PPT:第二章P176;
合并为一个新的整体:有序表的合并(有序,可重复)
线性表:
对于该操作的具体实现的流程设计:(各模块)
- 创建一个空表C
依次从A或B(中)“摘取”元素值较小的结点插入到C表的最后,直至其
中一表变空
继续将A或B其中一表的剩余结点插入C表的最后
模块一:
对于这里的模块一,我们需要进行的:
建一个新表来返回两表合并后的结果(最终合并后的表)的操作的整个学习过程与问题,详见:
数据结构与算法基础(王卓)(8)附:关于new的使用方法详解part 2;
而在本程序中,我们使用的语句,即:
C.elem = new Elemtype[100]; 模块二:
其中,模块二的流程实现,又具体细分为:
- 摘取两表中元素值较小的结点
- 将结点插入到C表的结尾
- 重复循环“1”、“2”步操作,直至其中一表变为空为止
project1:
//不用指针,直接硬钢判断语句
int i = 0,//对应A表
j = 0,//对应B表
k = 0;//对应C表
while (i < A.length || j < B.length)
{
if (A.elem[i] > B.elem[j])
{
C.elem[k] = B.elem[i];
i++;
k++;
}
if (A.elem[i] == B.elem[j])
{
C.elem[k] = A.elem[i];
C.elem[++k] = B.elem[j];
i++;
j++;
k++;
}
else// if (A.elem[i] < B.elem[j])
{
C.elem[k] = A.elem[i];
i++;
k++;
}
//当然,也可以先大于小于再等于说明:
(1):
在模块二中,两表相比较的两结点元素值都相等的语句,也可以写为:
if (A.elem[i] == B.elem[j])
{
C.elem[k] = A.elem[i];
C.elem[++k] = B.elem[j];
i++;
j++;
k++;
}(2):
需要注意(记住),本来(一开始),对于循环执行(的)判断语句,我们本来想写为
while(A.elem[i] != 0 || B.elem[j] != 0)然而,结果显示:

首先,第一点确定无疑的事情(结论)就是:
在这里,我们的程序不能完成该语句中的“!=”判断
在这里,想要程序能够成功实现执行该判断,我们可以有如下两种解决办法:
- 手撸一个关于<Poly类型> != <int类型>的判断定义表达式
- 定义结点为空时,该空节点的内容;即:定义一个这样的空结点
当然,要真这么写,可以是也可以,但是太过麻烦,我们这里就不选择这种方法了
project 2:(利用线性表地址线性排列存储的性质)
//利用指针
Poly* pa, * pb, * pc;
pa = A.elem;
pb = B.elem;
pc = C.elem;
//*pa = A.elem[0];
//*pb = B.elem[0];
while (pa <= &A.elem[A.length - 1] || pb < &B.elem[B.length - 1])
{
if (*pa > *pb)
{
*pc = *pb;
pa++;
pc++;
}
if (*pa == *pb)
{
*pc = *pa;
*(++pc) = *pb;
pa++;
pb++;
pc++;
}
else
{
*pc = *pa;
pa++;
pc++;
}模块三:
if (A.length > B.length)
{
//while (i < A.length) 同理,后面不再赘述
while (pa <= &A.elem[A.length - 1])
{
*pc = *pa;
pc++;
pa++;
}
}
else
{
while (pb <= &B.elem[B.length - 1])
{
*pc = *pb;
pc++;
pb++;
}
}最终修改打磨:
根据(参考)PPT(178)中的标准答案,我们发现以下地方仍有修改的空间:
模块一:
一方面:
我们没有给新建的C表的length元素赋值
另一方面:
C表的长度是A表和B表两表长度的总和
如果还是只是固定的,像开辟和A表B表一样的固定为100的大小的空间,未免有些不妥:
C.length = A.length + B.length;
C.elem = new Elemtype[C.length];另外,模块二这里我们写的限定条件:
while (pa <= &A.elem[A.length - 1] || pb < &B.elem[B.length - 1])写成:
while (pa <= A.elem + A.length - 1 || pb < B.elem + B.length - 1)也同理(一样);(标准答案就是按后者这么写的,但我感觉这么写倒也没有什么特别过人之处)
但是另一个问题就严重了:
在C++中:
与:&&
或:||
非:!
所以应该改为:
while (pa <= A.elem + A.length - 1 && pb < B.elem + B.length - 1)或者:
while (pa <= &A.elem[A.length - 1] && pb < &B.elem[B.length - 1])另外:
在模块二中关于这个循环的循环体,我写的倒是也没有什么大的错误
但是太过累赘,还是标准答案上写的更加简洁和方便
当然他其实没有我写的那么严谨:具体写出两节点元素值相等时的操作流程,可以让循环次数减少
但是从大的时间复杂度的角度来说,其实n次循环和(n-5)次循环本质上没有太大区别
所以这里我们还是选择标准答案上的写法:
while (pa <= &A.elem[A.length - 1] && pb < &B.elem[B.length - 1])
{
if (*pa < *pb)
*pc++ = *pa++;
else
*pc++ = *pb++;
}该写法,即:
先(给C表中最后的结点(*pc))赋值,再自增;一个语句实现
最后,关于模块三:
其实我们不用在去设置看A和B哪个表更长的判断语句
因为其实我们即使直接写两个循环语句,依然不影响程序的运行
因为一个表的指针已经到达该表的尾结点以后,自然就不符合该循环的循环判断条件:
while (pa <= &A.elem[A.length - 1])
和
while (pb <= &B.elem[B.length - 1])
了,另外,这里的函数体,我们也可以写为像上面一样的“先(给C表中最后的结点(*pc))赋值,再自增;”的形式:
while (pa <= &A.elem[A.length - 1])
{
*pc++ = *pa++;
}
while (pb <= &B.elem[B.length - 1])
{
*pc++ = *pb++;
}综上:
关于线性表的:有序表的合并(有序,可重复)操作如下:
int Merge(Sqlist A, Sqlist B, Sqlist& C)
{//合并; 融入; (使)结合; 并入; 相融;
typedef Poly Elemtype;
C.length = A.length + B.length;
C.elem = new Elemtype[C.length];
//利用指针
Poly* pa, * pb, * pc;
pa = A.elem;
pb = B.elem;
pc = C.elem;
//*pa = A.elem[0];
//*pb = B.elem[0];
while (pa <= &A.elem[A.length - 1] && pb < &B.elem[B.length - 1])
{
if (*pa < *pb)
*pc++ = *pa++;
else
*pc++ = *pb++;
}
//
while (pa <= &A.elem[A.length - 1])
{
*pc++ = *pa++;
}
while (pb <= &B.elem[B.length - 1])
{
*pc++ = *pb++;
}
//
return true;
}链表:
project 1:
int Merge(LinkList &A, LinkList& B, LinkList& C )
{
//给指针赋初值
LinkList
pa = A->next,
//注意:这里的指针指向的是AB表的首元结点而不是头结点
pb = B->next,
pc = C = A;
//pc = A;
//pc = &C = A;
//比较并插入
while(pa&&pb)
//while (pa->next!=0&& pa->next != 0)
{
if (pb->data > pa->data)
{
pc->next = pa;
pa = pa->next;
//pc = pc->next;
}
else
{
pc->next = pb;
pb = pb->next;
}
}
//插入剩余段
while(pa||pb)
{
pa ? pa : pb;
}
//返回操作成功信号
return true;
}另外:
struct K
{
float a;
int b;
string c;
bool operator==(K& t)
{
return t.a == a && t.b == b;
//&& t.c = c;
}
bool operator!=(K& t)
{
return t.a != a || t.b != b;
//|| t.c = c;
}
bool operator>(K& t)
{
return t.a > a && t.b > b;
//&& t.c = c;
}
bool operator<(K& t)
{
return t.a < a || t.b < b;
//|| t.c = c;
}
};issues:
一、
关于
pc = C = A;
//pc = A;
//pc = &C = A;(1):连续赋值表达式???
pc = C = A; 相当于: pc =(C = A); <C++书P25>
(2):注释里的两种样式(形式)为什么不行?
1、
pc = A;如果我们这样写,最终就会导致:
我们鼓捣(写)了半天的新表,最后和表C,或者说我们这里指向表C的指针&C(C的首地址)
没有任何联系(关系),即:
创建是创建了一个新的合并以后的有序表,但是根本没有办法返回回去,新建了个寂寞
2、
pc = &C = A;结果:
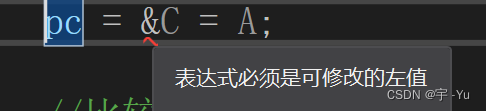
这里其实又可以联系到(1)中的问题,其中:
C表示的是Lnode类型的表C的头指针,也可以看做是一个LinkList类型的指针
而在对其取址操作以后,&C则表示这个LinkList类型的指针的地址
这个指针的地址是一个已经固定不变的值(常量)
而常量(一个固定的值)肯定是不能被别的任何变量所赋值的,所以报错自然也就是情理之中的事了
另外,同样的:
我们不要以为这个常量(不可改变的值)在表达式的最左侧(表达式的运行)就没事了
除了常量必须放在最左侧以外,同时我们还需要注意类型的统一:

同样的,在这里,我们对前面一直搅和了我们半天的LinkList &A等格式进行一个系统性的总结:
&A代表的到底是什么??
Lnode A:链表结点类型的变量A
Lnode &A:还是表示链表结点类型的变量A,但是(只是)表示采用引用传值的传值方式
LinkList A:指向目标对象为 链表结点类型的指针变量ALinkList &A:还是表示指向目标对象为 链表结点类型的指针变量A
只是
表示采用引用传值的传值方式传达(递)这个地址
二、
关于循环判断语句
while(pa&&pb)
//while (pa->next!=0&& pa->next != 0)为什么这里只要判断指针的值是否为0就可以决定程序是否执行循环?
你怎么知道程序对后面没有赋值的空结点所安排的地址都是0呢???
首先:
我们这里(至少目前)还无法判断还无法判断语句
//while (pa->next!=0&& pa->next != 0)
是否可行,而语句
while(pa&&pb)
则只是简单地表示:
如果pa和pb都为真,不为假(为空),那么程序就执行,否则就不执行
不存在这里0和假有什么关系关联的问题,当然,0是否就能代表为假,这个也是值得我们去了解(搜索)的问题
关于循环体:
循环体的执行的流程:
把元素值较小的结点接在表C的末尾(最后,下一个)
让C表(新表)的指针指向我们刚刚在C表新插入的结点
(因为之后的结点,都插入在新插入的结点之后了)
让指向 刚刚被提取元素的表 的指针 指向该表的下一个结点
我们在写循环体的过程当中,一方面:
每插入一个结点以后,修改的都是指向A表B表的指针,而不是指向C表的指针:
pa = pa->next;
//pc = pc->next;最重要的是:
我们忘了我们这里写的循环体的步骤的第二步:pc = pa / pb ;
而且实际上在真正操作的时候,第二步不能写在第三步之前!!!
三、
别忘了最后结束之前还有一步:
delete B;最终project:
int Merge(LinkList &A, LinkList& B, LinkList& C)
{
//给指针赋初值
LinkList
pa = A->next,
//注意:这里的指针指向的是AB表的首元结点而不是头结点
pb = B->next,
pc = C = A;
//比较并插入
while(pa&&pb)
{
if (pb->data > pa->data)
{
pc->next = pa;
pc = pa;
pa = pa->next;
}
else
{
pc->next = pb;
pc = pb;
pb = pb->next;
}
}
//插入剩余段
while(pa||pb)
{
pa ? pa : pb;
}
delete B;
//返回操作成功信号
return true;
}END