关联项目需求
进行FeatureAB上报的时候,我们使用HashSet的add方法存key值,如果key已存在,则add失败,返回false,如果key不存在,add成功,返回true。
看源码中HashSet的add(E e)方法实现:

HashSet#add
底层还是使用的hashMap的put(E e,Object o)方法。
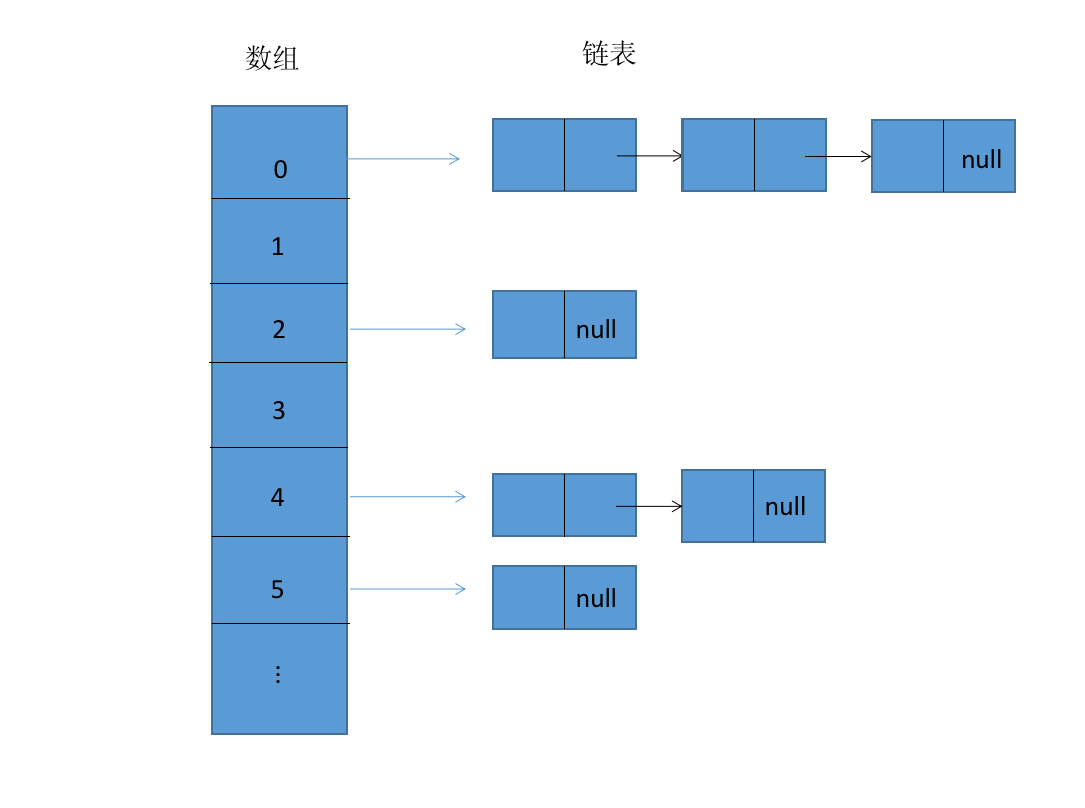
HashMap的结构:
使用数组的结构存链表(或树)的节点
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
...
}
hashMap结构:
HashMap的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}hashMap#put
实际上调用的是putVal方法:
储备知识点:
移位运算:左移 1 << 4 == 1*24 数组的初始容量为16
String内容一样,他们的hashCode也一样
按位与运算:00 1111 1111 & 11 0000 0000 和 00 1111 1111 & 10 0000 0000 结果一样都为0
哈希碰撞原理:上面的例子里11 0000 0000和10 0000 0000 代表的hash值不同,但是都放入同一个下标的数组里
定义的一些字段所表示的含义:
table是一组头结点数组
n赋值为数组长度
i = (n - 1) & hash按位与求出该key所在头结点数组的位置(哈希碰撞)
p为找到的头结点
e为最终找到的key对应的节点
TREEIFY_THRESHOLD为8
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; //n为数组长度
if ((p = tab[i = (n - 1) & hash]) == null) //(n - 1) & hash按位与求出该key所在头结点数组的位置
tab[i] = newNode(hash, key, value, null); //没有找到时,链表新创建一个节点
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; //头结点就是对应key的节点,p为头节点
else if (p instanceof TreeNode) //p如果是个二叉树节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //链表长度达到一定长度时会转为树结构
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { // 找到下一个节点,下一个节点为空则新建一个节点插入(hashCode一样,key不一样)
p.next = newNode(hash, key, value, null); //新建一个节点
if (binCount >= TREEIFY_THRESHOLD - 1) // 节点数大于8转为树结构
//这里binCount从0开始,binCount = 7时,节点数为9
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key,如果有存在的节点
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //给节点的value赋值
afterNodeAccess(e);
return oldValue; //返回原有的value
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}HashMap#putVal

hashMap结构:
put方法总结:(结合代码和图)
如果key所在数组位置头结点没有值,则新加一个头结点,返回上一个节点null
如果key所在的数组位置头结点有值,且头结点key和要插入的key一致则将头结点取出,将value值改为新的value,返回上一个节点
如果key所在的数组位置头结点有值,且头结点key和要插入的key不一致,则查找链表或树里key对应的节点,取出节点将value值改为新的value,返回上一个节点
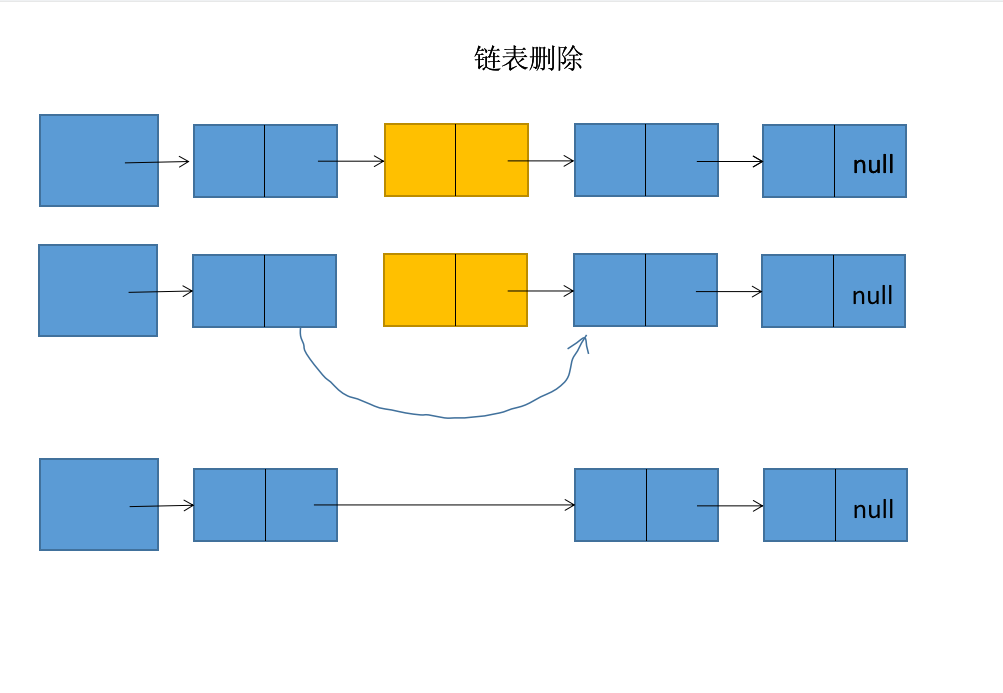
HashMap的remove方法
remove方法实际是调用的removeNode方法
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}HashMap#remove
一些字段所表示的含义:
index 为要删除的节点在数组下标的位置
node为要删除的节点
remove 方法matchValue是false、value是null
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) { //key所在的数组有值,p赋值头结点
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) //如果头结点就是所要找的节点
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key); //下一个节点是树形结构,找到对应节点
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) { //找到链表里key对应的节点
node = e;
break;
}
p = e;
} while ((e = e.next) != null); //没找到则循环查找下一个节点
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) { //找到的node不为空
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); //树形结构删除节点
else if (node == p)
tab[index] = node.next; //如果找到的node是头结点,将头结点的next指向node的下一个节点
else
p.next = node.next; //不是头节点,使用链表删除方法删除节点
++modCount;
--size;
afterNodeRemoval(node);
return node; //把找到要删除的节点返回
}
}
return null;
}
HashMap的get方法
get方法相对简单,原理也就是在链表里查找或树里查找
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { //找到key对应数组下标的头结点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first; //如果头结点key和查找的key一样则返回头结点
if ((e = first.next) != null) { //找下一个节点
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key); //是树形结构则从树里找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e; //在链表里挨个查找下一个,直到key匹配
} while ((e = e.next) != null);
}
}
return null; //啥也没找到返回null
}思考:
这里留给大家思考两个数据结构的问题
为什么是数组+链表(树)的结构?
为什么要转成树形结构?