笔记整理:柳鹏凯,天津大学硕士
发表期刊:计算机学报 第45卷Vol.45, 第9期 No.9
链接:http://cjc.ict.ac.cn/online/onlinepaper/lpk-202297212908.pdf
动机
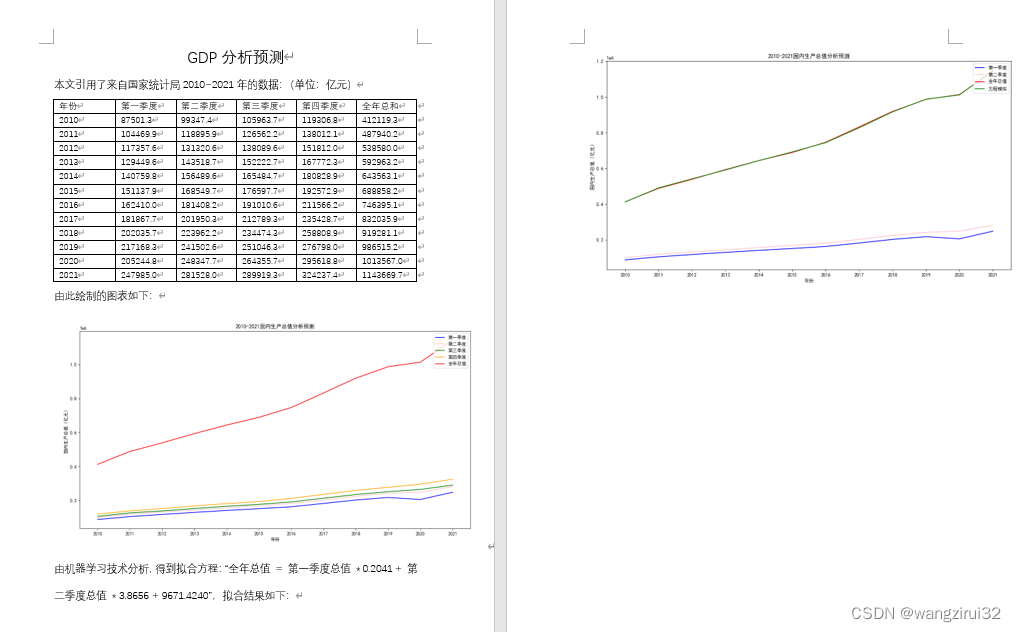
知识图谱嵌入技术主要将知识图谱中的实体和关系嵌入到连续的向量空间中,有助于完成诸如链接预测等下游任务。随着基于知识的人工智能的日益普及和应用,知识图谱的数据规模正在急剧增加。然而,大部分的知识图谱嵌入工作主要关注模型训练的结果,忽略了对于数据规模的可扩展性,在处理大规模知识图谱时表现出较差的性能。通过将知识图谱嵌入模型与数据库在数据管理上的优势进行有效的结合,能够在保证知识图谱嵌入模型训练的准确率和效率的同时,提供更好的可扩展性以支持大规模知识图谱数据的训练。基于此,本文提出一种数据库内置知识图谱嵌入模型训练引擎DB4Trans。首先,设计了一种用于知识图谱嵌入模型训练的数据存储方案,对实体和关系进行编码并建立索引结构,以实现模型训练过程中对中间结果的访问和更新;其次,提出了一种数据库内置的模型训练算法,对数据库与内存间的数据批量交换方案进行设计以支持大规模数据的训练与存储;最后,在不同数据集上进行了测试,比较了模型训练与预测的时间、模型训练的准确率、存储时间和空间效率并验证了方法的可扩展性。实验结果表明,所提出的方法能够在不影响模型训练效率和准确率的同时,通过内存与数据库间的数据交换,支持在数据库内完成大规模知识图谱的训练过程。
亮点
DB4Trans的亮点主要包括:
(1)设计了一种新颖的数据库内置知识图谱嵌入模型训练引擎,基于“存算一体化”的思想,以TransE模型为例,设计数据存储方案,使用关系数据库完成对知识图谱嵌入模型的训练与存储;
(2)提出数据库内模型训练算法,利用数据库技术支持模型训练的工作流程,基于设计的存储及索引方案提升模型训练过程中数据的读写速度从而保证模型训练的效率,并提出数据库与内存间的数据批量交换的方案以支持大规模数据的训练与存储。
概念及模型
DB4Trans主要以训练数据与模型在数据库中的存储及在内存中的计算与迭代训练两个方面为研究重点设计技术方案,总体架构如图1所示。DB4Trans将数据库技术与知识图谱嵌入的整体流程相融合,在数据库内进行知识图谱嵌入模型的训练,(1)将训练数据中的实体和关系进行编码后按照设计的存储方案导入并存储在数据库内;(2)在训练过程中,分批次将数据导入内存中完成模型训练的计算与迭代过程;(3)在多轮迭代之后,数据库内存储的实体和关系的嵌入值,即为模型训练所得到的结果。可以直接使用得到的训练结果进行链接预测等下游任务。
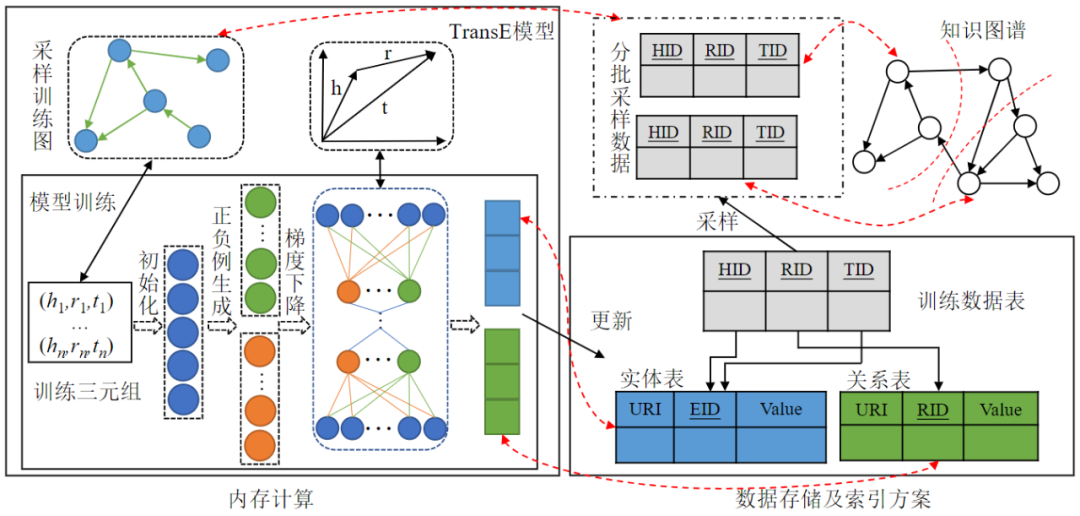
图1 DB4Trans总体架构图
数据存储方案
在读入知识图谱数据后,随机地将其划分为训练数据和测试数据,并将训练数据按照实体和关系分别存储到数据库的实体表和关系表中。根据训练时指定的嵌入向量的维数,在数据库中能够直接用向量类型的字段对训练结果进行存储与表示。对于用于训练的正例数据,建立训练数据表来存储三元组,表中每一行对应数据中一条(h,r,t)三元组,存储头实体、关系与尾实体的字典编码值。
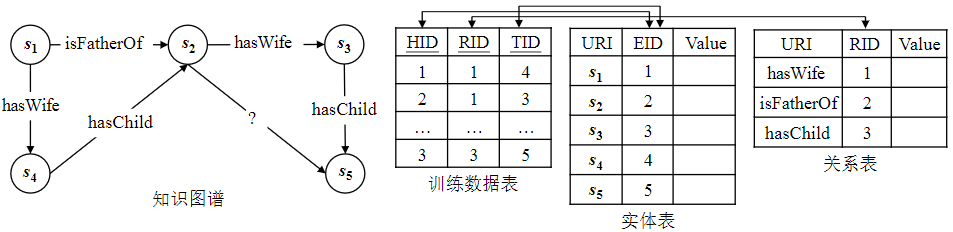
图2 数据存储方案示例
数据库内置模型训练优化技术
结合TransE模型工作流程,基于设计的数据存储方案,给出利用数据库技术进行模型训练的具体流程,使用数据库与内存间的数据批量交换策略来优化训练的过程,以支持大规模知识图谱的训练。考虑到现有KB2E方法存在的问题,DB4Trans利用数据库技术优化大规模知识图谱嵌入的模型训练过程。根据设计的数据存储方案,提出数据库和内存之间的数据批量交换算法。通过随机采样的方式,将训练数据从数据库读取到内存中,根据目标函数迭代计算进行模型的训练,并将实体和关系的嵌入值更新到数据库中。从而实现对大规模知识图谱嵌入模型的训练。
知识图谱嵌入模型适用性
提出的数据库内置知识图谱嵌入模型训练引擎对于在TransE基础上提出的其他基于翻译的知识图谱嵌入模型同样具有适用性。现有的不同模型从不同的角度把相应的语义信息嵌入知识图谱的向量表示中,如TransH、TransR等,本文提出的数据存储方案与数据库内置模型训练算法能够适用于该类模型。此外,通过对知识图谱嵌入模型可解释性的研究,可以将模型的训练及预测过程进行分解并提出新的算子,如数据批量交换算子、梯度下降计算算子以及不同模型对应得分函数计算的算子。通过在数据库底层实现这些新的算子,可以获取数据库技术对不同的大规模知识图谱嵌入模型训练过程的支持。
实验
本节在不同的数据集上进行实验,与TransE模型在单机环境下的框架进行训练的效率和链接预测得到的准确率进行比较,使用的数据集包括两个常用于进行链接预测评估任务的数据集WordNet和Freebase的子集。图3给出了实验所用数据集的具体统计信息,记录了实体、关系的数量以及训练集和测试集包含三元组的数量。
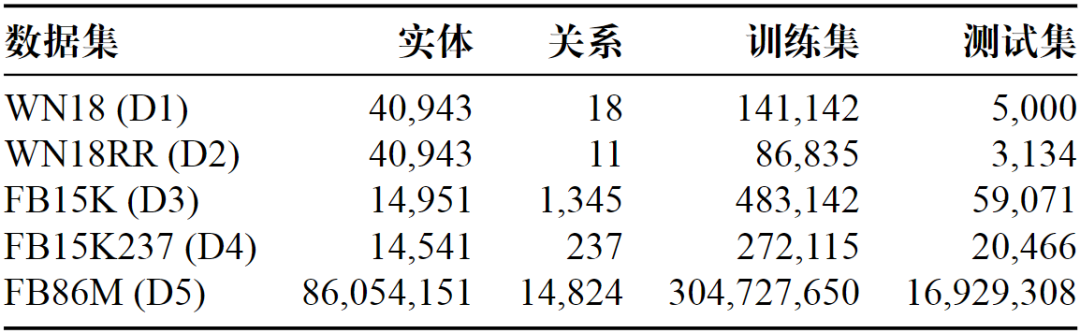 图3 实验数据集
图3 实验数据集
从3个方面对本文提出的方法的性能进行分析与比较.为了验证DB4Trans不会对模型训练的准确率和效率造成影响,将DB4Trans与KB2E在小规模的数据集上进行模型训练,并比较(1)模型训练与预测的效率;(2)模型训练结果进行链接预测的准确率。为了验证DB4Trans对于处理大规模数据集的适用性,并测试其对于数据采样与训练的有效性与高效性,分析(3)在不同规模的数据集下,DB4Trans对数据进行存储的空间开销与数据导入、分批采样训练的时间开销。
在常用的小规模数据集上测试,记录TransE模型训练和预测的时间。图4表明DB4Trans通过数据库进行模型训练与预测可以与原框架KB2E达到相近的效率。小规模数据集上模型训练与预测时间开销的测试证明了DB4Trans能够在不影响效率的前提下支持数据库内置的模型训练与预测。
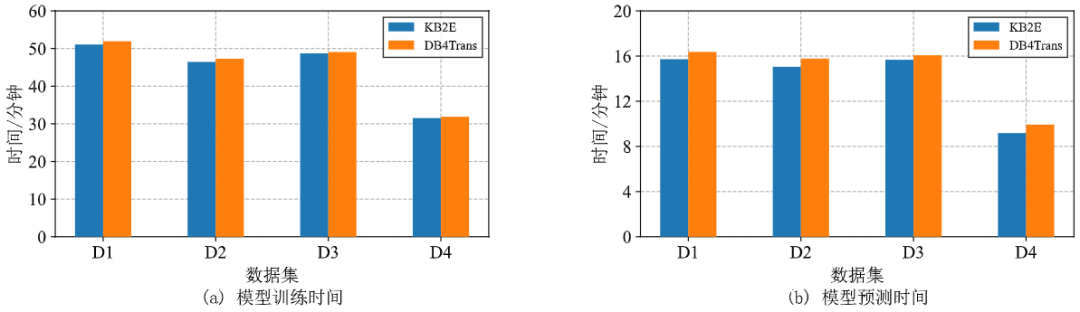 图4 不同数据集进行模型训练与预测的时间
图4 不同数据集进行模型训练与预测的时间
对上述四个数据集进行链接预测得到的结果进行分析,将DB4Trans和KB2E两种方法得到的三元组的Hits@10的值进行比较,两种方法训练得到的模型在预测结果上基本相近,各数据集训练结果准确率的差异与图5中迭代后loss值的差异相符。结果表明两种方法可以在模型训练的准确性上达到相当的效果,从而验证了DB4Trans对于模型预测的有效性,即DB4Trans利用数据库进行模型训练不会对预测结果的准确率造成影响。
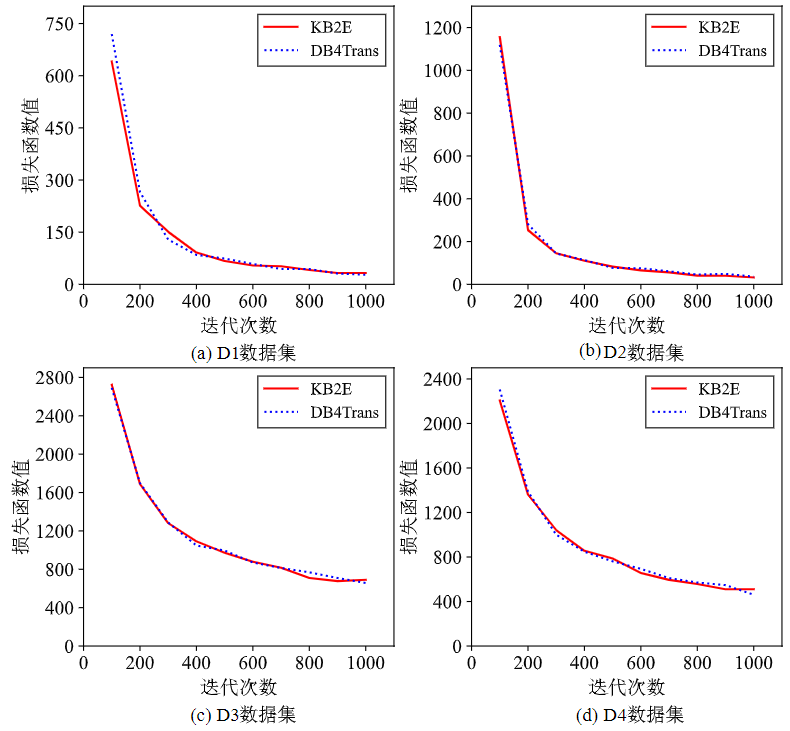
图5 模型训练 loss 值随迭代次数变化曲线
传统KB2E框架需要将数据全部读入内存后进行计算。在数据规模过大时,导致占用内存过大而无法直接对大规模数据进行训练。而DB4Trans能够通过数据库和内存间的批量数据交换读取数据进行训练,并将训练好的模型存储到数据库中。图6给出了DB4Trans与KB2E对于不同数据集进行采样的时间开销。可以看出,随着训练数据规模的增加,数据导入与采样的效率相比于传统方法能够提升至多一个数量级。
 图6 数据导入与随机采样所消耗的时间
图6 数据导入与随机采样所消耗的时间
通过数据在内存和数据库之间的交换,数据分批次从磁盘读入内存中进行训练,经过多次迭代,将训练后的模型结果更新到磁盘中,以用于后续的预测任务。通过这样的方式,能够有效避免现有的TransE实现方法存在的因需要一次性将数据全部读入内存中而导致在进行训练时内存占用率会过大的问题。因此,DB4Trans具备可扩展性并适用于大规模的数据集的训练与预测。
总结
本文提出了一种数据库内置的知识图谱嵌入模型训练引擎DB4Trans,能够在关系数据库内部进行知识图谱嵌入模型的训练,并利用基于数据库技术的优化方法,通过磁盘和内存间数据的不断交换,以支持大规模知识图谱数据的训练。以TransE模型为例,设计训练数据和模型的存储方案,提出利用数据库内的数据访问算法进行模型训练的优化方法。在不同数据集上的实验结果表明,通过将知识图谱嵌入模型训练与数据库技术相结合,DB4Trans能够在不影响原有方法训练准确率和效率的前提下,支持大规模知识图谱的训练,对数据规模具有良好的扩展性,同时也为今后面向知识图谱嵌入的查询工作提供了基础。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。