什么是断点续传
上图是我们平时在浏览器下载文件的场景,下载的本质是数据的传输。当出现网络异常,浏览器异常,或者文件源的服务器异常,下载都可能会终止。而当异常解除后,重新下载文件,我们希望从上一次下载的位置开始下载,而不是从头开始下载。这就是断点续传
断点续传的实现
ETag头部字段
ETag是用来标识文件的头部字段,由用户自己设定,其目的是表示文件的唯一性,修改过的文件和原文件是不同的。
ETag由服务端设置
static void download(const httplib::Request& req, httplib::Response& resp)
{
//......
//服务端设置ETag头部字段
resp.set_header("ETag", "......");
//......
}浏览器解析响应,发现有ETag字段,保存并在下次发送GET请求时包含。ETag搭配Range字段实现断点续传
Range
当服务端返回的响应中有Accept-Ranges头部字段,代表服务端允许断点续传
客户端此时发送的请求可以携带Range头部字段,形式如下:
//服务端响应设置允许断点续传
static void download(const httplib::Request& req, httplib::Response& resp)
{
//......
//bytes表示客户端数据请求区间的单位
resp.set_header("Accept-Ranges", "bytes");
//......
}
//客户端请求断点续传区间
static void download(const httplib::Request& req, httplib::Response& resp)
{
//......
//val是服务端上一次发送的ETag
res.set_header("If-Range", ETag);
//val的bytes是服务端返回的断点区间的单位
//start-end代表重传start到end区间的数据,比如5430-66758
res.set_header("Range", "bytes=start-end");
//......
}
//服务端返回响应
static void download(const httplib::Request& req, httplib::Response& resp)
{
//......
//响应的文件数据范围是start-end,文件总大小为fsize
resp.set_header("Content-Range, "start-end/fsize");
//重新设置ETag
resp.set_header("ETag", "......");
//......
}
- 服务端设置Accept-Range字段,val值一般为bytes。该字段表示服务端支持断点续传,以字节单位传输数据
- ETag表示服务端上某一版本资源的唯一标识,如果资源被改动,则ETag改变。客户端收到ETag表示会保存
当下载中断时,浏览器重新下载文件,则第二次的http请求需要包含If-Range字段和Range字段
- If-Range字段:保存服务端响应的ETag字段的信息。用于服务端判断是否和上一次请求的资源一致,一致则断点续传,不一致则从头重新下载
- Range字段:记录断点请求的数据区间,bytes start-end,表示请求服务器资源从第start字节开始到第end个字节的数据
收到客户端发送的断点续传的http响应,需要包含Content-Range字段和ETag字段4
- Content-Range: start-end/文件大小,表示http响应包含文件数据从start开始到end结束的文件数据,文件大小表示文件总大小
- ETag:服务端资源的唯一标识
当服务端返回的数据是断点续传的数据区间时,状态码是206
示例断点续传的请求&响应如下:
GET /download/a.txt http/1.1
If-Range: "文件唯一标识"
Range: bytes=89-999
-------------------------------------------
HTTP/1.1 206 Partial Content
Accept-Ranges: bytes
Content-Range: bytes 89-999/100000
Content-Type: application/octet-stream
ETag: "文件唯一标识"
对应文件从89到999字节的数据。编码实现
使用httplib实现断点续传。
基本逻辑:
- 查看客户端请求是否包含If-Range字段,有则匹配请求文件的ETag,没有则是正常下载文件
- 若相同,说明客户端请求断点续传,解析Range字段,将start-end的数据填入响应的正文部分。并设置头部字段
- 若不同,说明客户端请求的数据被修改了,则需要从头下载,返回文件全部数据。并设置头部字段
以上逻辑,我们需要手动解析客户端响应的Range字段,但httplib已经帮我们解析了,以下源码是httplib做的部分处理

这部分表示,httplib解析客户端请求,如果包含Range字段,会自动设置响应的状态码为206
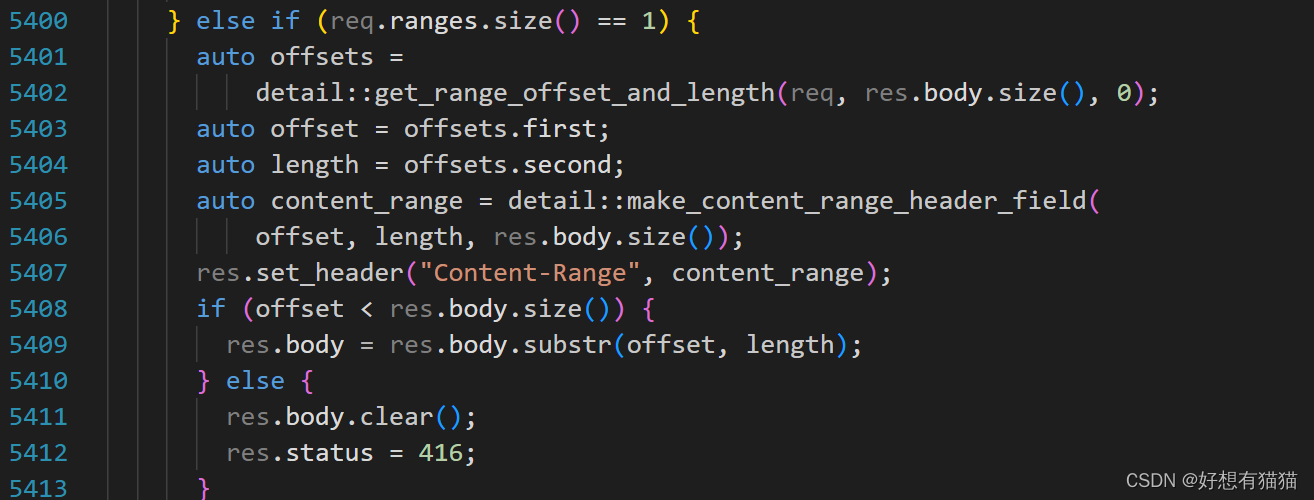
这部分是httplib解析Range字段,在返回文件数据时,会根据Range字段的解析结果,截断文件数据。所以我们在代码编写时不管是正常下载,还是断点续传都直接响应文件全部数据即可, 如果是断点续传,httplib会帮我们进行数据截断,如果start-end是5430-66347,就截出这部分数据返回给客户端
示例代码如下:
//生成ETag
//ETag = 文件名 + 文件大小 + 文件最后一次修改时间
static std::string getETag(const std::string& filename, const struct stat st)
{
std::string ETag;
ETag = filename + std::to_string(st.st_size) + std::to_string(st.m_tim);
return ETag;
}
//返回客户端要下载的文件
static void download(const httplib::Request& req, httplib::Response& resp)
{
//1. 获取客户端请求的资源路径:req.path。截取最后一个/后的字符串,为文件名
//2. 根据资源路径,获取文件信息
auto pos = req.path.find_last_of('/');
std::string filename
if(pos == std::string::npos)
filename = req.path;
else
filename = req.path.substr(pos + 1);
struct stat st;
stat(filename.c_str(), &st);
//查看请求是否有If-Range(记录之前服务器响应的ETag)
bool retrans = true;
std::string old_etag;
//有If-Range,两种可能:有修改,全部重传;没有修改,断点续传
if(req.has_header("If-Range"))
{
old_etag = req.get_header_value("If-Range");
if(old_etag == getETag(info, st))
retrans = false;
}
//4. 读取文件信息到响应中
std::ifstream ifs(filename.c_str(), std::ios::binary);
//读取文件内容
body.resize(st.s_size);
ifs.read(&body[0], st.s_size);
//5. 设置头部字段
resp.set_header("ETag", getETag(info, st));
resp.set_header("Accept-Ranges", "bytes");//提供断点续传
resp.set_header("Content-Type", "application/octet-stream");//下载文件
if(retrans)
{
//文件有修改,需要重传文件
//ETag Accept-Ranges bytes(断点续传)
resp.status = 200;
}
else
{
//断点续传实现:获取头部字段中Range:bytes start-end,解析请求文件的起始和结束
//再返回响应时,对文件内容进行截断
//但httplib都实现了,他检测到req中有Range,然后进行处理,甚至会设置resp的状态码
//我们只要返回完整的文件,httplib会对文件进行截断,最后响应正文中只有start-end的文件内容
//resp.set_header("Content-Range", "bytes start-end/fsize");//原本还要设置这个头部字段,httplib帮我们做了
resp.status = 206;//断点续传的状态码
}
}




![[数据集][目标检测]轮胎检测数据集VOC+YOLO格式439张1类别](https://img-blog.csdnimg.cn/direct/be432130d3814e5fae9592d21b2ab5d1.png)