1、背景
有一个hdfs高可用集群,因为某些操作,导致其中一个namenode的信息全部丢失了。最后只剩下一个完整的namenode信息和datanode信息。于是在在启动hdfs后发现独有的namenode始终处于standby状态。即使通过hdfs haadmin -transitionToActive命令也不能强制转换namenode为active。因此hdfs一直不能正常对外提供服务。
上篇文章(HDFS高可用单NameNode从standby恢复为active(一)_Interest1_wyt的博客-CSDN博客)讲解了通过新增namenode节点的方式解决高可用hdfs集群namenode为standy的问题。新增节点解决方式虽然很好。但是需要准备一个新节点,紧急情况下可能不能很快拿到可用的节点,而且新节点还要安装好基础的环境信息。另外如果该hdfs已经废弃,当前只是紧急访问下hdfs某个文件,那么新增一个节点其实有点浪费资源。基于场景需要,所以就想能不能将集群从高可用状态降为单namenode状态继续使用。
2、解决思路
hdfs ha主要基于zkfc实现,zkfc主要有两个功能:
1)namenode的节点切换。
2)编辑日志和镜像文件的定期整合。
如果从ha降为单节点。那么zkfc肯定不能继续使用,其特有的两个功能也不再继续生效,namenode节点切换在单节点时不需要,但是编辑日志和镜像文件整合还是需要的。这个功能可以通过secondaryNameNode实现(secondaryNameNode也不是必须的,即只启动namenode和datanode也可以)。
3、解决步骤
整个方案是基于我的虚拟机进行验证,总共有三台虚拟机,分别是node1、node2、node3,其中node1和node3是原先namenode的安装点。后面准备只启动node1作为namenode节点,并且在node2上启动secondaryNameNode进程。
3.1)停止所有hdfs进程
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop zkfc
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop journalnode
3.2)修改core-site.xml配置文件并分发到所有节点
指定hdfs地址为确切的节点
<property>
<!-- hdfs 地址,ha中是连接到nameservice -->
<name>fs.defaultFS</name>
<!-- <value>hdfs://ns1</value> -->
<value>hdfs://node1:9000</value>
</property>
<property>
3.3)修改hdfs-site.xml配置文件并分发到所有节点
删除或注释所有ha相关的配置
<configuration>
<!-- 指定secondaryNameNode节点 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:50090</value>
</property>
<!-- 为namenode集群定义一个services name -->
<!-- <property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property> -->
<!-- nameservice 包含哪些namenode,为各个namenode起名 -->
<!-- <property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property> -->
<!-- 名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯 -->
<!-- <property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>node1:8020</value>
</property> -->
<!-- 名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯 -->
<!-- <property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>node3:8020</value>
</property> -->
<!--名为nn1的namenode 的http地址和端口号,web客户端 -->
<!-- <property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>node1:50070</value>
</property> -->
<!--名为nn2的namenode 的http地址和端口号,web客户端 -->
<!-- <property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>node3:50070</value>
</property> -->
<!-- namenode间用于共享编辑日志的journal节点列表 -->
<!-- <property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/ns1</value>
</property> -->
<!-- journalnode 上用于存放edits日志的目录 -->
<!-- <property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-2.10.1/data/tmp/dfs/jn</value>
</property> -->
<!-- 客户端连接可用状态的NameNode所用的代理类 -->
<!-- <property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> -->
<!-- sshfence:防止namenode脑裂,当脑裂时,会自动通过ssh到old-active将其杀掉,将standby切换为active -->
<!-- <property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> -->
<!--ssh密钥文件路径-->
<!-- <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property> -->
<!-- 故障转移 -->
<!-- <property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> -->
</configuration>3.4)删除zookeeper上的高可用记录节点
zkCli.sh 进入zk客户端
ls / 查看根目录下是否有hadoop-ha目录
deleteall /hadoop-ha 删除高可用记录
3.5)启动hadoop集群
hadoop-daemon.sh start namenode
hadoop-daemon.sh start secondarynamenode (非必须)
hadoop-daemon.sh start datanode
3.6)访问hdfs web接口 namenodeIp:50070
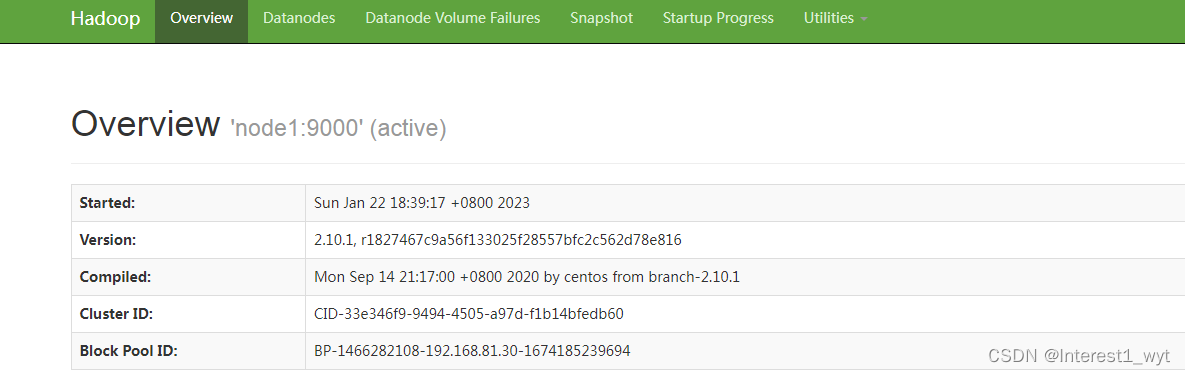
4、总结
最后访问hdfs web页面,可以看到hdfs集群正常工作,读写也正常。所以将高可用的hdfs降为单节点namenode的集群方案是可行的。即如果两个namenode有一个不能用了,紧急情况下也可以通过修改配置的方式将hdfs降低为单namenode的集群继续进行工作。
secondaryNameNode的功能是整合namenode的元信息,如果集群只是临时用一下,可以不用开启该进程,但是如果集群需要长时间以单namenode的情况进行运行,最好还是开始secondaryNameNode进程。





![[LeetCode周赛复盘] 第 96 场双周赛20230121](https://img-blog.csdnimg.cn/d972e2545ba9422182701f0a68f6a01c.png)