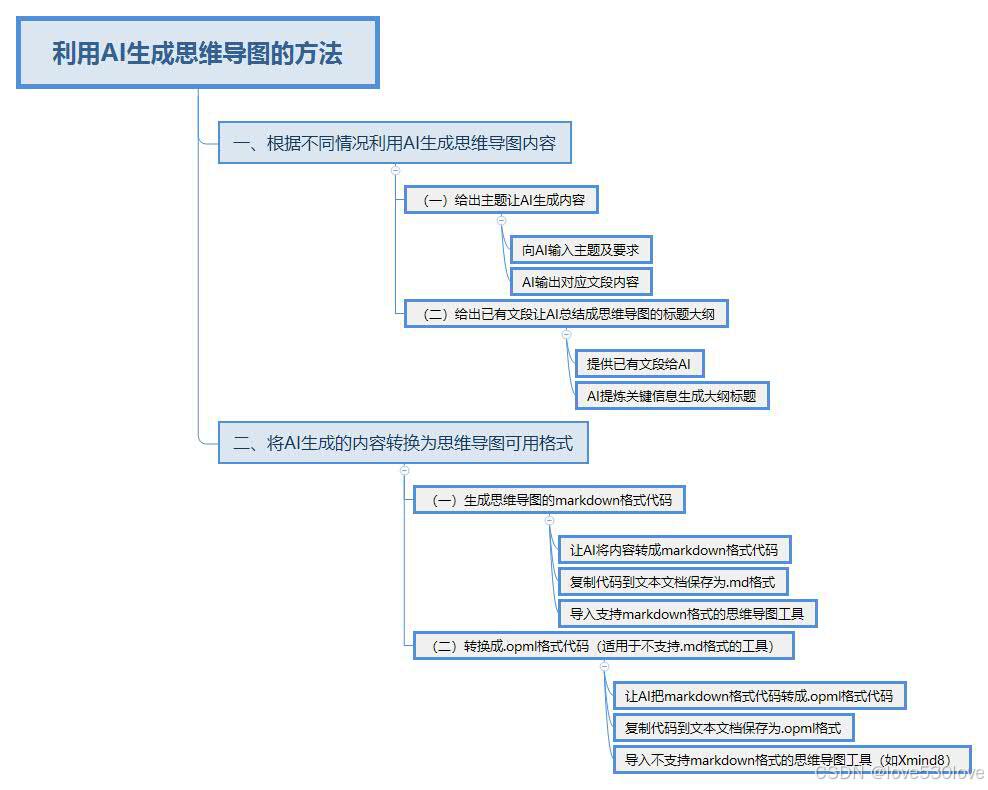
文章目录
- 什么是下采样?
- 为什么在逻辑回归中要使用下采样?
- 使用下采样和不使用下采样的区别
- 实例
- 1、实例内容
- 2、实例步骤
什么是下采样?
- 下采样(Down - Sampling)是一种数据处理技术,主要用于处理数据集中不同类别样本数量不均衡的情况。它通过减少数据集中数量较多类别的样本数量,使不同类别样本的数量达到相对平衡。
为什么在逻辑回归中要使用下采样?
- 在逻辑回归应用于分类任务时,如果数据集中存在类别不平衡的情况,例如正类样本只占总样本数的 1%,而负类样本占 99%。逻辑回归模型在训练过程中会倾向于将更多的样本预测为负类,因为这样可以获得较高的准确率(把所有样本都预测为负类,准确率也能达到 99%)。下采样可以平衡不同类别样本的数量,使得逻辑回归模型能够更加关注少数类的特征,从而提高模型对少数类的分类性能。
使用下采样和不使用下采样的区别
- 不使用下采样,是对原始数据直接进行训练集和测试集的划分,进行模型的性能测试。
- 使用下采样是,对原始数据进行划分后再对训练集进行划分,划分成y值相同数量相同的训练集,原始数据划分的测试集,当测试集。
实例
我们从实例中观察下采样。
1、实例内容
本次实例是对银行的数据进行分类的问题,数据部分内容为
共有28万多条数据。其中Time为无关特征,class为分类特征有两个分类分别为0、1,其余全部为特征变量。如图看看出Amount里的数据与其他特征的数据有区别,故此数据处理中要对Amount进行z标准化处理。
2、实例步骤
- 导入数据
- 处理数据
- 下采样处理数据
- 画图查看样本个数
- 抽取数据进行划分
- 选择较优惩罚因子
- 建立最优模型并训练数据
- 测试数据并评估模型性能
- 导入数据
需要数据测试的自取通过网盘分享的文件:creditcard.csv
链接: https://pan.baidu.com/s/1BIjUp16GBRlkbmN86XjCuw 提取码: rqhx
data = pd.read_csv('creditcard.csv')
- 处理数据
"""数据标准化:z标准化"""
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
a = data[['Amount']] # 返回dataframe数据,而不是series
data['Amount']=scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'],axis=1) # 删除无用列
- 下采样处理数据
"""下采样解决样本不均衡问题"""
positive_eg = data[data["Class"]==0] # 获取到了所有标签(Class=0)的数据
negative_eg = data[data["Class"]==1] # 获取到了所有标签(Class=1)的数据
np.random.seed(seed=0) # 随机种子
positive_eg = positive_eg.sample(len(negative_eg)) # sample表示随机从参数里面选择参数
data_c = pd.concat([positive_eg,negative_eg]) # 是把两个pandas数据组合为一个
print(data_c)

- 画图查看样本个数
"""绘制图形,查看正负样本个数"""
mpl.rcParams['font.sans-serif']=['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus']=False
labels_count = pd.value_counts(data_c["Class"]) # 统计表格data_c中class这一列中,为0的数量和为1的数量
plt.title('正负例样本数') # matplotlib直接显示中文?
plt.xlabel('类别')
plt.ylabel('频数')
labels_count.plot(kind='bar')
plt.show()

可以看到训练集中class为0和1的样本数量。
- 抽取数据进行划分
其中test_size=0.3代表从被切分数据的百分之三十。
"""训练集使用下采样数据,测试集使用原始数据进行预测"""
from sklearn.model_selection import train_test_split
# 抽选数据后,对下采样数据划分
x = data_c.drop("Class",axis=1) # 对data_c数据进行划分,以y轴
y = data_c.Class
x_train,x_test,y_train,y_test= \
train_test_split(x,y,test_size=0.3,random_state=0)
# 对原始数据集进行切分,用于后期的测试
x_whole =data.drop("Class",axis=1)
y_whole = data.Class
x_train_w,x_test_w,y_train_w,y_test_w= \
train_test_split(x_whole,y_whole,test_size=0.2,random_state=0)
- 选择较优惩罚因子

"""执行交叉验证操作
scoring:可选"accuracy(精度)"、recall(召回率)、roc_auc(roc值)
neg_mean_squared_error(均方误差)
"""
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score # 交叉验证的函数
# 交叉验证选择较优惩罚因子
scores = []
c_param_range = [0.01,0.1,1,10,100]
for i in c_param_range:# 第一个词循环的时候C=0.01,5个逻辑回归模型
lr = LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)
score = cross_val_score(lr,x_train,y_train,cv=10,scoring='recall') # 交叉验证
score_mean = sum(score)/len(score) # 交叉验证后的值召回率
scores.append(score_mean) # 里面保存了所有的交叉验证召回率
print(score_mean) # 将不同的c参数分别传入模型,分别看看哪个模型效果更好
best_c = c_param_range[np.argmax(scores)] # 寻找到scores中最大值的对应的c参数

- 建立最优模型并训练数据
- 自测:
lr = LogisticRegression(C=best_c,penalty='l2',max_iter=1000)
lr.fit(x_train,y_train)
- 测试数据并评估模型性能
- 分别对原始数据划分的测试集和原始数据的训练集划分的测试集进行训练:
from sklearn import metrics
# 传入下采样后的测试数据
test_s_predicted = lr.predict(x_test_w)
print(metrics.classification_report(y_test_w, test_s_predicted))
# 传入原数据的测试数据
test_predicted = lr.predict(x_test)
print(metrics.classification_report(y_test, test_predicted))

因为银行主要观察特征为1的人,宁愿原本为0的预测为1,也不愿判断错一个1的样本。故主要看召回率,从测试结果可以看出准确率还是挺高的,也没有产生过拟合和欠拟合。