深度学习网络—YOLO
yolov1(仅适用一个卷积神经网络端到端地实现检测物体的目的)
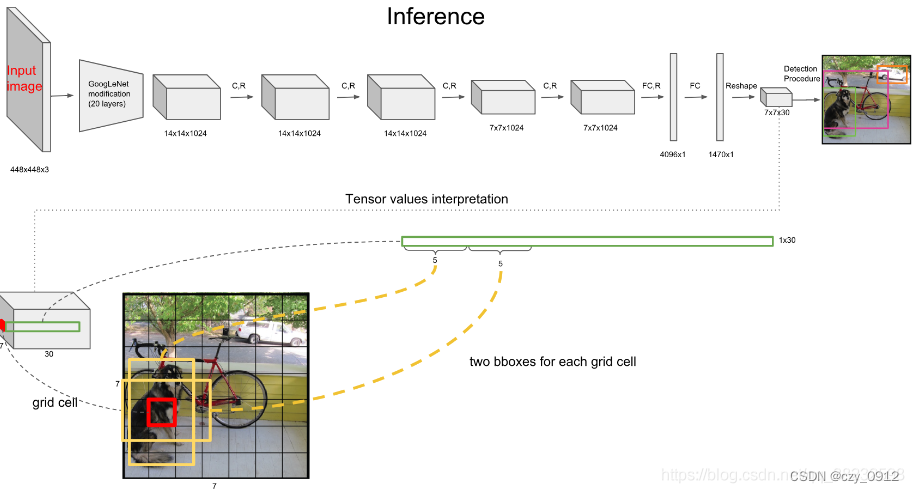
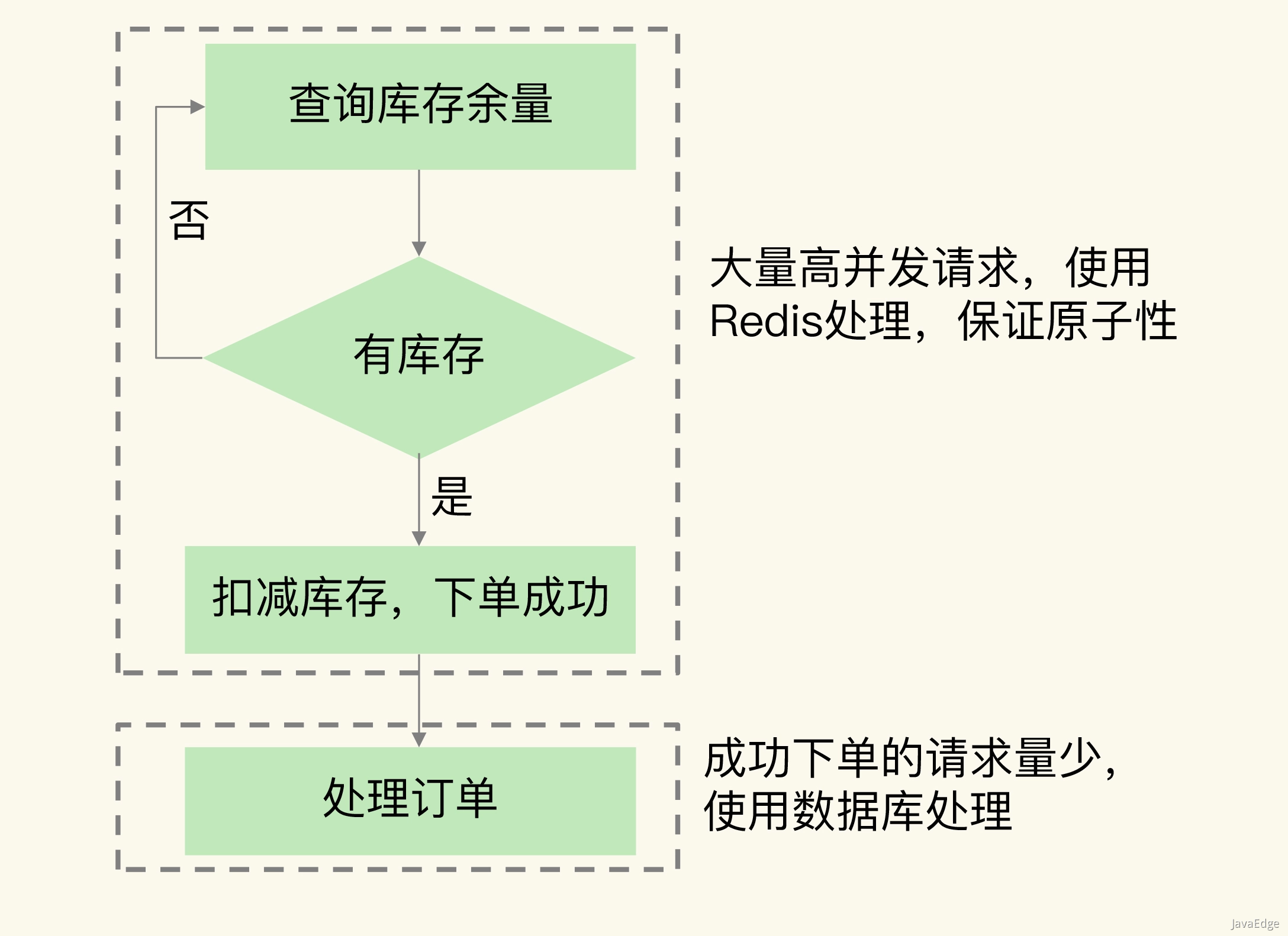
首先将输入图片resize到448448,然后送入CNN网络,最后处理预测的结果得到检测的目标;yolov1的具体思想是将全图划分为SS的格子,每个格子负责对落入其中的目标进行检测,一次性预测所有格子所含目标的边界框,置信度,以及所有类别的概率向量。
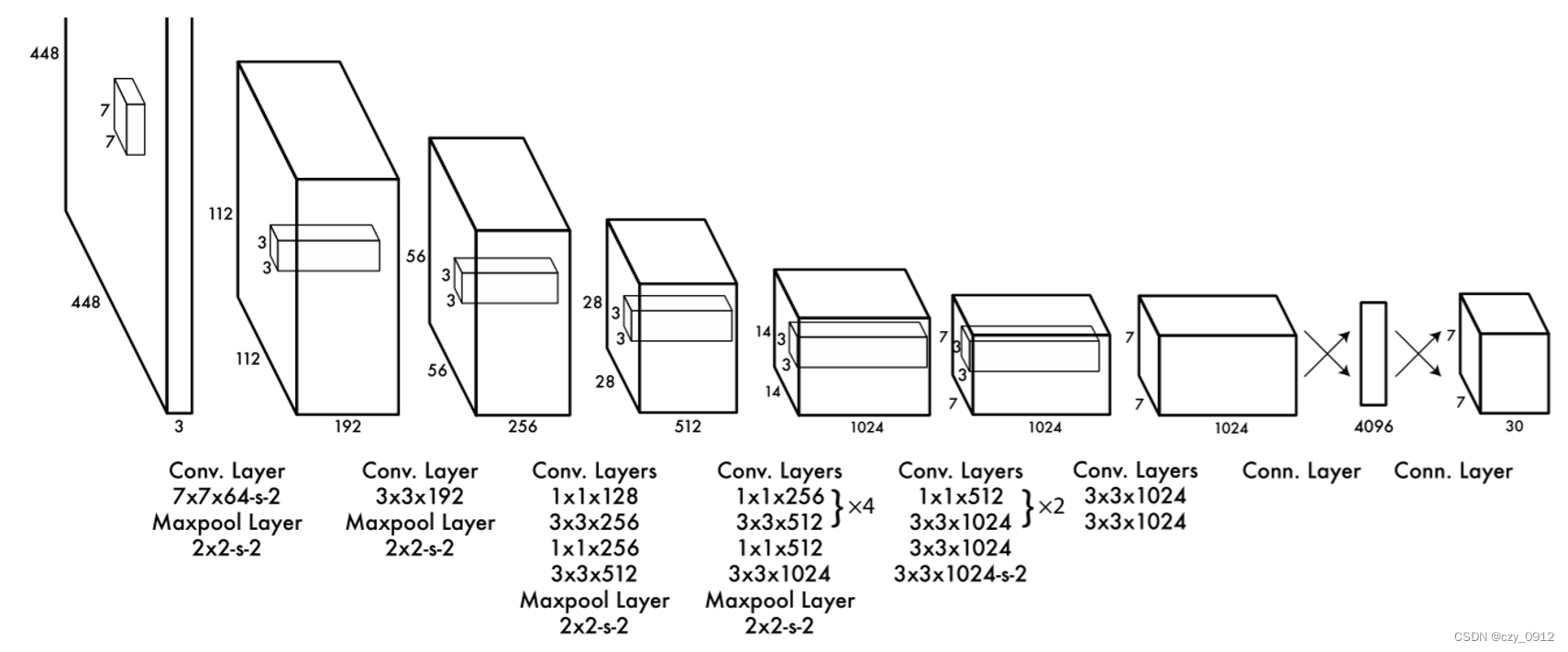
YOLO输入图像的尺寸为448448,经过24个卷积层(从图像中提取特征),2个全连接层(预测分类概率和bbox坐标),最后在reshape操作,输出的特征图大小为7730,这个30的信息中包含了坐标,置信度以及分类概率这三大信息,25+20中的2表示预测框的个数,20表示类别总数,5表示(x,y,w,h,confidence)信息。
yolov1的backbone网络是仿照GoogleNet搭建的,但并没有采用Inception模块,而是使用11和33卷积层来堆砌的,所以网络的结构是非常简单的,yolov1一共有三部分输出
yolov1损失函数计算如下:

坐标误差:预测的bbox与groundtruth框的中心点平方误差,以及相对于整幅图片的宽高平方误差
置信度误差:对于每一个gridcell的每一个bbox都有一个confidence score,如果包含物体,那么置信度就接近于1,如果不包含物体,那么置信度就接近0
分类误差:每个gridcell负责预测一个物体,获取得到分类结果与groundtruth的真实结果进行比较。