PHP源码
分享151个PHP源码,总有一款适合您
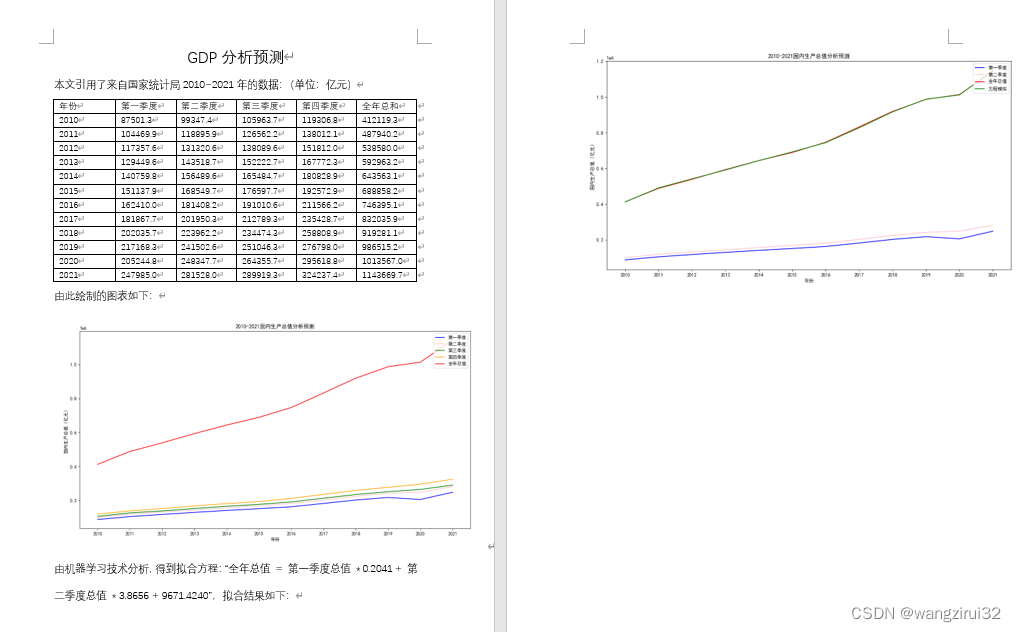
下面是文件的名字,我放了一些图片,文章里不是所有的图主要是放不下...,
151个PHP源码下载链接:https://pan.baidu.com/s/1T_Hs4j0t39b-Y8UWHmAKyw?pwd=7ao0
提取码:7ao0
Python采集代码下载链接:采集代码.zip - 蓝奏云
class HuaJunCode:
base_url = "https://down.chinaz.com" # 采集的网址
save_path = "D:\\Freedom\\Sprider\\ChinaZ\\"
sprider_count = 151 # 采集数量
sprider_start_count=7208 #正在采集第491页的第12个资源,共499页资源 debug
word_content_list = []
folder_name = ""
page_end_number=0
max_pager=15 #每页的数量
haved_sprider_count =0 # 已经采集的数量
page_count = 1 # 每个栏目开始业务content="text/html; charset=gb2312"
filter_down_file=[]

MySQL数据库用户在线注册系统 v1.0
夜猫下载 v1.0.1 修改版
单工语音聊天室
iDownS(冰冰下载系统) v2.0 rc4
阿志下载程序
卧龙下载管理 v0.5 测试版(php文本存储格式)
侠客居软件下载系统测试版
玉环信息港留言本
旅行的风事画馆 测试版
shocker的赛马程序
简单美观文章管理
灵石岛站内搜索程序
在线文件管理程序
删除ftp无法删除文件程序
SkyLogCount 贝塔简体汉化版
华育论坛 v4.0 beta7.5 安装版
W8C WebFTP v1.0
XYListmail(星原邮件列表程序) 文本型多用户 v4.0
phpMyChat v0.14.5
import os
# 查找指定文件夹下所有相同名称的文件
def search_file(dirPath, fileName):
dirs = os.listdir(dirPath) # 查找该层文件夹下所有的文件及文件夹,返回列表
for currentFile in dirs: # 遍历列表
absPath = dirPath + '/' + currentFile
if os.path.isdir(absPath): # 如果是目录则递归,继续查找该目录下的文件
search_file(absPath, fileName)
elif currentFile == fileName:
print(absPath) # 文件存在,则打印该文件的绝对路径
os.remove(absPath)
VBB论坛Xpsky V6风格
枫 文章管理程序
星原邮件列表程序 v3.2
skyboard v2.0 beta 中文版
Bluemagic(BMB) v1.1 超级论坛
IP地址归属地查询程序(PHP)
Blue Maigc Board 论坛v1.3
php文本交换链
Discuz! v1.01 GB稳定版
Discuz! v1.01 BIG5稳定版
水云PHP探针 v1.0.9
Net Journalist Unlimited CMS v1.1
在线挖地雷游戏
imgeasy图片管理程序
Blue Magic Board v1.1
星原邮件列表程序 v3.0
4images 完美简体中文思诺工作室版
顶级域名在线查询
WDB论坛の南宫紫剑修改版wdb_qbit_1001
XYListmail(星原邮件列表程序) 文本型多用户 v2.0
险情文章管理 v1.08 正式版本-NECY修改版
馒头留言簿
思诺在线影视交易系统 v3.0 免费版
时代论坛社区v3.0.5--2002-2003免费版
vv66.com商业音乐程序
apple风格php 文本留言本
CDB v3.0 RC1 GB 标准版
CDB v3.0 RC1 (繁体版)
我的PHP探针(MyPHP) v1.1

dream club v0240(WDB修改版)
Myup v1.1 WEB自上传系统单用户版
TURBO LINK1_18传销式文本广告交换
ReleaeEasy Home Edition(PHP文本站点管理)
4image v1.7汉化 vbulletin整合程序
险情文章管理 v1.80
半条命服务器排行程序HLstats v1.02 汉化版 简明安装教程
我的PHP探针 v1.0 正式版(简)
我的PHP探针 v1.0 正式版(繁)
1:24文本广告交换系统
IMG EASY 国庆版
FLASH 文本聊天室完美中文版
水柠檬IBF XBOX(白色风格)
ADN 论坛 v3.2
4images v1.7 完美简体中文版
MercuryBoard v3.0 Beta
优秀同学录程序CLAROLINEClassroom online 030
虚拟主机 PHP 管理程序web://cp v0.5
WebZone Redirector v1.03b(虚拟主机域名转向程序)
冰冰春节大礼包之留言本
冰冰图片通用管理系统(iZzIMG System) v0.1.0 专业版
北京龙珠江湖 v1.0(免费版)
JChat v3.6.3
schocker文章管理
紫桐超级留言本
shocker字符界面留言本
WDB v0825 繁体版
id设计留言板 v0518
街舞的link系统
仿雷傲文本统计系统(yucount)v1.0
IBF v1.5 最终版
龙龙下载系统 v4.0
贴图论坛 edphpbbs
web管理器
思诺在线影视收费系统 v2.0 免费版
PhpGuest 2002.08.14
IBF v1.5 水柠檬汉化中文修改版
edgeboard v1.2 bata XBOX风格汉化版
edgeboard v1.2 bata FB风格升级汉化版
HTML SITE MANAGER
散人设计论坛和留言板
IP 查 询
Squito Gallery v1.3b
SGB(SuperGuestBook) v0908
星伴论坛个人版 v2.0(多数据库支持)
FB风格的EB文本论坛
4images v1.7.4
域名查询系统 Matt's 域名查询(可查询世界各地的域名)
域名查询
def sprider(self,title_name="NET"):
"""
采集
PHP https://down.chinaz.com/class/572_5_1.htm
NET https://down.chinaz.com/class/572_4_1.htm
ASP https://down.chinaz.com/class/572_3_1.htm
Python https://down.chinaz.com/class/604_572_1.htm
https://down.chinaz.com/class/608_572_1.htm
微信 https://down.chinaz.com/class/610_572_1.htm
Ruby https://down.chinaz.com/class/622_572_1.htm
NodeJs https://down.chinaz.com/class/626_572_1.htm
C https://down.chinaz.com/class/594_572_1.htm
:return:
"""
if title_name == "PHP":
self.folder_name = "PHP源码"
self.second_column_name = "572_5"
elif title_name == "Go":
self.folder_name = "Go源码"
self.second_column_name = "606_572"
elif title_name == "NET":
self.folder_name = "NET源码"
self.second_column_name = "572_4"
elif title_name == "ASP":
self.folder_name = "ASP源码"
self.second_column_name = "572_3"
elif title_name == "Python":
self.folder_name = "Python源码"
self.second_column_name = "604_572"
elif title_name == "JavaScript":
self.folder_name = "JavaScript源码"
self.second_column_name = "602_572"
elif title_name == "Java":
self.folder_name = "Java源码"
self.second_column_name = "572_517"
elif title_name == "HTML":
self.folder_name = "HTML-CSS源码"
self.second_column_name = "608_572"
elif title_name == "TypeScript":
self.folder_name = "TypeScript源码"
self.second_column_name = "772_572"
elif title_name == "微信小程序":
self.folder_name = "微信小程序源码"
self.second_column_name = "610_572"
elif title_name == "Ruby":
self.folder_name = "Ruby源码"
self.second_column_name = "622_572"
elif title_name == "NodeJs":
self.folder_name = "NodeJs源码"
self.second_column_name = "626_572"
elif title_name == "C++":
self.folder_name = "C++源码"
self.second_column_name = "596_572"
elif title_name == "C":
self.folder_name = "C源码"
self.second_column_name = "594_572"
#https://down.chinaz.com/class/594_572_1.htm
first_column_name = title_name # 一级目录
self.sprider_category = title_name # 一级目录
second_folder_name = str(self.sprider_count) + "个" + self.folder_name #二级目录
self.sprider_type =second_folder_name
self.merchant=int(self.sprider_start_count) //int(self.max_pager)+1 #起始页码用于效率采集
self.file_path = self.save_path + os.sep + "Code" + os.sep + first_column_name + os.sep + second_folder_name
self.save_path = self.save_path+ os.sep + "Code" + os.sep+first_column_name+os.sep + second_folder_name+ os.sep + self.folder_name
BaseFrame().debug("开始采集ChinaZCode"+self.folder_name+"...")
sprider_url = (self.base_url + "/class/{0}_1.htm".format(self.second_column_name))
down_path="D:\\Freedom\\Sprider\\ChinaZ\\Code\\"+first_column_name+"\\"+second_folder_name+"\\Temp\\"
if os.path.exists(down_path) is True:
shutil.rmtree(down_path)
if os.path.exists(down_path) is False:
os.makedirs(down_path)
if os.path.exists(self.save_path ) is True:
shutil.rmtree(self.save_path )
if os.path.exists(self.save_path ) is False:
os.makedirs(self.save_path )
chrome_options = webdriver.ChromeOptions()
diy_prefs ={'profile.default_content_settings.popups': 0,
'download.default_directory':'{0}'.format(down_path)}
# 添加路径到selenium配置中
chrome_options.add_experimental_option('prefs', diy_prefs)
chrome_options.add_argument('--headless') #隐藏浏览器
# 实例化chrome浏览器时,关联忽略证书错误
driver = webdriver.Chrome(options=chrome_options)
driver.set_window_size(1280, 800) # 分辨率 1280*800
# driver.get方法将定位在给定的URL的网页,get接受url可以是任何网址,此处以百度为例
driver.get(sprider_url)
# content = driver.page_source
# print(content)
div_elem = driver.find_element(By.CLASS_NAME, "main") # 列表页面 核心内容
element_list = div_elem.find_elements(By.CLASS_NAME, 'item')
laster_pager_ul = driver.find_element(By.CLASS_NAME, "el-pager")
laster_pager_li =laster_pager_ul.find_elements(By.CLASS_NAME, 'number')
laster_pager_url = laster_pager_li[len(laster_pager_li) - 1]
page_end_number = int(laster_pager_url.text)
self.page_count=self.merchant
while self.page_count <= int(page_end_number): # 翻完停止
try:
if self.page_count == 1:
self.sprider_detail(driver,element_list,self.page_count,page_end_number,down_path)
pass
else:
if self.haved_sprider_count == self.sprider_count:
BaseFrame().debug("采集到达数量采集停止...")
BaseFrame().debug("开始写文章...")
self.builder_word(self.folder_name, self.word_content_list)
BaseFrame().debug("文件编写完毕,请到对应的磁盘查看word文件和下载文件!")
break
#(self.base_url + "/sort/{0}/{1}/".format(url_index, self.page_count))
#http://soft.onlinedown.net/sort/177/2/
next_url = self.base_url + "/class/{0}_{1}.htm".format(self.second_column_name, self.page_count)
driver.get(next_url)
div_elem = driver.find_element(By.CLASS_NAME, "main") # 列表页面 核心内容
element_list = div_elem.find_elements(By.CLASS_NAME, 'item')
self.sprider_detail( driver, element_list, self.page_count, page_end_number, down_path)
pass
#print(self.page_count)
self.page_count = self.page_count + 1 # 页码增加1
except Exception as e:
print("sprider()执行过程出现错误:" + str(e))
sleep(1)
def sprider_detail(self, driver,element_list,page_count,max_page,down_path):
"""
采集明细页面
:param driver:
:param element_list:
:param page_count:
:param max_page:
:param down_path:
:return:
"""
index = 0
element_array=[]
element_length=len(element_list)
for element in element_list:
url_A_obj = element.find_element(By.CLASS_NAME, 'name-text')
next_url = url_A_obj.get_attribute("href")
coder_title = url_A_obj.get_attribute("title")
e=coder_title+"$"+ next_url
element_array.append(e)
pass
if int(self.page_count) == int(self.merchant):
self.sprider_start_index = int(self.sprider_start_count) % int(self.max_pager)
index=self.sprider_start_index
while index < element_length:
if os.path.exists(down_path) is False:
os.makedirs(down_path)
if self.haved_sprider_count == self.sprider_count:
BaseFrame().debug("采集到达数量采集停止...")
break
#element = element_list[index]
element=element_array[index]
time.sleep(1)
index = index + 1
sprider_info="正在采集第"+str(page_count)+"页的第"+str(index)+"个资源,共"+str(max_page)+"页资源"
BaseFrame().debug(sprider_info)
next_url=element.split("$")[1]
coder_title=element.split("$")[0]
# next_url = element.find_element(By.TAG_NAME, 'a').get_attribute("href")
# coder_title =element.find_element(By.TAG_NAME, 'img').get_attribute("title")
try:
codeEntity = SpriderEntity() # 下载过的资源不再下载
codeEntity.sprider_base_url = self.base_url
codeEntity.create_datetime = SpriderTools.get_current_datetime()
codeEntity.sprider_url = next_url
codeEntity.sprider_pic_title = coder_title
codeEntity.sprider_pic_index = str(index)
codeEntity.sprider_pager_index = page_count
codeEntity.sprider_type = self.sprider_type
if SpriderAccess().query_sprider_entity_by_urlandindex(next_url, str(index)) is None:
SpriderAccess().save_sprider(codeEntity)
else:
BaseFrame().debug(coder_title+next_url + "数据采集过因此跳过")
continue
driver.get(next_url) # 请求明细页面1
if SeleniumTools.judeg_element_isexist(driver, "CLASS_NAME", "download-item") == 3:
driver.back()
BaseFrame().debug(coder_title+"不存在源码是soft因此跳过哦....")
continue
print("准备点击下载按钮...")
driver.find_element(By.CLASS_NAME, "download-item").click() #下载源码
sleep(1)
result,message=SpriderTools.judge_file_exist(True,240,1,down_path,self.filter_down_file,"zip|rar|gz|tgz")#判断源码
if result is True:
sprider_content = [coder_title, self.save_path + os.sep +"image"+ os.sep + coder_title + ".jpg"] # 采集成功的记录
self.word_content_list.append(sprider_content) # 增加到最终的数组
self.haved_sprider_count = self.haved_sprider_count + 1
BaseFrame().debug("已经采集完成第" + str(self.haved_sprider_count) + "个")
time.sleep(1)
driver.back()
coder_title = str(coder_title).replace("::", "").replace("/", "").strip() #去掉windows不识别的字符
files = os.listdir(down_path)
file_name = files[0] # 获取默认值
srcFile = down_path + os.sep + file_name
file_ext = os.path.splitext(srcFile)[-1]
dstFile = down_path + os.sep + coder_title + file_ext
os.rename(srcFile, dstFile)
srcFile = dstFile
dstFile = self.save_path + os.sep + coder_title + file_ext
shutil.move(srcFile, dstFile) # 移动文件
else:
files = os.listdir(down_path) # 读取目录下所有文件
coder_title = str(coder_title).replace("/", "") # 去掉windows不识别的字符
try:
if str(message)=="0个文件认定是False":
BaseFrame().error(coder_title+"文件不存在...")
shutil.rmtree(down_path) # 如果没下载完是无法删除的
pass
else:
BaseFrame().error("检测下载文件出错可能原因是等待时间不够已经超时,再等待60秒...")
time.sleep(60)
shutil.rmtree(down_path) #如果没下载完是无法删除的
#清空数组
self.filter_down_file.clear()
except Exception as e:
# 使用数组append记录文件名字 移动的时候过滤
self.builder_filter_file(files)
pass
except Exception as e:
BaseFrame().error("sprider_detail()执行过程出现错误:" + str(e))
BaseFrame().error("sprider_detail()记录下载的文件名")
# 使用数组append记录文件名字 移动的时候过滤
files = os.listdir(down_path) # 读取目录下所有文件
self.builder_filter_file(files)
if(int(page_count)==int(max_page)):
self.builder_word(self.folder_name,self.word_content_list)
BaseFrame().debug("文件编写完毕,请到对应的磁盘查看word文件和下载文件!")
OekakiPoteto涂鸦板v4.32 中文版
WEBLOG(日记模式个人网站) v2.1
XEOBOOK 留言板
XEOBOOK 留言板汉化版
PHP文本分析统计
非常酷的多用户留言本
北方女孩图片管理
精英计数器
WEBDI 增强版(WDB=PKMM=美化版)
迷你php留言板v1.80.20000507
慕逸留言薄 v4.0(第四版)
MCclass 同学录
奥捷特网上办公自动化
IBF v1.4 星晴汉化中文版
OOPS留言本
吉鑫网络商店 v2.2 完美版
PHP的校友录程序 v1.01
PHP的FTP搜索程序
时代软件下载 2002 v2.01
时代友情链接 2001 v1.0
时代留言簿 2001 v2.0
冰雨盟下载系统 v0.1
Php Guest System(超级留言系统) v0814
多用户图片管理系统 v2.0
kpc卡通图片管理
flash xml投票程序
flash投票程序
phpMyBackup v1.0 汉化版
PHP文本聊天室
Y10K留言本(我的留言本) v1.0
phpbbmx v2.5.2 简体中文版
zChain留言簿2000多用户版 v2.12(仿YUZI留言簿)
SW下载系统 (PHP文本下载系统)
PHP自助友情链接系统
Develooping Flash Chat v1.2(Flash 聊天室)
一个新闻小偷
漫步精品程序 v1.0
ymDown(夜猫下载系统) v1.0.1
PHP的天气预报小偷
iDownS(冰冰下载系统) v2.0 rc 1(繁體)
蓝芒图书管理系统示范版
网络图书管理
phplinks v2.1.2 汉化版
Demon Board v1.0 WorldEast.NET 修正版
EV News v20020504
小露珠PHP MYSQL留言薄 v2.0(多用户版)
PhpGuest2002
往事随风MYSQL备份
实易数据库工具 v1.4
x-pad v1.0
MYWBB v2.0 完全汉化版
PHP留言簿
软件信息反馈系统 v1.0beta 2 v1.0 beta 2
8Forum v2.3.1 汉化版
def builder_filter_file(self,files):
"""
:param files:
:return:
"""
for file in files:
if len(self.filter_down_file)==0:
self.filter_down_file.append(str(file))
for filter_file in self.filter_down_file:
if str(file) in str(filter_file):
BaseFrame().error(filter_file + "文件存在...")
pass
else:
self.filter_down_file.append(str(file))
def builder_word(self, word_title, list_files):
"""
输出产物是word文件
:param word_title: 文件的标题
:param save_path: 文件的保存路径
:param list_files: 文件集合(单个内容)
:return:
"""
try:
self.copy_file(self.save_path)
print("Create Word:"+word_title)
file_count= len(list_files)
self.gen_passandtxt(file_count,word_title,list_files)
random_full_file_name = SpriderTools.get_word_image(self.sprider_category,6)
document = Document()
document.add_heading(""+word_title+"", level=2)
document.add_paragraph("分享"+str(file_count)+"个"+word_title+",总有一款适合您\r\n"
"下面是文件的名字,我放了一些图片,文章里不是所有的图主要是放不下...,")
document.add_paragraph(""+str(file_count)+"个"+word_title+"下载")
document.add_picture(random_full_file_name, width=Inches(3))
ppt_tieles = ""
for files in list_files:
ppt_tieles = ppt_tieles + str(files[0]) + "\r"
document.add_paragraph(ppt_tieles)
# for files in list_files:
# try:
# document.add_paragraph(files[0])
# document.add_picture(files[1], width=Inches(3))
# except Exception as e:
# pass
random_full_file_name1 = SpriderTools.get_word_image(self.sprider_category, 6)
document.add_picture(random_full_file_name1, width=Inches(3))
document.add_paragraph("最后送大家一首诗:")
paragraph = document.add_paragraph() # 单独控制
paragraph.add_run("山高路远坑深,\r")
paragraph.add_run("大军纵横驰奔,\r")
paragraph.add_run("谁敢横刀立马?\r")
paragraph.add_run("惟有点赞加关注大军。\r")
paragraph.bold = True # 字体加粗
file_full_path=self.file_path+os.sep+word_title+".docx"
document.save(file_full_path)
except Exception as e:
print("Create Word Fail reason:" + str(e))
def copy_file(self,target_path):
print("copy files")
import os
import shutil
src_apk_file_path="亚丁号自动阅读_v0.0.53.apk"
dst_apk_file_path=self.file_path+os.sep+"亚丁号自动阅读_v0.0.53.apk"
shutil.copyfile(src_apk_file_path, dst_apk_file_path) # 移动文件
src_pdf_file_path = "薅羊毛专业版.pdf"
dst_pdf_file_path = target_path + os.sep + "薅羊毛专业版.pdf"
#shutil.copyfile(src_pdf_file_path, dst_pdf_file_path) # 移动文件
src_pdf_file_path = "亚丁号.url"
dst_pdf_file_path = self.file_path + os.sep + "亚丁号.url"
shutil.copyfile(src_pdf_file_path, dst_pdf_file_path) # 移动文件
src_doc_file_path = "readme.docx"
dst_doc_file_path = self.file_path + os.sep + "readme.docx"
shutil.copyfile(src_doc_file_path, dst_doc_file_path) # 移动文件
pass
def gen_passandtxt(self,file_count,word_title, list_files):
print("Create PassWord and Pass.txt")
message=SpriderTools.gen_password()
password = "".join(message)
content=""
content = content + "\n分享"+str(file_count)+"个"+word_title+",总有一款适合您"
content = content + "\n\r"
content=content+"\n都到这里了您就支持一下呗!谢谢老铁~~"
content=content+"\n\r"
# content = content + "\n\r"
# content = content + "\n\r"
# for files in list_files:
# content = content+str(files[0])+ "\n"
content=content+"\n文件我就不一一列举了,送老铁一首打油诗"
content=content+"\n学习知识费力气,"
content=content+"\n收集整理更不易。"
content=content+"\n知识付费甚欢喜,"
content=content+"\n为咱码农谋福利。"
content=content+"\n\r"
content=content+"\n\r"
content=content+"\n感谢您的支持"
content=content+"\n\r"
content=content+"\n-------------------------------------------华丽分割线-------------------------------------------------------"
content=content+"\n友情提醒解压密码:"+password+""
full_path=self.file_path+os.sep+""+str(file_count)+"sell_pass.txt"
with open(full_path, 'a', encoding='utf-8') as f:
f.write(content)
链接:https://pan.baidu.com/s/1T_Hs4j0t39b-Y8UWHmAKyw?pwd=7ao0
提取码:7ao0
最后送大家一首诗:
山高路远坑深,
大军纵横驰奔,
谁敢横刀立马?
惟有点赞加关注大军。