文章目录
- 前言
- 全局内存的访问模式
- 合并访问和非合并访问
- 使用全局内存进行矩阵转置
- 矩阵复制
- 矩阵转置
- 总结
前言
全局内存的合理使用
全局内存的访问模式
合并访问和非合并访问
合并访问指的是一个线程束(同一个线程块中相邻的wrapSize个线程。现在GPU的内建变量wrapSize都是32)对全局的一次性访问请求(读或写)导致最少数据量的传输。
定量的说,可以定义一个合并度,它等于线程束请求的字节数除以由该请求导致的所有数据传输处理的字节数。若所有数据传输中处理的数据都是线程束所需要的,那么合并度就是100%,即对应合并访问,否则为非合并访问。
需要注意的是为了保证一次数据传输中内存片段的首地址是最小粒度()的整数倍,cuda运行cudaMalloc函数时分配的内存首地址至少是256字节的整数倍。
通过例子来看几种常见的内存访问模式及其和合并度。
(1)顺序合并
__global__ void add(float *x,float *y,float *z)
{
int n = threadIdx.x + blockIdx.x * blockDim.x;
z[n] = x[n] + y[n];
}
add<<<128,32>>>(x,y,z);
从上面的代码可知,核函数线程块大小为blockDim.x=32,int类型,对应128个字节,线程块中的每个线程束可以访问这么多的连续内存。首地址一定是256的整数倍,这样根据前面的概念,在合并度100%的情况下,一个线程束将请求32*4=128个字节的数据。访问只需要128/32=4次数据传输即可完成。
(2)不对齐的非合并访问
__global__ void add_offset(float *x,float *y,float *z)
{
int n = threadIdx.x + blockIdx.x * blockDim.x + 1;
z[n] = x[n] + y[n];
}
add_offset<<<128,32>>>(x,y,z);
第一个线程块中的线程数将访问数组x中的第1-32个元素。假设数组x的首地址是256字节,该线程数将访问设备内存的260-387字节。将触发5次数据传输,对应的内存地址分别是256-287,288-319,320-351,352-383和384-415字节。这样的访问属于不对齐的非合并访问,合并度为( 32 ∗ 4 32*4 32∗4)/( 32 ∗ 5 32*5 32∗5)=4/5=0.8,即80%。
(3)跨越式的非合并访问
__global__ void add_stride(float *x,float *y,float *z)
{
int n = blockIdx.x + threadIdx.x * gridDim.x ;
z[n] = x[n] + y[n];
}
add_offset<<<128,32>>>(x,y,z);
上面的代码第一个线程块中的线程束将访问数组x中指标为0,128,256,384等元素,不在一个连续的32字节的内存片段,所以将触发32次数据传输,假设首地址为256,256-287,384-415等32个不连续字节段。合并度为( 32 ∗ 4 32*4 32∗4)/( 32 ∗ 32 32*32 32∗32)=4/32=0.125,即12.5%。这样的访问属于跨越式的非合并访问。
使用全局内存进行矩阵转置
矩阵复制
首先考虑矩阵复制问题,如将B = A
// const real *A, real *B是全局内存,const int N是常量内存
__global__ void copy(const real *A, real *B, const int N)
{
// 二维,TILE_DIM宏定义为32,可以在核函数里直接调用宏定义和const的整型和浮点型变量
const int nx = blockIdx.x * TILE_DIM + threadIdx.x; // 寄存器内存
const int ny = blockIdx.y * TILE_DIM + threadIdx.y;
// 将多维索引转换成一维的索引
const int index = ny * N + nx; // 寄存器内存
if (nx < N && ny < N)
{
B[index] = A[index];
}
}
// 定义网格和线程块大小
const int grid_size_x = (N+TILE_DIM-1)/TILE_DIM;
const int grid_size_y = grid_stride_y;
// 定义多维网格和线程块,第三个维度默认为1
const dim3 block_size(TILE_DIM,TILE_DIM);
const dim3 gride_size(grid_size_x,grid_size_y);
copy<<<gride_size,block_size>>>(d_A,d_B,N);
矩阵转置
在上面的复制操作中,定义的索引变量和读写操作代码为:
const int index = ny * N + nx;
if (nx < N && ny < N) B[index] = A[index];
两条语句写成一条:
if (nx < N && ny < N) B[ny * N + nx] = A[ny * N + nx];
数学角度看,相当于做了
B
i
j
B_{ij}
Bij =
A
i
j
A_{ij}
Aij。所以要转置的话,就是
B
i
j
B_{ij}
Bij =
A
j
i
A_{ji}
Aji的操作。
代码替换成:
if (nx < N && ny < N) B[nx * N + nx] = A[ny * N + nx];
// or
if (nx < N && ny < N) B[ny * N + nx] = A[nx * N + ny];
在上面的第一条语句中,矩阵A读取是顺序的,矩阵B中写入不是顺序的。根据全局内存的访问模式的划分规则,可以说核函数对矩阵A的读取是非合并的,对矩阵B的写入是合并的。第二条语句正好反过来,矩阵A读取不是顺序的,矩阵B中写入是顺序的,核函数对矩阵A的读取是合并的,对矩阵B的写入是非合并的。
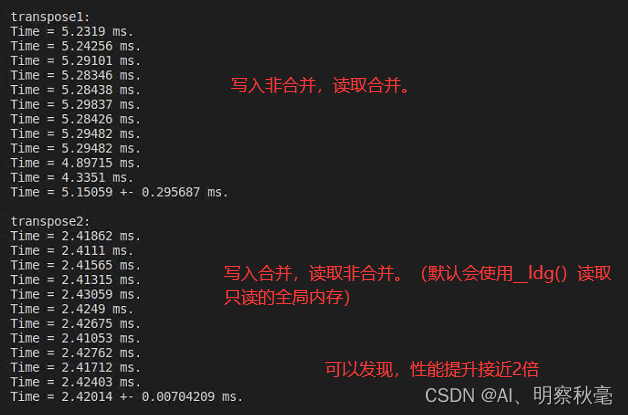
那么这两个语句都能正确进行矩阵转置的代码用起来性能会有什么差别呢?
从帕斯卡架构的GPU开始,编译器如果能判断一个全局内存变量在整个核函数的范围都是只读的,会自动用上篇讲的__ldg()只读数据缓存加载函数读取,它能缓解非合并访问带来的影响。而对于全局内存的写入,则没有类似的函数。所以,对只读的可以是合并和非合并的读取,但是可以写入数据的最好是合并访问。
在2080Ti上,给定N=10000,通过代码例子来看看性能的影响:
代码:https://github.com/brucefan1983/CUDA-Programming/blob/master/src/07-global-memory/matrix.cu
总结
cuda全局内存通过选择访问模式的合理使用,对性能有较大的提升。
参考:
如博客内容有侵权行为,可及时联系删除!
CUDA 编程:基础与实践
https://docs.nvidia.com/cuda/
https://docs.nvidia.com/cuda/cuda-runtime-api
https://github.com/brucefan1983/CUDA-Programming

![Introduction to Multi-Armed Bandits——04 Thompson Sampling[2]](https://img-blog.csdnimg.cn/img_convert/c52f2fd8f387c56050a3a2568fe7b273.png)






![[基础]qml基础控件](https://img-blog.csdnimg.cn/img_convert/6b47376f6bbc4d91ab9e5fcd754009b0.png)

![流批一体计算引擎-6-[Flink]的Python DataStream API程序](https://img-blog.csdnimg.cn/09f7fe17a88b4fd598e88b2eb3b9b9cb.png)