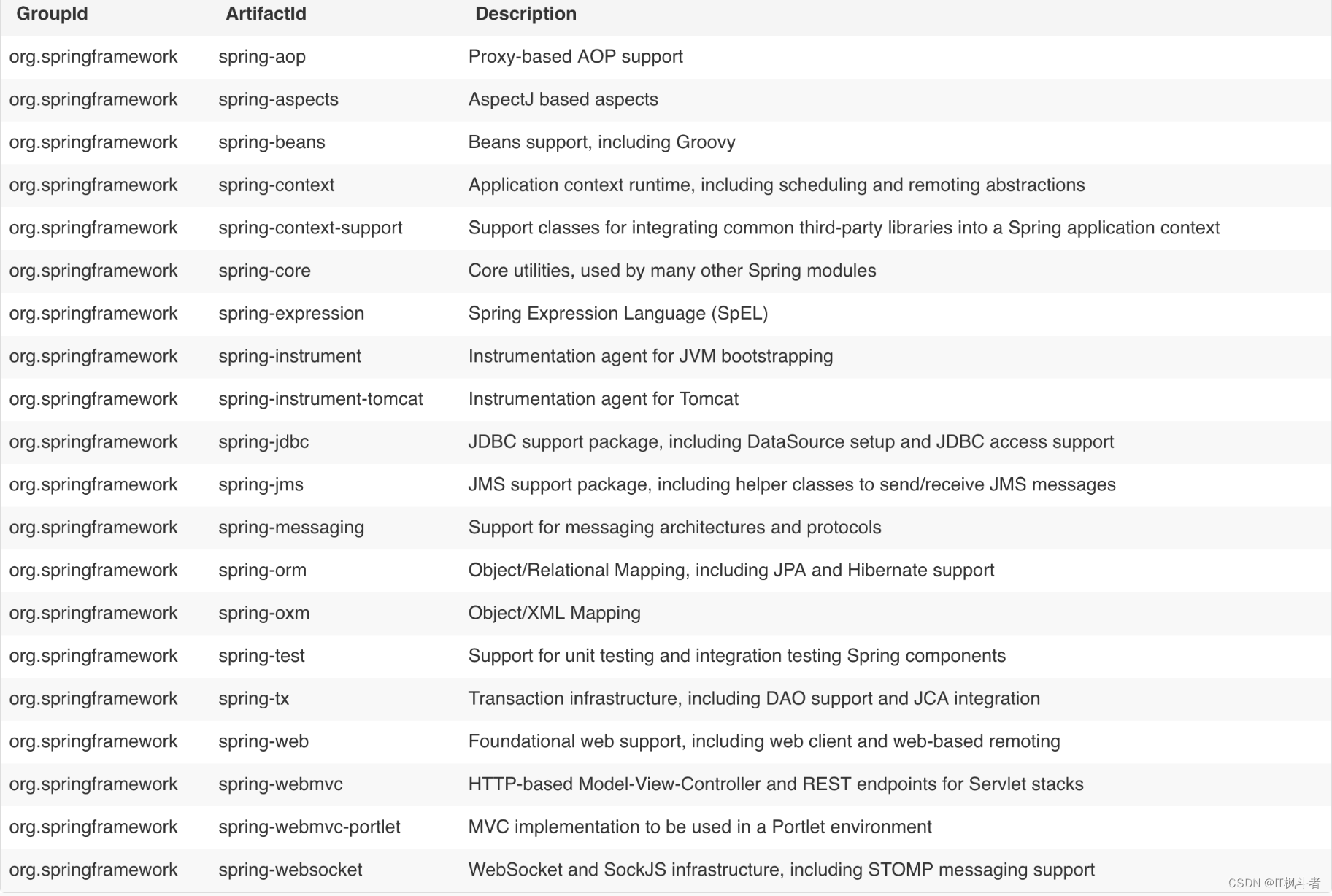
Prometheus 版本 2.41.0
- 平台统一监控的介绍和调研
- 直观感受PromQL及其数据类型
- PromQL之选择器和运算符
- PromQL之函数
PromQL 聚合函数
PromQL 的聚合函数只能用于瞬时向量,支持的聚合函数有:
- sum 求和
- min 最小值
- max 最大值
- avg 平均值
- group 分组,并设置值为1
- stddev 标准差
- stdvar 标准差异
- count 计数
- count_values 对value进行计数
- bottomk 样本值最小的k个元素
- topk 样本值最大的k个元素
- quantile 分布统计
另外通过 without 和 by 可以保留不同纬度的数据。
语法:
<aggr-op> [without|by (<label list>)] ([parameter,] <vector expression>)
或者
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
without
删除指定标签,保留剩余标签
示例:
原始数据:

删除 instance 标签,保留其他的标签
sum(jvm_memory_used_bytes) without(instance)
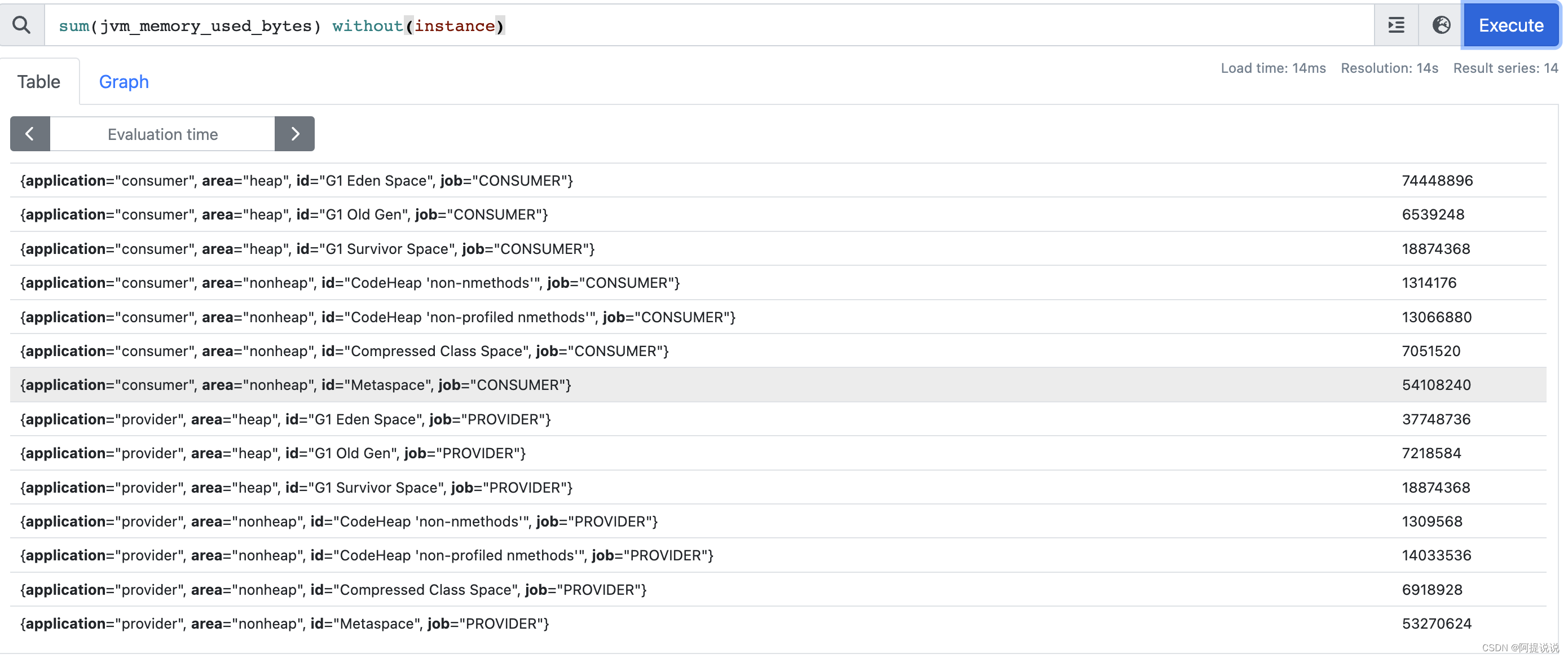
without 不包含标签,与jvm_memory_used_bytes 等价
sum(jvm_memory_used_bytes) without()
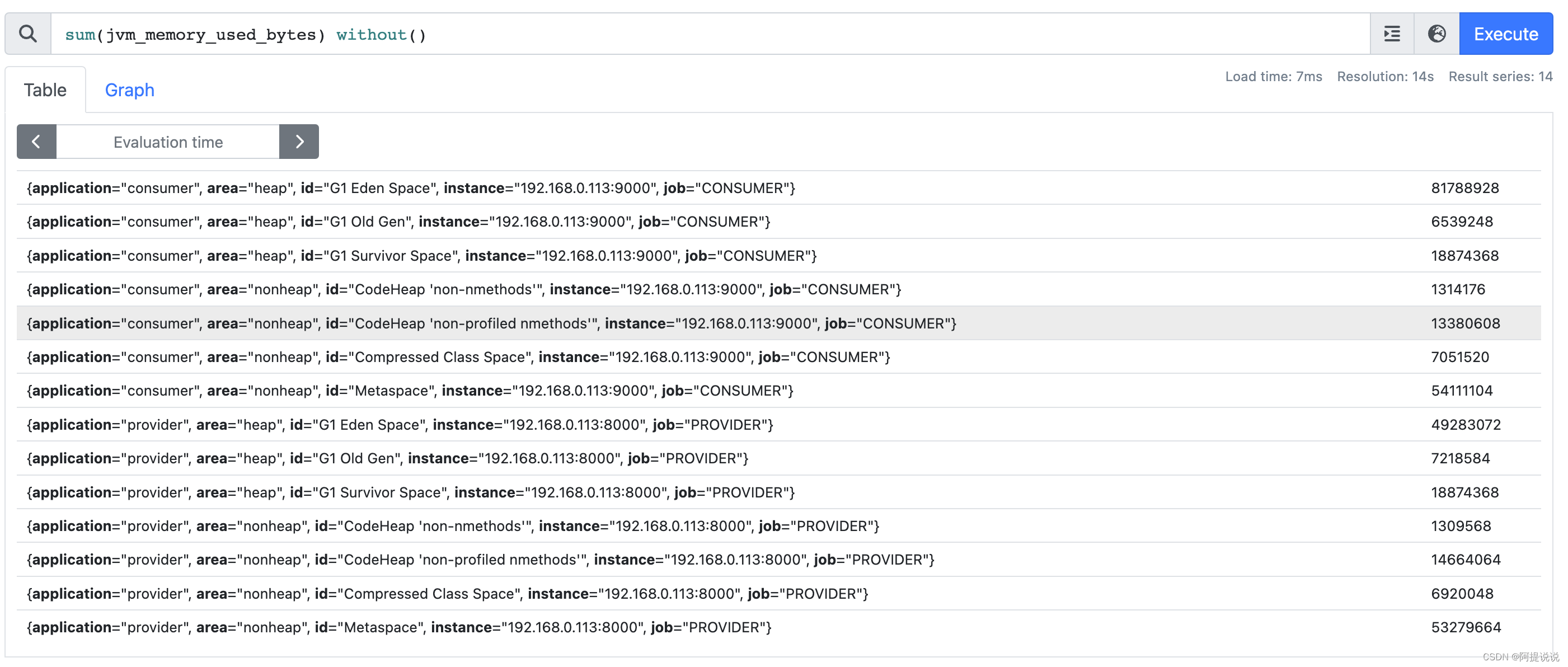
without 生成的是一个基于原始指标聚合计算后的新指标
by
保留指定标签,删除其他标签
示例:
只保留 instance 标签
sum(jvm_memory_used_bytes) by(instance)

by 不包含标签,跟 sum(jvm_memory_used_bytes) 等价
sum(jvm_memory_used_bytes) by()

by 生成的是一个基于原始指标聚合计算后的新指标
sum
最常见的聚合函数,将分组中所有值相加并返回。
示例:
计算每个应用的已占用的堆内存和非堆内存,单位MB
sum(jvm_memory_used_bytes) by(application,area) /1024 /1024
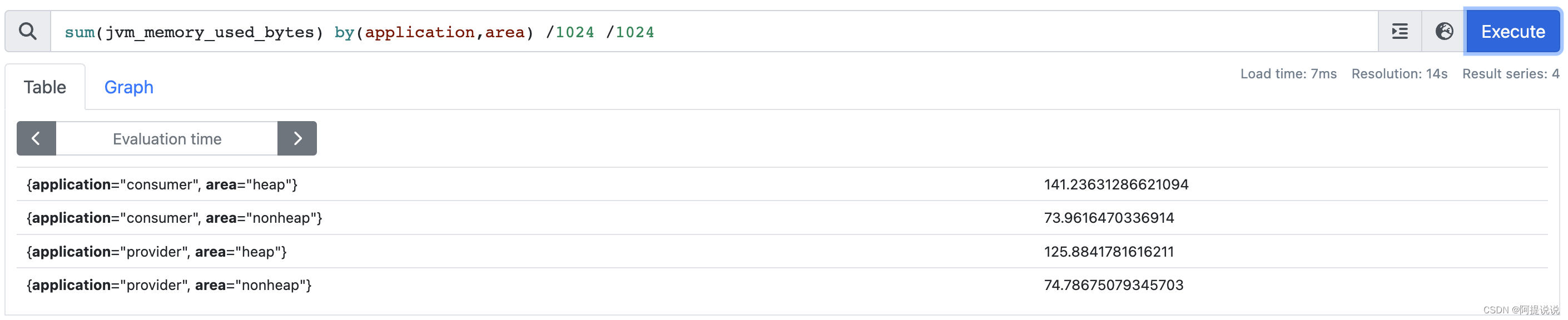
看到consumer 应用的堆占用内存为 141MB,我们不使用by 来查询一下,比较下两者:
sum(jvm_memory_used_bytes{application="consumer",area="heap"}) / 1024 /1024

同样 consumer 应用的堆占用内存为 141MB
min
返回分组内的最小值作为这个分组的返回值
示例:
返回堆内存占用最小的样本,单位MB
min(jvm_memory_used_bytes{area="heap"}) /1024 /1024

max
返回分组内最大值
示例:
返回堆内存占用最大的样本,单位MB
max(jvm_memory_used_bytes{area="heap"}) /1024 /1024

avg
返回分组内时间序列的平均值
示例:
返回应用在1分钟内 堆占用内存的平均值,单位MB
avg(jvm_memory_used_bytes{area="heap"}) without(id) / 1024 /1024

group
设置分组内时间序列的值为1
示例:
group(jvm_memory_used_bytes{area="heap"}) without(id)

使用group 可以在只关心分组,而不关注聚合后的值,在这种场景下使用
stddev
标准差,又称为方差,是离均差平方的算术平均数的平方根。在概率统计中,常使用标准差来统计分布程度。
stdvar
在数学中称为方差,用于衡量随机变量或一组数据的离散程度。
count
对分组中的时间序列数目进行求和
quantile
示例:
返回在线微服务的数量
count(up == 1)

count_values
表示时间序列中每一个样本值出现的次数
示例:
计算 样本值 出现的次数
使用 up == 1, 看到 样本值1 出现了2次

使用 count_values("count", up == 1) 后的结果如下:

常用于频率直方图
bottomk
用于对样本值进行排序,然后返回排在后n位的样本值
示例:
返回 接口请求数最多的1次
bottomk(1, http_server_requests_seconds_count)

bottomk 会对结果升序排列
topk
用来对样本值进行排序,然后返回排在前n位的时间序列
示例:
返回接口请求数最多的1次
topk(1, http_server_requests_seconds_count)

quantile
用于计算当前样本数据值的分布情况,quantile(分数位),分数位范围大于0,小于1。
示例:
过去1分钟内,90%的接口,每秒请求数的增长速率
quantile(0.9, rate(http_server_requests_seconds_count[1m]))
PromQL 内置函数
Prometheus 提供了大量的内置函数,至2.4.1版本,一共46个函数。
根据函数类型大致可以分成如下几种:
| 类型名称 | 函数 |
|---|---|
| 动态标签 | label_replace、label_join |
| 数学运算 | abs、exp、ln、log2、log10、sqrt、ceil、floor、 round、clamp_max、clamp_min |
| 类型转换 | vector、scalar |
| 时间和日期 | time、minute、hour、month、year、day_of_month、 day_of_week、days_in_month、timestamp |
| 多对多逻辑运算 | absent |
| 排序 | sort、sort_desc |
| Counter | rate、increase、irate、resets |
| Gauge | changes、deriv、predict_linear、delta、idelta、holt_winters |
| Histogram | histogram_quantile |
| 时间聚合 | avg_over_time、min_over_time、max_over_time、sum_over_time、 count_over_time、quantile_over_time、stddev_over_time、stdvar_over_time |
label_replace
表示通过正则表达式为时间序列添加额外的标签
语法:label_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string)
不会删除指定指标,依次对v中的每一条时间序列进行处理,通过regex匹配src_label的值,如果匹配,则将匹配部分的replacement写入dst_label标签,匹配到的值可以用$1,$2 引用,$1 用第一个匹配的子组替换,$2 用第二个匹配到的子组替换。如果正则表达式不匹配,则时间序列不变。
示例:
从up 的 instance 中匹配到IP 地址,并赋值给新的host标签
label_replace(up, "host", "$1", "instance", "(.*):(.*)")

label_join
将多个标签通过指定分隔符连接起来,写入指定的新标签中
语法:
label_join(v instant-vector, dst_label string, separator string, src_label_1 string, src_label_2 string, …)
示例:
将up指标的 job 和 instance 标签通过 “-” 分隔符连接
label_join(up, "combined", "-", "job", "instance")

abs
输入一个瞬时向量,返回所有向量样本的绝对值
语法:abs(v instant-vector)
exp
输入一个瞬时向量,返回各个样本值的e的指数值
语法:exp(v instant-vector)
特殊情况:
指数过大,返回+Inf
Exp(+Inf) = +Inf
无法计算指数值,返回NaN
Exp(NaN) = NaN
ln
ln函数的功能与exp函数相反,输入一个瞬时向量,返回样本值的自然对数
语法:ln(v instant-vector)
特殊情况:
ln(+Inf) = +Inf
ln(0) = -Inf
ln(x < 0) = NaN
ln(NaN) = NaN
log2
输入一个瞬时向量,返回样本值的二进制对数
语法:log2(v instant-vector)
log10
输入一个瞬时向量,返回样本值的十进制对数
语法:log10(v instant-vector)
sqrt
输入一个瞬时向量,返回样本值的平方根
语法:sqrt(v instant-vector)
ceil
输入一个瞬时向量,返回样本值向上四舍五入的整数
语法:ceil(v instant-vector)
floor
输入一个瞬时向量,返回样本值向下四舍五入的整数
语法:floor(v instant-vector)
round
用于返回向量中样本值最接近某个整数的值,两个参数,一个接收瞬时向量,另外一个是标量,默认为1,表示样本返回的是最接近1的整数倍的值,也可以指定为小数,表示返回的是最接近它的整数倍的值。
语法:round(v instant-vector, to_nearest=1 scalar)
示例:

clamp_max
输入一个瞬时向量和标量最大值,如果样本值大于标量最大值max,则返回值max,否则不变,用于限制最大值
语法:clamp_max(v instant-vector, max scalar)
clamp_min
输入一个瞬时向量和标量最小值,如果样本值小于min,则返回min,否则不变,用于限制最小值
语法:clamp_min(v instant-vector, min scalar)
vector
输入一个标量,并返回一个没有标签的标量
语法:vector(s scalar)

scalar
输入一个瞬时向量,如果具有唯一的时间序列,则返回其值作为一个标量,如果样本数量大于1或者等于0,则返回NaN
语法:scalar(v instant-vector)
示例:

time
返回时间戳,并不是当前时间,而是计算表达式时的时间
语法:time()
minute
返回当前UTC时间的分钟部分,结果范围0-59
语法:minute(v=vector(time()) instant-vector)
hour
返回当前UTC时间的小时部分,结果范围0-23
语法:hour(v=vector(time()) instant-vector)
month
返回当前UTC时间的月份,结果范围1-12
语法:month(v=vector(time()) instant-vector)
year
返回当前UTC时间的年份
语法:year(v=vector(time()) instant-vector)
day_of_week
返回当前UTC时间的,星期几,结果范围0-6
语法:day_of_week(v=vector(time()) instant-vector)
day_of_month
返回当前UTC时间的,天,结果范围1-31
语法:day_of_month(v=vector(time()) instant-vector)
days_in_month
返回当前UTC时间,给定时间在一个月中的总天数,返回值28-31
语法:days_in_month(v=vector(time()) instant-vector)
timestamp
返回给定向量中每个样本的时间戳,UTC时间
语法:timestamp(v instant-vector)
absent
如果传递给absent函数的向量具有样本数据,则返回空向量,如果没有样本数据,则返回样本值为1
语法:absent(v instant-vector)
示例:

sort
对向量按元素值升序
语法:sort(v instant-vector)
sort_desc
对向量按元素值降序
rate
计算区间向量v在时间窗口内的平均增长速率
语法:rate(v range-vector)
注意:与聚合函数(比如sum)一起使用时,必须先执行rate,再执行聚合操作。因为重启服务后计数器被重置为0,总和将减少,结果会出现较大的虚假峰值
irate
针对长尾效应提供的高灵敏度函数,用于计算区间向量的增长速率,但是建议在长期告警中使用rate函数,因为irate只能绘制快速变化的计数器
语法:irate(v range-vector)
increase
获取区间向量中第一个和最后一个样本并返回其增长量
语法:increase(v range-vector)
示例:
计算过去一分钟内HTTP请求的增长数
原始数据:
increase后数据:

resets
输入一个区间向量,返回一个计数器重置的次数,两个连续样本之间的值的减少被认为是一次计数器重置
语法:resets(v range-vector)
predict_linear
预测时间序列v(区间向量)在t秒后的值,可以对时间序列的变化趋势做出预测
语法:predict_linear(v range-vector, t scalar)
deriv
输入一个区间向量,返回一个瞬时向量,使用简单的线性回归计算区间向量v中各个时间序列的导数
语法:deriv(v range-vector)
delta
输入一个区间向量,返回一个瞬时向量,用于计算一个区间向量v的第一个元素和最后一个元素之间的差值
语法:delta(v range-vector)
idelta
输入一个区间向量,返回一个瞬时向量,计算最新的两个样本值之间的差值
语法:idelta(v range-vector)
holt_winters
基于区间向量v生成时间序列数据平滑值
语法:holt_winters(v range-vector, sf scalar, tf scalar)
changes
输入一个区间向量,返回这个区间向量中每个样本数据值变化的次数(瞬时向量)
语法:changes(v range-vector)
histogram_quantile
从bucket 类型的向量b中计算分位数的样本最大值
语法:histogram_quantile(φ scalar, b instant-vector)
<aggregation>_over_time()
该组函数针对区间向量中的时间序列的值,返回一个瞬时向量
- avg_over_time(range-vector): 区间向量内每个指标的平均值
- min_over_time(range-vector): 区间向量内每个指标的最小值
- max_over_time(range-vector): 区间向量内每个指标的最大值
- sum_over_time(range-vector): 区间向量内每个指标的和
- count_over_time(range-vector): 区间向量内样本数据个数
- quantile_over_time(scalar, range-vector): 区间向量内每个指标的样本数据值分位数
- stddev_over_time(range-vector): 区间向量内每个指标的总体标准差
- stdvar_over_time(range-vector): 区间向量内每个指标的总体标准方差
- last_over_time(range-vector): 区间向量内每个指标的最新样本值
- present_over_time(range-vector): 区间向量内每个指标的值为1
作者其他文章:
Grafana 系列文章,版本:OOS v9.3.1
- Grafana 的介绍和安装
- Grafana监控大屏配置参数介绍(一)
- Grafana监控大屏配置参数介绍(二)
- Grafana监控大屏可视化图表
- Grafana 查询数据和转换数据
- Grafana 告警模块介绍
- Grafana 告警接入飞书通知
Spring Boot Admin 系列
- Spring Boot Admin 参考指南
- SpringBoot Admin服务离线、不显示健康信息的问题
- Spring Boot Admin2 @EnableAdminServer的加载
- Spring Boot Admin2 AdminServerAutoConfiguration详解
- Spring Boot Admin2 实例状态监控详解
- Spring Boot Admin2 自定义JVM监控通知
- Spring Boot Admin2 自定义异常监控
- Spring Boot Admin 监控指标接入Grafana可视化