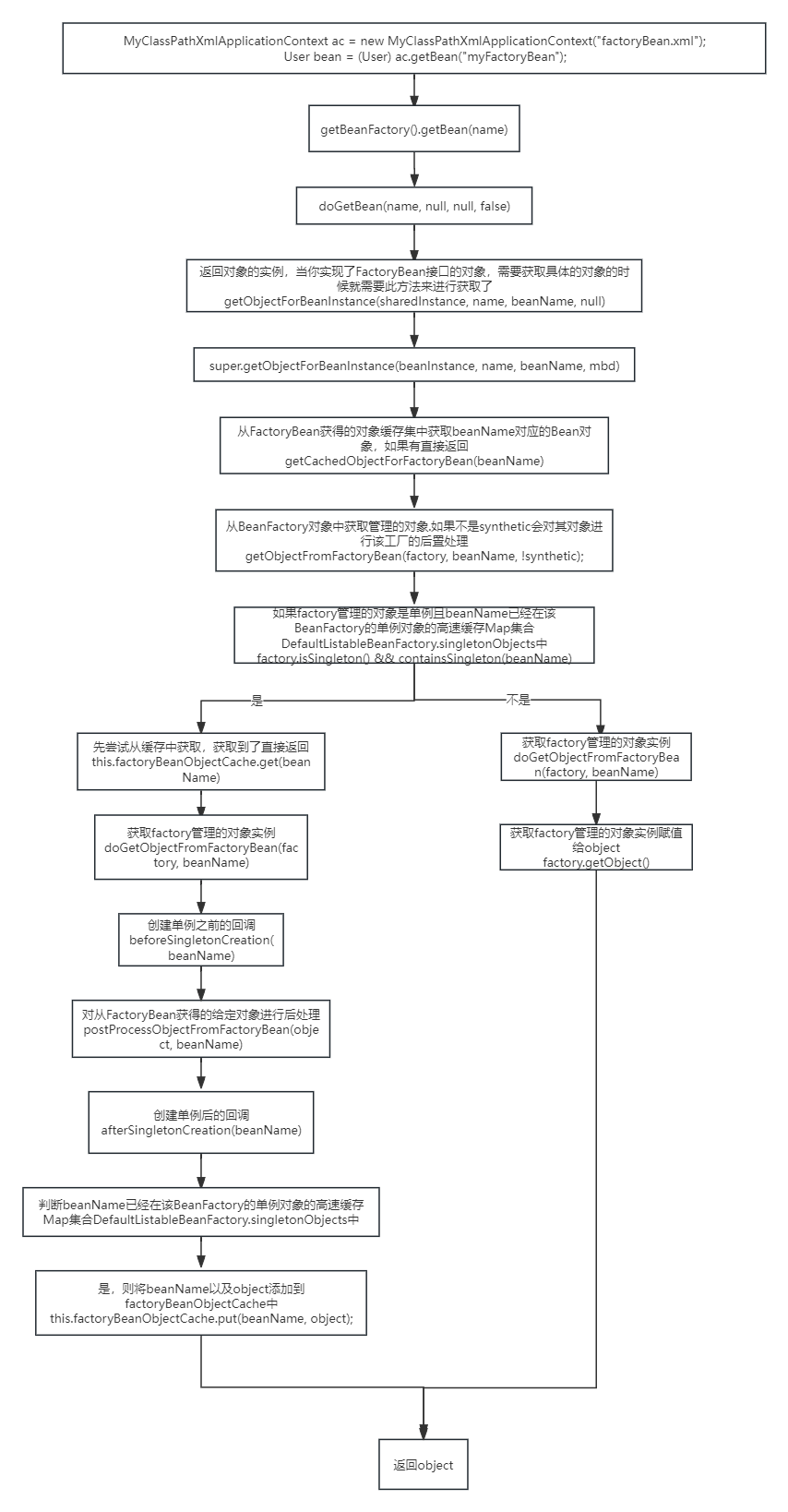
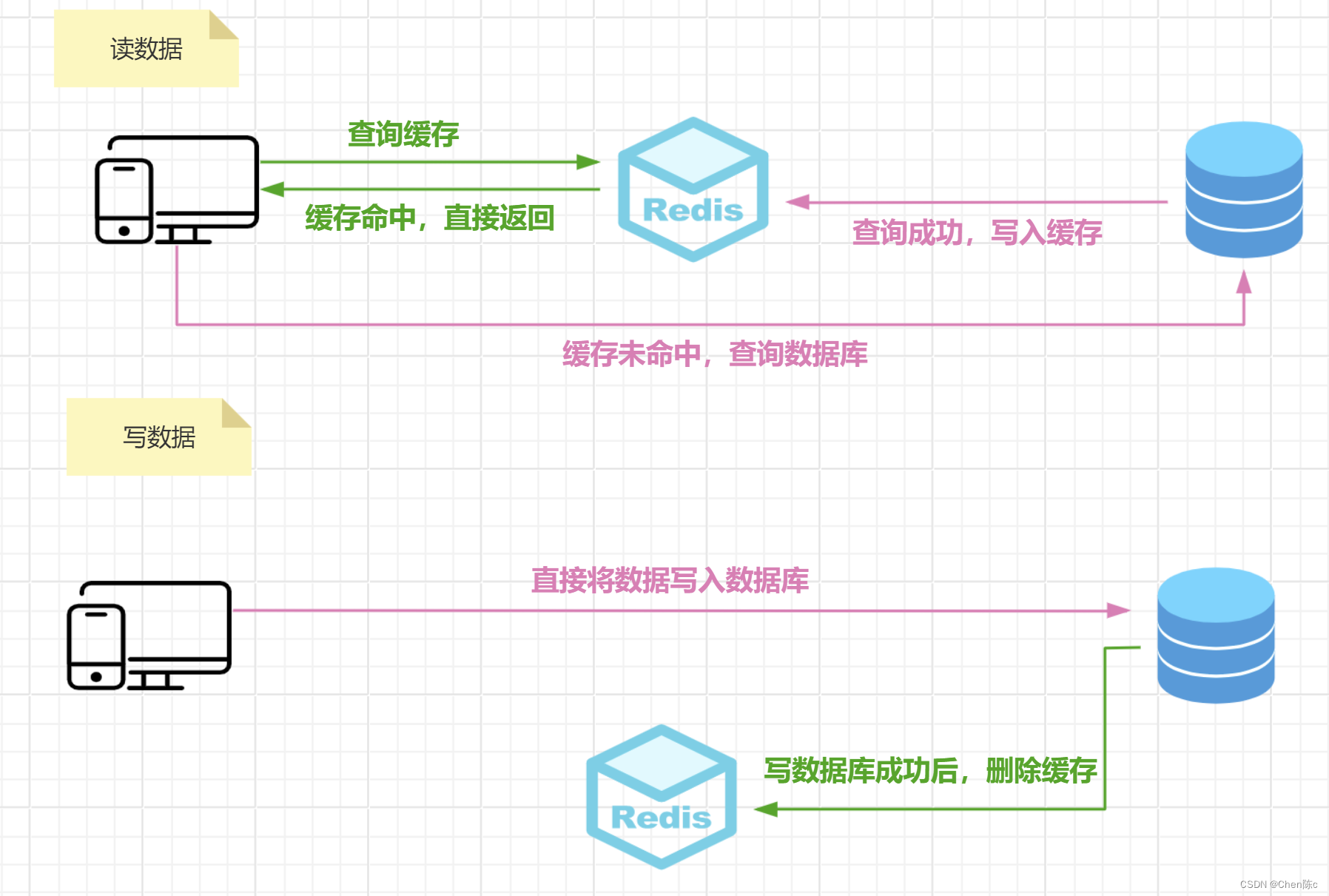
读穿透模式:在这种模式下,应用程序在读数据时,首先直接对缓存发起请求(先查缓存),如果缓存未命中(缓存中不存在该数据),缓存中间件会自动触发一个回源操作,从数据库或其它数据源中获取数据,然后将数据写入缓存中,最终由缓存返回数据给应用程序。
步骤:
- 应用程序请求读数据。
- 首先查询缓存中是否有数据的键存在。
- 如果缓存命中(缓存中存在该数据),则直接从缓存中获取数据,返回给应用程序。
- 如果缓存未命中,缓存层会从数据库中获取数据。
- 将数据写入缓存。
- 缓存返回新加载的数据给应用程序。
优点:
降低数据库的负载:一旦数据被加载到缓存中,后续的读取请求将直接从缓存中获取数据,减少了对数据库的直接访问。
提高系统的性能和并发读取能力:读操作从缓存中进行,缓存的读取速度快,从而提高了系统的性能。
缺点:
高并发请求下的数据不一致:连续两次写入请求,由于写入操作存在先后顺序问题,当数据被更新时,其它并发请求可能还在读取缓存中的旧数据,导致数据不一致。
回源延迟:如果缓存未命中,回源操作会导致数据的获取有一定的延迟,特别是当数据量较大时,延迟会更加明显。
解决方案:
设置合适的缓存数据过期时间,采用适当的缓存数据过期策略和缓存淘汰策略确保缓存的有效性。
“定期删除+惰性删除”策略:用于删除过期的缓存数据。
内存淘汰策略:用于在内存不足时,选择要淘汰的缓存数据。
适用场景:
适用于读取频繁、写入较少,对数据一致性要求不高,对速度和性能要求较高的场景。
2 写模式
2.1 Write Through Pattern
写穿透模式(直写模式):在这种模式下,应用程序在写数据时,首先将数据写入缓存,然后再将数据立即写入到数据库,确保数据库和缓存中的数据保持一致。
步骤:
- 应用程序发起写操作。
- 首先将数据写入缓存。
- 再将数据立即写入到数据库。
先更新缓存,再立即更新数据库

优点:
数据一致性:每次写操作都要同时更新缓存和数据库,保证了缓存和数据库之间的数据一致性。
即时的数据访问:由于缓存始终保持最新状态,读取操作可以立即从缓存中获取最新的数据,提高了数据访问的速度。
缺点:
写操作延迟:对于写操作频繁的场景,每次写操作都要同时更新缓存和数据库,导致写操作延迟。
资源消耗:缓存和数据库的同步更新会消耗更多的计算和内存资源。
适用场景:
适用于对数据一致性要求较高,写操作不频繁的场景。
例如:电商平台的订单处理,当用户下单时,订单信息既写入缓存,也同步写入数据库,保证了数据的实时性和一致性。
2.2 Write Behind Pattern
写后模式:在这种模式下,应用程序在写数据时,首先将数据写入缓存,然后再将数据异步的批量写入到数据库。
步骤:
- 应用程序发起写操作。
- 首先将数据写入缓存。
- 再将数据异步的批量写入到数据库。
先更新缓存,再异步更新数据库。

优点:
提高写操作性能:写操作首先发生在缓存中,通常比写入数据库快得多。
减轻数据库负载:异步批量写入数据库,减少对数据源的即时写操作。
提高响应时间:写操作首先发生在缓存中,可以更快的响应写请求。
缺点:
数据一致性问题:由于数据是异步写入数据库的,导致缓存和数据库之间在一定时间内的数据不一致。
适用场景:
适用于写操作远多于读操作,且对数据一致性要求不高的场景。
例如:用户行为日志收集,用户在网站上的点击行为被记录在缓存中,然后异步批量写入到日志数据库。
2.3 Write Around Pattern
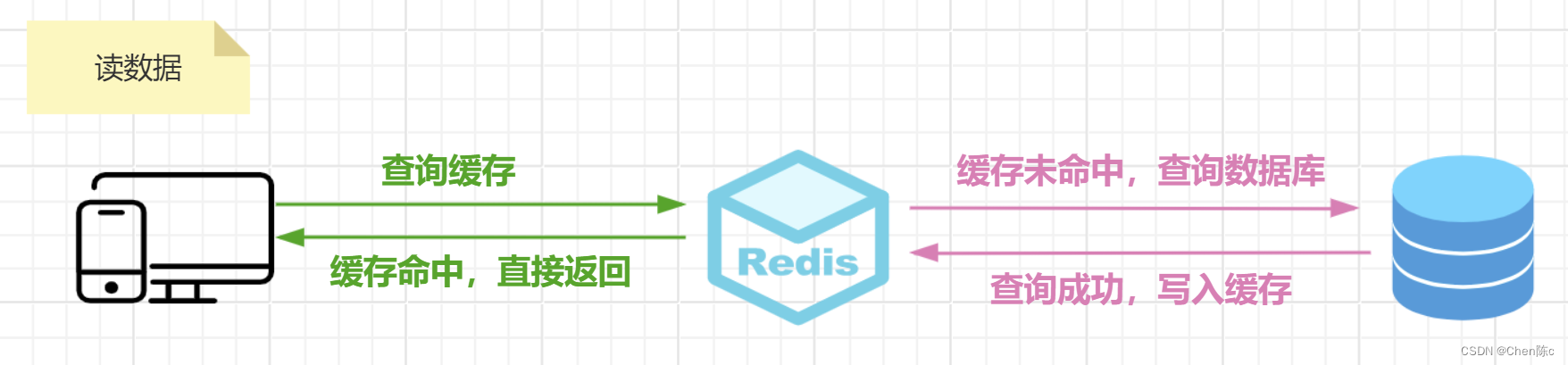
绕写模式:在这种模式下,应用程序在写数据时,直接将数据写入数据库,写操作不经过缓存(写数据绕过缓存),缓存仅用于读取操作。
优点:
提高缓存效率:写操作不需要同步到缓存,缓存不会应为写操作而频繁的失效或更新。
提高内存利用率:防止那些不会再次被读取到的数据占用缓存空间,提高资源利用率。
缺点:
无法保障数据一致性:如果更新的数据同时存在于缓存和数据库中,则会造成缓存和数据库中的数据不一致。由于缓存数据没有被及时更新,导致从缓存中获取到脏数据。
适用场景:
适用于数据写入后很少被读取的场景。
例如:对于数据备份操作直接写入到备份存储中,不经过缓存;或者是针对报告、归档信息的操作。
3 读写模式
3.1 Cache Aside Pattern
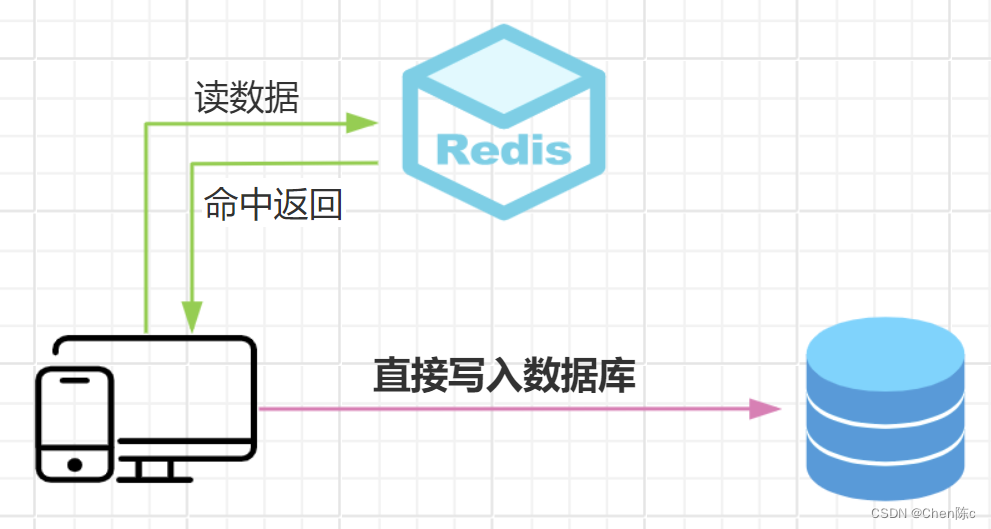
旁路缓存模式:在这种模式下,读数据时先查询缓存,缓存命中则直接返回数据;缓存未命中,则查询数据库,查询成功后,更新缓存中的数据。
写数据时先更新数据库,更新成功后删除缓存。
读数据:
-
首先查询缓存中是否有数据的键存在。
-
如果缓存命中,则直接从缓存中获取数据,返回给应用程序。
-
如果缓存未命中,则从数据库中查询数据。
-
查询成功后,将数据写入缓存。
-
最后,将数据返回给应用程序。
写数据:
-
直接将数据写入数据库。
-
写数据库成功后,删除缓存。
优点:
确保缓存中存放的是真热点数据:只有在实际需要时,才加载数据到缓存,避免缓存中填充未使用或很少使用的数据,保证缓存中存放的是当前窗口的活跃数据。
内存占用小:只缓存真正的热点数据,减少缓存空间的浪费,更有效的利用缓存空间。
提高灵活性:缓存操作是由应用程序显式控制的,开发者可以根据特定业务需求来管理缓存数据。
缺点:
代码复杂性:需要额外的代码逻辑去处理缓存的加载和失效。
数据一致性问题:由于缓存更新依赖于应用程序逻辑,如果处理不当,可能会导致缓存和数据库之间的数据不一致。
适用场景:
适用于读多写少,对数据实时性要求不高的场景。
例如:新闻内容展示、博客文章的阅读。
如果缓存删除失败,设置缓存过期时间兜底。---- 保证最终一致性
一. 缓存数据的类型
- 静态缓存数据
例如:字典表,静态缓存数据没有时间窗口,即没有设置过期时间。
- 动态的缓存
当前窗口的活跃数据,需要设置合适的缓存过期时间。
2. 过期时间的设置
建议:过期时间 <= 业务时间 — 续期
总结:
即使缓存删除失败了,这个缓存数据也是带有过期时间的,采用“定期删除+惰性删除”的策略。
定期删除:Redis默认每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果有过期就删除。 定期删除可能会导致很多过期的key到了时间并没有被删除掉,此时就要用到惰性删除。
惰性删除:在你请求某个key的时候,redis会检查这个key是否设置了过期时间,并判断是否过期了,如果过期就删除。
所谓延时双删
A读数据 --> 发现缓存失效了 --> A读数据库(假设读到5) --> 更新缓存(缓存中数据为5)
在A读数据后到更新缓存的过程中,发生了:
B写数据 ----> 写入数据库(数据库中值被更新为6) —> 删除缓存
这个写操作正好卡在A读后到更新的过程中。
于是有人提出了延时双删:
先更新数据库 --> 更新成功后,立刻删除缓存 --> 延时后再删除缓存
延时双删并没有彻底解决问题,也带来了数据延时一致性的窗口期。
所以增加延时双删反而使得问题更复杂了,还不如直接给缓存中的数据设置合适的过期时间,采用缓存淘汰策略兜底。
即使有第三方直接更新了数据库,而不是通过请求进来更新的,用设置缓存数据过期时间兜底的方案仍然可以解决问题。