想要入门深度学习的小伙伴们,可以了解下本博主的其它基础内容:
🏠我的个人主页
🚀深度学习入门基础CNN系列——卷积计算
🌟深度学习入门基础CNN系列——填充(padding)与步幅(stride)
😊深度学习入门基础CNN系列——感受野和多输入通道、多输出通道以及批量操作基本概念
🚀 深度学习入门基础CNN系列——池化(Pooling)和Sigmoid、ReLU激活函数
一、批归一化(Batch Normalization)
批归一化方法(Batch Normalization,BatchNorm)是由Ioffe和Szegedy于2015年提出的,已被广泛应用在深度学习中,其目的是对神经网络中间层的输出进行标准化处理,使得中间层的输出更加稳定。
通常我们会对神经网络的数据进行标准化处理,处理后的样本数据集满足均值为0,方差为1的统计分布,这是因为当输入数据的分布比较固定时,有利于算法的稳定和收敛。对于深度神经网络来说,由于参数是不断更新的,即使输入数据已经做过标准化处理,但是对于比较靠后的那些层,其接收到的输入仍然是剧烈变化的,通常会导致数值不稳定,模型很难收敛。BatchNorm能够使神经网络中间层的输出变得更加稳定,并有如下三个优点:
- 使学习快速进行(能够使用较大的学习率)
- 降低模型对初始值的敏感性
- 从一定程度上抑制过拟合
1. 数据分布和模型的数值稳定性
模型收敛: 需要稳定的数据分布
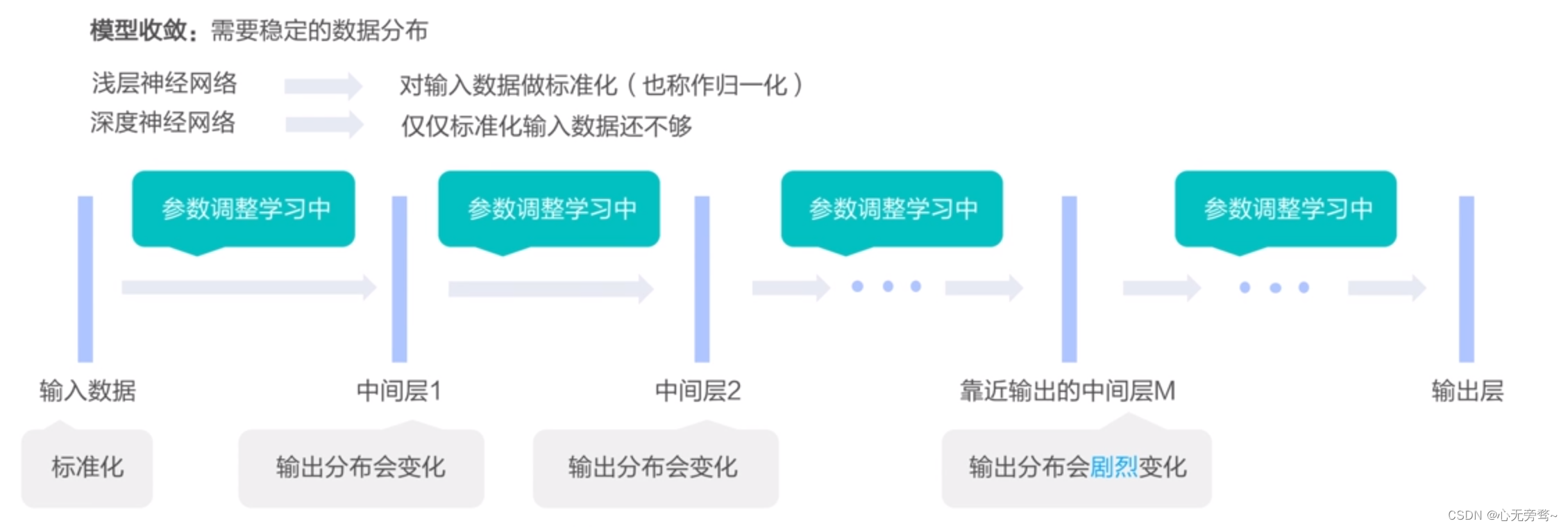
- 前面M层网络的参数一直在调整学习中,即是输入数据是标准化了,但是中间层M的数值分布却一直在剧烈地变化着。
- 将M到输出层之间的部分看作是一个浅层神经网络,那么对于这个浅层神经网络而言,它观察到的输入数据的分布是不稳定的,那么模型稳定性就会受到影响。
因此为了解决数据分布不稳定的问题,我们可以使用批归一化(Batch Normalization,简称BatchNorm)对中间层的输出做标准化,这样就可以保证在网络学习的过程中,网络层的输出具有稳定的分布。
2. 批归一化BatchNorm——计算过程

-
计算mini-batch内样本的均值
μ B ← 1 m ∑ i = 1 m x ( i ) \mu_{B}\leftarrow \frac{1}{m}\sum^{m}_{i=1}{x^{(i)}} μB←m1i=1∑mx(i)
其中 x ( i ) x_{(i)} x(i)表示mini-batch中的第 i i i个样本。
例如输入mini-batch包含3个样本,每个样本有2个特征,分别是(此处都用向量表示):
x ( 1 ) = ( 1 , 2 ) , x ( 2 ) = ( 3 , 6 ) , x ( 3 ) = ( 5 , 10 ) x^{(1)}=(1,2),\ x^{(2)}=(3,6),\ x^{(3)}=(5,10) x(1)=(1,2), x(2)=(3,6), x(3)=(5,10)
对每个特征分别计算mini-batch内样本的均值:
μ B 0 = 1 + 3 + 5 3 = 3 , μ B 1 = 2 + 6 + 10 3 = 6 \mu_{B0}=\frac{1+3+5}{3}=3,\ \mu_{B1}=\frac{2+6+10}{3}=6 μB0=31+3+5=3, μB1=32+6+10=6
则样本均值是:
μ B = ( μ B 0 , μ B 1 ) = ( 3 , 6 ) \mu_{B}=(\mu_{B0},\mu_{B1})=(3,6) μB=(μB0,μB1)=(3,6) -
计算mini-batch内样本的方差(方差为样本特征减去均值)
σ B 2 ← 1 m ∑ i = 1 m ( x ( i ) − μ B ) 2 \sigma^2_{B}\leftarrow \frac{1}{m}\sum^{m}_{i=1}(x^{(i)}-\mu_{B})^2 σB2←m1i=1∑m(x(i)−μB)2
上面的计算公式先计算一个批次内样本的均值 μ B \mu_{B} μB和方差 σ B 2 \sigma^2_{B} σB2,然后再对输入数据做归一化,将其调整成均值为0,方差为1的分布。对于上述给定的输入数据 x ( 1 ) , x ( 2 ) , x ( 3 ) x^{(1)},\ x^{(2)}, \ x^{(3)} x(1), x(2), x(3),可以计算出每个特征对应的方差,详细如下:
σ B 0 2 = 1 3 ( ( 1 − 3 ) 2 + ( 3 − 3 ) 2 + ( 5 − 3 ) 2 ) = 8 3 σ B 1 2 = 1 3 ( ( 2 − 6 ) 2 + ( 6 − 6 ) 2 + ( 10 − 6 ) 2 ) = 32 3 \begin{align} \sigma^2_{B0}=\frac{1}{3}((1-3)^2+(3-3)^2+(5-3)^2)=\frac{8}{3} \\ \sigma^2_{B1}=\frac{1}{3}((2-6)^2+(6-6)^2+(10-6)^2)=\frac{32}{3} \end{align} σB02=31((1−3)2+(3−3)2+(5−3)2)=38σB12=31((2−6)2+(6−6)2+(10−6)2)=332
则样本方差是:
σ B 2 = ( σ B 0 2 , σ B 1 2 ) = ( 8 3 , 32 3 ) \sigma^2_{B}=(\sigma^2_{B0},\sigma^2_{B1})=(\frac{8}{3},\frac{32}{3}) σB2=(σB02,σB12)=(38,332) -
计算标准化之后的输出
x ^ ( i ) ← x ( i ) − μ B ( σ B 2 + ε ) \hat{x}^{(i)}\leftarrow \frac{x^{(i)}-\mu_{B}}{\sqrt{(\sigma^2_{B}+\varepsilon)}} x^(i)←(σB2+ε)x(i)−μB
其中 ε \varepsilon ε是一个微小值(例如 1 e − 7 1e-7 1e−7),其主要作用是为了防止分母为0。
对于上述给定的输入数据 x ( 1 ) , x ( 2 ) , x ( 3 ) x^{(1)},\ x^{(2)}, \ x^{(3)} x(1), x(2), x(3),可以计算出标准化之后的输出:

我们可以自行验证由 x ^ ( 1 ) , x ^ ( 2 ) , x ^ ( 3 ) \hat{x}^{(1)}, \hat{x}^{(2)},\hat{x}^{(3)} x^(1),x^(2),x^(3)构成的mini-batch,是否满足均值为0,方差为1的分布。
但是我们仅仅对样本特征进行归一化是远远不够的,因为如果强行限制输出层的分布式标准化的,可能会导致某些特征模式的丢失,所以在标准化之后,BatchNorm会紧接着对数据做缩放和平移。
y i ← γ x ^ i + β y_{i}\leftarrow \gamma \hat{x}_{i}+\beta yi←γx^i+β
其中 γ 和 β \gamma和\beta γ和β是可学习的参数,可以赋初始值 γ = 1 , β = 0 \gamma=1,\beta=0 γ=1,β=0,在训练过程中不断学习调整,经过上面的式子算出的 y i y_{i} yi才是最终的输出。
3. 计算举例
这里我们使用飞桨paddle框架做示范。
示例一:当输入数据形状是 [ N , K ] [N, K] [N,K]时,一般对应全连接层的输出,示例代码如下所示。这种情况下会分别对K的每一个分量计算N个样本的均值和方差,数据和参数对应如下:
- 输入 x , [ N , K ] x, [N,K] x,[N,K]
- 输出 y , [ N , K ] y,[N,K] y,[N,K]
- 均值 μ B , [ K , ] \mu_{B},[K,] μB,[K,]
- 方差 σ B 2 , [ K , ] \sigma^2_{B},[K,] σB2,[K,]
- 缩放参数 γ , [ K , ] \gamma,[K,] γ,[K,]
- 平移参数 β , [ K , ] \beta,[K,] β,[K,]
# 输入数据形状是 [N, K]时的示例
import numpy as np
import paddle
from paddle.nn import BatchNorm1D
# 创建数据
data = np.array([[1,2,3], [4,5,6], [7,8,9]]).astype('float32')
# 使用BatchNorm1D计算归一化的输出
# 输入数据维度[N, K],num_features等于K
bn = BatchNorm1D(num_features=3)
x = paddle.to_tensor(data)
y = bn(x)
print('output of BatchNorm1D Layer: \n {}'.format(y.numpy()))
# 使用Numpy计算均值、方差和归一化的输出
# 这里对第0个特征进行验证
a = np.array([1,4,7])
a_mean = a.mean()
a_std = a.std()
b = (a - a_mean) / a_std
print('std {}, mean {}, \n output {}'.format(a_mean, a_std, b))
# 输出结果如下
# 使用飞桨paddle实现的输出
output of BatchNorm1D Layer:
[[-1.2247438 -1.2247438 -1.2247438]
[ 0. 0. 0. ]
[ 1.2247438 1.2247438 1.2247438]]
#
std 4.0, mean 2.449489742783178,
output [-1.22474487 0. 1.22474487]
细心的我们可以发现使用飞桨的框架输出的结果中归一化输出的值要比numpy输出的归一化的值要小一点点,例如1.2247438和1.22474487,虽然只是小数点后面好几位的差距,但是可以体现出分母加 ε \varepsilon ε的作用。如果我们numpy中也在下面加上 ε \varepsilon ε,那么输出结果便会一致了。
示例二:当输入数据形状是 [ N , C , H , W ] [N, C, H, W] [N,C,H,W]时, 一般对应卷积层的输出,示例代码如下所示。这种情况下会沿着C这一维度进行展开,分别对每一个通道计算N个样本中总共 N × H × W N×H×W N×H×W个像素点的均值和方差,数据和参数对应如下:
- 输入 x , [ N , C , H , W ] x, [N,C,H,W] x,[N,C,H,W]
- 输出 y , [ N , C , H , W ] y,[N,C,H,W] y,[N,C,H,W]
- 均值 μ B , [ C , ] \mu_{B},[C,] μB,[C,]
- 方差 σ B 2 , [ C , ] \sigma^2_{B},[C,] σB2,[C,]
- 缩放参数 γ , [ C , ] \gamma,[C,] γ,[C,]
- 平移参数 β , [ C , ] \beta,[C,] β,[C,]
小窍门:
可能有读者会问:“BatchNorm里面不是还要对标准化之后的结果做仿射变换吗,怎么使用Numpy计算的结果与BatchNorm算子一致?” 这是因为BatchNorm算子里面自动设置初始值
γ
=
1
,
β
=
0
\gamma=1,\beta=0
γ=1,β=0,这时候仿射变换相当于是恒等变换。在训练过程中这两个参数会不断的学习,这时仿射变换就会起作用。
# 输入数据形状是[N, C, H, W]时的batchnorm示例
import numpy as np
import paddle
from paddle.nn import BatchNorm2D
# 设置随机数种子,这样可以保证每次运行结果一致
np.random.seed(100)
# 创建数据
data = np.random.rand(2,3,3,3).astype('float32')
# 使用BatchNorm2D计算归一化的输出
# 输入数据维度[N, C, H, W],num_features等于C
bn = BatchNorm2D(num_features=3)
x = paddle.to_tensor(data)
y = bn(x)
print('input of BatchNorm2D Layer: \n {}'.format(x.numpy()))
print('output of BatchNorm2D Layer: \n {}'.format(y.numpy()))
# 取出data中第0通道的数据,
# 使用numpy计算均值、方差及归一化的输出
a = data[:, 0, :, :]
a_mean = a.mean()
a_std = a.std()
b = (a - a_mean) / a_std
print('channel 0 of input data: \n {}'.format(a))
print('std {}, mean {}, \n output: \n {}'.format(a_mean, a_std, b))
# 输出结果如下
# 提示:这里通过numpy计算出来的输出
# 与BatchNorm2D算子的结果略有差别,
# 因为在BatchNorm2D算子为了保证数值的稳定性,
# 在分母里面加上了一个比较小的浮点数epsilon=1e-05
4. 预测时使用BatchNorm
上面介绍了在训练过程中使用BatchNorm对一批样本进行归一化的方法,但如果使用同样的方法对需要预测的一批样本进行归一化,则预测结果会出现不确定性。
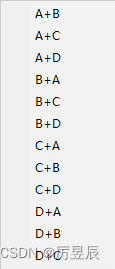
例如样本A、样本B作为一批样本计算均值和方差,与样本A、样本C和样本D作为一批样本计算均值和方差,得到的结果一般来说是不同的。那么样本A的预测结果就会变得不确定,这对预测过程来说是不合理的。解决方法是在训练过程中将大量样本的均值和方差保存下来,预测时直接使用保存好的值而不再重新计算。实际上,在BatchNorm的具体实现中,训练时会计算均值和方差的移动平均值。在飞桨Paddle中,默认是采用如下方式计算:
s
a
v
e
d
μ
B
←
s
a
v
e
d
μ
B
×
0.9
+
μ
B
×
(
1
−
0.9
)
s
a
v
e
d
σ
B
2
←
s
a
v
e
d
σ
B
2
×
0.9
+
σ
B
2
×
(
1
−
0.9
)
\begin{align} saved\mu_{B}\leftarrow saved\mu_{B} \times 0.9+\mu_{B}\times(1-0.9)\\ saved\sigma^2_{B}\leftarrow saved\sigma^2_{B} \times 0.9+\sigma^2_{B}\times(1-0.9) \end{align}
savedμB←savedμB×0.9+μB×(1−0.9)savedσB2←savedσB2×0.9+σB2×(1−0.9)
在训练过程的最开始将
s
a
v
e
d
μ
B
和
s
a
v
e
d
σ
B
2
saved\mu_{B}和saved\sigma^2_{B}
savedμB和savedσB2设置为0,每次输入一批新的样本,计算出
μ
B
和
σ
B
2
\mu_{B}和\sigma^2_{B}
μB和σB2,然后通过上面的公式更新
s
a
v
e
d
μ
B
和
s
a
v
e
d
σ
B
2
saved\mu_{B}和saved\sigma^2_{B}
savedμB和savedσB2,在训练的过程中不断的更新它们的值,并作为BatchNorm层的参数保存下来。预测的时候将会加载参数
s
a
v
e
d
μ
B
和
s
a
v
e
d
σ
B
2
saved\mu_{B}和saved\sigma^2_{B}
savedμB和savedσB2,用他们来代替
μ
B
和
σ
B
2
\mu_{B}和\sigma^2_{B}
μB和σB2。
二、丢弃法(Dropout)
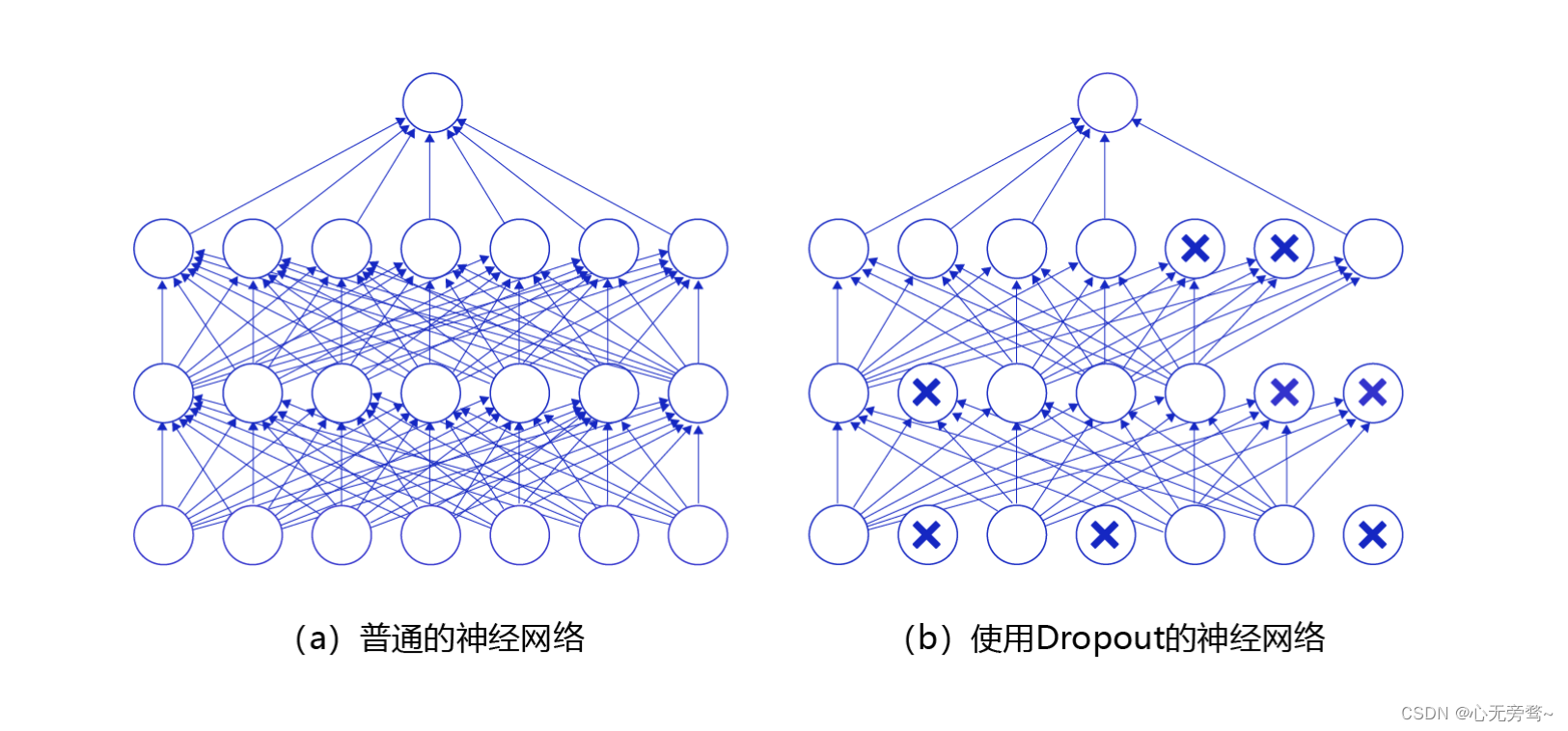
丢弃法(Dropout)是深度学习中一种常用的抑制过拟合的方法,其做法是在神经网络学习过程中,随机删除一部分神经元。训练时,随机选出一部分神经元,将其输出设置为0,这些神经元将不对外传递信号。
下图是Dropout示意图,左边是完整的神经网络,右边是应用了Dropout之后的网络结构。应用Dropout之后,会将标了
×
\times
×的神经元从网络中删除,让它们不向后面的层传递信号。在学习过程中,丢弃哪些神经元是随机决定,因此模型不会过度依赖某些神经元,能一定程度上抑制过拟合。
在预测场景时,会向前传递所有神经元的信号,可能会引出一个新的问题:训练时由于部分神经元被随机丢弃了,输出数据的总大小会变小。比如:计算其
L
1
L1
L1范数会比不使用Dropout时变小,但是预测时却没有丢弃神经元,这将导致训练和预测时数据的分布不一样。为了解决这个问题,飞桨Paddle支持如下两种方法:
- downscale_in_infer
训练时以比例 r r r随机丢弃一部分神经元,不向后传递它们的信号;预测时向后传递所有神经元的信号,但是将每个神经元上的数值乘以 1 − r 1-r 1−r。 - upscale_in_train
训练时以比例 r r r随机丢弃一部分神经元,不向后传递它们的信号,但是将那些被保留的神经元上的数值除以 1 − r 1-r 1−r预测时向后传递所有神经元的信号,不做任何处理。
在飞桨Dropout API中,通过mode参数来指定用哪种方式对神经元进行操作。
paddle.nn.Dropout(p=0.5, axis=None, mode="upscale_in_train”, name=None)
主要参数如下:
- p (float) :将输入节点置为0的概率,即丢弃概率,默认值:0.5。该参数对元素的丢弃概率是针对于每一个元素而言,而不是对所有的元素而言。举例说,假设矩阵内有12个数字,经过概率为0.5的dropout未必一定有6个零。
- axis (int|list):指定对输入 Tensor 进行 Dropout 操作的轴。默认:None。
- mode(str) :丢弃法的实现方式,有’downscale_in_infer’和’upscale_in_train’两种,默认是’upscale_in_train’。
注意: 不同框架对于dropout的默认处理方式不同,比如pytorch中的torch.nn.dropout()中只有p和inplace两个参数。其中p参数的含义和飞桨Paddle一致,而inplace参数的含义是:如果设置为True,将就地执行此操作。默认值:假。详细可以查看各个框架的API进行了解。
下面这段程序展示了经过Dropout之后输出数据的形式。
# dropout操作
import paddle
import numpy as np
# 设置随机数种子,这样可以保证每次运行结果一致
np.random.seed(100)
# 创建数据[N, C, H, W],一般对应卷积层的输出
data1 = np.random.rand(2,3,3,3).astype('float32')
# 创建数据[N, K],一般对应全连接层的输出
data2 = np.arange(1,13).reshape([-1, 3]).astype('float32')
# 使用dropout作用在输入数据上
x1 = paddle.to_tensor(data1)
# downgrade_in_infer模式下
drop11 = paddle.nn.Dropout(p = 0.5, mode = 'downscale_in_infer')
droped_train11 = drop11(x1)
# 切换到eval模式。在动态图模式下,使用eval()切换到求值模式,该模式禁用了dropout。
drop11.eval()
droped_eval11 = drop11(x1)
# upscale_in_train模式下
drop12 = paddle.nn.Dropout(p = 0.5, mode = 'upscale_in_train')
droped_train12 = drop12(x1)
# 切换到eval模式
drop12.eval()
droped_eval12 = drop12(x1)
x2 = paddle.to_tensor(data2)
drop21 = paddle.nn.Dropout(p = 0.5, mode = 'downscale_in_infer')
droped_train21 = drop21(x2)
# 切换到eval模式
drop21.eval()
droped_eval21 = drop21(x2)
drop22 = paddle.nn.Dropout(p = 0.5, mode = 'upscale_in_train')
droped_train22 = drop22(x2)
# 切换到eval模式
drop22.eval()
droped_eval22 = drop22(x2)
print('x1 {}, \n droped_train11 \n {}, \n droped_eval11 \n {}'.format(data1, droped_train11.numpy(), droped_eval11.numpy()))
print('x1 {}, \n droped_train12 \n {}, \n droped_eval12 \n {}'.format(data1, droped_train12.numpy(), droped_eval12.numpy()))
print('x2 {}, \n droped_train21 \n {}, \n droped_eval21 \n {}'.format(data2, droped_train21.numpy(), droped_eval21.numpy()))
print('x2 {}, \n droped_train22 \n {}, \n droped_eval22 \n {}'.format(data2, droped_train22.numpy(), droped_eval22.numpy()))
在此由于输出结果太长,我只截图一部分。

以上全部代码实现都是基于飞桨AI Studio平台,任何用户上去都会送免费算力,可以直接使用平台的服务器跑代码。
飞桨AI Studio平台链接:https://aistudio.baidu.com/aistudio/projectoverview/public
✨ 原创不易,还希望各位大佬支持一下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下
👍 点赞,你的认可是我创作的动力! \textcolor{green}{点赞,你的认可是我创作的动力!} 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向! \textcolor{green}{收藏,你的青睐是我努力的方向!} 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富! \textcolor{green}{评论,你的意见是我进步的财富!} 评论,你的意见是我进步的财富!