前言
我们写的函数是怎么返回的,该如何返回一个临时变量,临时变量不是出栈就销毁了吗,为什么可以传递给调用方?返回对象的大小对使用的方式有影响吗?本文将带你探究这些问题,阅读本文需要对函数栈帧有一定的理解,并了解基本的汇编指令。
文章汇编代码:采用 GCC 8.3.1,对 C 代码使用 -Og 优化级别生成的可执行程序,再用 objdump -d 反汇编的结果。
寄存器保存
如果返回的对象比较小,寄存器可以放得下,返回值将被放到 %rax 中。%rax 只能存放整数数据和指针,浮点数使用另外一组单独的寄存器。
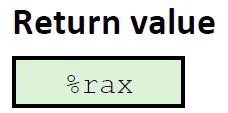
来看一段简单的代码:
// 一段简单让两数相乘的代码,写成这种形式,主要是尽量减少编译器优化
long mult2(long a, long b) {
long t = a * b;
return t;
}
void mult_store(long x, long y, long* dest) {
long t = mult2(x, y);
*dest = t;
}
00000000004004d2 <mult2>:
# a in %rdi,b in %rsi
4004d2: mov %rdi,%rax # 把 a 移动到 %rax
4004d5: imul %rsi,%rax # 此时 %rax 保存的是参数 a,再将 %rsi 保存的参数 b 乘到 %rax
4004d9: retq # 这时 %rax 保存的是 a * b
00000000004004da <mult_store>:
# x in %rdi,y in %rsi,dest in %rdx
4004da: push %rbx
4004db: mov %rdx,%rbx # 保存 dest,采取调用方保存
4004de: callq 4004d2 <mult2> # 调用 mult2
4004e3: mov %rax,(%rbx) # 将 %rax 保存的 a * b
# 移动到 %rbx 保存的 dest 指针指向的内存处
# t 并没有实际的作用,编译器将其创建优化掉了
4004e6: pop %rbx
4004e7: retq
编译器优化
上面所说的都是比较小的内置类型,那假如返回的对象很大,%rax 放不下该怎么办?
下面介绍一种 C++ 对返回值的优化方式,实际编译器并不一定会使用该方式。
class qgw {
// 有默认构造函数、拷贝构造函数、析构函数等
long a1;
long a2;
long a3;
} qgw;
qgw fun() {
qgw q;
// 处理 q
return q;
}
如果返回值很小,我们可以使用寄存器取到返回值,现在又该怎么办呢?Stroustrup 在 cfront 中的解决方案是一个双阶段优化:
- 加上一个额外参数,类型是 class object 的一个 reference
- 这个参数在最后用 “返回值” 构建
- 在 return 指令之前插入一个拷贝构造调用操作,以便将想要返回的 object 的内容当做上述新增参数的初值
上述代码经转化后如下:
void fun(qgw& __result) {
qgw q;
// 编译器产生的默认构造函数调用操作
q.qgw::qgw();
// 处理 q
// 编译器产生的拷贝构造调用操作
__result.qgw::qgw(q);
return;
}
qgw qin = fun();
// 转化为
// 不必为 qin 调用默认构造函数
qgw qin;
fun(qin);
// fun() 函数返回值调用 test 函数
fun().test();
// 转化为
// 编译器生成的临时变量
qgw __temp0;
(fun(__temp0), __temp0).test();
还有一种被称为 Named Return Value(NRL)优化,被视为标准 C++ 编译器的一个义不容辞的优化操作。
qgw fun() {
qgw q;
// 处理 q
return q;
}
// 直接优化为
void fun(qgw& __result) {
// 默认构造被调用
__result.gqw::qgw();
// 直接处理 __result
return;
}
经上述处理后,函数没有真正意义上的返回值了,也就不需要处理大对象的情况了。
对于传参请参考:传参的理解




![[基础]qml基础控件](https://img-blog.csdnimg.cn/img_convert/6b47376f6bbc4d91ab9e5fcd754009b0.png)

![流批一体计算引擎-6-[Flink]的Python DataStream API程序](https://img-blog.csdnimg.cn/09f7fe17a88b4fd598e88b2eb3b9b9cb.png)


![[JavaEE]线程池](https://img-blog.csdnimg.cn/5106466fd66245a5b53b1f687a282933.png)