推荐看看这个视频,将两种引擎实现的索引原理说的比较清楚
4-2 索引概述
本文转载:想飞的盗版鱼的博客
mysql5.5之后都是用idb了
补充一个主键和索引的关系:Are You OK?主键就是聚集索引吗?
索引类型
索引根据底层实现可分为B-Tree索引和哈希索引,大部分时候我们使用的都是B-Tree索引,因为它良好的性能和特性更适合于构建高并发系统。
根据索引的存储方式来划分,索引可以分为聚簇索引和非聚簇索引。聚簇索引的特点是叶子节点包含了完整的记录行,而非聚簇索引的叶子节点只有所以字段和主键ID。
根据聚簇索引和非聚簇索引还能继续下分还能分为普通索引、覆盖索引、唯一索引以及联合索引等。



总结
主键一定是聚簇索引,MySQL的InnoDB中一定有主键,即便研发人员不手动设置,则会使用unique索引,没有unique索引,则会使用数据库内部的一个行的id来当作主键索引,其它普通索引需要区分SQL场景,当SQL查询的列就是索引本身时,我们称这种场景下该普通索引也可以叫做聚簇索引,MyisAM引擎没有聚簇索引。
叶子结点是个双向链表,普通的b+树结构下面是单链表女朋友问我:为什么 MySQL 喜欢 B+ 树?我笑着画了 20 张图 (qq.com)
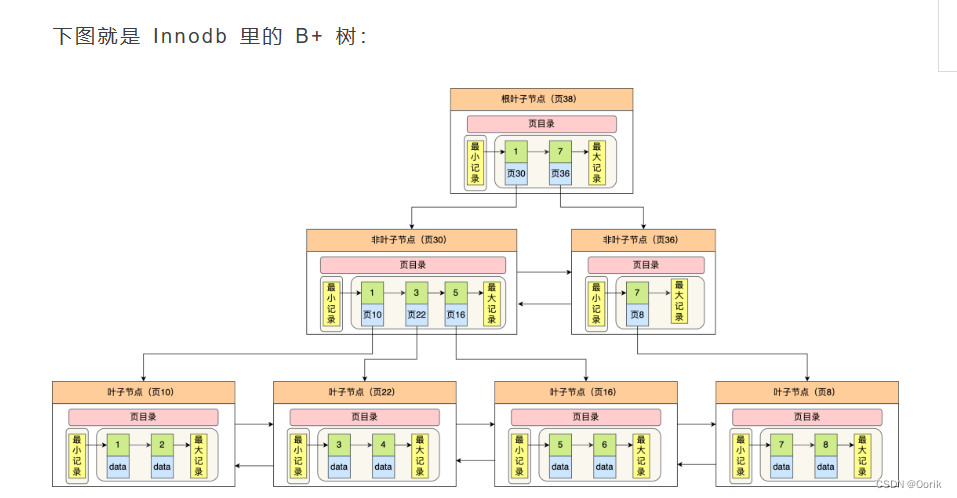
InnoDB和MyISAM的特点及区别:
InnoDB:
支持事务操作(并且实现了SQL标准的四种隔离级别)
支持行级锁(查询速度快)和表级索
不支持全文索引(没有保存表的行数)
是聚簇索引(因为索引文件和数据哎同一个文件下)
是数据库默认的存储引擎
MyISAM:
不支持事务
不支持行级锁和外键
若表建立时指定存储引擎是MyISAM,则生成表时会生成3个文件:
.frm文件存储表定义
.MYI文件存储索引文件
.MYD文件存储数据表中的数据
是非聚簇索引(因为索引文件和数据表中的数据是分开的)
区别:
MyISAM是非事务的,InnoDB是事务安全的
MyISAM是表级的,InnoBD是行级的
MyISAM支持全文索引,InnoBD不支持全文索引
MyISAM相对简单,效率优于InnoDB (小型应用可以考虑使用MyISAM)
MyISAM表保存成文件形式,跨平台使用更加方便
以上为比较普通的区别,下面这几个是面试官比较相同的区别:
1) count运算上的区别: 因为MyISAM缓存有表meta-data(行数等),因此在做COUNT(*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于InnoDB来说,则没有这种缓存。
2) 是否支持事务和崩溃后的安全恢复: MyISAM 强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。但是InnoDB 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
3)是否支持外键: MyISAM不支持,而InnoDB支持。
总结:
MyISAM更适合读密集的表,而InnoDB更适合写密集的的表。 在数据库做主从分离的情况下,经常选择MyISAM作为主库的存储引擎。
一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB是不错的选择。如果你的数据量很大(MyISAM支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM是最好的选择。
MyISAM的索引实现:
MyISAM引擎使用B+Tree作为索引结构,叶子节点的data域存放的是数据记录的地址。
可以看出,MyISAM的索引文件仅仅保存数据记录的地址。
在MyIASM中,主索引和辅助索引在结构上没有任何区别,只要主索引要求key是唯一的,而辅助索引的key可以重复。
因此,MyISAM中索引检索算法为首先按照B+Tree搜索算法搜索索引,若指定的key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
==>MyISAM的索引方式也叫“非聚集的”
InnoDB的索引实现:
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别:
InnoDB的数据本身就是索引文件。
MyISAM索引文件和数据文件是分离的,索引文件仅仅保存数据记录的地址
而InnoDB:表数据本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录,这个索引的key是数据表的主键。所以,InnoDB表数据文件本身就是主索引。
叶子结点包含了完整的数据记录,这种索引叫做聚集索引。因为InnoDB的数据本身要按主键聚集。所以,InnoDB要求表必须有主键(MyISAM可以没有),若没有显示指定,则会自动选择一个可以唯一标识数据记录的列作为主键,若不存再这种列,则会生成一个隐含字段作为主键。(使用自增字段作为主键时一个很好的选择)
第二个不同:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。也就是说,InnoDB的所有辅助索引都引用主键作为data域。
下图为辅助索引:
聚簇索引这种实现方式使得按主键的搜索十分高效。
但是辅助索引搜索需要检查两遍索引:首先检查辅助索引获得主键,然后根据主键到主索引中检索获得的记录。这也就是为什么:为什么不建议使用过长的字段作为主键。因为,所有辅助索引变得过大。
这里涉及到一道面试题:
InnoDB索引种类:
主键索引称为聚集索引
非主键索引称为非聚集索引或者辅助索引
辅助索引:一个非主键索引对应一个辅助索引,一个表可以有多个辅助索引,辅助索引域聚集索引的区别在于叶节点。
辅助索引的叶节点数据页存的不是真实记录,而是对于记录的主键。这种辅助索引名称的由来,通过这个索引,仅仅能查到某些记录的主键,这些主键去查主键索引,得到相应的记录。