一 前言
从上篇原创文章到现在又是新的一年,今天是2023年的大年初三,先在这里祝各位亲爱的老铁们新年快乐,身体健康,在新的一年里更帅气、更漂亮,都能完成自己的小目标。
一直以来,我对数据存储还是比较感兴趣的,计算机从大的抽象层次来说,只干了三件事情,存入数据,计算,输出数据。所以数据的存储和搜索可以说是占据计算机的大半功能了。在工作中,也自己设计过一些存储和索引,不过是简单的哈希表的结构存储,对以B+树为核心的数据库一直挺有兴趣,所以翻找了一些原理文章和源码研究了下,虽然原理看的不少,但是总觉得没有动手亲自写过还是学习的不够深刻,同时在github上找到了一步步写简单db的项目,于是开始借鉴学习后(代码参考后有所改进)有了这一系列文章。
这次也不定啥目标了,怕坑挖大了,填不完,能写多少就写多少吧,同时希望自己写的这个开源,并将自己以后所学所知的一些优化的技巧应用在这上面,当一个练手的小项目吧,不要相信题目,题目只是吸引大家进来的,请原谅我厚着脸皮起的这么大的题目。
二 开始
2.1 名字和设计原则
名字 这是个练手的小的不能再小的数据库,最终很可能会基于B+树来构建,至于后续的谁知道那,所以起了个名叫microdb,会用纯c开发,希望用标准的C开发,仿照sqlite,不会考虑多系统的兼容性,这是小玩具,仅此而已。
设计原则 简单!简单!简单!
2.2 关于数据库存储的疑问
在设计需要持久化到硬盘索引的时候,觉得写的不够好,数据结构还有存储格式有很大的优化空间。总在想在Mysql等数据库上,上亿条记录最多通过四次的磁盘读就搜寻到了需要的数据,这个是怎么实现的?内存对应的数据是何时持久化到磁盘上的?B+树上每个分支的指针怎么保存,内存里面就是地址,B+树持久化到磁盘上,这个指针是磁盘块的地址吗?
2.3 sqlite
只所以仿照sqlite,原因无非是它够小,只有一个c文件,功能少模仿简单。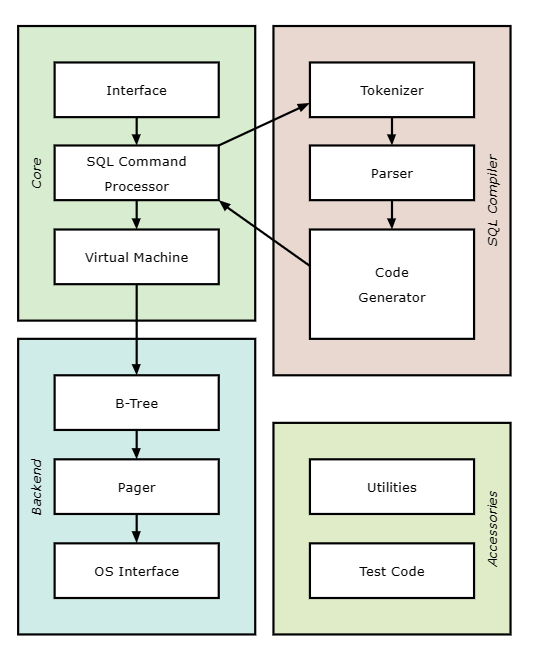
说明:整体来说sqlite将sql命令通过分词、解析和代码生成器最后生成字节码,在虚拟机上运行,直到它完成或返回结果、或遇到致命错误、或中断。
2.3 第一个版本
主要开发工具vscode,采用xmake做c的构建工具,主要是比较简单和方便,可以跨平台使用,不了解的可以参考我的xmake构建工具的文章。 新建个项目,最终展示如下:
先来仿照sqlite的命令行实现个简单的解释器,它会循环执行:读取用户输入-->执行命令-->输出结果-->继续等待用户输出。 关键代码如下:
int main(int argc, char **argv)
{
InputBuffer *input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("unkown command: '%s'.\n", input_buffer->buffer);
}
}
return 0;
}其中InputBuffer为自定义的保存用户输入的缓冲区,读取一行数据后判断命令是否为".exit"命令,不是退出命令则打印不识别命令,是退出命令则退出,非常简单:
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
int getline_my(char **buffer, int *length, FILE *fd)
{
int i = 0;
char ch;
char buf[MAX_LEN] = {0};
while ((ch = fgetc(fd)) != EOF && ch != '\n') {
if (MAX_LEN - 1 == i) {
break;
}
buf[i++] = ch;
}
*length = i;
buf[i] = '\0';
*buffer = (char *)malloc(sizeof(char) * (i + 1));
assert(buffer != NULL);
strncpy(*buffer, buf, i + 1);
return i;
}
void read_input(InputBuffer *input_buffer)
{
ssize_t bytes_read =
getline_my(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
input_buffer->input_length = bytes_read ;
input_buffer->buffer[bytes_read] = 0;
}运行提示行:
F:\ccode\microdb-my\build\windows\x86\debug>microdb-my.exe
microdb > .test
unkown command: '.test'.
microdb > .help
unkown command: '.help'.
microdb > .exit三 小小的改进版本
3.1 支持语句识别
上个版本的功能除了识别.exit退出外,没啥其他有用的功能,这个版本先添加对语句的支持,另外我们区分下点号开头的表示是元命令,否则就是正常的sql语句,需要我们解析执行的先不管怎么解析和执行。 第2版的main函数,内容如下:
int main(int argc, char **argv)
{
InputBuffer *input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (input_buffer->buffer[0] == '.') {
switch (do_meta_command(input_buffer)) {
case (META_COMMAND_SUCCESS):
continue;
case (META_COMMAND_UNRECOGNIZED_COMMAND):
printf("Unrecognized command '%s'\n", input_buffer->buffer);
continue;
}
} else {
Statement statement;
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
case (PREPARE_UNRECOGNIZED_STATEMENT):
printf("Unrecognized keyword at start of '%s'.\n",
input_buffer->buffer);
continue;
}
execute_statement(&statement);
printf("Executed.\n");
}
}
return 0;
}将整个输入分成两个部分,以点号开头的表示元命令,不然就当成sql语句进行处理, 解析好语句后,就执行,执行只是打印个输出内容:
F:\ccode\microdb-my\build\windows\x86\debug>microdb-my.exe
microdb > .test
Unrecognized command '.test'
microdb > .help
Unrecognized command '.help'
microdb > insert a
This is where we would do an insert.
Executed.
microdb > select a
This is where we would do a select.
Executed.
microdb > .exit关于语句和解析语句的定义如下:
typedef enum {
META_COMMAND_SUCCESS,
META_COMMAND_UNRECOGNIZED_COMMAND
} MetaCommandResult;
typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
typedef enum { PREPARE_SUCCESS, PREPARE_UNRECOGNIZED_STATEMENT } PrepareResult;
typedef struct {
StatementType type;
} Statement;
MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
}
PrepareResult prepare_statement(InputBuffer *input_buffer,
Statement *statement)
{
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
statement->type = STATEMENT_INSERT;
return PREPARE_SUCCESS;
}
else if (strncmp(input_buffer->buffer, "select",6) == 0) {
statement->type = STATEMENT_SELECT;
return PREPARE_SUCCESS;
}
return PREPARE_UNRECOGNIZED_STATEMENT;
}
void execute_statement(Statement *statement)
{
switch (statement->type) {
case (STATEMENT_INSERT):
printf("This is where we would do an insert.\n");
break;
case (STATEMENT_SELECT):
printf("This is where we would do a select.\n");
break;
}
}3.2 支持在内存中插入和查询语句
首先数据保存在内存中,采用硬编码的方式来保存用户信息,用户信息如下表:
插入语句和查询语句的语法也进行了简化,插入语句如下:
insert 1 cstack foo@bar.com
select整体实现思路如下:
扩展解析功能,将插入的数据以行为基本单元保存在称为页的一块内存中。
每个页面有很多行组成,行紧凑排列。
整个系统会根据需要申请多个页面,所有的页面都保存在一个大数组里面。
对row的定义如下:
typedef struct {
uint32_t id;
char username[COLUMN_USERNAME_SIZE];
char email[COLUMN_EMAIL_SIZE];
} Row;
// 判断数据类型的长度,(Struct*)0是把null强转为Struct*指针,后获取属性,这里面只获取类型 所以不会报错
#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
// 获取ID的属性的长度
const uint32_t ID_SIZE = size_of_attribute(Row, id);
// 获取用户名的长度
const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
// 获取邮箱的长度
const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
// ID偏移量
const uint32_t ID_OFFSET = 0;
// 用户名偏移量
const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
// 邮箱的偏移量
const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
// 整行长度
const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
下面两个函数比较关键,即序列化列和反序列化列,这里面序列化并没有把数据写入到磁盘,只是放入一块连续的平铺的内存中而已,不过这个却是可以方便持久化到磁盘上。
/*序列化行,将row信息放入连续内存行中*/
void serialize_row(Row* source, void* destination) {
memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
}
/*反序列化,将内存块行转成row*/
void deserialize_row(void* source, Row* destination) {
memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}定义一个页面为4KB大小,然后定义最大只能保存100个页面,每个页面再按照每个用户总的字节数大小进行划分,具体如下:
// 总页数
#define TABLE_MAX_PAGES 100
// 每页的大小
const uint32_t PAGE_SIZE = 4096;
// 每页可以保存row的总量
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
// 整个表可以保存的总的数据量
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
uint32_t num_rows;
void* pages[TABLE_MAX_PAGES];
} Table;行不跨页,每页会有些浪费空间. 定位行的算法也是常用在布隆过滤器的算法,如下:
void *row_slot(Table *table, uint32_t row_num)
{
uint32_t page_num = row_num / ROWS_PER_PAGE;
void *page = table->pages[page_num];
if (page == NULL) {
page = table->pages[page_num] = malloc(PAGE_SIZE);
}
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return (char *)page + byte_offset;
}通过:uint32_t page_num = row_num / ROWS_PER_PAGE; 来定位具体的页, 通过uint32_t row_offset = row_num % ROWS_PER_PAGE; 来定位具体的row,然后通过offset来定义在页面的具体偏移量。
uint32_t byte_offset = row_offset * ROW_SIZE;
return (char *)page + byte_offset;插入和查询函数定义如下:
ExecuteResult execute_insert(Statement *statement, Table *table)
{
if (table->num_rows >= TABLE_MAX_ROWS) {
return EXECUTE_TABLE_FULL;
}
Row *row_to_insert = &(statement->row_to_insert);
serialize_row(row_to_insert, row_slot(table, table->num_rows));
table->num_rows += 1;
return EXECUTE_SUCCESS;
}
ExecuteResult execute_select(Statement *statement, Table *table)
{
Row row;
for (uint32_t i = 0; i < table->num_rows; i++) {
deserialize_row(row_slot(table, i), &row);
print_row(&row);
}
return EXECUTE_SUCCESS;
}插入比较简单,关键是定位到具体的页面的偏移量,将row的内容持久化到内存块中。 查询是每次都是全部查询没有查询全部的功能。
四 第一个正式版本
代码一共320行,要定义为main.cpp,用c++编译器编译才可以,虽然大部分是c的语法,但是定义const外部产量原因,c编译器无法通过。 代码实现了内存一个固定表格的插入和查询功能,和一个交互界面,下一阶段是实现文件的持久化和B+树的存储功能。
#include <stdio.h>
#if defined(_MSC_VER)
#include <BaseTsd.h>
typedef SSIZE_T ssize_t;
#endif
#include <stdint.h>
#include <string.h>
#include <malloc.h>
#include <cstdlib>
#ifndef true
#define true 1
#define false 0
#endif
#define EXIT_SUCCESS 0
#define MAX_LEN 1024
#pragma warning(disable : 4819)
#define COLUMN_USERNAME_SIZE 32
#define COLUMN_EMAIL_SIZE 255
#define TABLE_MAX_PAGES 100
/*元命令的解析结果*/
typedef enum {
META_COMMAND_SUCCESS,
META_COMMAND_UNRECOGNIZED_COMMAND
} MetaCommandResult;
/*插入和查询语句*/
typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
/*解析命令结果*/
typedef enum { PREPARE_SUCCESS, PREPARE_UNRECOGNIZED_STATEMENT, PREPARE_NEGATIVE_ID, PREPARE_STRING_TOO_LONG, PREPARE_NEGATIVE_ID, PREPARE_SYNTAX_ERROR} PrepareResult;
/*执行结果*/
typedef enum { EXECUTE_SUCCESS, EXECUTE_TABLE_FULL } ExecuteResult;
// 行定义
typedef struct {
uint32_t id;
char username[COLUMN_USERNAME_SIZE + 1];
char email[COLUMN_EMAIL_SIZE + 1];
} Row;
// 表的定义
typedef struct {
uint32_t num_rows;
void *pages[TABLE_MAX_PAGES];
} Table;
// 语句定义
typedef struct {
StatementType type;
Row row_to_insert;
} Statement;
// 缓冲区定义
typedef struct {
char *buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
const uint32_t ID_SIZE = size_of_attribute(Row, id);
const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
// 偏移量
const uint32_t ID_OFFSET = 0;
const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
const uint32_t PAGE_SIZE = 4096;
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
InputBuffer *new_input_buffer()
{
InputBuffer *input_buffer = (InputBuffer *)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
int getline_my(char **buffer, size_t *length, FILE *fd)
{
int i = 0;
char ch;
char buf[MAX_LEN] = {0};
while ((ch = fgetc(fd)) != EOF && ch != '\n') {
if (MAX_LEN - 1 == i) {
break;
}
buf[i++] = ch;
}
*length = i;
buf[i] = '\0';
*buffer = (char *)malloc(sizeof(char) * (i + 1));
strncpy(*buffer, buf, i + 1);
return i;
}
void print_row(Row *row)
{
printf("(%d,%s,%s)\n", row->id, row->username, row->email);
}
// 从命令行读取一行命令
void read_input(InputBuffer *input_buffer)
{
ssize_t bytes_read =
getline_my(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
input_buffer->input_length = bytes_read ;
input_buffer->buffer[bytes_read] = 0;
}
void close_input_buffer(InputBuffer *input_buffer)
{
free(input_buffer->buffer);
free(input_buffer);
input_buffer = NULL;
}
///
// 解析元命令
MetaCommandResult do_meta_command(InputBuffer *input_buffer)
{
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
}
// 解析插入语句
PrepareResult prepare_insert(InputBuffer *input_buffer, Statement *statement)
{
statement->type = STATEMENT_INSERT;
char *keyword = strtok(input_buffer->buffer, " ");
char *id_string = strtok(NULL, " ");
char *username = strtok(NULL, " ");
char *email = strtok(NULL, " ");
if (id_string == NULL || username == NULL || email == NULL) {
return PREPARE_SYNTAX_ERROR;
}
int id = atoi(id_string);
if (id < 0) {
return PREPARE_NEGATIVE_ID;
}
if (strlen(username) > COLUMN_USERNAME_SIZE) {
return PREPARE_STRING_TOO_LONG;
}
if (strlen(email) > COLUMN_EMAIL_SIZE) {
return PREPARE_STRING_TOO_LONG;
}
statement->row_to_insert.id = id;
strcpy(statement->row_to_insert.username, username);
strcpy(statement->row_to_insert.email, email);
return PREPARE_SUCCESS;
}
// 语句的解析
PrepareResult prepare_statement(InputBuffer *input_buffer,
Statement *statement)
{
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
return prepare_insert(input_buffer, statement);
} else if (strncmp(input_buffer->buffer, "select", 6) == 0) {
statement->type = STATEMENT_SELECT;
return PREPARE_SUCCESS;
}
return PREPARE_UNRECOGNIZED_STATEMENT;
}
// 持久化row
void serialize_row(Row *source, void *destination)
{
memcpy((char *)destination + ID_OFFSET, &(source->id), ID_SIZE);
memcpy((char *)destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
memcpy((char *)destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
}
// 反持久化row
void deserialize_row(void *source, Row *destination)
{
memcpy(&(destination->id), (char *)source + ID_OFFSET, ID_SIZE);
memcpy(&(destination->username), (char *)source + USERNAME_OFFSET, USERNAME_SIZE);
memcpy(&(destination->email), (char *)source + EMAIL_OFFSET, EMAIL_SIZE);
}
//核心 row的定位
void *row_slot(Table *table, uint32_t row_num)
{
uint32_t page_num = row_num / ROWS_PER_PAGE;
void *page = table->pages[page_num];
if (page == NULL) {
page = table->pages[page_num] = malloc(PAGE_SIZE);
}
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return (char *)page + byte_offset;
}
// 核心 定位row之后持久化
ExecuteResult execute_insert(Statement *statement, Table *table)
{
if (table->num_rows >= TABLE_MAX_ROWS) {
return EXECUTE_TABLE_FULL;
}
Row *row_to_insert = &(statement->row_to_insert);
serialize_row(row_to_insert, row_slot(table, table->num_rows));
table->num_rows += 1;
return EXECUTE_SUCCESS;
}
// 查询语句执行
ExecuteResult execute_select(Statement *statement, Table *table)
{
Row row;
for (uint32_t i = 0; i < table->num_rows; i++) {
deserialize_row(row_slot(table, i), &row);
print_row(&row);
}
return EXECUTE_SUCCESS;
}
ExecuteResult execute_statement(Statement *statement, Table *table)
{
switch (statement->type) {
case (STATEMENT_INSERT):
return execute_insert(statement, table);
case (STATEMENT_SELECT):
return execute_select(statement, table);
}
}
Table *new_table()
{
Table *table = (Table *)malloc(sizeof(Table));
table->num_rows = 0;
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
table->pages[i] = NULL;
}
return table;
}
void free_table(Table *table)
{
for (int i = 0; table->pages[i]; i++) {
free(table->pages[i]);
}
free(table);
}
void print_prompt()
{
printf("microdb > ");
}
int main(int argc, char **argv)
{
InputBuffer *input_buffer = new_input_buffer();
Table *table = new_table();
while (true) {
print_prompt();
read_input(input_buffer);
if (input_buffer->buffer[0] == '.') {
switch (do_meta_command(input_buffer)) {
case (META_COMMAND_SUCCESS):
continue;
case (META_COMMAND_UNRECOGNIZED_COMMAND):
printf("Unrecognized command '%s'\n", input_buffer->buffer);
continue;
}
} else {
Statement statement;
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
case (PREPARE_STRING_TOO_LONG):
printf("String is too long.\n");
continue;
case (PREPARE_NEGATIVE_ID):
printf("ID must be positive.\n");
continue;
case (PREPARE_SYNTAX_ERROR):
printf("Syntax error. Could not parse statement.\n");
continue;
case (PREPARE_UNRECOGNIZED_STATEMENT):
printf("Unrecognized keyword at start of '%s'.\n",
input_buffer->buffer);
continue;
}
switch (execute_statement(&statement, table)) {
case EXECUTE_SUCCESS:
printf("Executed.\n");
break;
case EXECUTE_TABLE_FULL:
printf("Error: Table full.\n");
break;
}
}
}
return 0;
}









![Introduction to Multi-Armed Bandits——04 Thompson Sampling[2]](https://img-blog.csdnimg.cn/img_convert/c52f2fd8f387c56050a3a2568fe7b273.png)