前言
- 数据来自于
kaggle比赛Ventilator Pressure Prediction,数据背景介绍请看官方说明 - 代码来自于当前排名第一的团队
Shujun, Kha, Zidmie, Gilles, B,他们在获得第一名的成绩以后发了一篇博客,提供了他们在比赛中使用的模型,包括LSTM CNN transformer、PID Controller Matching、Simple LSTM - 该篇博客主要对
Simple LSTM做解读,代码写的非常好,包含了一个完整的解决方案、从数据准备、可视化、模型搭建、交叉检验、测试、提交测试文件。 - 我针对该代码可能缺失的功能做了一定补充,比如数据内存优化、利用
tensorboard可视化训练过程、早停功能、数据最大最小归一化。
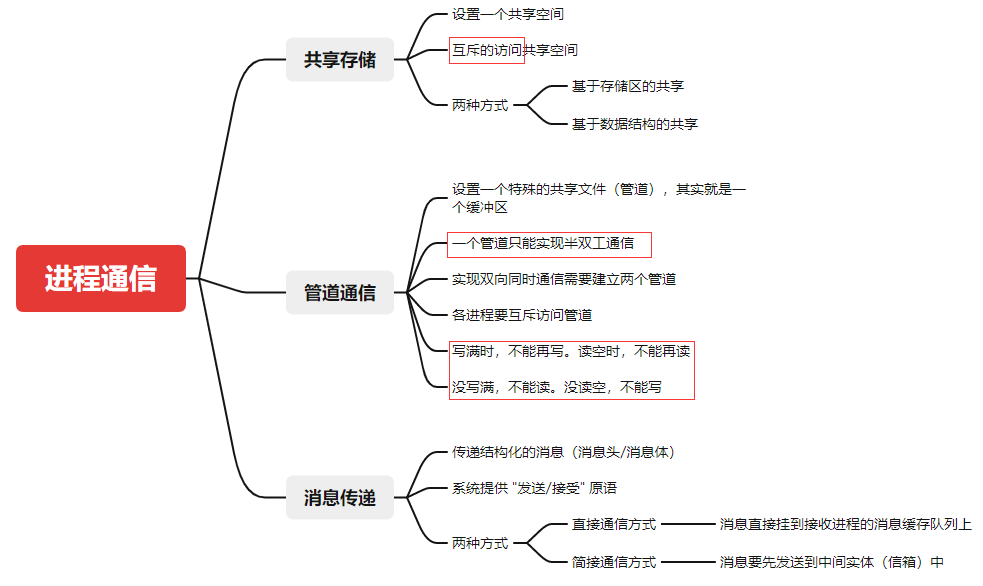
数据特征说明
id:整个文件中全局唯一的时间步长标识符breath_id:全局唯一的呼吸时间步骤R:肺部气道受限程度(单位: c m H 2 O / L / S cm H_2O/L/S cmH2O/L/S)。在物理学上,每一次的空气量的压力变化。我们可以想象通过吸管吹起一个气球。我们可以通过改变吸管的直径来改变 R R R, R R R越高就越难吹。C:肺部顺应性程度(单位: m L / c m H 2 O mL/cm H_2O mL/cmH2O)。从物理上讲,每一个压力变化所带来的体积变化。直观地说,我们可以想象同一个气球的例子。我们可以通过改变气球乳胶的厚度来改变C,C越高,乳胶越薄,越容易吹。time_step:实际时间戳u_in:吸气式电磁阀的控制输入,范围从0到100。u_out:探索性电磁阀的控制输入,取值为0或1。pressure:呼吸回路中测量的气道压力,单位为 c m H 2 O cm H_2O cmH2O。
代码解析
导入必要包
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
from collections import Counter
import optuna
from IPython.display import display
from sklearn.metrics import mean_absolute_error as mae
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split, GroupKFold
import torch
import torch.nn as nn
from torch import optim
from torch.utils.data import Dataset
from torchvision import datasets
from torch.utils.data import DataLoader
from transformers import get_linear_schedule_with_warmup
import gc
import os
import time
import warnings
import random
warnings.filterwarnings("ignore")
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('/kaggle/working/runs_info/')
数据可视化及准备
数据内存优化
- 通过更改数据默认数据格式,尽可能选择小的满足精度要求的数据类型,这样可以减小数据占用空间
def read_csv(file_name):
return pd.read_csv(file_name, encoding='utf-8')
def reduce_mem_usage(df, verbose=True):
start_mem = df.memory_usage().sum() / 1024**2
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
train_file = '../input/ventilator-pressure-prediction/train.csv'
test_file = '../input/ventilator-pressure-prediction/test.csv'
train_data = reduce_mem_usage(read_csv(train_file))
test_data = reduce_mem_usage(read_csv(test_file))
df = train_data[train_data['breath_id'] < 5].reset_index(drop=True)
输出:
Memory usage after optimization is: 97.86 MB
Decreased by 73.4%
Memory usage after optimization is: 57.56 MB
Decreased by 73.2%
可视化数据
- 定义可视化函数,各呼吸步骤的
pressure变化趋势
def plot_sample(sample_id, df):
df_breath = df[df['breath_id'] == sample_id]
r, c = df_breath[['R', 'C']].values[0]
cols = ['u_in', 'u_out', 'pressure'] if 'pressure' in df.columns else ['u_in', 'u_out']
plt.figure(figsize=(12, 4))
for col in ['u_in', 'u_out', 'pressure']:
plt.plot(df_breath['time_step'], df_breath[col], label=col)
plt.legend()
plt.title(f'Sample {sample_id} - R={r}, C={c}')
for i in df['breath_id'].unique():
plot_sample(i, train_data)
- 部分可视化展示:


数据处理
- 使用最大最小归一化方法,对测试以及训练数据进行归一化。
def data_scaler(train,test):
# 训练数据
temp_train = train.drop(labels=['id','breath_id','pressure'], axis=1)
# 测试数据
temp_test = test.drop(labels=['id','breath_id'], axis=1)
# 最大最小归一化
scaler = MinMaxScaler()
scaler = scaler.fit(temp_train)
# 训练集归一化数据
train_scaler = scaler.transform(temp_train)
# 测试集归一化数据
test_scaler = scaler.transform(temp_test)
# 将训练、测试集转换为DataFrame格式
train_scaler = pd.DataFrame(train_scaler)
test_scaler = pd.DataFrame(test_scaler)
# 继承列名
train_scaler.columns = temp_train.columns
test_scaler.columns = temp_test.columns
# 添加id列
for i in ['id','breath_id','pressure']:
train_scaler[i] = train[i]
for i in ['id','breath_id']:
test_scaler[i] = test[i]
# 调整列顺序
train_scaler = train_scaler[list(train_data.columns)]
test_scaler = test_scaler[list(test_data.columns)]
del (temp_train, temp_test)
# 释放内存
gc.collect()
return train_scaler,test_scaler
# 训练、测试归一化
train_data,test_data = data_scaler(train_data,test_data)
- 定义
Datasets,整理输入、输出:
class TimeDataset(Dataset):
def __init__(self, df):
# 如果pressure列不在数据中
if "pressure" not in df.columns:
# 添加列pressure并将其置为0
df['pressure'] = 0
# 按'breath_id'列进行分组,并将每个特征的所有取值放在一个列表中,重置索引
self.df = df.groupby('breath_id').agg(list).reset_index()
# 数据预处理步骤
self.prepare_data()
def __len__(self):
# 数据样本量
return self.df.shape[0]
def prepare_data(self):
# 将pressure列由多维list转换为数组
# pressures、rs、cs、u_int、u_ins维度均为(75450, 80)
self.pressures = np.array(self.df['pressure'].values.tolist())
rs = np.array(self.df['R'].values.tolist())
cs = np.array(self.df['C'].values.tolist())
u_ins = np.array(self.df['u_in'].values.tolist())
self.u_outs = np.array(self.df['u_out'].values.tolist())
# 特征增加一个维度,如(75450,80) --> (75450,1,80)
# 沿维度1拼接,拼接完后维度为(75450,5,80)
# 维度转置((75450,5,80) --> (75450,80,5),即(batch, seq, feature)
self.inputs = np.concatenate([
rs[:, None],
cs[:, None],
u_ins[:, None],
np.cumsum(u_ins, 1)[:, None],
self.u_outs[:, None]
], axis = 1).transpose(0, 2, 1)
def __getitem__(self, idx):
data = {
"input": torch.tensor(self.inputs[idx], dtype=torch.float),
"u_out": torch.tensor(self.u_outs[idx], dtype=torch.float),
"p": torch.tensor(self.pressures[idx], dtype=torch.float),
}
return data
- 检查
Datasets正确性,输出input shape: torch.Size([80, 5]), u_out: torch.Size([80]), p: torch.Size([80]),正确无误
dataset = TimeDataset(train_data)
print('input shape: %s, u_out: %s, p: %s'%(dataset[0]['input'].shape,dataset[0]['u_out'].shape,dataset[0]['p'].shape))
模型架构
- 模型由全连接层、LSTM层、全连接层组成,输入格式为
[batch,seq_len,feature],为方便大家理解,我用tensorboard可视化了模型框架

class LSTMNet(nn.Module):
def __init__(self,input_dim=5,lstm_dim=256,dense_dim=256,logit_dim=256,num_classes=1,):
super().__init__()
# 全连接层
self.mlp = nn.Sequential(
nn.Linear(input_dim, dense_dim // 2),
nn.ReLU(),
nn.Linear(dense_dim // 2, dense_dim),
nn.ReLU(),
)
# LSTM连接层,输出格式(batch, seq, feature),双向连接
self.lstm = nn.LSTM(dense_dim, lstm_dim, batch_first=True, bidirectional=True)
# 全连接层
self.logits = nn.Sequential(
nn.Linear(lstm_dim * 2, logit_dim),
nn.ReLU(),
nn.Linear(logit_dim, num_classes),
)
def forward(self, x):
features = self.mlp(x)
features, _ = self.lstm(features)
pred = self.logits(features)
return pred
固定随机种子
- 固定随机种子方便复现网络
# 固定随机种子
def seed_everything(seed):
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
保存模型
# 保存模型权重
def save_model_weights(model, filename, verbose=1, cp_folder=""):
if verbose:
print(f"\n -> Saving weights to {os.path.join(cp_folder, filename)}\n")
torch.save(model.state_dict(), os.path.join(cp_folder, filename))
模型评估函数
# 模型度量参数
def compute_metric(df, preds):
y = np.array(df['pressure'].values.tolist())
w = 1 - np.array(df['u_out'].values.tolist())
assert y.shape == preds.shape and w.shape == y.shape, (y.shape, preds.shape, w.shape)
mae = w * np.abs(y - preds)
mae = mae.sum() / w.sum()
return mae
定义损失函数
# 定义损失函数
class VentilatorLoss(nn.Module):
def __call__(self, preds, y, u_out):
w = 1 - u_out
mae = w * (y - preds).abs()
mae = mae.sum(-1) / w.sum(-1)
return mae
早停策略
# 早停策略
class EarlyStopping:
def __init__(self, patience=10, verbose=False, delta=0):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
def __call__(self, val_loss):
score = -val_loss
if self.best_score is None:
self.best_score = score
elif score < self.best_score + self.delta:
self.counter += 1
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.counter = 0
模型训练函数
def fit(model,train_dataset,val_dataset,optimizer="Adam",epochs=50,batch_size=32,val_bs=32,warmup_prop=0.1,lr=1e-3,num_classes=1,verbose=1,first_epoch_eval=0,device="cuda"):
# 可视化模型
writer.add_graph(model, input_to_model = torch.rand((1,80,5)).to(device))
# 平均验证集损失
avg_val_loss = 0.
# 设置优化器
optimizer = getattr(torch.optim, optimizer)(model.parameters(), lr=lr)
# 加载训练集
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
pin_memory=True,
)
# 加载验证集
val_loader = DataLoader(
val_dataset,
batch_size=val_bs,
shuffle=False,
pin_memory=True,
)
# 损失函数
loss_fct = VentilatorLoss()
# 学习更新策略(warmup)
num_warmup_steps = int(warmup_prop * epochs * len(train_loader))
num_training_steps = int(epochs * len(train_loader))
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps, num_training_steps
)
# 早停策略
early_stopping = EarlyStopping(patience = 20, verbose=True)
for epoch in range(epochs):
# 将模型置于train模式
model.train()
# 梯度清零
model.zero_grad()
# 记录开始时间
start_time = time.time()
# 平均损失
avg_loss = 0
# 取数据
for data in train_loader:
# 得到输出,并去除最后维度值为1的维度
pred = model(data['input'].to(device)).squeeze(-1)
# 计算该批平均损失
loss = loss_fct(
pred,
data['p'].to(device),
data['u_out'].to(device),
).mean()
# 反向传播
loss.backward()
avg_loss += loss.item() / len(train_loader)
# 更新优化器和学习率
optimizer.step()
scheduler.step()
for param in model.parameters():
param.grad = None
# 将模型置为评估模式
model.eval()
# 将mae和ang_val_loss置为0
mae, avg_val_loss = 0, 0
# 预测列表
preds = []
# 不用计算梯度
with torch.no_grad():
for data in val_loader:
# 得到输出,并去除最后维度值为1的维度
pred = model(data['input'].to(device)).squeeze(-1)
# 计算损失
loss = loss_fct(
pred.detach(),
data['p'].to(device),
data['u_out'].to(device),
).mean()
avg_val_loss += loss.item() / len(val_loader)
# 将预测值加入列表中
preds.append(pred.detach().cpu().numpy())
# 将预测值拼接
preds = np.concatenate(preds, 0)
mae = compute_metric(val_dataset.df, preds)
# 计算模型运行时间
elapsed_time = time.time() - start_time
# 打印间隔
if (epoch + 1) % verbose == 0:
elapsed_time = elapsed_time * verbose
lr = scheduler.get_last_lr()[0]
print(
f"Epoch {epoch + 1:02d}/{epochs:02d} \t lr={lr:.1e}\t t={elapsed_time:.0f}s \t"
f"loss={avg_loss:.3f}",
end="\t",
)
if (epoch + 1 >= first_epoch_eval) or (epoch + 1 == epochs):
print(f"val_loss={avg_val_loss:.3f}\tmae={mae:.3f}")
else:
print("")
# 记录训练、验证集损失、学习率、线性层直方图
writer.add_scalar('train_loss', avg_loss, global_step=epoch+1)
writer.add_scalar('valid_loss', avg_val_loss, global_step=epoch+1)
writer.add_scalar('learning_rate', scheduler.get_last_lr()[0], global_step=epoch+1)
writer.close()
# 仅记录logits层权重以及偏置
for name, param in model.logits.named_parameters():
writer.add_histogram(name, param.data.to('cpu').numpy(), epoch+1)
early_stopping(mae)
if early_stopping.early_stop:
print("Early stopping")
break
# 删除数据加载器以及变量
del (val_loader, train_loader, loss, data, pred)
# 释放内存
gc.collect()
torch.cuda.empty_cache()
# 输出预测值
return preds
模型预测函数
# 预测函数
def predict(model,dataset,batch_size=64,device="cuda"):
# 将模型置为评估模式
model.eval()
# 加载数据
loader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
# 预测列表
preds = []
# 不计算梯度
with torch.no_grad():
# 取数据
for data in loader:
pred = model(data['input'].to(device)).squeeze(-1)
preds.append(pred.detach().cpu().numpy())
# 预测值拼接
preds = np.concatenate(preds, 0)
return preds
模型准备函数
# 训练函数
def train(config, df_train, df_val, df_test, fold):
# 固定随机种子
seed_everything(config.seed)
# 定义模型
model = LSTMNet(
input_dim=config.input_dim,
lstm_dim=config.lstm_dim,
dense_dim=config.dense_dim,
logit_dim=config.logit_dim,
num_classes=config.num_classes,
).to(config.device)
# 梯度清零
model.zero_grad()
# 加载数据
train_dataset = TimeDataset(df_train)
val_dataset = TimeDataset(df_val)
test_dataset = TimeDataset(df_test)
# 统计模型参数量
n_parameters = count_parameters(model)
print(f" -> {len(train_dataset)} training breathes")
print(f" -> {len(val_dataset)} validation breathes")
print(f" -> {n_parameters} trainable parameters\n")
# 训练模型并在验证集上评估模型效果
pred_val = fit(
model,
train_dataset,
val_dataset,
optimizer=config.optimizer,
epochs=config.epochs,
batch_size=config.batch_size,
val_bs=config.val_bs,
lr=config.lr,
warmup_prop=config.warmup_prop,
verbose=config.verbose,
first_epoch_eval=config.first_epoch_eval,
device=config.device,
)
# 在测试集上输出预测值
pred_test = predict(
model,
test_dataset,
batch_size=config.val_bs,
device=config.device
)
# 保存模型权重
if config.save_weights:
save_model_weights(
model,
f"{config.selected_model}_{fold}.pt",
cp_folder="",
)
# 删除模型、训练集加载器、验证集加载器、测试集加载器
del (model, train_dataset, val_dataset, test_dataset)
# 释放内存
gc.collect()
torch.cuda.empty_cache()
return pred_val, pred_test
定义交叉检验函数
# 交叉检验函数
def k_fold(config, df, df_test):
# 初始化pred数组
pred_oof = np.zeros(len(df))
preds_test = []
# 进行几折交叉检验
gkf = GroupKFold(n_splits=config.k)
# 分组交叉检验
splits = list(gkf.split(X=df, y=df, groups=df["breath_id"]))
# 交叉检验循环
for i, (train_idx, val_idx) in enumerate(splits):
if i in config.selected_folds:
print(f"\n------------- Fold {i + 1} / {config.k} -------------\n")
# 得到训练与验证数据
df_train = df.iloc[train_idx].copy().reset_index(drop=True)
df_val = df.iloc[val_idx].copy().reset_index(drop=True)
# 训练模型
pred_val, pred_test = train(config, df_train, df_val, df_test, i)
#将验证集、测试集预测数组展平
pred_oof[val_idx] = pred_val.flatten()
preds_test.append(pred_test.flatten())
# 输出信息
print(f'\n -> CV MAE : {compute_metric(df, pred_oof) :.3f}')
return pred_oof, np.mean(preds_test, 0)
参数设定类
class Config:
# General
seed = 42
verbose = 20
device = "cuda" if torch.cuda.is_available() else "cpu"
save_weights = True
# k-fold
k = 5
selected_folds = [0, 1, 2, 3, 4]
# Model
selected_model = 'rnn'
input_dim = 5
dense_dim = 512
lstm_dim = 512
logit_dim = 512
num_classes = 1
# Training
optimizer = "AdamW"
batch_size = 128
epochs = 400
lr = 1e-3
warmup_prop = 0
val_bs = 256
first_epoch_eval = 0
训练
pred_oof, pred_test = k_fold(Config, train_data, test_data,)
- 这里因为内容限制,仅输出第1折运行信息:
------------- Fold 1 / 5 -------------
-> 60360 training breathes
-> 15090 validation breathes
-> 4860929 trainable parameters
Epoch 20/400 lr=9.5e-04 t=515s loss=0.808 val_loss=0.794 mae=0.796
Epoch 40/400 lr=9.0e-04 t=516s loss=0.648 val_loss=0.679 mae=0.682
Epoch 60/400 lr=8.5e-04 t=517s loss=0.549 val_loss=0.587 mae=0.589
Epoch 80/400 lr=8.0e-04 t=517s loss=0.492 val_loss=0.550 mae=0.552
Epoch 100/400 lr=7.5e-04 t=515s loss=0.437 val_loss=0.511 mae=0.512
Epoch 120/400 lr=7.0e-04 t=515s loss=0.401 val_loss=0.520 mae=0.522
Epoch 140/400 lr=6.5e-04 t=515s loss=0.368 val_loss=0.464 mae=0.465
Epoch 160/400 lr=6.0e-04 t=515s loss=0.344 val_loss=0.452 mae=0.453
Epoch 180/400 lr=5.5e-04 t=516s loss=0.321 val_loss=0.432 mae=0.434
Epoch 200/400 lr=5.0e-04 t=516s loss=0.307 val_loss=0.411 mae=0.412
Epoch 220/400 lr=4.5e-04 t=515s loss=0.281 val_loss=0.405 mae=0.406
Epoch 240/400 lr=4.0e-04 t=515s loss=0.268 val_loss=0.408 mae=0.409
Epoch 260/400 lr=3.5e-04 t=514s loss=0.252 val_loss=0.388 mae=0.389
Epoch 280/400 lr=3.0e-04 t=515s loss=0.240 val_loss=0.380 mae=0.382
Epoch 300/400 lr=2.5e-04 t=514s loss=0.229 val_loss=0.388 mae=0.389
Epoch 320/400 lr=2.0e-04 t=520s loss=0.213 val_loss=0.373 mae=0.374
Epoch 340/400 lr=1.5e-04 t=517s loss=0.202 val_loss=0.368 mae=0.370
Epoch 360/400 lr=1.0e-04 t=514s loss=0.191 val_loss=0.367 mae=0.368
Epoch 380/400 lr=5.0e-05 t=513s loss=0.182 val_loss=0.365 mae=0.366
Epoch 400/400 lr=0.0e+00 t=515s loss=0.174 val_loss=0.362 mae=0.363
-> Saving weights to rnn_0.pt
结果对比
定义绘图函数
def plot_prediction(sample_id, df):
df_breath = df[df['breath_id'] == sample_id]
cols = ['u_in', 'u_out', 'pressure'] if 'pressure' in df.columns else ['u_in', 'u_out']
plt.figure(figsize=(12, 4))
for col in ['pred', 'pressure', 'u_out']:
plt.plot(df_breath['time_step'], df_breath[col], label=col)
metric = compute_metric(df_breath, df_breath['pred'])
plt.legend()
plt.title(f'Sample {sample_id} - MAE={metric:.3f}')
-
观察模型效果,如图


-
观察模型预测效果,如图


![[C/C++]对象指针](https://img-blog.csdnimg.cn/0ae170c7c92b40febed6a553c7df9a7a.png)