CAP
●一致性(Consistency):所有节点在同一时间具有相同的数据;
●可用性(Availability) :保证每个请求不管成功或者失败都有响应;某个系统的某个节点挂了,但是并不影响系统的接受或者发出请求。
●分隔容忍(Partition tolerance) :系统中任意信息的丢失或失败不会影响系统的继续运作;在整个系统中某个部分,挂掉了,或者宕机了,并不影响整个系统的运作或使用
CAP 不可能都取,只能取其中2个的原因如下:
●如果C是第一需求的话,那么会影响A的性能,因为要数据同步,不然请求结果会有差异,但是数据同步会消耗时间,期间可用性就会降低。
●如果A是第一需求,那么只要有一个服务在,就能正常接受请求,但是对与返回结果变不能保证,原因是,在分布式部署的时候,数据一致的过程不可能想切线路那么快。
●同时满足一致性和可用性,那么分区容错P就很难保证了,也就是单点,也是分布式的基本核心。

注册中心 registry center

Eureka
Consul
Nacos
Zookeeper
Etcd
Eureka
Eureka is created in strict accordance with the AP principle. As long as there is one Eureka in the cluster, the provision of registration services is guaranteed, but the information found may not be the latest information (there is no guarantee of strong consistency).
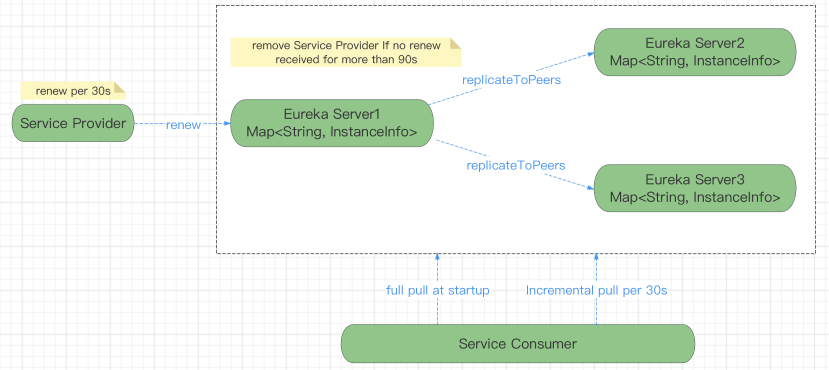
架构图 architecture diagram

master-slave

peer-to-peer replication

服务注册 registry

Why Is It so Slow to Register a Service?
Being an instance also involves a periodic heartbeat to the registry (through the client’s serviceUrl) with a default duration of 30 seconds. A service is not available for discovery by clients until the instance, the server, and the client all have the same metadata in their local cache (so it could take 3 heartbeats). You can change the period by setting eureka.instance.leaseRenewalIntervalInSeconds. Setting it to a value of less than 30 speeds up the process of getting clients connected to other services. In production, it is probably better to stick with the default, because of internal computations in the server that make assumptions about the lease renewal period.
服务续约 renew heartbeat
服务下线 cancel

服务失效剔除 Eviction

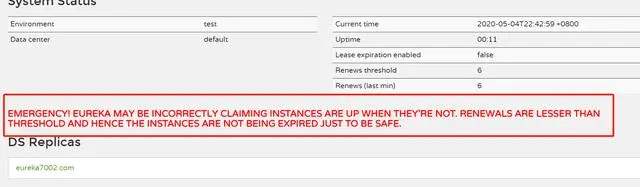
自我保护机制 self-protection mode
By default, if Eureka Server does not receive the heartbeat of a microservice instance within a certain period of time, Eureka Server will log off the instance (90s by default). But when a network partition failure occurs (delay, freeze, congestion), the microservice The normal communication between the service and Eureka Server may become very dangerous because the microservice itself is actually healthy. At this time, the microservice should not be logged out. Eureka solves this problem through the "self-protection mode"-when the Eureka Server node loses too many clients in a short period of time (a network partition failure may occur), then this node will enter the self-protection mode.
Self-protection is a security protection measure to deal with network anomalies. Its architectural philosophy is to rather keep all microservices at the same time (both healthy and unhealthy microservices will be kept), rather than blindly log off any healthy microservices. Using the self-protection mode can make the Eureka cluster more robust and stable
Less than 85% of renews within 15 minutes will enter the self-protection mode
机房 Zones
If you have deployed Eureka clients to multiple zones, you may prefer that those clients use services within the same zone before trying services in another zone. To set that up, you need to configure your Eureka clients correctly.
First, you need to make sure you have Eureka servers deployed to each zone and that they are peers of each other. See the section on zones and regions for more information.
Next, you need to tell Eureka which zone your service is in. You can do so by using the metadataMap property. For example, if service 1 is deployed to both zone 1 and zone 2, you need to set the following Eureka properties in service 1:
高可用 High Availability, Zones and Regions
The Eureka server does not have a back end store, but the service instances in the registry all have to send heartbeats to keep their registrations up to date (so this can be done in memory). Clients also have an in-memory cache of Eureka registrations (so they do not have to go to the registry for every request to a service).
By default, every Eureka server is also a Eureka client and requires (at least one) service URL to locate a peer. If you do not provide it, the service runs and works, but it fills your logs with a lot of noise about not being able to register with the peer.
测试
注册中心有两个 eureka(peer1):1111 和 eureka(peer2):1112,他们之间相互注册实现高可用。
The registration center has two eureka(peer1):1111 and eureka(peer2):1112, and they register with each other to achieve high availability.

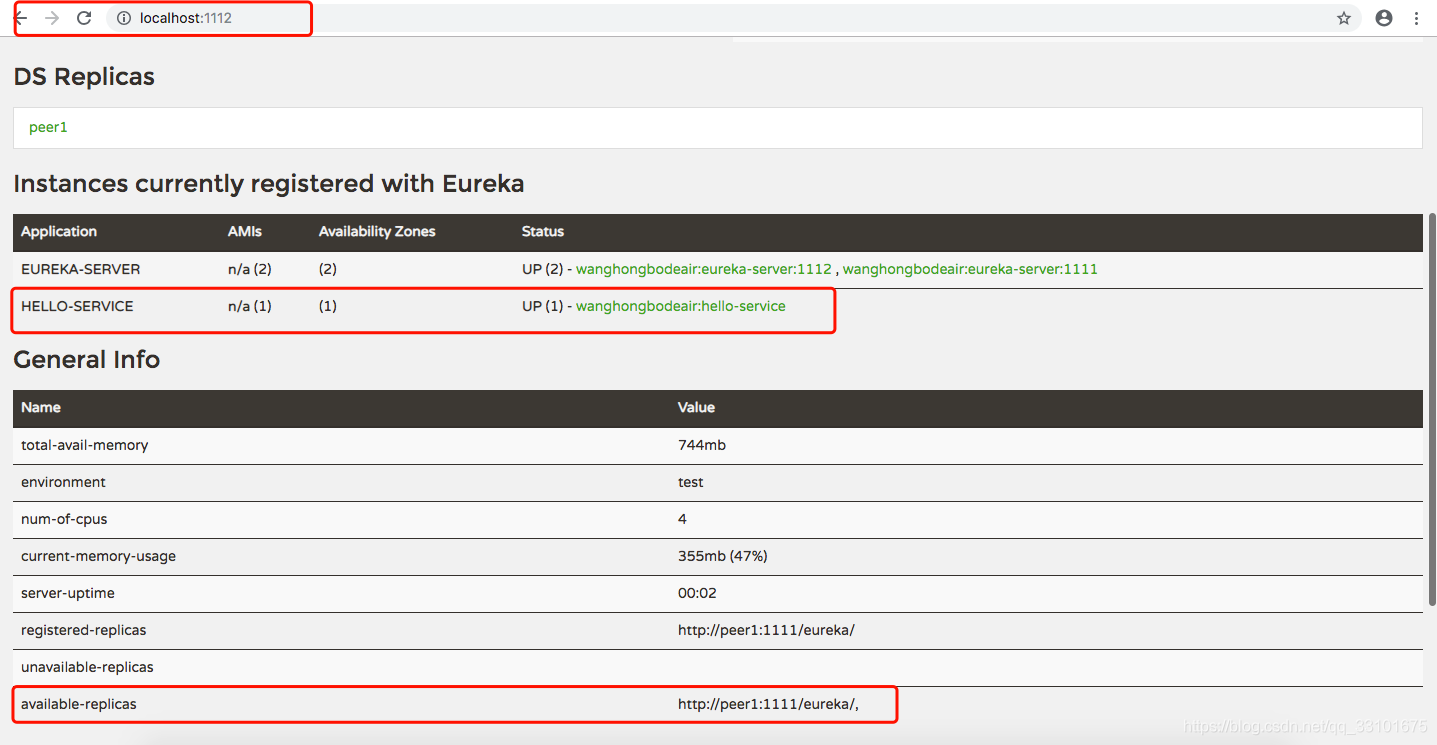
eureka(peer1):1111 shutdown

Zookeeper


Zookeeper可以充当一个服务注册表(Service Registry),让多个服务提供者形成一个集群,让服务消费者通过服务注册表获取具体的服务访问地址(Ip+端口)去访问具体的服务提供者。

服务注册 registry
每当一个服务提供者部署后都要将自己的服务注册到zookeeper的某一路径上: /{service}/{version}/{ip:port} 。
比如我们的HelloWorldService部署到两台机器,那么Zookeeper上就会创建两条目录:
/HelloWorldService/1.0.0/100.19.20.01:16888
/HelloWorldService/1.0.0/100.19.20.02:16888

在zookeeper中,进行服务注册,实际上就是在zookeeper中创建了一个znode节点,该节点存储了该服务的IP、端口、调用方式(协议、序列化方式)等。该节点承担着最重要的职责,它由服务提供者(发布服务时)创建,以供服务消费者获取节点中的信息,从而定位到服务提供者真正网络拓扑位置以及得知如何调用。
RPC服务注册/发现过程简述如下:
1provider 启动时,会将其appName, ip注册到配置中心。
2consumer 在第一次调用服务时,会通过 zookeeper 找到 providers 的IP地址列表,并缓存到本地,以供后续使用。当 consumer 调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从IP列表中取一个 providers 调用服务。
3当 providers 的某台服务器宕机或下线时,相应的ip会从服务提供者IP列表中移除。同时,注册中心会将新的服务IP地址列表发送给 consumer 机器,缓存在消费者本机。
4当某个服务的所有服务器都下线了,那么这个服务也就下线了。
5同样,当服务提供者的某台服务器上线时,注册中心会将新的服务IP地址列表发送给服务消费者机器,缓存在消费者本机。
6服务提供方可以根据服务消费者的数量来作为服务下线的依据。
心跳检测 heartbeat
当服务提供者的某台服务器宕机或下线时,zookeeper如何感知到呢?
zookeeper提供了“心跳检测”功能,它会定时向各个服务提供者发送一个请求(实际上建立的是一个 socket 长连接),如果长期没有响应,服务中心就认为该服务提供者已经“挂了”,并将其剔除。
比如100.19.20.01这台机器如果宕机了,那么zookeeper上的路径就会只剩/HelloWorldService/1.0.0/100.19.20.02:16888。
Watch机制
注册中心会将新的服务IP地址列表发送给服务消费者机器,这步如何实现呢?
这个问题也是经典的生产者-消费者问题,解决的方式有两种:
主动拉取策略:服务的消费者定期调用注册中心提供的服务获取接口获取最新的服务列表并更新本地缓存,经典案例就是Eureka。
发布-订阅模式:服务消费者能够实时监控服务更新状态,通常采用监听器以及回调机制。
Zookeeper使用的是“发布-订阅模式”,这里就要提到Zookeeper的Watch机制,整体流程如下:
客户端先向ZooKeeper服务端成功注册想要监听的节点状态,同时客户端本地会存储该监听器相关的信息在WatchManager中;
当ZooKeeper服务端监听的数据状态发生变化时,ZooKeeper就会主动通知发送相应事件信息给相关会话客户端,客户端就会在本地响应式的回调相关Watcher的Handler。

Zookeeper的Watch机制其实就是一种推拉结合的模式:
1服务消费者会去监听相应路径(/HelloWorldService/1.0.0),一旦路径上的数据有任务变化(增加或减少),Zookeeper只会发送一个事件类型和节点信息给关注的客户端,而不会包括具体的变更内容,所以事件本身是轻量级的,这就是推的部分。
2收到变更通知的客户端需要自己去拉变更的数据,这就是拉的部分。
Zookeeper是否用作注册中心?
ZooKeeper is a distributed, open-source coordination service for distributed applications. It exposes a simple set of primitives that distributed applications can build upon to implement higher level services for synchronization, configuration maintenance, and groups and naming. It is designed to be easy to program to, and uses a data model styled after the familiar directory tree structure of file systems.
Coordination services are notoriously hard to get right. They are especially prone to errors such as race conditions and deadlock. The motivation behind ZooKeeper is to relieve distributed applications the responsibility of implementing coordination services from scratch.
ZooKeeper的官网介绍没有说他是一个注册中心,而是说他是一个分布式协同服务,能够实现 同步、配置维护以及组和命名的更高级别的服务,他是有序的,且在读多写少的场景中很快,读写比大概10:1表现最佳。
Zookeeper性能测试
followers 失败并快速恢复,那么 ZooKeeper 能够在失败的情况下维持高吞吐量。
leader选举算法允许系统足够快地恢复,以防止吞吐量大幅下降。 在我们的观察中,ZooKeeper 只需不到 200ms 即可选出新的leader
随着follow的恢复,一旦开始处理请求,ZooKeeper 就能够再次提高吞吐量。
所以 3.2版本之后,读写性能增大了2倍,Leader宕机之后也能很快的完成选举,可以考虑用做注册中心。
Nacos
Introduce
Nacos is the acronym for 'Dynamic Naming and Configuration Service',an easy-to-use dynamic service discovery, configuration and service management platform for building cloud native applications。
Nacos is committed to help you discover, configure, and manage your microservices. It provides a set of simple and useful features enabling you to realize dynamic service discovery, service configuration, service metadata and traffic management.
Nacos makes it easier and faster to construct, deliver and manage your microservices platform. It is the infrastructure that supports a service-centered modern application architecture with a microservices or cloud-native approach.
Service is a first-class citizen in Nacos. Nacos supports discovering, configuring, and managing almost all types of services:
Kubernetes Service
gRPC & Dubbo RPC Service
Spring Cloud RESTful Service
Key features of Nacos:
●Service Discovery And Service Health Check Nacos supports both DNS-based and RPC-based (Dubbo/gRPC) service discovery. After a service provider registers a service with native, OpenAPI, or a dedicated agent, a consumer can discover the service with either DNS or HTTP.Nacos provides real-time health check to prevent services from sending requests to unhealthy hosts or service instances. Nacos supports both transport layer (PING or TCP) health check and application layer (such as HTTP, Redis, MySQL, and user-defined protocol) health check. For the health check of complex clouds and network topologies(such as VPC, Edge Service etc), Nacos provides both agent mode and server mode health check. Nacos also provide a unity service health dashboard to help you manage the availability and traffic of services.
●Dynamic configuration management Dynamic configuration service allows you to manage the configuration of all applications and services in a centralized, externalized and dynamic manner across all environments.Dynamic configuration eliminates the need to redeploy applications and services when configurations are updated.Centralized management of configuration makes it more convenient for you to achieve stateless services and elastic expansion of service instances on-demand.Nacos provides an easy-to-use UI (DEMO) to help you manage all of your application or services's configurations. It provides some out-of-box features including configuration version tracking, canary/beta release, configuration rollback, and client configuration update status tracking to ensure the safety and control the risk of configuration change.
●Dynamic DNS service Dynamic DNS service which supports weighted routing makes it easier for you to implement mid-tier load balancing, flexible routing policies, traffic control, and simple DNS resolution services in your production environment within your data center. Dynamic DNS service makes it easier for you to implement DNS-based Service discovery.Nacos provides some simple DNS APIs TODO for you to manage your DNS domain names and IPs.
●Service governance and metadata management Nacos allows you to manage all of your services and metadata from the perspective of a microservices platform builder. This includes managing service description, life cycle, service static dependencies analysis, service health status, service traffic management,routing and security rules, service SLA, and first line metrics.

As the figure above shows, Nacos seamlessly supports open source ecologies including Dubbo and Dubbo Mesh, Spring Cloud, and Kubernetes and CNCF.
Use Nacos to simplify your solutions in service discovery, configuration management, and service governance and management. With Nacos, microservices management in open source system is easy.
For more information about how to use Nacos with other open source projects, see the following:
Use Nacos with Kubernetes
Use Nacos with Dubbo
Use Nacos with gRPC
Use Nacos with Spring Cloud
Use Nacos with Istio

Domain Model
Data Model
The Nacos data model Key is uniquely determined by the triplet. The Namespace defaults to an empty string, the public namespace (public), and the group defaults to DEFAULT_GROUP.

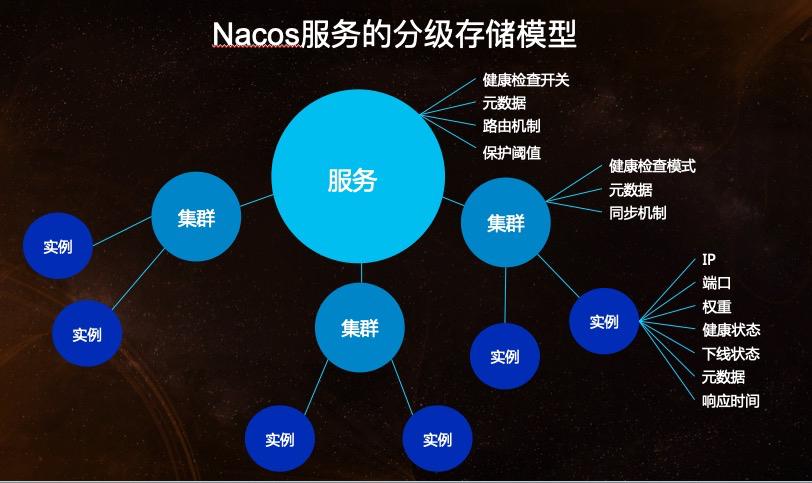
Service Entity Relationship Model
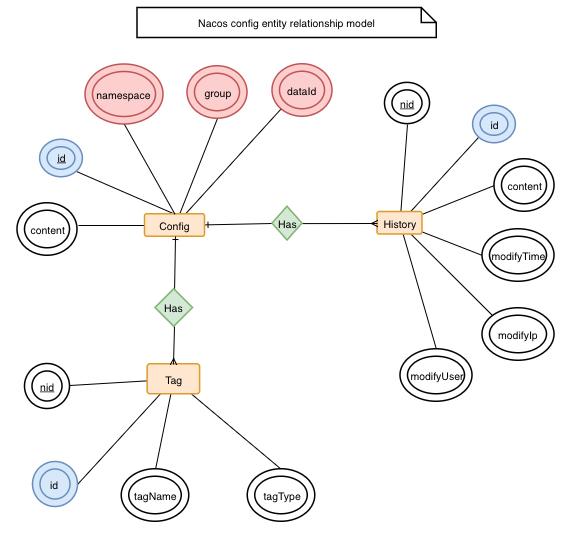
Config Entity Relationship Model
Around the configuration, there are mainly two associated entities, one is the configuration change history, and the other is the service tag (used for marking classification, convenient for indexing), which is associated by ID.
Artifacts, Deployment, and Start Mode

Two Artifacts
Nacos supports both standard Docker images (v0.2.0) and nacos-.zip(tar.gz). You can choose the appropriate build to deploy the Nacos service according to your needs.
Two Start Modes
Nacos supports two start modes. you can merging the Service Registry and the Config Center in one process or deploying them in separately cluster.
Nacos service discovery performance test report
Nacos 2.0 的性能测试报告
腾讯云对Nacos 2.0 的性能测试报告
Consul
What is Consul?
HashiCorp Consul is a service networking solution that enables teams to manage secure network connectivity between services and across on-prem and multi-cloud environments and runtimes. Consul offers service discovery, service mesh, traffic management, and automated updates to network infrastructure device. You can use these features individually or together in a single Consul deployment.
Hands-on: Complete the Getting Started tutorials to learn how to deploy Consul:
●Get Started on Kubernetes
●Get Started on VMs
●HashiCorp Cloud Platform (HCP) Consul
How does Consul work?
Consul provides a control plane that enables you to register, query, and secure services deployed across your network. The control plane is the part of the network infrastructure that maintains a central registry to track services and their respective IP addresses. It is a distributed system that runs on clusters of nodes, such as physical servers, cloud instances, virtual machines, or containers.
Consul interacts with the data plane through proxies. The data plane is the part of the network infrastructure that processes data requests. Refer to Consul Architecture for details.

The core Consul workflow consists of the following stages:
●Register: Teams add services to the Consul catalog, which is a central registry that lets services automatically discover each other without requiring a human operator to modify application code, deploy additional load balancers, or hardcode IP addresses. It is the runtime source of truth for all services and their addresses. Teams can manually define and register services using the CLI or the API, or you can automate the process in Kubernetes with service sync. Services can also include health checks so that Consul can monitor for unhealthy services.
●Query: Consul’s identity-based DNS lets you find healthy services in the Consul catalog. Services registered with Consul provide health information, access points, and other data that help you control the flow of data through your network. Your services only access other services through their local proxy according to the identity-based policies you define.
●Secure: After services locate upstreams, Consul ensures that service-to-service communication is authenticated, authorized, and encrypted. Consul service mesh secures microservice architectures with mTLS and can allow or restrict access based on service identities, regardless of differences in compute environments and runtimes.
What is service discovery?
Service discovery helps you discover, track, and monitor the health of services within a network. Service discovery registers and maintains a record of all your services in a service catalog. This service catalog acts as a single source of truth that allows your services to query and communicate with each other.
Benefits of service discovery
Service discovery provides benefits for all organizations, ranging from simplified scalability to improved application resiliency. Some of the benefits of service discovery include:
●Dynamic IP address and port discovery
●Simplified horizontal service scaling
●Abstracts discovery logic away from applications
●Reliable service communication ensured by health checks
●Load balances requests across healthy service instances
●Faster deployment times achieved by high-speed discovery
●Automated service registration and de-registration
How does service discovery work?
Service discovery uses a service's identity instead of traditional access information (IP address and port). This allows you to dynamically map services and track any changes within a service catalog. Service consumers (users or other services) then use DNS to dynamically retrieve other service's access information from the service catalog. The lifecycle of a service may look like the following:
A service consumer communicates with the “Web” service via a unique Consul DNS entry provided by the service catalog.

A new instance of the “Web” service registers itself to the service catalog with its IP address and port. As new instances of your services are registered to the service catalog, they will participate in the load balancing pool for handling service consumer requests.

The service catalog is dynamically updated as new instances of the service are added and legacy or unhealthy service instances are removed. Removed services will no longer participate in the load balancing pool for handling service consumer requests.

What is service discovery in microservices?
In a microservices application, the set of active service instances changes frequently across a large, dynamic environment. These service instances rely on a service catalog to retrieve the most up-to-date access information from the respective services. A reliable service catalog is especially important for service discovery in microservices to ensure healthy, scalable, and highly responsive application operation.
What are the two main types of service discovery?
There are two main service‑discovery patterns: client-side discovery and server-side discovery.
In systems that use client‑side discovery, the service consumer is responsible for determining the access information of available service instances and load balancing requests between them.
1The service consumer queries the service catalog
2The service catalog retrieves and returns all access information
3The service consumer selects a healthy downstream service and makes requests directly to it

In systems that use server‑side discovery, the service consumer uses an intermediary to query the service catalog and make requests to them.
1The service consumer queries an intermediary (Consul)
2The intermediary queries the service catalog and routes requests to the available service instances.

For modern applications, this discovery method is advantageous because developers can make their applications faster and more lightweight by decoupling and centralizing service discovery logic.
Service discovery vs load balancing
Service discovery and load balancing share a similarity in distributing requests to back end services, but differ in many important ways.
Traditional load balancers are not designed for rapid registration and de-registration of services, nor are they designed for high-availability. By contrast, service discovery systems use multiple nodes that maintain the service registry state and a peer-to-peer state management system for increased resilience across any type of infrastructure.
For modern, cloud-based applications, service discovery is the preferred method for directing traffic to the right service provider due to its ability to scale and remain resilient, independent of infrastructure.
How do you implement service discovery?
You can implement service discovery systems across any type of infrastructure, whether it is on-premise or in the cloud. Service discovery is a native feature of many container orchestrators such as Kubernetes or Nomad. There are also platform-agnostic service discovery methods available for non-container workloads such as VMs and serverless technologies. Implementing a resilient service discovery system involves creating a set of servers that maintain and facilitate service registry operations. You can achieve this by installing a service discovery system or using a managed service discovery service.
Recommended Architecture
The following diagram shows the recommended architecture for deploying a single Consul cluster with maximum resiliency:

We recommend deploying 5 nodes within the Consul cluster distributed between three availability zones as this architecture can withstand the loss of two nodes from within the cluster or the loss of an entire availability zone. Together, these servers run the Raft-driven consistent state store for updating catalog, session, prepared query, ACL, and KV state.
If deploying to three availability zones is not possible, this same architecture may be used across one or two availability zones, at the expense of significant reliability risk in case of an availability zone outage. For more information on quorum size and failure tolerance for various cluster sizes, please refer to the Consul Deployment Table.
Failure tolerance characteristics
When deploying a Consul cluster, it’s important to consider and design for the specific requirements for various failure scenarios:
Node failure
Consul allows for individual node failure by replicating all data between each server agent of the cluster. If the leader node fails, the remaining cluster members will elect a new leader following the Raft protocol. To allow for the failure of up to two nodes in the cluster, the ideal size is five nodes for a single Consul cluster.
Availability zone failure
By deploying a Consul cluster in the recommended architecture across three availability zones, the Raft consensus algorithm is able to maintain consistency and availability given the failure of any one availability zone.
In cases where deployment across three availability zones is not possible, the failure of an availability zone may cause the Consul cluster to become inaccessible or unable to elect a leader. In a two availability zone deployment, for example, the failure of one availability zone would have a 50% chance of causing a cluster to lose its Raft quorum and be unable to service requests.
Etcd
etcd is a strongly consistent, distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines. It gracefully handles leader elections during network partitions and can tolerate machine failure, even in the leader node.
Simple interface
Read and write values using standard HTTP tools, such as curl
{JSON
HTTP

Key-value storage
Store data in hierarchically organized directories, as in a standard filesystem

Watch for changes
Watch specific keys or directories for changes and react to changes in values
PPP1
/CONFIG
APP2

●Optional SSL client certificate authentication
●Benchmarked at 1000s of writes/s per instance
●Optional TTLs for keys expiration
●Properly distributed via Raft protocol
Kubernetes
Etcd is built in to realize the function of service discovery
Compared
Consul | Nacos | Zookeeper | Etcd | Kubernetes(Etcd) | Eureka | |
Conpany | HashiCorp | Alibaba | Apache | CoreOS | Netflix | |
Language | Go | Java | Java | Go | Go | Java |
GitHub | https://github.com/hashicorp/consul(25.9K Star) | https://github.com/alibaba/nacos(25.2K Star) | https://github.com/apache/zookeeper(11K Star) | https://github.com/etcd-io/etcd(42.3K Star) | https://github.com/kubernetes/kubernetes(95.2K Star) | https://github.com/Netflix/eureka(11.6K Star) |
GitHub Solve Issue | ✅✅(May be Stablize) | ✅✅✅ | ✅✅(May be Stablize) | ✅✅✅ | ✅✅✅ | |
LICENSE | MPL-2.0 license | Apache-2.0 license | Apache-2.0 license | Apache-2.0 license | Apache-2.0 license | Apache-2.0 license |
Web Tools | Consul | Nacos | ZKUI | etcd-browser、etcdkeeper | cloud platform | Eureka |
Cloud Products | ❌ Aliyun ❌ AWS ✅ Tencent Cloud TSE Consul | ✅ Aliyun MSE Nacos ❌ AWS ✅ Tencent Cloud TSE Nacos | ✅ Aliyun MSE Zookeeper ✅ AWS EMR ZooKeeper ✅ Tencent Cloud TSE Zookeeper | ✅ Aliyun ACK(kubernetes) ✅ AWS EKS(kubernetes) ✅ Tencent Cloud TKE / Cloud Service for etcd(cetcd) | ✅ Aliyun ACK(kubernetes) ✅ AWS EKS(kubernetes) ✅ Tencent Cloud TKE | |
Performance | ✅✅ |

Nacos2.0服务发现性能测试报告 ✅✅ Configuration center: a single machine, 8C 16G, write TPS reaches 2500, with an average of about 10ms. Read TPS 14000, an average of 40ms. Registration center: 3 clusters, 8C 16G, the service and instance capacity reached one million levels during the stress test, the cluster operation continued to be stable, the registration/deregistration instance TPS reached more than 26,000, and the average time-consuming was 3.6ms, and the query instance TPS could reach more than 30,000. Average time spent 3.12ms | ZooKeeper: Because Coordinating Distributed Systems is a Zoo ✅✅✅ |

Performance ✅✅✅✅ | ✅✅✅✅ | ✅ |
Performance Bottleneck | Consul's write capability is limited by disk I/O, and its read capability is limited by CPU. Memory requirements will depend on the total size of KV pairs stored and should be sized based on that data (as should hard disk storage). The value of the key (Value) size limit is 512KB. | ●In order to ensure strong consistency, in the same zk cluster, only one leader can perform write operations, and the write operation must be completed after more than half of the node machines are synchronized before acking the client. ●When there are hundreds of thousands of machines in this cluster system to continuously use zk for distributed lock operations or other operations, zk will inevitably become a performance bottleneck (cannot be scaled horizontally) ●ZooKeeper does not support cross-computer room routing. Unlike eureka, which has the concept of zone, local routing is preferred. When the local computer room is routed, when there is a problem in the local computer room, it can be routed to another computer room. ●When there are too many ZooKeeper nodes, if there is a service node change and the machine needs to be notified at the same time, then the network card will be fully loaded in an instant, and it is easy to repeat the notification | When the scale of Eureka's service instances is around 5000, the problem of service unavailability has already occurred. Even in the process of stress testing, if the number of concurrent threads is too high, Eureka will crash. | |||
CAP | CP | CP:Config Center AP:Registry Center | CP | CP | AP | |
Consistency Algorithm | Raft | Raft | ZAB | Raft | - | |
Service Health Check | TCP/HTTP/GRPC/CMD | TCP/HTTP/MySQL/Custom | Keep Alive | Heart Beat | Client Beat | |
Load Balance | Fabio | Weight/Metadata/Selector | - | Ribbon | ||
Avalanche Protection | ❌ | ✅ | ❌ | ❌ | ✅ | |
Multi Data Center | ✅✅(natural support) | ✅ | ❌ | ❌ | ❌ | |
Sync Across Registry Center | ✅ | ✅ | ❌ | ❌ | ❌ | |
KV Storage Service | ✅ | ✅ | ✅ | ✅ | ✅ After purchase, test whether it is convenient to change the configuration, whether it supports dynamic configuration, and whether it is convenient to authorize permissions | ❌ |
Service Auto Remove | ✅ | ✅ | ✅ | ✅ | ✅ | |
Watch | ✅ | ✅ | ✅ Pros:
Cons:
| ✅✅ Pros:
| ❌ | |
Access Agreement | HTTP/DNS | HTTP/DNS/UDP | TCP | HTTP/gRPC | HTTP | |
Self-monitoring | Metrics | Metrics | ❌ | Metrics
| Metrics | |
Access Control | ACL | RBAC | ACL | RBAC | RBAC | ❌ |
SRE Authorization Convenient? | ✅✅ | ✅✅ | ✅ | ✅✅ | test after purchase | |
Dubbo | ✅ | ✅ | ✅ | ❌ | ❌ | |
K8S | ✅ | ✅ | ❌ | ✅ | ❌ | |
Spring Cloud | ✅ | ✅ | ✅ | ✅ | ✅ | |
Pros | ● Compared with other distributed service registration and discovery solutions, Consul's solution is more "one-stop", with built-in service registration and discovery framework, distributed consistency protocol implementation, health check, Key/Value storage, and multi-data center solutions , no longer need to rely on other tools (such as ZooKeeper, etc.). It is also relatively simple to use. Consul is written in the Go language, so it is naturally portable; the installation package contains only one executable file, which is easy to deploy and works seamlessly with lightweight containers such as Docker. ● At the same time, Consul is more famous in the world, the official documents are very complete, the recommended deployment architecture, the number of nodes, and the stability of multiple data centers are very clear | ● The configuration center uses CP, and the registration center uses AP, which not only ensures the consistency of configuration, but also ensures the high availability of services. | ● Non-blocking full snapshots (to make eventually consistent). ● Efficient memory management. ● Reliable (has been around for a long time). ● A simplified API. ● Automatic ZooKeeper connection management with retries. ● Complete, well-tested implementations of ZooKeeper recipes. ● A framework that makes writing new ZooKeeper recipes much easier. ● Event support through ZooKeeper watches. ● In a network partition, both minority and majority partitions will start a leader election. Therefore, the minority partition will stop operations. You can read more about this here. | ● Incremental snapshots avoid pauses when creating snapshots, which is a problem in ZooKeeper. ● No garbage collection pauses due to off-heap storage. ● Watchers are redesigned, replacing the older event model with one that streams and multiplexes events over key intervals. Therefore, there's no socket connection per watch. Instead, it multiplexes events on the same connection. ● Unlike ZooKeeper, etcd can continuously watch from the current revision. There's no need to place another watch once a watch is triggered. ● Etcd3 holds a sliding window to keep old events so that disconnecting will not cause all events to be lost. | ||
Cons | ● Service registration will be slower, because Consul's Raft protocol requires more than half of the nodes to write successfully to register successfully. ● When the Leader hangs up, the entire Consul is unavailable during the re-election period, ensuring strong consistency but sacrificing availability. | ● Nacos is not well-known internationally, and there are relatively few English documents ● This is not friendly to foreign SRE and development students, especially SRE, because Nacos needs to ensure high availability and no problems. | ● Since ZooKeeper is written in Java, it inherits few drawbacks of Java (i.e. garbage collection pauses). ● When creating snapshots (where the data is written to disks), ZooKeeper read/write operations are halted temporarily. This only happens if we have enabled snapshots. If not, ZooKeeper operates as an in-memory distributed storage. ● ZooKeeper opens a new socket connection per each new watch request we make. This has made ZooKeepers like more complex since it has to manage a lot of open socket connections in real time. ●The callback mechanism is limited. The watch on the Znode only supports triggering a callback once, and does not support timed expiration. ●Insufficient scalability, ZK cluster does not support online dynamic addition or replacement of machines:Because there is only one Leader, horizontal expansion cannot significantly improve performance. Because there is only one Leader, the more zk machine nodes, it will lead to longer communication and synchronization time, and performance may deteriorate. ●Zab protocol, the protocol has room for optimization in the election and sending links:The design of zab is extremely sensitive to the network. If you manage a dual-computer room (network jitter in a dual-computer room is normal), the single-computer room will be unavailable due to jitter (because there is only one Leader), even in a computer room (often in the computer room. Routing adjustment), jitter will also lead to leader re-election, the actual leader election is usually tens of seconds to a few minutes, which will seriously amplify the network jitter that was originally only in seconds | ● Note that the client may be uncertain about the status of an operation if it times out or if there's a network disruption between the client and the etcd member. etcd may also abort operations when there is a leader election. etcd does not send abort responses to clients’ outstanding requests in this event. ● Serialized read requests will continue to be served in a network split where the minority partition is the leader at the time of the split. | 1Eureka currently does not support the watch function, and can only update the service status through rotation training. If there are many services, the pressure on the server will be relatively high, and the relative performance will be relatively poor. However, the number of our services is currently within 100, so performance is not the main problem |
Avalanche Protection:The protection threshold is to prevent all traffic from flowing into the remaining healthy instances due to too many instance failures, and then cause traffic pressure to overwhelm the remaining healthy instances and form an avalanche effect
● Eureka will not be updated and maintained after version 2.0, so we will discard it.
● Zookeeper's write performance can reach tens of thousands of TPS, and its capacity can reach millions in terms of the number of storage nodes. However, the Paxos protocol limits the size of the Zookeeper cluster (3, 5 nodes). When a large number of instances go offline, the performance of Zookeeper is not stable. At the same time, the defect in the push mechanism will cause the resource usage of the client to increase, resulting in a sharp drop in performance, so we will discard it.
● Etcd is developed based on Zookeeper and written in Go, so there will be no Java GC problems. At the same time, it also optimizes Watch. Etcd is a durable and stable watch rather than a simple single-trigger watch. Zookeeper's single-trigger watch means that after monitoring an event, the client needs to re-initiate the monitoring, so that the zookeeper server cannot obtain the events before receiving the client's monitoring request; and at the time of the two monitoring requests The client cannot perceive the events that occur within the interval. The persistent monitoring of etcd is triggered continuously whenever an event occurs, and the client does not need to re-initiate the monitoring. Although etcd is relatively new, it has a strong background of Kubernetes, an active community, and a bright future, so it can still be considered.
● Nacos /nɑ:kəʊs/ is the acronym for 'Dynamic Naming and Configuration Service',an easy-to-use dynamic service discovery, configuration and service management platform for building cloud native applications,It is easy to use and has high performance(Doubtful). The community in China is very active and used a lot. However, for foreign colleagues, especially SRE, Nacos is not well-known internationally, and there are relatively few English documents. The cluster deployment in the official document Documentation is also relatively simple, so we will discard it.
● Compared with other distributed service registration and discovery solutions, Consul's solution is more "one-stop", with built-in service registration and discovery framework, distributed consistency protocol implementation, health check, Key/Value storage, and multi-data center solutions , no longer need to rely on other tools (such as ZooKeeper, etc.). It is also relatively simple to use. Consul is written in the Go language, so it is naturally portable; the installation package contains only one executable file, which is easy to deploy and works seamlessly with lightweight containers such as Docker, so it can still be considered.
● Kubernetes has some built-in components(Etcd), which allow him to have functions such as service discovery, configuration management, which are fully functional and make our distributed applications more elastic and free, so it can still be considered.
Therefore, in my opinion, if our container uses Kubernetes, then our entire set of microservices can also use Kubernetes, without the need to introduce other components like Consul or Nacos to increase the cost of money and SRE, and every All cloud vendors will have Kubernetes-managed products; in the future, our new architecture will be deployed on Alibaba Cloud first, and then migrated to AWS. Then we only need to buy Kubernetes on AWS, and there is no need to change the service discovery and configuration. If We use Consul, we need to deploy a Consul cluster on Alibaba Cloud, and after migrating to AWS, we also need to deploy a Consul cluster on AWS. Otherwise, we can use Consul as our registry and configuration center
Reference Documents
Spring Cloud
What is Nacos
微服务引擎 TSE Zookeeper 性能评估-购买指南-文档中心-腾讯云
微服务引擎 TSE Nacos 性能评估-购买指南-文档中心-腾讯云
Apache ZooKeeper vs. etcd3 - DZone
Consul Reference Architecture | Consul | HashiCorp Developer
The Future of Spring Cloud Microservices After Netflix Era - DZone
dbtester/test-results/2018Q1-02-etcd-zookeeper-consul at master · etcd-io/dbtester
若有收获,就点个赞吧

![[ESP][驱动]GT911 ESP系列驱动](https://img-blog.csdnimg.cn/img_convert/f96532c3bade5fbde7420e358c26c16f.png)