常用Action算子
1、countByKey算子
功能:统计key出现的次数(一般适用于KV型的RDD)
用法:
result = rdd1.countByKey()
print(result)
代码示例:
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 通过SparkConf对象构建SparkContext
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
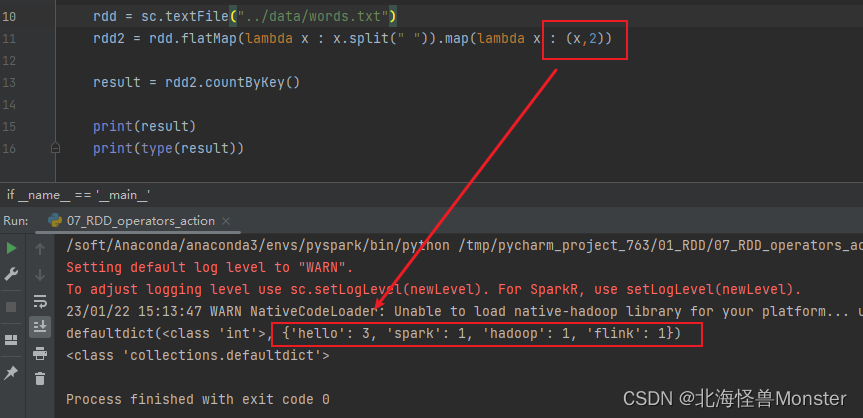
rdd = sc.textFile("../data/words.txt")
rdd2 = rdd.flatMap(lambda x : x.split(" ")).map(lambda x : (x,1))
result = rdd2.countByKey()
print(result)
print(type(result))
测试数据:
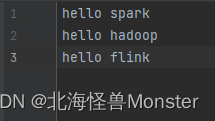
结果打印:

注意: action算子返回的结果的字典类型,和之前的转换算子时有区别的。
注意: countByKey只是统计key出现的次数,但是只是使用于KV型的RDD,所以上面使用元组,value值为1。但是不能误以为时value值相加。
例如下面示例:显然说明了只是统计key的出现次数
2、collect算子
功能:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象
用法:
rdd.collect()
这个算子,是将RDD各个分区数据都拉取到Driver中,注意的是:RDD是分布式对象,其数据量会很大,所以使用这个算子之前,必须知道,结果数据集不会太大。不然会把Driver内存撑爆。
3、reduce算子
功能:对RDD数据集按照你传入的逻辑进行聚合
语法:
rdd.reduce(func)
# func : (T,T) -> T
# 2个形参,一个返回值,三个参数的类型必须一致
代码示例:
rdd = sc.parallelize(range(1,10))
print(rdd.reduce(lambda a ,b : a + b ))
reduce执行流程分析:
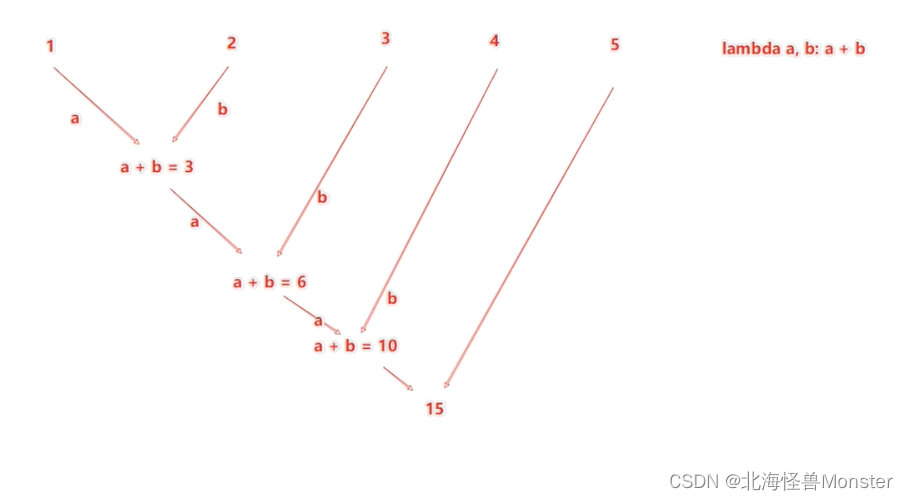
4、fold算子
功能:和reduce一样,接收传入逻辑进行聚合,但是聚合是带有初始值的
这个初始值聚合,会作用在
分区内聚合,分区间聚合
比如:[ [1,2,3] , [4,5,6] , [7,8,9] ]
数据分布在3个分区,分区内聚合:
分区1 1,2,3聚合的时候带上10作为初始值得到 16
分区2 4,5,6聚合的时候带上10作为初始值得到 25
分区3 7,8,9聚合的时候带上10作为初始值得到 34
分区间聚合:
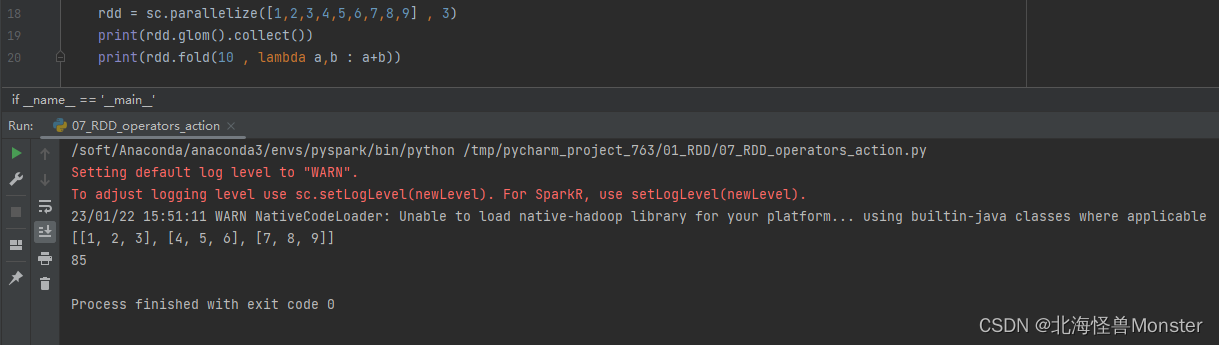
3个分区的结果做聚合也会带上初始值10,所以结果是 10+16+25+34 = 85
语法:
rdd.fold(初始值,func)
# func : (T,T) -> T
# 2个形参,一个返回值,三个参数的类型必须一致
代码示例:
5、first算子
功能:取出RDD的第一个元素,返回值根据存储的数据而定
语法:
rdd.first()
6、take算子
功能:取RDD的前n个元素,组合成list返回,list里面的数据类型根据RDD存储的数据而定
语法:
rdd.take(n)
7、top算子
功能:对RDD的数据集进行降序排序,取前n个
大小的比较依据的是对象的compare方法进行比较,如果没有重写compare方法,对于数字来说,按照大小降序,对于字符串来说,按照ASCII码进行比较
语法:
rdd.top(n) # 表示降序之后取前n个
8、count算子
功能:计算RDD有多少条数据,返回值是一个数字
语法:
rdd.count()
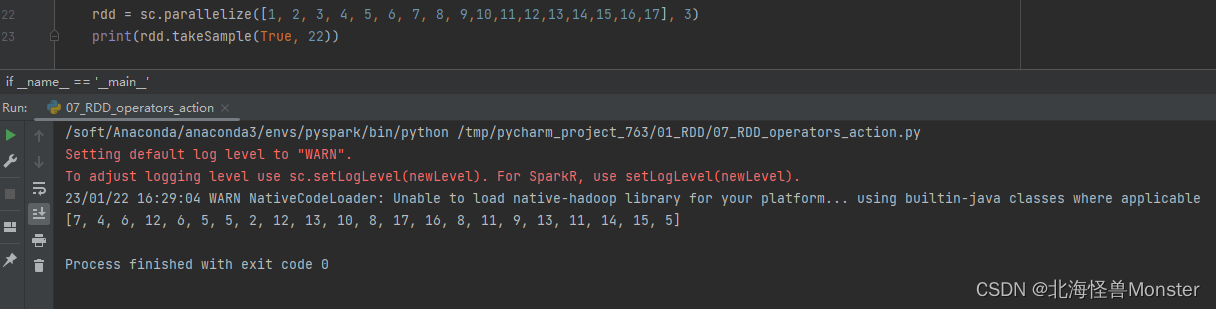
9、takeSample算子
功能:随机抽样RDD的数据
因为spark是用来做大数据计算的,当你想查看数据时,如果是有collect查看数据,有可能会把Driver内存撑爆。所以可以使用takeSample从
语法:
takeSample(参数1 : True or False , 参数2:采样数, 参数3:随机数种子)
参数1 : True表示运行取同一个数据,False表示不允许取同一个数据。和数据内容无关,是否重复表示的是 : 同一个位置的数据
参数2 : 抽样要几个
参数3 : 随机数种子,这个参数传入一个数据即可,随意给
随机数种子,数字可以随便传,如果传同一个数字,那么取出的结果是一致的
一般参数3,我们不传,spark会自动给与随机的种子。
其实这个种子代表步长,在计算机中其实没有严格意义上的随机数,大部分的时候,都是基于随机数种子来去决定随机数的产生。所以,如果随机数种子一样,那么取出来的结果也是一样的。
代码演示:
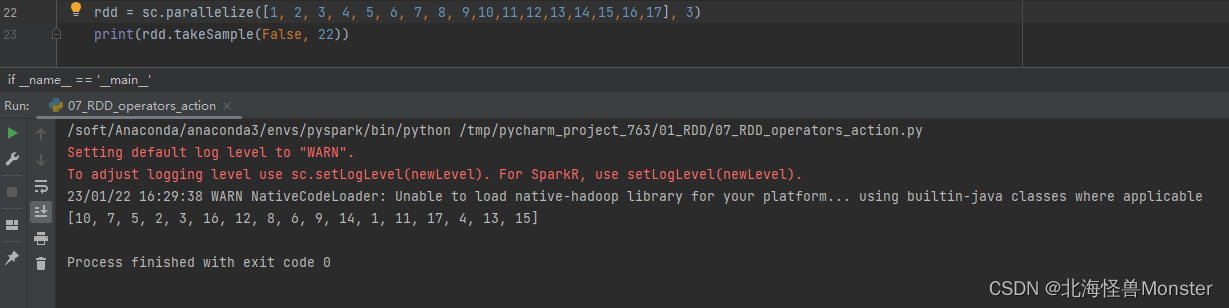
在测试的时候,给定种子,并且你取数量小于数据总量时,你每次运行结果都是一样的。
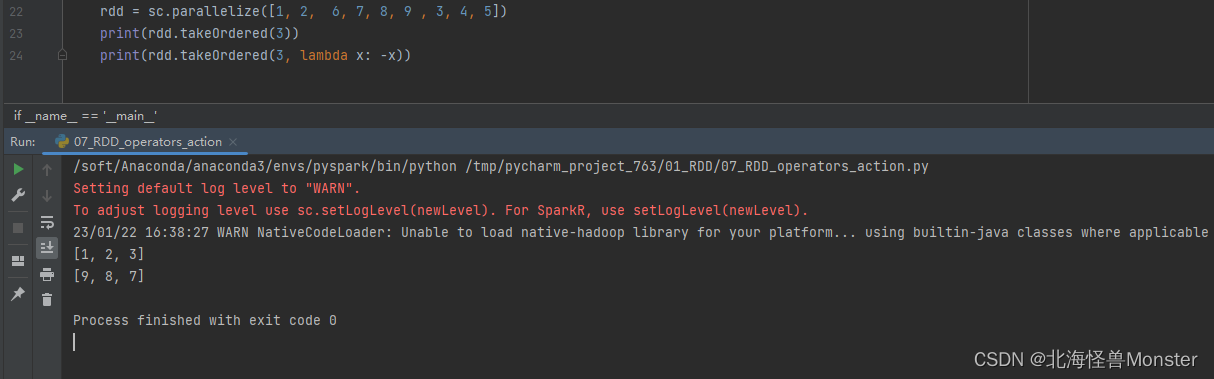
10、takeOrdered算子
功能:对RDD进行排序取前n个
语法:
rdd.takeOrdered(参数1,参数2)
参数1:要几个数据
参数2:对排序的数据进行更改(不会更改数据本身,只是在排序的时候换个样子),默认升序,可以指定降序,但是需要自定定义降序逻辑。
代码示例:
10、foreach算子
功能:对RDD的每一个元素,执行你提供的逻辑操作(和map一个意思),但是这个方法没有返回值
语法:
rdd.foreach(func)
# func : (T) -> None
代码示例:
我们可以看见,foreach是没有返回值的,你想要返回值就用map,不需要就使用foreach
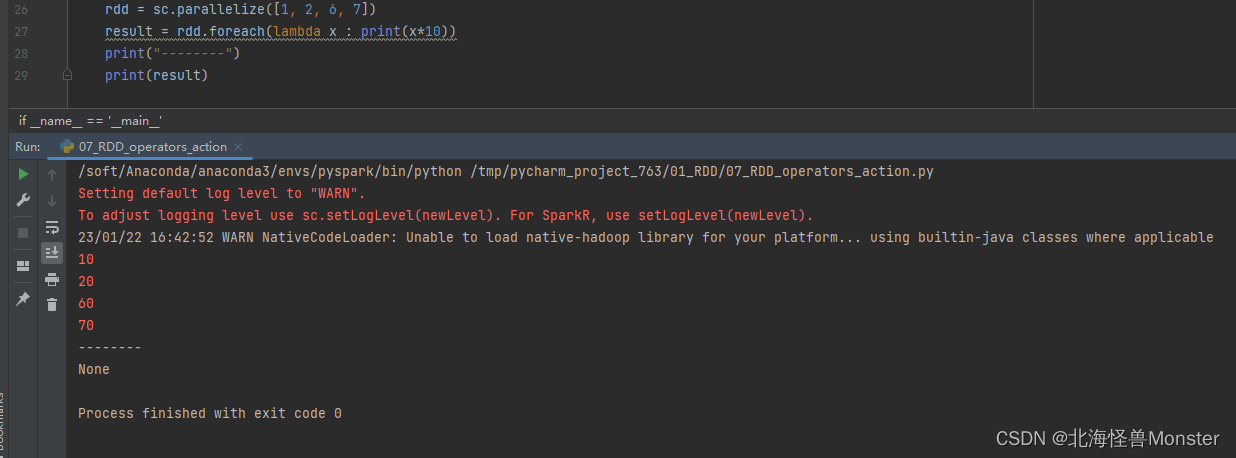
foreach的执行是由Executor直接输出的!!!
和collect有区别的,collect会将数据从Executor收集到Driver中,再由Driver输出。
所以再某些程度上。效率会高一点(比如打印操作,或者一些插入数据操作)
11、saveAsTextFile算子
功能:将RDD的数据写入文本文件中
支持本地写出,hdfs等文件系统
语法:
rdd.saveAsTextFile("hdfs://node1:8020/output/test")
代码示例:
执行之后你会发现,在你Pycharm中没有这个文件,因为你是将你的工程同步到Linux虚拟机中的,这个本地路径肯定就是你Linux的路径。在PyCharm中只会自动将工程的同步到Linux中,不会讲Linux同步到你自己开发项目中。所以需要你自己手动取拉取同步。

注意:!!!
你有几个分区,就有几个文件!!!
注意点:
saveAsTextFile会由Executor直接写文件,和forEach一样,由Executor输出,不经由Driver收集之后输出。
可以在一定程度上的 性能提高。
目前学习中:其余的Action算子都会讲结果发送至Driver。
分区操作算子
1、mapPartitions算子----属于转换算子
首先回忆一下map算子的功能,是将RDD的数据一条条处理。
如果分区1数据为 1,2
分区2数据为3,4
分区3数据为5,6
对这个rdd数据执行乘以10的操作,那么分区1的1,2分别乘以10,放入一个新的分区,会执行两次操作。同理分区3,4。那么总共会经历6次IO传输。
mapPartitions
功能:还是之前的数据,三个分区,6个数据,执行乘以10的操作。分区1的数据会整体进行处理,将1和2乘以10,放入新的分区中,只会有一次IO的处理。同理,分区2,3。
从结果看,map和mapPartitions效果是一样的,但是它两中间过程是不一样的。
语法:
rdd.mapPartitions( func )
# func : Iterable[T] -> Iterable[U]
传入的参数是一个迭代器对象,返回参数也是一个迭代器对象,数据类型没有要求。
代码示例:
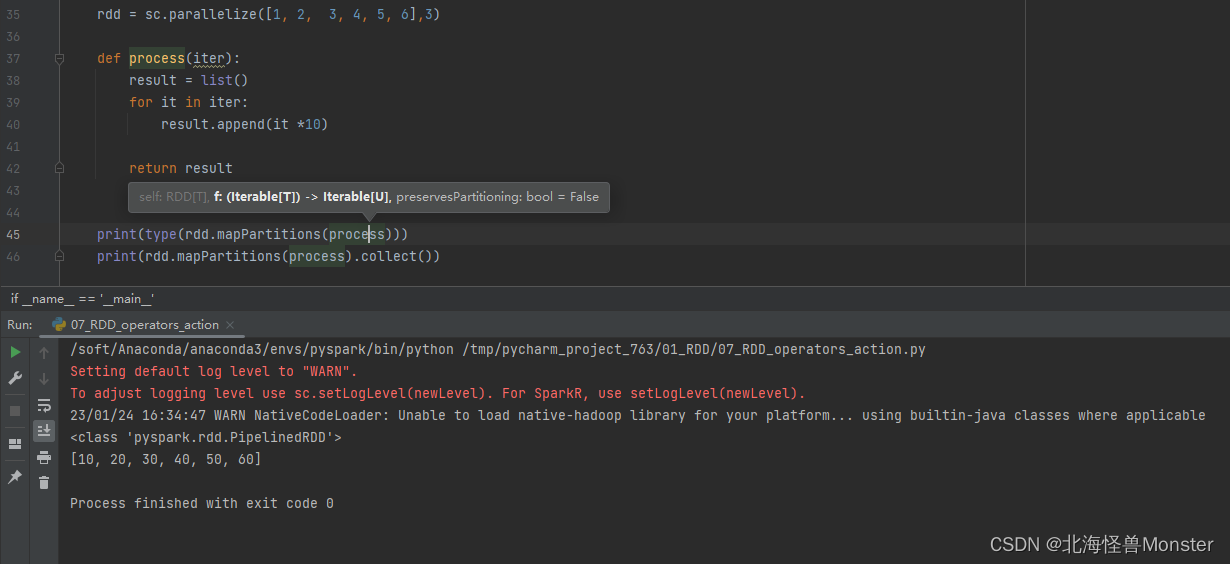
从以上代码看,map和mapPartitions这两个算子,在CPU层面没有区别,但是在网络IO层面看,mapPartitions效率更高。
2、foreachPartition算子----属于Action算子
功能:和普通foreach一致,但是,foreachPartition是一次处理一个分区的数据,foreach是一条一条处理数据。
两者都属于Action算子,没有返回值。
代码示例:
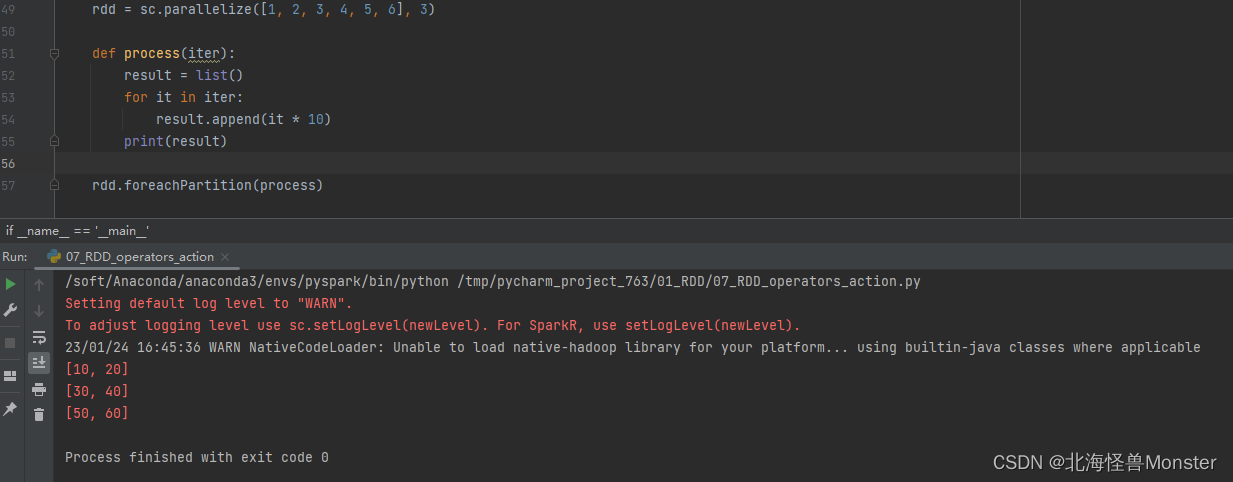
总结:foreachPartition 和 mapPartitions 就是对foreach,map的加强版。前者一个分区只走一次IO,后者会走多次IO。
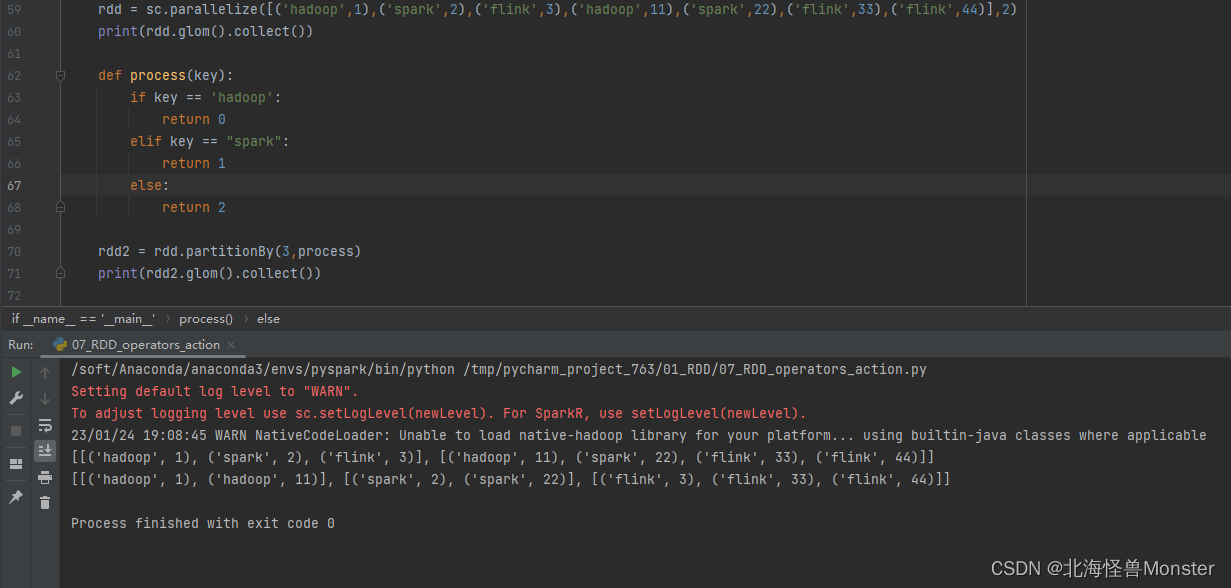
3、partitionBy算子---- 转换算子
功能:对RDD进行自定义分区操作
语法:
rdd.partitionBy(参数1,参数2)
# 参数1: 重新分区后有几个分区
# 参数2: 自定义分区规则,函数传入
# 参数2:(k)-> int
一个传入参数进来,类型无所谓,但是返回值一定是int类型,将key传给这个函数,你自己写逻辑,
决定返回一个分区编号
分区编号从0开始,不要超出分区数
代码示例:
当前指定分区数为2,数据按照顺序进行了分区
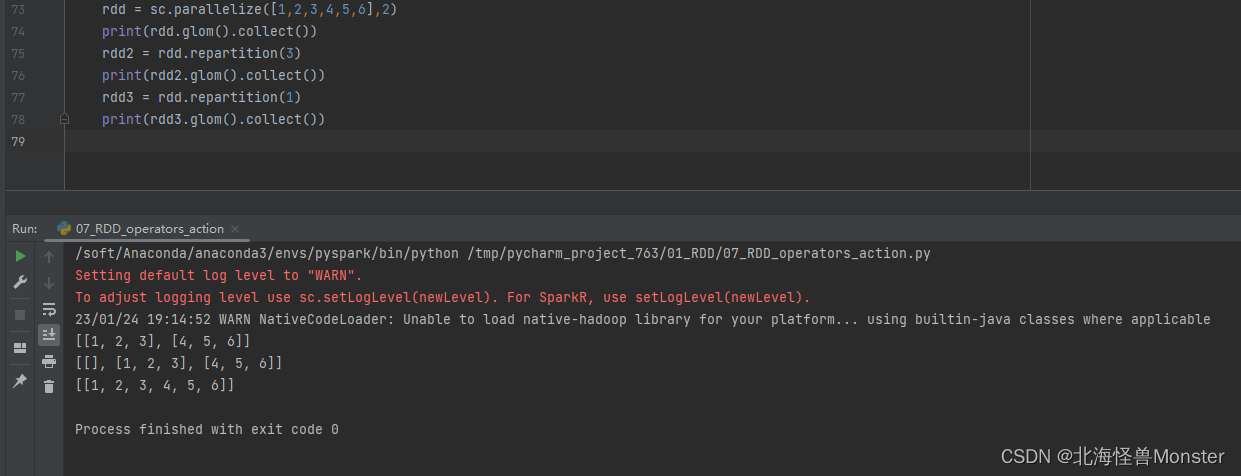
4、repartition算子---- 转换算子
功能:对RDD的分区数进行修改,仅仅修改分区数。
语法:
rdd.repartition(N)
注意:对分区的数量进行操作,一定要慎重
一般情况下,我们写spark代码,除了要求全局排序设置1个分区外,多数时候,所有API中关于分区相关的代码我们都不太理会。
因为,如果你修改了分区,会影响并行计算(内存迭代的并行管道数量),分区增加,极大可能导致shuffle
代码示例:
coalesce算子:
这个算子和repartition功能一样,增减分区的。
# 如果rdd分区数为3
rdd2 = rdd.coalesce(1) # 将分区数设置为1
rdd3 = rdd.coalesce(5,shuffle=True) # 将分区数设置为5
coalesce在增加分区的时候,shuffle=True,这个参数必须带上。就是为了告诉开发人员,增加分区会导致shuffle,为了避免误增加分区。
repartition算子底层就是coalesce,默认shuffle=True