目录
一:串行的Stream流
二:并行的Stream流
获取并行Stream流的两种方式
小结
三:并行和串行Stream流的效率对比
四:parallelStream线程安全问题
五:parallelStream背后的技术
Fork/Join框架介绍
Fork/Join原理-分治法
Fork/Join原理-工作窃取算法
Fork/Join案例
小结
一:串行的Stream流
目前我们使用的Stream流是串行的,就是在一个线程上执行。
@Test
public void test0Serial() {
long count = Stream.of(4, 5, 3, 9, 1, 2, 6)
.filter(s -> {
System.out.println(Thread.currentThread() + ", s = " + s);
return true;
})
.count();
System.out.println("count = " + count);
}
效果:
Thread[main,5,main], s = 4
Thread[main,5,main], s = 5
Thread[main,5,main], s = 3
Thread[main,5,main], s = 9
Thread[main,5,main], s = 1
Thread[main,5,main], s = 2
Thread[main,5,main], s = 6二:并行的Stream流
parallelStream
其实就是一个并行执行的流。它通过默认的
ForkJoinPool
,可能提高多线程任务的速度。
获取并行Stream流的两种方式
1.
直接获取并行的流
2.
将串行流转成并行流
@Test
public void testgetParallelStream() {
ArrayList<Integer> list = new ArrayList<>();
// 直接获取并行的流
// Stream<Integer> stream = list.parallelStream();
// 将串行流转成并行流
Stream<Integer> stream = list.stream().parallel();
}
并行操作代码:
@Test
public void test0Parallel() {
long count = Stream.of(4, 5, 3, 9, 1, 2, 6)
.parallel() // 将流转成并发流,Stream处理的时候将才去
.filter(s -> {
System.out.println(Thread.currentThread() + ", s = " + s);
return true;
})
.count();
System.out.println("count = " + count);
}
效果:
@Test
public void test0Parallel() {
long count = Stream.of(4, 5, 3, 9, 1, 2, 6)
.parallel() // 将流转成并发流,Stream处理的时候将才去
.filter(s -> {
System.out.println(Thread.currentThread() + ", s = " + s);
return true;
})
.count();
System.out.println("count = " + count);
}
效果:
Thread[ForkJoinPool.commonPool-worker-13,5,main], s = 3
Thread[ForkJoinPool.commonPool-worker-19,5,main], s = 6
Thread[main,5,main], s = 1
Thread[ForkJoinPool.commonPool-worker-5,5,main], s = 5
Thread[ForkJoinPool.commonPool-worker-23,5,main], s = 4
Thread[ForkJoinPool.commonPool-worker-27,5,main], s = 2
Thread[ForkJoinPool.commonPool-worker-9,5,main], s = 9
count = 7小结
获取并行流有两种方式:
- 直接获取并行流: parallelStream()
- 将串行流转成并行流: parallel()
三:并行和串行Stream流的效率对比
使用
for
循环,串行
Stream
流,并行
Stream
流来对
5
亿个数字求和。看消耗的时间。
public class Demo06 {
private static long times = 50000000000L;
private long start;
@Before
public void init() {
start = System.currentTimeMillis();
}
@After
public void destory() {
long end = System.currentTimeMillis();
System.out.println("消耗时间: " + (end - start));
}
// 测试效率,parallelStream 120
@Test
public void parallelStream() {
System.out.println("serialStream");
LongStream.rangeClosed(0, times)
.parallel()
.reduce(0, Long::sum);
}
// 测试效率,普通Stream 342
@Test
public void serialStream() {
System.out.println("serialStream");
LongStream.rangeClosed(0, times)
.reduce(0, Long::sum);
}
// 测试效率,正常for循环 421
@Test
public void forAdd() {
System.out.println("forAdd");
long result = 0L;
for (long i = 1L; i < times; i++) {
result += i;
}
}
}
我们可以看到
parallelStream
的效率是最高的。
Stream
并行处理的过程会分而治之,也就是将一个大任务切分成多个小任务,这表示每个任务都是一个操作。
四:parallelStream线程安全问题
// 并行流注意事项
@Test
public void parallelStreamNotice() {
ArrayList<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 1000; i++) {
list.add(i);
}
List<Integer> newList = new ArrayList<>();
// 使用并行的流往集合中添加数据
list.parallelStream()
.forEach(s -> {
newList.add(s);
});
System.out.println("newList = " + newList.size());
}运行效果:
newList = 903
我们明明是往集合中添加
1000
个元素,而实际上只有
903
个元素。
解决方法: 加锁、使用线程安全的集合或者调用
Stream
的
toArray()
/
collect()
操作就是满足线程安全的了。
// parallelStream线程安全问题
@Test
public void parallelStreamNotice() {
ArrayList<Integer> list = new ArrayList<>();
/*IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
list.add(i);
});
System.out.println("list = " + list.size());*/
// 解决parallelStream线程安全问题方案一: 使用同步代码块
/*Object obj = new Object();
IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
synchronized (obj) {
list.add(i);
}
});*/
// 解决parallelStream线程安全问题方案二: 使用线程安全的集合
// Vector<Integer> v = new Vector();
/*List<Integer> synchronizedList = Collections.synchronizedList(list);
IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
synchronizedList.add(i);
});
System.out.println("list = " + synchronizedList.size());*/
// 解决parallelStream线程安全问题方案三: 调用Stream流的collect/toArray
List<Integer> collect = IntStream.rangeClosed(1, 1000)
.parallel()
.boxed()
.collect(Collectors.toList());
System.out.println("collect.size = " + collect.size());
}五:parallelStream背后的技术
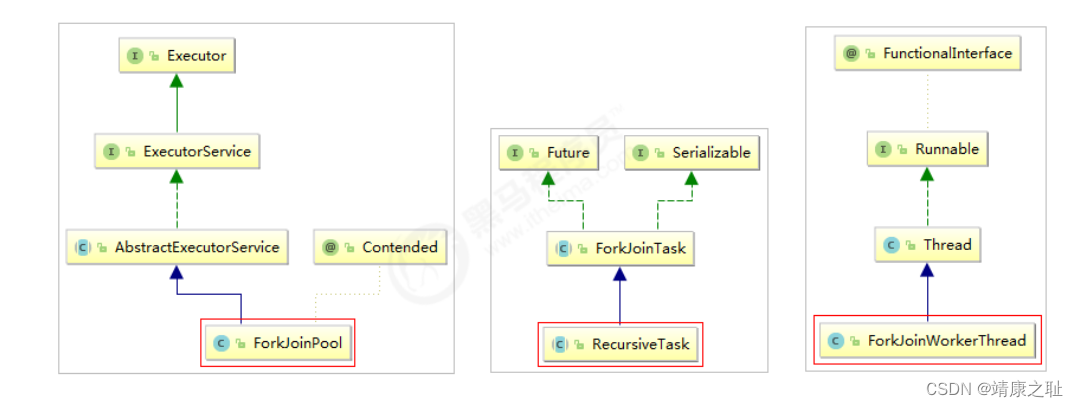
Fork/Join框架介绍
parallelStream
使用的是
Fork/Join
框架。
Fork/Join
框架自
JDK 7
引入。
Fork/Join
框架可以将一个大任务拆分为很多小任务来异步执行。 Fork/Join
框架主要包含三个模块:
1.
线程池:
ForkJoinPool
2.
任务对象:
ForkJoinTask
3.
执行任务的线程:
ForkJoinWorkerThread
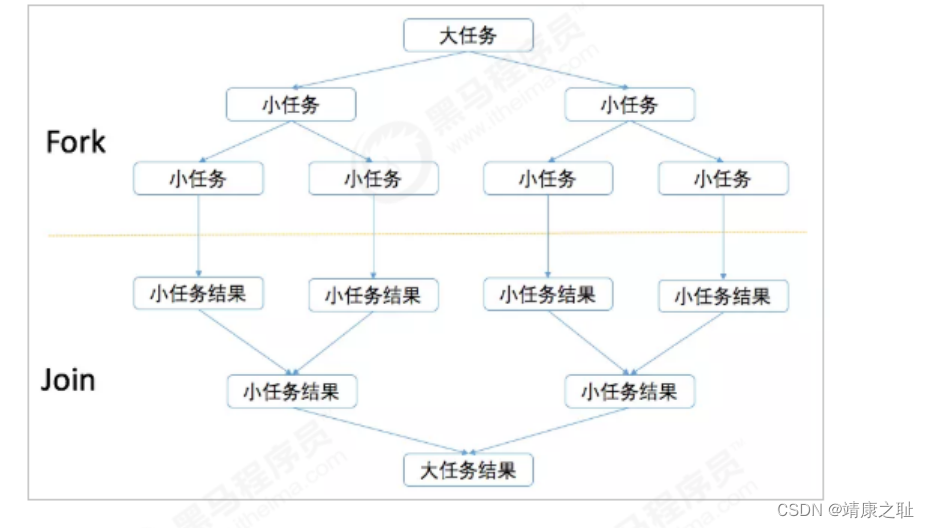
Fork/Join原理-分治法
ForkJoinPool
主要用来使用分治法
(Divide-and-Conquer Algorithm)
来解决问题。典型的应用比如快速排序算法,ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对
1000
万个数据进行排序,那么会将这个任务分割成两个500
万的排序任务和一个针对这两组
500
万数据的合并任务。以此类推,对于
500
万的数据也会做出同样的分割处 理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10
时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+
个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
Fork/Join原理-工作窃取算法
Fork/Join
最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的
cpu
,那么如何利用好这个空闲的cpu就成了提高性能的关键,而这里我们要提到的工作窃取(
work-stealing
)算法就是整个
Fork/Join
框架的核心理念Fork/Join工作窃取(
work-stealing
)算法是指某个线程从其他队列里窃取任务来执行。
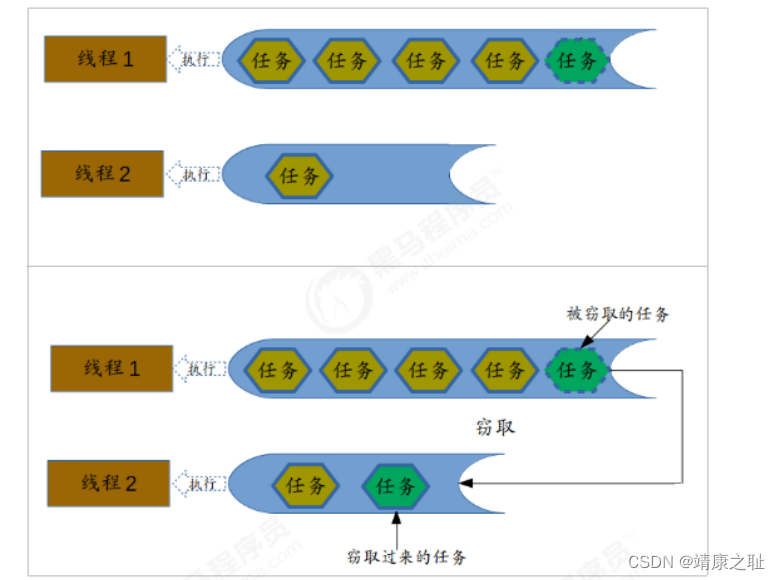
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来 执行队列里的任务,线程和队列一一对应,比如A
线程负责处理
A
队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
上文中已经提到了在
Java 8
引入了自动并行化的概念。它能够让一部分
Java
代码自动地以并行的方式执行,也就是我们使用了ForkJoinPool
的
ParallelStream
。
对于
ForkJoinPool
通用线程池的线程数量,通常使用默认值就可以了,即运行时计算机的处理器数量。可以通过设置系统属性:java.util.concurrent.ForkJoinPool.common.parallelism=N
(
N
为线程数量),来调整
ForkJoinPool
的线程数量,可以尝试调整成不同的参数来观察每次的输出结果。
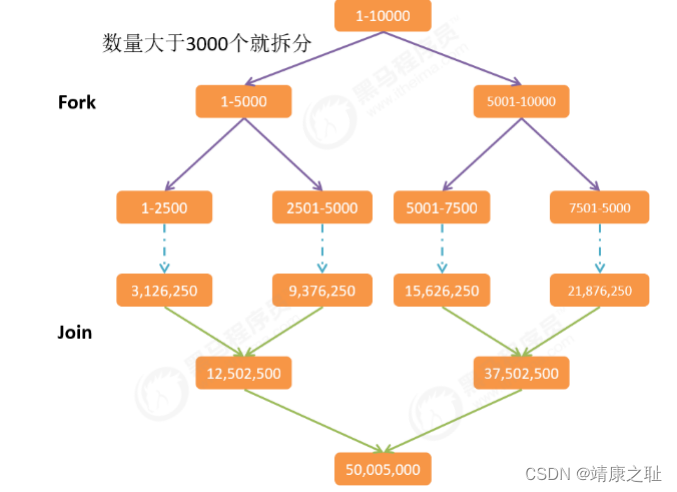
Fork/Join案例
需求:使用
Fork/Join
计算
1-10000
的和,当一个任务的计算数量大于
3000
时拆分任务,数量小于
3000
时计算。
mport java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class Demo08ForkJoin {
public static void main(String[] args) {
long start = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool();
SumRecursiveTask task = new SumRecursiveTask(1, 99999999999L);
Long result = pool.invoke(task);
System.out.println("result = " + result);
long end = System.currentTimeMillis();
System.out.println("消耗时间: " + (end - start));
}
}
// 1.创建一个求和的任务
// RecursiveTask: 一个任务
class SumRecursiveTask extends RecursiveTask<Long> {
// 是否要拆分的临界值
private static final long THRESHOLD = 3000L;
// 起始值
private final long start;
// 结束值
private final long end;
public SumRecursiveTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
if (length < THRESHOLD) {
// 计算
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
// 拆分
long middle = (start + end) / 2;
SumRecursiveTask left = new SumRecursiveTask(start, middle);
left.fork();
SumRecursiveTask right = new SumRecursiveTask(middle + 1, end);
right.fork();
return left.join() + right.join();
}
}
}
小结
1. parallelStream
是线程不安全的
2. parallelStream
适用的场景是
CPU
密集型的,只是做到别浪费
CPU
,假如本身电脑
CPU
的负载很大,那还到处用并行流,那并不能起到作用
3. I/O
密集型 磁盘
I/O
、网络
I/O
都属于
I/O
操作,这部分操作是较少消耗
CPU
资源,一般并行流中不适用于
I/O
密集型的操作,就比如使用并流行进行大批量的消息推送,涉及到了大量I/O
,使用并行流反而慢了很多
4.
在使用并行流的时候是无法保证元素的顺序的,也就是即使你用了同步集合也只能保证元素都正确但无法保证其中的顺序