🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊往期回顾:CV攻城狮入门VIT(vision transformer)之旅——近年超火的Transformer你再不了解就晚了! CV攻城狮入门VIT(vision transformer)之旅——VIT原理详解篇 CV攻城狮入门VIT(vision transformer)之旅——VIT代码实战篇
🍊近期目标:写好专栏的每一篇文章
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
Swin Transformer代码实战篇
写在前面
上一篇我们已经介绍了Swin Transformer的原理,对此还不了解的点击☞☞☞了解详情。此篇文章参考B站UP霹雳吧啦Wz 的视频,大家若对Swin Transformer代码没有一点基础,建议先去观看视频。有一说一,这位UP的视频质量做的是真高,到目前为止,我已经不知道推荐过多少次了。但是呢,这部分视频时间确实长,有的地方也难以听懂,所以我听了20分钟就听不下去了,于是自己慢慢的调试起代码,这个过程挺漫长也挺难的,但是你坚持下来就会有所收获。当然了,光靠我慢慢摸索代码并没有把整个框架都弄清楚,仍然存在许多搞不明白的地方。这时候我就又观看了一篇视频,二刷的感觉明显不一样,UP说到的点基本都能理解了。但还是存在一些疑难杂症,后来又进一步调试摸索,最后基本都弄明白了。🥤🥤🥤
说这些,只是为大家提供一个学习代码的路线,具体怎么做,还是仁者见仁智者见智,只要找到最符合你习惯的就好。这篇文章不会把每句代码都讲的十分详细,重点会挑一些我觉得理解起来有一定难度,UP也没有细讲的点,所以此篇文章和UP主的视频更配喔!!!🍟🍟🍟
准备好了嘛,开始发车!!!🚖🚖🚖
模型整体设计框架
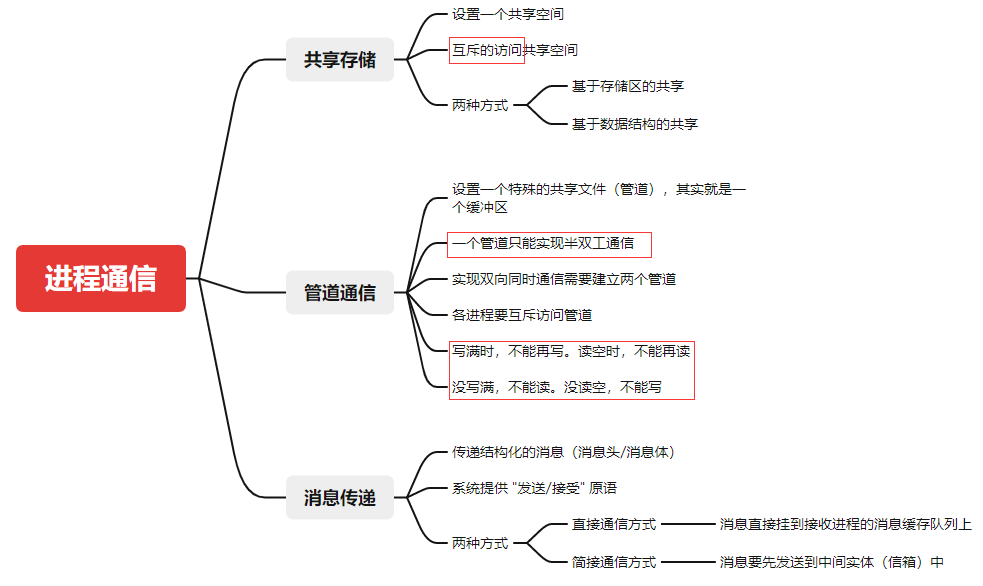
为方便大家理解代码,我画出了代码中几个关键的类,如下图:

首先,最大的一个类就是SwinTransformer,它定义了整个Swin Transformer的框架。接着是BasicLayer类,它是Swin Transformer Block和Patch Merging的组合。【注意,代码中是Swin Transformer Block+patch merging组合在一起,而不是理论部分的Patch merging+Swin Transformer Block】 然后是SwinTransformer Block类,它定义了Swin Transformer的结构。还有一个是WindowAttention类,它定义了W-MSA和SW-MSA结构。
Patch partition+Linear Embedding实现
和ViT相同,这部分采用一个卷积实现,代码如下:
## 定义PatchEmbed类
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=None):
super().__init__()
patch_size = (patch_size, patch_size)
self.patch_size = patch_size
self.in_chans = in_c
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) #定义卷积
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
_, _, H, W = x.shape
# padding
# 如果输入图片的H,W不是patch_size的整数倍,需要进行padding
pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)
if pad_input:
# to pad the last 3 dimensions,
# (W_left, W_right, H_top,H_bottom, C_front, C_back)
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],
0, self.patch_size[0] - H % self.patch_size[0],
0, 0))
# 下采样patch_size倍
x = self.proj(x)
_, _, H, W = x.shape
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
Patch Merging实现
这部分原理在上一篇已经详细介绍,代码如下:
## 定义PatchMerging类
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
"""
x: B, H*W, C
"""
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
# padding
# 如果输入feature map的H,W不是2的整数倍,需要进行padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
# to pad the last 3 dimensions, starting from the last dimension and moving forward.
# (C_front, C_back, W_left, W_right, H_top, H_bottom)
# 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]
x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]
x = self.norm(x)
x = self.reduction(x) # [B, H/2*W/2, 2*C]
return x
关于这部分,稍难理解的是这部分代码,如下图所示:

这几行代码就对应我们理论部分所说的划分成四个小patch。以x0 = x[:, 0::2, 0::2, :]为例,它表示取所以Batch和Chanel的数据,从H的第0位和W的第0位开始取,行列都每隔两个取一个数据。其它三个表达的含义类似。
上面这样解释不知道大家能否听懂,我再举个例子,代码如下:【这里忽略了Batch和Chanel维度】
import torch
x= [[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]]
x = torch.tensor(x)
这样我们定义了一个四行四列的元素,来看一下其结果:
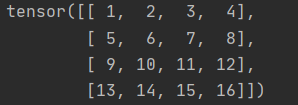
接着,我们对上述x进行切片,代码如下:
x0 = x[0::2, 0::2]
x1 = x[1::2, 0::2]
x2 = x[0::2, 1::2]
x3 = x[1::2, 1::2]
此时,我们来看看x0、x1、x2、x3的输出结果,如下图所示:

相信通过这个例子大家就一目了然了。🥂🥂🥂
SW-MSA
这部分我主要讲讲窗口移动的代码,其实就一行,如下图所示:
x = torch.roll(shifted_x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
这行代码到底干了什么呢?我们同样以一个例子来讲解,如下:
import torch
x= [[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]]
x = torch.tensor(x)
先定义一个四行四列的元素,我们打印出x看一看:
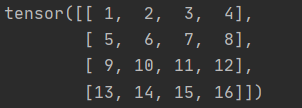
接着我们执行这行代码:
shifted_x1 = torch.roll(x, shifts=(-1, -1), dims=(0, 1))
来看看输出的shifted_x1结果:

是不是发现就是先将x的第一行移动到最后一行,然后将第一列移动到最后一列的结果呢。是不是发现代码实现这一步非常的简单呢。至于self.shift_size为 ⌊ M 2 ⌋ \left\lfloor {\frac{{\rm{M}}}{2}} \right\rfloor ⌊2M⌋,M为窗口大小。【注意:只有在SW-MSA是才使用此步骤】
我们在理论部分谈到,执行完SW-MSA后,要将移动后的窗口还原回去,代码也很简单,就是一个反向的移动,如下:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
我们在来通过刚刚的例子理解一下:
shifted_x2 = torch.roll(shifted_x1, shifts=(1, 1), dims=(0, 1))
来看看输出的shifted_x2结果:
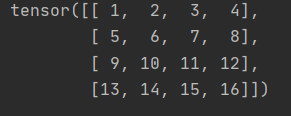
会发现shifted_x2和原始的x是一致的!!!🥗🥗🥗
训练结果展示
以下结果为花的五分类训练结果:
- 使用预训练模型:
swin_tiny_patch4_window7_224.pth,一共训练10轮,结果如下:

- 使用预训练模型:
swin_base_patch4_window7_224_in22k,一共训练10轮,结果如下:

- 不使用预训练模型:
swin_base_patch4_window7_224_in22k,一共训练10轮,结果如下:

通过上面几个实验可以看出,swin Transformer的效果还是很不错的,特别是使用了预训练模型后。
我也在swin transformer的代码中尝试加上可学习的位置编码,发现效果较之前也有一定的提升,如下:
- 使用预训练模型:
swin_tiny_patch4_window7_224.pth,一共训练10轮 ,加入可学习位置编码。

小结
这部分就写这么多了,用文字来讲解代码感觉确实有难度,所以后期可能会打算出一些视频教学,当然这都是后话了。本篇其实主要就为大家整理了两个点,通过两个例子帮助大家进行理解。其它的内容相信你通过调试或者看我推荐的视频是可以解决的,最后希望大家学有所成。🌼🌼🌼
参考链接
使用Pytorch搭建Swin-Transformer网络 🍁🍁🍁
如若文章对你有所帮助,那就🛴🛴🛴