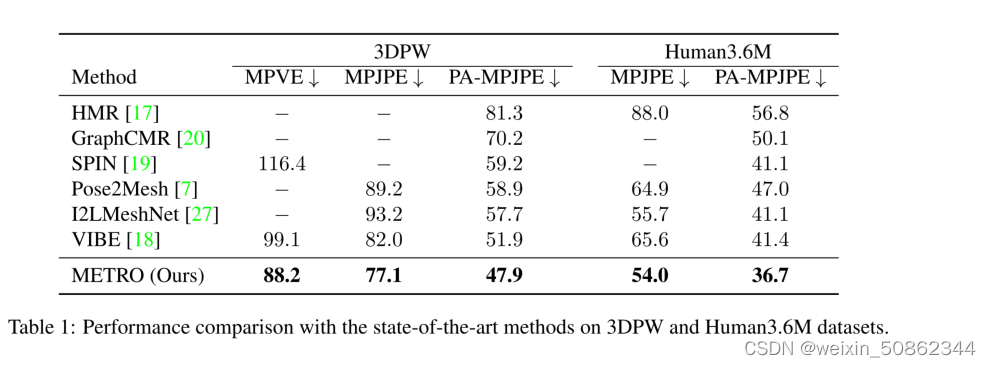
介绍了一些棘手的数学魔法,但我一直没有抽出时间说出妙语。目标是计算

同时正确处理溢出。我们的秘密武器是 EVM 的mulmod指令。这条指令完全符合我们的要求,只是它返回的是余数而不是商。那么我们的策略是什么?
- 计算 512 位乘积一种⋅b使用
mulmod. - 通过使用 减去余数使除法精确
mulmod。 - 从分数中去除二的幂以使分母可逆模组2个256.
- 计算分母的模逆。
- 乘以分子和反分母模组2个256.
每个步骤的实现我这里就不解释了,具体可以参考之前的帖子:
- 中国剩余定理
- 全乘法
- 512位除法(包括一些简单的技巧)
- 乘法逆元
实施和优化的策略如下:
contract MulDiv {
function muldiv(uint256 a, uint256 b, uint256 denominator)
internal pure returns (uint256 result)
{
// Handle division by zero
require(denominator > 0);
// 512-bit multiply [prod1 prod0] = a * b
// Compute the product mod 2**256 and mod 2**256 - 1
// then use the Chinese Remainder Theorem to reconstruct
// the 512 bit result. The result is stored in two 256
// variables such that product = prod1 * 2**256 + prod0
uint256 prod0; // Least significant 256 bits of the product
uint256 prod1; // Most significant 256 bits of the product
assembly {
let mm := mulmod(a, b, not(0))
prod0 := mul(a, b)
prod1 := sub(sub(mm, prod0), lt(mm, prod0))
}
// Short circuit 256 by 256 division
// This saves gas when a * b is small, at the cost of making the
// large case a bit more expensive. Depending on your use case you
// may want to remove this short circuit and always go through the
// 512 bit path.
if (prod1 == 0) {
assembly {
result := div(prod0, denominator)
}
return result;
}
///
// 512 by 256 division.
///
// Handle overflow, the result must be < 2**256
require(prod1 < denominator);
// Make division exact by subtracting the remainder from [prod1 prod0]
// Compute remainder using mulmod
// Note mulmod(_, _, 0) == 0
uint256 remainder;
assembly {
remainder := mulmod(a, b, denominator)
}
// Subtract 256 bit number from 512 bit number
assembly {
prod1 := sub(prod1, gt(remainder, prod0))
prod0 := sub(prod0, remainder)
}
// Factor powers of two out of denominator
// Compute largest power of two divisor of denominator.
// Always >= 1 unless denominator is zero, then twos is zero.
uint256 twos = -denominator & denominator;
// Divide denominator by power of two
assembly {
denominator := div(denominator, twos)
}
// Divide [prod1 prod0] by the factors of two
assembly {
prod0 := div(prod0, twos)
}
// Shift in bits from prod1 into prod0. For this we need
// to flip `twos` such that it is 2**256 / twos.
// If twos is zero, then it becomes one
assembly {
twos := add(div(sub(0, twos), twos), 1)
}
prod0 |= prod1 * twos;
// Invert denominator mod 2**256
// Now that denominator is an odd number, it has an inverse
// modulo 2**256 such that denominator * inv = 1 mod 2**256.
// Compute the inverse by starting with a seed that is correct
// correct for four bits. That is, denominator * inv = 1 mod 2**4
// If denominator is zero the inverse starts with 2
uint256 inv = 3 * denominator ^ 2;
// Now use Newton-Raphson itteration to improve the precision.
// Thanks to Hensel's lifting lemma, this also works in modular
// arithmetic, doubling the correct bits in each step.
inv *= 2 - denominator * inv; // inverse mod 2**8
inv *= 2 - denominator * inv; // inverse mod 2**16
inv *= 2 - denominator * inv; // inverse mod 2**32
inv *= 2 - denominator * inv; // inverse mod 2**64
inv *= 2 - denominator * inv; // inverse mod 2**128
inv *= 2 - denominator * inv; // inverse mod 2**256
// If denominator is zero, inv is now 128
// Because the division is now exact we can divide by multiplying
// with the modular inverse of denominator. This will give us the
// correct result modulo 2**256. Since the precoditions guarantee
// that the outcome is less than 2**256, this is the final result.
// We don't need to compute the high bits of the result and prod1
// is no longer required.
result = prod0 * inv;
return result;
}
}
这个例程包含在 Uniswap V3FullMath.sol中,它可以在每笔交易中节省 gas。它也可以在OpenZeppelin和其他各种项目中找到。
上述的一个早期变体被简要地考虑包含在0x 协议 v2中。米哈伊尔·弗拉基米罗夫独立地将各个部分拼凑起来并提出了相同的策略。