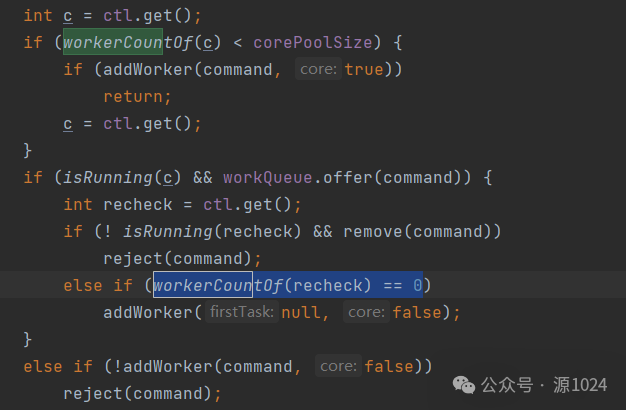
sh命令
cmd="fairseq-train data-bin/$data_dir
--save-dir $save_dir
--distributed-world-size $gpu_num -s $src_lang -t $tgt_lang
--arch $arch
--dropout $dropout
--criterion $criterion --label-smoothing 0.1
--task mmt_vqa
--optimizer adam --adam-betas '(0.9, 0.98)'
--lr $lr --lr-scheduler inverse_sqrt --warmup-init-lr 1e-07 --warmup-updates $warmup
--max-tokens $max_tokens --update-freq $update_freq
--share-all-embeddings
--find-unused-parameters
--skip-invalid-size-inputs-valid-test
--patience $keep_last_epochs
--keep-last-epochs $keep_last_epochs
--image-name-dir data-bin/$data_dir
--ptm-name $vision_model_name
--vision-model $vision_model_name
--weight $weight
--source-sentence-dir data-bin"
主要的执行流程–task
fairseq/tasks/mmt_vqa.py
模型–arch
fairseq/models/transformer/transformer_mmt_vqa_legacy.py
@register_model_architecture("transformer_mmt_vqa", "transformer_mmt_vqa_2sa_2decoder")
def transformer_mmt_vqa_2sa_2decoder(args):
args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 128)
args.encoder_ffn_embed_dim = getattr(args, "encoder_ffn_embed_dim", 256)
args.encoder_attention_heads = getattr(args, "encoder_attention_heads", 4)
args.encoder_layers = getattr(args, "encoder_layers", 4)
args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 128)
args.decoder_ffn_embed_dim = getattr(args, "decoder_ffn_embed_dim", 256)
args.decoder_attention_heads = getattr(args, "decoder_attention_heads", 4)
args.decoder_layers = getattr(args, "decoder_layers", 4)
mmt_vqa_base_architecture(args)
DualSAEncoder
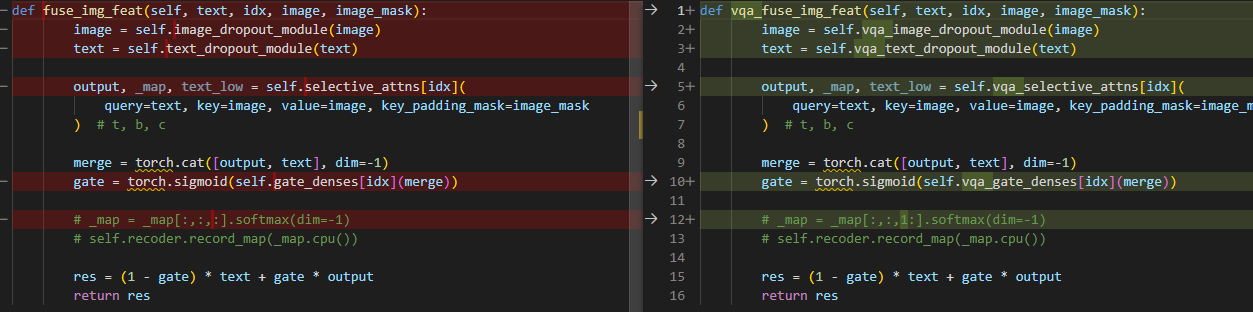
VQA和MMT融合图像特征时 提取特征的encoder不一样、融合时选择的注意力也不一样、融合的门控参数也不一样。
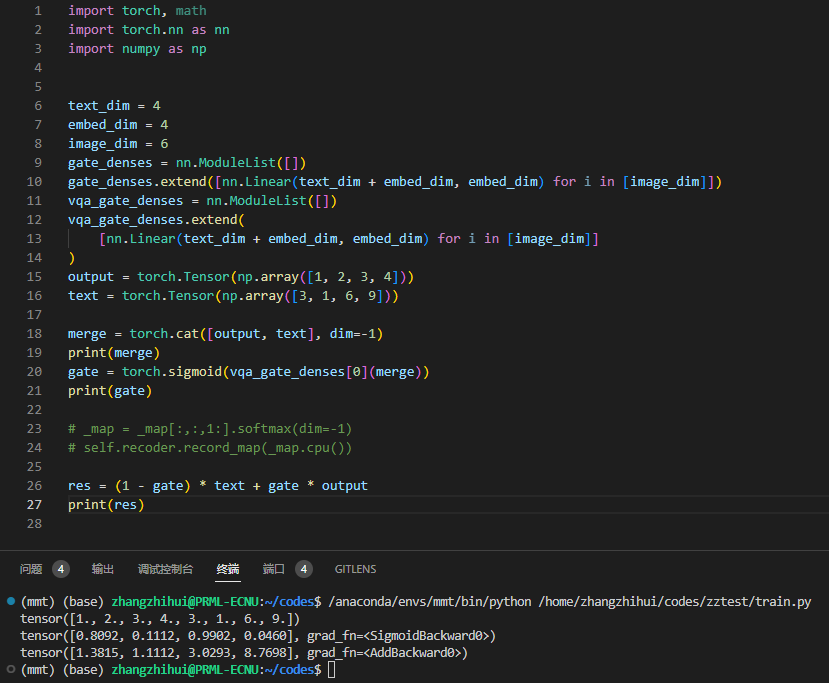
具体的特征融合:
DualLayersDecoder
TransformerMMTVQAModel
损失函数–criterion
fairseq/criterions/label_smoothed_cross_entropy_mmt_vqa.py




![[数据集][目标检测]轮胎检测数据集VOC+YOLO格式439张1类别](https://img-blog.csdnimg.cn/direct/be432130d3814e5fae9592d21b2ab5d1.png)