Apache Solr 9.1-(二)集群模式运行
Solr是一个基于Apache Lucene的搜索服务器,Apache Lucene是开源的、基于Java的信息检索库,Solr能为用户提供无论在任何时候都可以根据用户的查询请求返回结果,它被设计为一个强大的文档检索引擎。
Apache Solr系列文章:
1、Apache Solr 9.1-(一)初体验单机模式运行
2、Apache Solr 9.1-(二)集群模式运行
目录
- Apache Solr 9.1-(二)集群模式运行
- 一、准备
- 1、各组件版本说明
- 2、部署架构
- 3、硬件环境准备
- 4、各服务器节点服务部署情况
- 5、服务器基础环境准备
- 二、部署OpenJDK 11
- 1、下载OpenJDK11
- 2、上传服务器并解压
- 3、将jdk同步到hnode2服务器上
- 4、将jdk同步到hnode2服务器上
- 三、部署Zookeeper集群
- 1、在hnode1服务器上部署Zookeeper
- 1). 解压安装包
- 2). 配置环境变量
- 3). 配置zookeeper
- 4). 在zkData目录生成myid文件
- 2、在hnode2服务器上部署Zookeeper
- 1). 从hnode1服务器复制Zookeeper安装目录
- 2). 配置环境变量
- 3). 修改myid
- 3、在hnode3服务器上部署Zookeeper
- 1). 从hnode1服务器复制Zookeeper安装目录
- 2). 配置环境变量
- 3). 修改myid
- 四、部署Apache Solr集群
- 1、解压安装包
- 2、配置solr环境变量
- 3、配置jvm
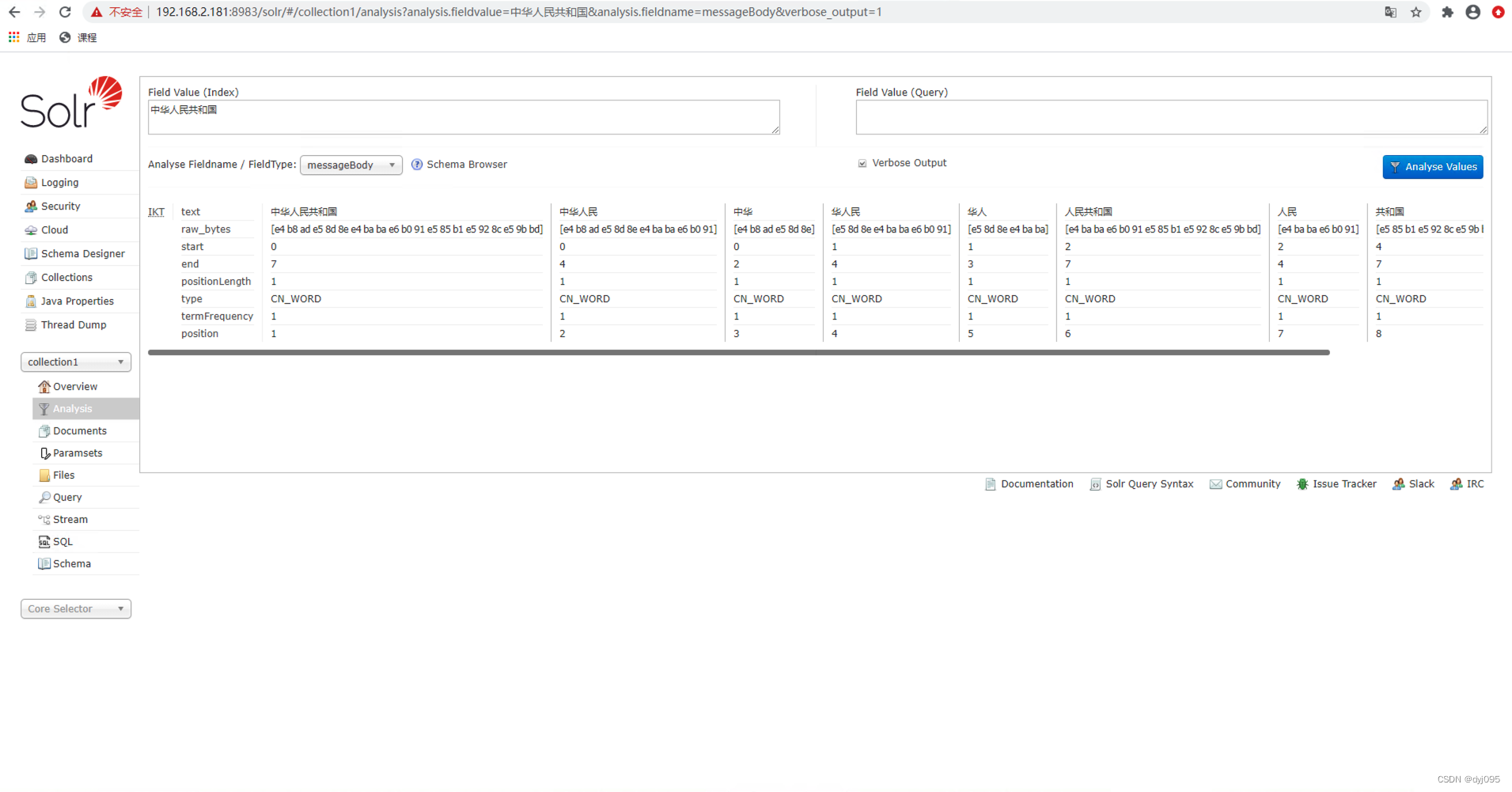
- 4、安装IK-Analyzer中文分词器
- 5、将solr安装目录同步到hnode2节点上
- 6、将solr安装目录同步到hnode3节点上
- 7、启动Zookeeper集群
- 1).在hnode1上启动Zookeeper
- 2).在hnode2上启动Zookeeper
- 3).在hnode3上启动Zookeeper
- 8、启动Solr集群
- 1).在hnode1上启动solr
- 2).在hnode2上启动solr
- 3).在hnode3上启动solr
- 9、创建一个Collection
- 10、更新Collection中Schema字段
- 1).从Zookeeper集群中下载配置文件
- 2).修改配置文件
- 3).更新配置文件到Zookeeper集群中
- 五、验证结果
- 1、确认collection1重载配置后Schema生效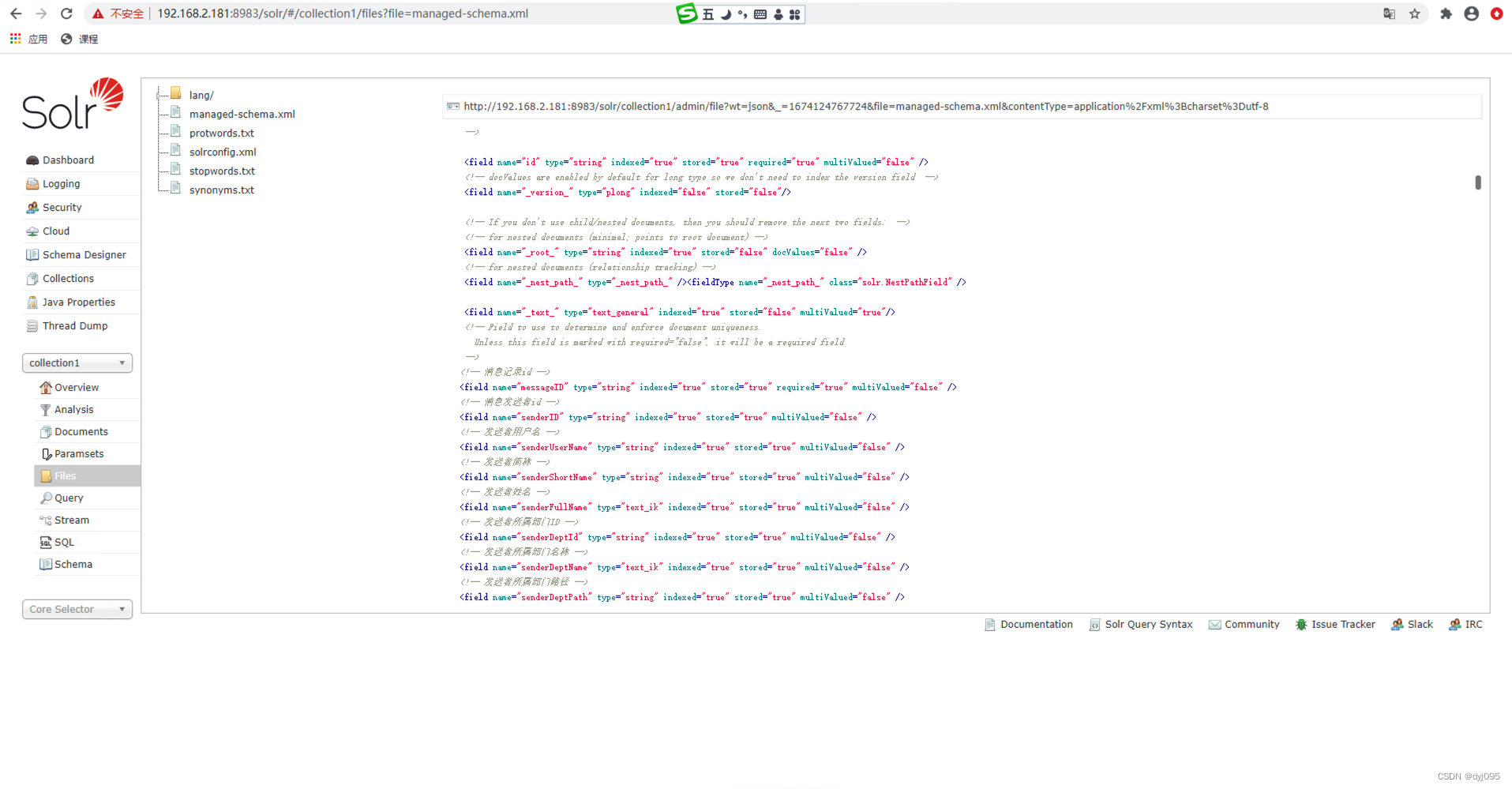
- 2、验证中文分词
一、准备
1、各组件版本说明
| 序号 | 软件名称 | 版本 | 说明 |
|---|---|---|---|
| 1 | JDK | 11 | Apache Solr9.1要求JDK的版本最低为11,可以是openjdk |
| 2 | Apache Solr | 9.1 | 基于Apache Lucene搜索服务器 |
| 3 | IK-Analyzer | 8.5.0 | 中文分词器 |
| 4 | Zookeeper | 2.4.15 |
2、部署架构
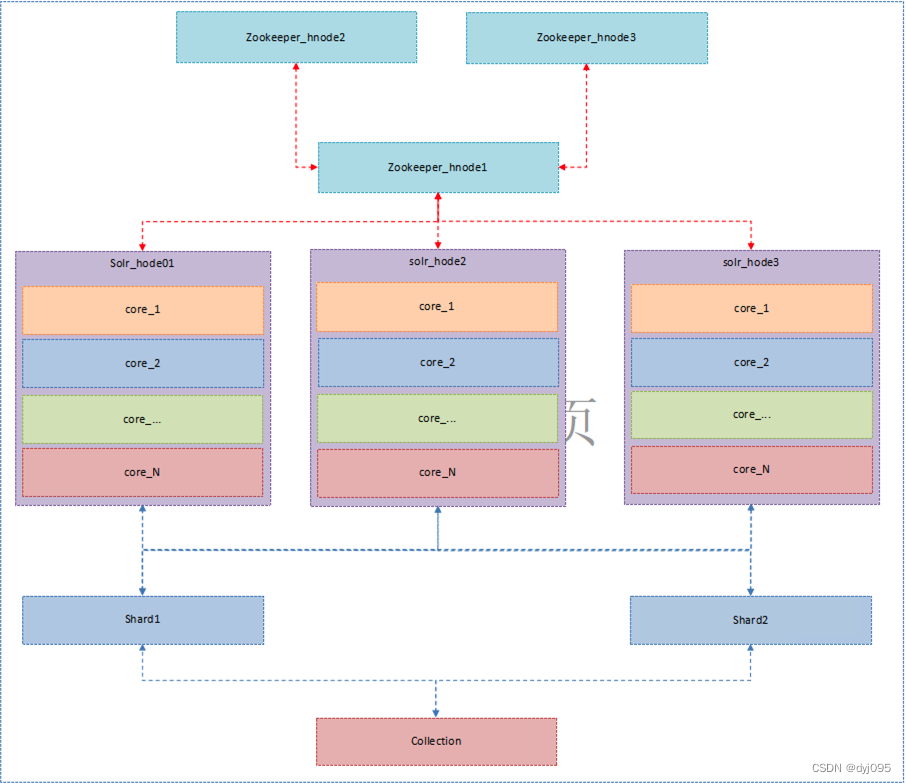
3、硬件环境准备
| 序号 | IP | HostName | 操作系统 | 说明 |
|---|---|---|---|---|
| 1 | 192.168.2.181 | hnode1 | CentOS7_x64 | |
| 2 | 192.168.2.182 | hnode2 | CentOS7_x64 | |
| 3 | 192.168.2.183 | hnode3 | CentOS7_x64 |
4、各服务器节点服务部署情况
| 序号 | 服务节点 | Zookeeper节点 | solr节点 |
|---|---|---|---|
| 1 | hnode1 | √ | √ |
| 2 | hnode2 | √ | √ |
| 3 | hnode3 | √ | √ |
5、服务器基础环境准备
参见【大数据基础平台搭建-(一)基础环境准备】
二、部署OpenJDK 11
1、下载OpenJDK11
点击此处【OpenJDK11】进入下载页面下载
2、上传服务器并解压
本文是将openjdk11包上传到/opt/solr/目录下了
[root@hnode1 ~]# cd /opt/solr
[root@hnode1 solr]# tar -xzvf ./openjdk-11+28_linux-x64_bin.tar.gz

3、将jdk同步到hnode2服务器上
[root@hnode2 ~]# cd /opt/
[root@hnode2 opt]# mkdir solr
[root@hnode2 opt]# cd solr
[root@hnode2 solr]# scp -r root@hnode1:/opt/solr/jdk-11 ./
4、将jdk同步到hnode2服务器上
[root@hnode3 ~]# cd /opt
[root@hnode3 opt]# mkdir solr
[root@hnode3 opt]# cd solr
[root@hnode3 solr]# scp -r root@hnode1:/opt/solr/jdk-11 ./
三、部署Zookeeper集群
根据 Solr官方文档 说明:
1、如果在生产环境中部署Solr集群,那么不要使用Solr自带的Zookeeper,要使用外部独立部署的Zookpeer集群,因为自带的Zookeeper不具备故障转移的功能。
2、强烈建议在您的集成中使用奇数个ZooKeeper服务器,这样就可以保持大多数服务器。
3、通常不建议超过5个节点。虽然看起来更多的节点提供了更大的容错性和可用性,但实际上,由于发生了大量的节点间协调,它的效率会降低。除非你有一个真正庞大的Solr集群(规模为1000个节点),否则一般情况下尽量保持在3个,如果你有更大的集群,可能保持在5个。
- 关与更多细节请您阅读官方文档。
1、在hnode1服务器上部署Zookeeper
1). 解压安装包
[root@hnode1 ~]# cd /opt/
[root@hnode1 opt]# tar -xzvf ./apache-zookeeper-3.8.0-bin.tar.gz /opt/zk/apache-zookeeper-3.8.0-bin
[root@hnode1 opt]# cd /opt/zk/apache-zookeeper-3.8.0-bin
2). 配置环境变量
[root@hnode1 apache-zookeeper-3.8.0-bin]# vim /etc/profile
#Zookeeper
export ZOOKEEPER_HOME=/opt/zk/apache-zookeeper-3.8.0-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@hnode1 apache-zookeeper-3.8.0-bin]# source /etc/profile
3). 配置zookeeper
[root@znode apache-zookeeper-3.8.0-bin]# mkdir zkData
[root@znode apache-zookeeper-3.8.0-bin]# cd conf
[root@znode conf]# cp ./zoo_sample.cfg ./zoo.cfg
[root@znode conf]# vim ./zoo.cfg
tickTime=2000
clientPort=2181
dataDir=/opt/zk/apache-zookeeper-3.8.0-bin/zkData
initLimit=5
syncLimit=2
#添加集群中其他节点的信息
server.1=hnode1:2888:3888
server.2=hnode2:2888:3888
server.3=hnode3:2888:3888
# 指定允许管理员在solr Admin管理画面上查看Zookeeper的状态数据
4lw.commands.whitelist=mntr,conf,ruok
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
[root@hnode1 apache-zookeeper-3.8.0-bin]# source /etc/profile
4). 在zkData目录生成myid文件
[root@znode apache-zookeeper-3.8.0-bin]# cd zkData/
[root@znode zkData]# vim myid
1
2、在hnode2服务器上部署Zookeeper
1). 从hnode1服务器复制Zookeeper安装目录
[root@hnode2 ~]# cd /opt/
[root@hnode2 opt]# mkdir zk
[root@hnode2 opt]# cd zk
[root@hnode2 zk]# scp -r root@hnode1:/opt/zk/apache-zookeeper-3.8.0-bin ./
2). 配置环境变量
[root@hnode2 zk]# vim /etc/profile
#Zookeeper
export ZOOKEEPER_HOME=/opt/zk/apache-zookeeper-3.8.0-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@hnode2 zk]# source /etc/profile
3). 修改myid
[root@hnode2 zk]# cd apache-zookeeper-3.8.0-bin/zkData/
[root@hnode2 zkData]# vim myid
2
3、在hnode3服务器上部署Zookeeper
1). 从hnode1服务器复制Zookeeper安装目录
[root@hnode3 ~]# cd /opt/
[root@hnode3 opt]# mkdir zk
[root@hnode3 opt]# cd zk
[root@hnode3 zk]# scp -r root@hnode1:/opt/zk/apache-zookeeper-3.8.0-bin ./
2). 配置环境变量
[root@hnode3 zk]# vim /etc/profile
#Zookeeper
export ZOOKEEPER_HOME=/opt/zk/apache-zookeeper-3.8.0-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@hnode3 zk]# source /etc/profile
3). 修改myid
[root@hnode3 zk]# cd apache-zookeeper-3.8.0-bin/zkData/
[root@hnode3 zkData]# vim myid
3
四、部署Apache Solr集群
1、解压安装包
本文是将solr-9.1.0.tgz包上传到/opt/solr/目录下了
[root@hnode1 ~]# cd /opt/solr
[root@hnode1 solr]# tar -xzvf ./solr-9.1.0.tgz
2、配置solr环境变量
[root@hnode1 solr]# vim ./bin/solr.in.sh
查找到下面两行配置,并解注后,参照下面值进行配置
ZK_HOST="hnode1:2181,hnode2:2181,hnode3:2181"
ZK_CLIENT_TIMEOUT="30000"
SOLR_HOST="hnode1"
SOLR_PORT=8983
SOLR_HOME="/opt/solr/solr-9.1.0"
3、配置jvm
[root@hnode1 solr]# vim ./bin/solr
在脚本开始新增下面代码
SOLR_JAVA_HOME="/opt/solr/jdk-11"
SOLR_JETTY_HOST="192.168.2.181"
4、安装IK-Analyzer中文分词器
将ik-analyzer-8.5.0.jar上传到/opt/solr/solr-9.1.0/server/solr-webapp/webapp/WEB-INF/lib/目录下
5、将solr安装目录同步到hnode2节点上
[root@hnode2 solr]# scp -r root@hnode1:/opt/solr/solr-9.1.0 ./
[root@hnode2 solr]# vim ./solr-9.1.0/bin/solr
修改ip
SOLR_JETTY_HOST="192.168.2.182"
修改环境变量中的host即可,其它都不变
[root@hnode2 solr]# vim ./bin/solr.in.sh
SOLR_HOST="hnode2"
6、将solr安装目录同步到hnode3节点上
[root@hnode3 solr]# scp -r root@hnode1:/opt/solr/solr-9.1.0 ./
[root@hnode3 solr]# vim ./solr-9.1.0/bin/solr
修改ip
SOLR_JETTY_HOST="192.168.2.183"
修改环境变量中的host即可,其它都不变
[root@hnode3 solr]# vim ./bin/solr.in.sh
SOLR_HOST="hnode3"
7、启动Zookeeper集群
1).在hnode1上启动Zookeeper
[root@hnode1 bin]# zkServer.sh start
[root@hnode1 bin]# zkServer.sh status
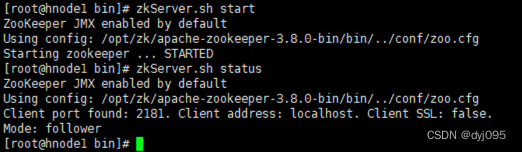
2).在hnode2上启动Zookeeper
[root@hnode2 bin]# zkServer.sh start
[root@hnode2 bin]# zkServer.sh status
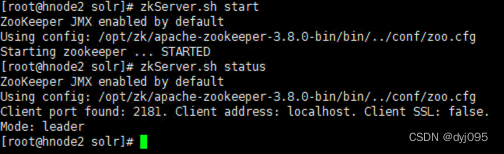
3).在hnode3上启动Zookeeper
[root@hnode3 bin]# zkServer.sh start
[root@hnode3 bin]# zkServer.sh status
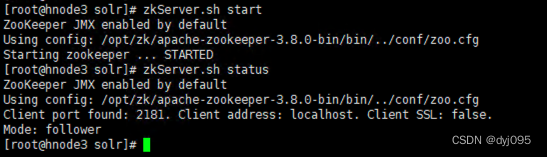
8、启动Solr集群
1).在hnode1上启动solr
[root@hnode1 solr]# cd /opt/solr/solr-9.1.0/bin
# 通过solr命令来在zookeeper集群上创建/solr目录来存放solr集群的数据
[root@hnode1 bin]# ./solr zk mkroot /solr -z hnode1:2181,hnode2:2181,hnode3:2181
# 启动Solr集群
[root@hnode1 bin]# ./solr start -e cloud -z hnode1:2181,hnode2:2181,hnode3:2181/solr -force
2).在hnode2上启动solr
[root@hnode2 solr]# cd /opt/solr/solr-9.1.0/bin
[root@hnode2 bin]# ./solr start -e cloud -z hnode1:2181,hnode2:2181,hnode3:2181/solr -force
3).在hnode3上启动solr
[root@hnode3 solr]# cd /opt/solr/solr-9.1.0/bin
[root@hnode3 bin]# ./solr start -e cloud -z hnode1:2181,hnode2:2181,hnode3:2181/solr -force
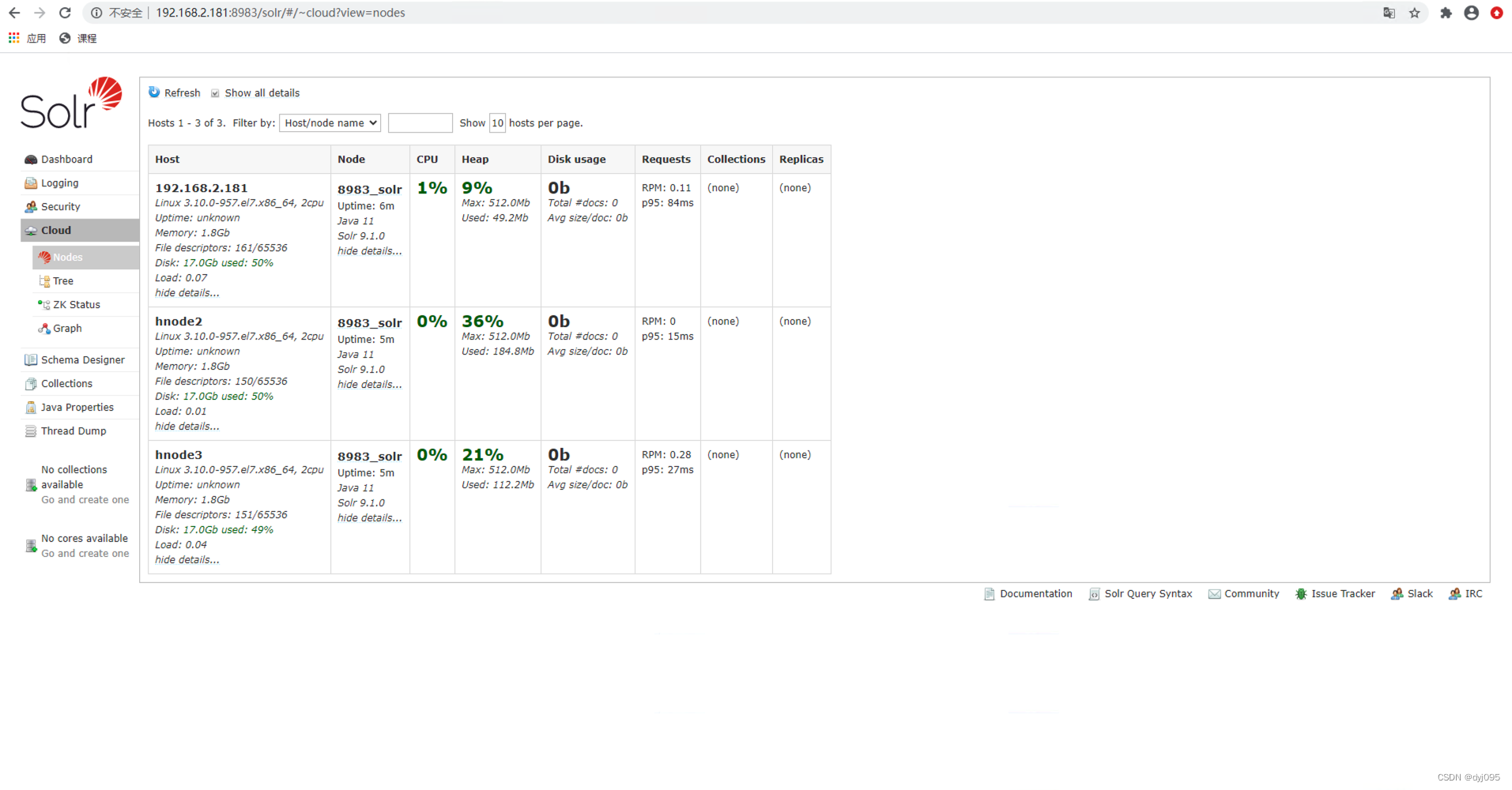
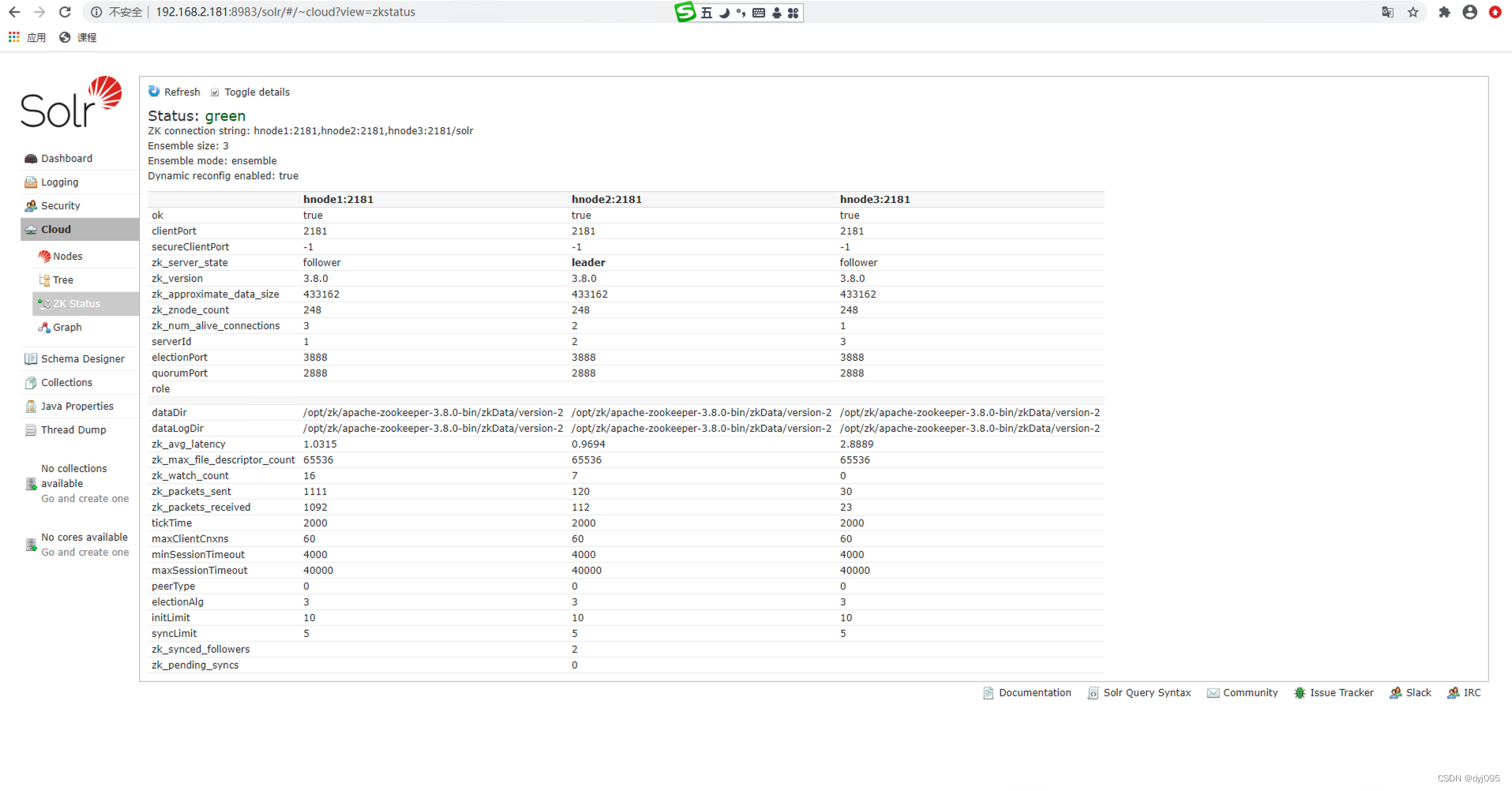
因为此时还未创建Collection,所以此时Cloud->Graph显示的Solr集群图中是空的,下面9将创建一个Collection后就可以看到了。
9、创建一个Collection
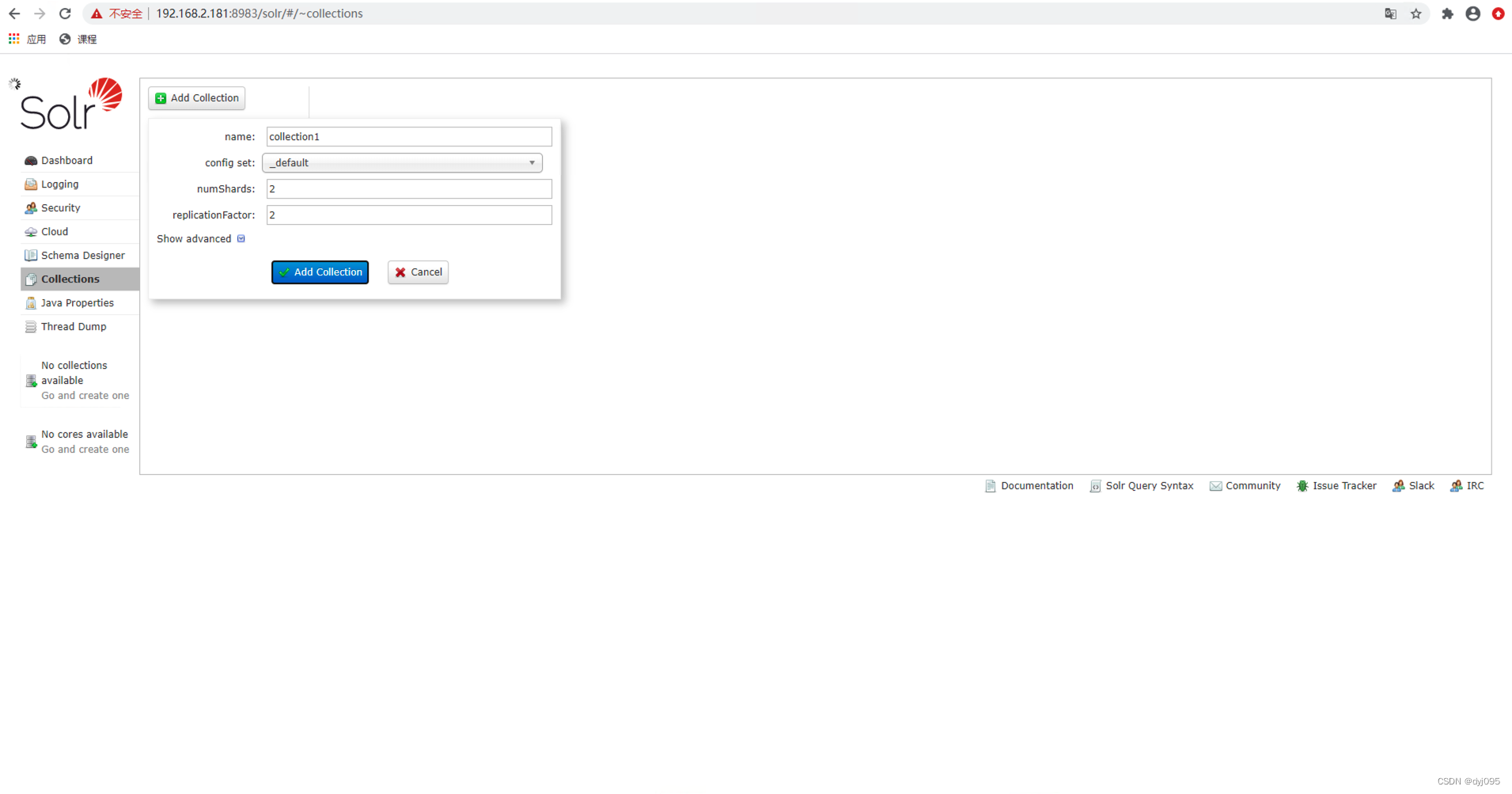
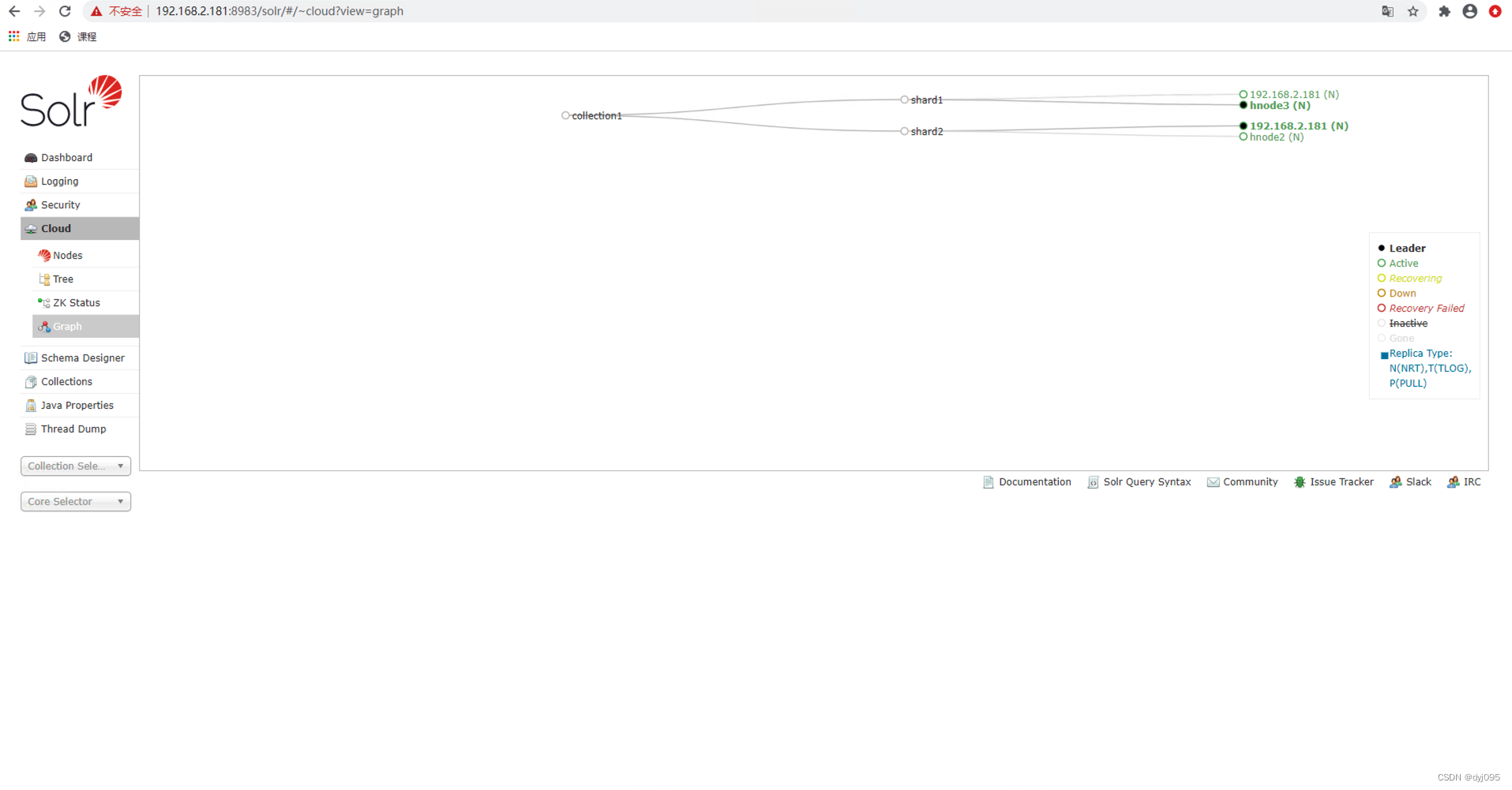
10、更新Collection中Schema字段
1).从Zookeeper集群中下载配置文件
[root@hnode1 solr]# solr-9.1.0/bin/solr zk downconfig -d . -n _default
[root@hnode1 solr]# cd conf
2).修改配置文件
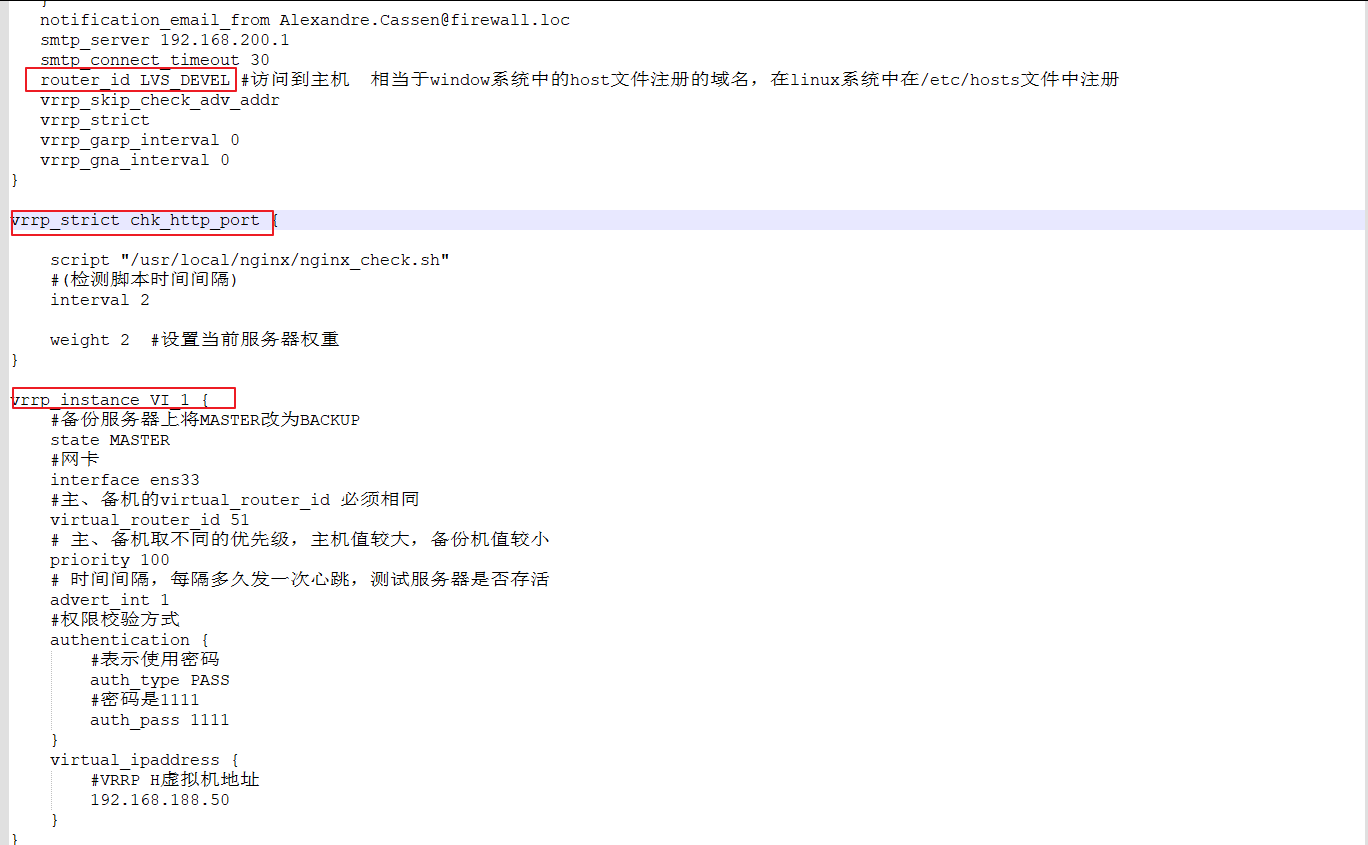
[root@hnode1 conf]# vim managed-schema.xml
添加IK中文分词器配置和添加两个自定义字段
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!-- 消息记录id -->
<field name="messageID" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!-- 发送者姓名 -->
<field name="senderFullName" type="text_ik" indexed="true" stored="true" multiValued="false" />
3).更新配置文件到Zookeeper集群中
第一步:先删除zookeeper集群中solr目录下的配置文件
[root@hnode1 conf]# zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /solr/configs/_default
[lang, managed-schema.xml, protwords.txt, solrconfig.xml, stopwords.txt, synonyms.txt]
[zk: localhost:2181(CONNECTED) 1] delete /solr/configs/_default/managed-schema.xml
第二步:通过cloud-scripts中的zkcli.sh脚本将本地修改完成的managed-schema.xml上传到zookeeper集群中/solr/configs/_default/目录下
[root@hnode1 conf]# cd ..
[root@hnode1 solr]# cd /opt/solr/solr-9.1.0/server/scripts/cloud-scripts
[root@hnode1 cloud-scripts]# ./zkcli.sh -zkhost hnode1:2181,hnode2:2181,hnode3:2181 -cmd putfile /solr/configs/_default/managed-schema.xml /opt/solr/conf/managed-schema.xml
第三步:通过solr Admin UI画面,重新加载Collection配置
点击画面中Collections->collection1->Reload按钮
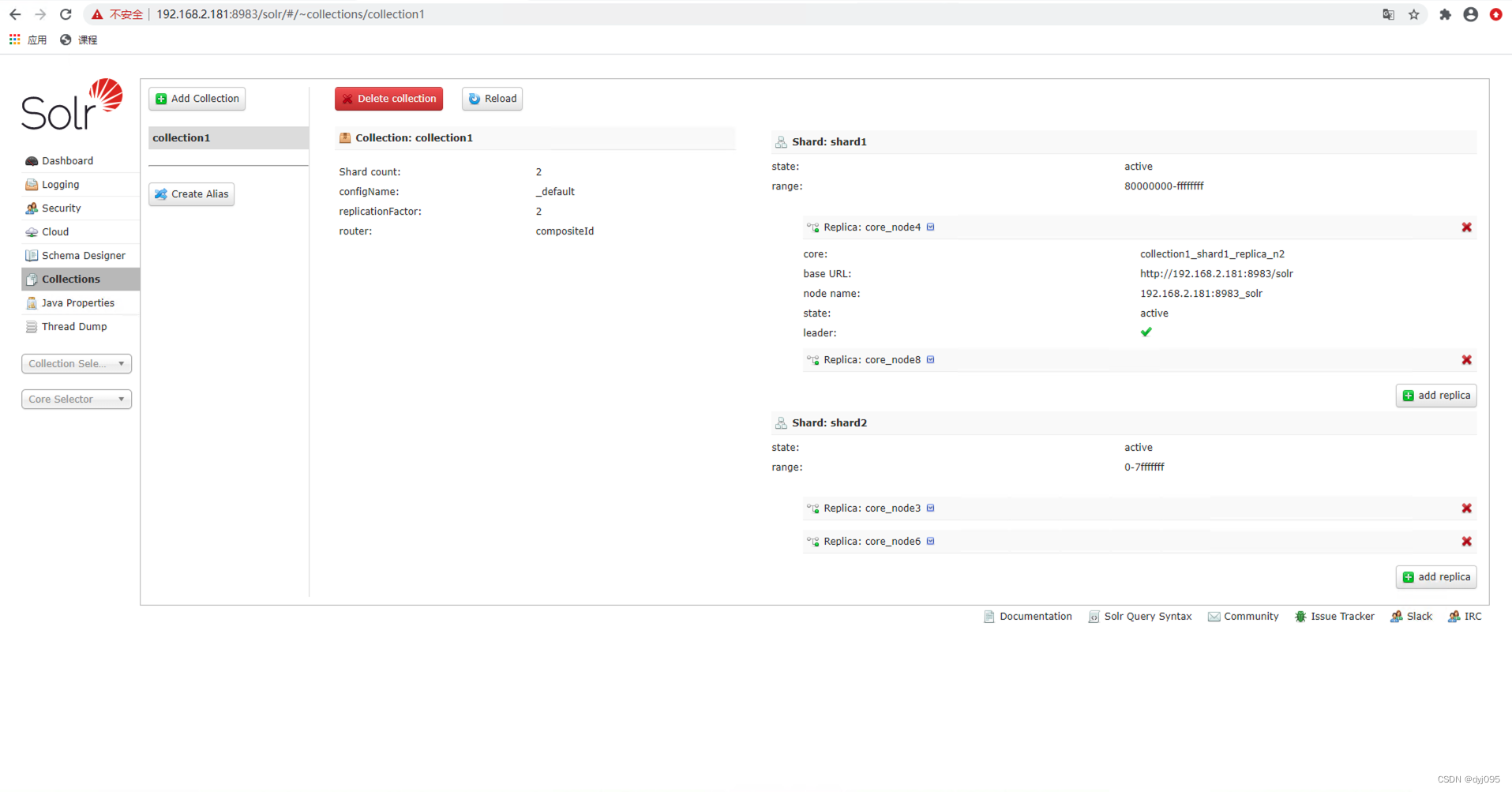
五、验证结果
1、确认collection1重载配置后Schema生效
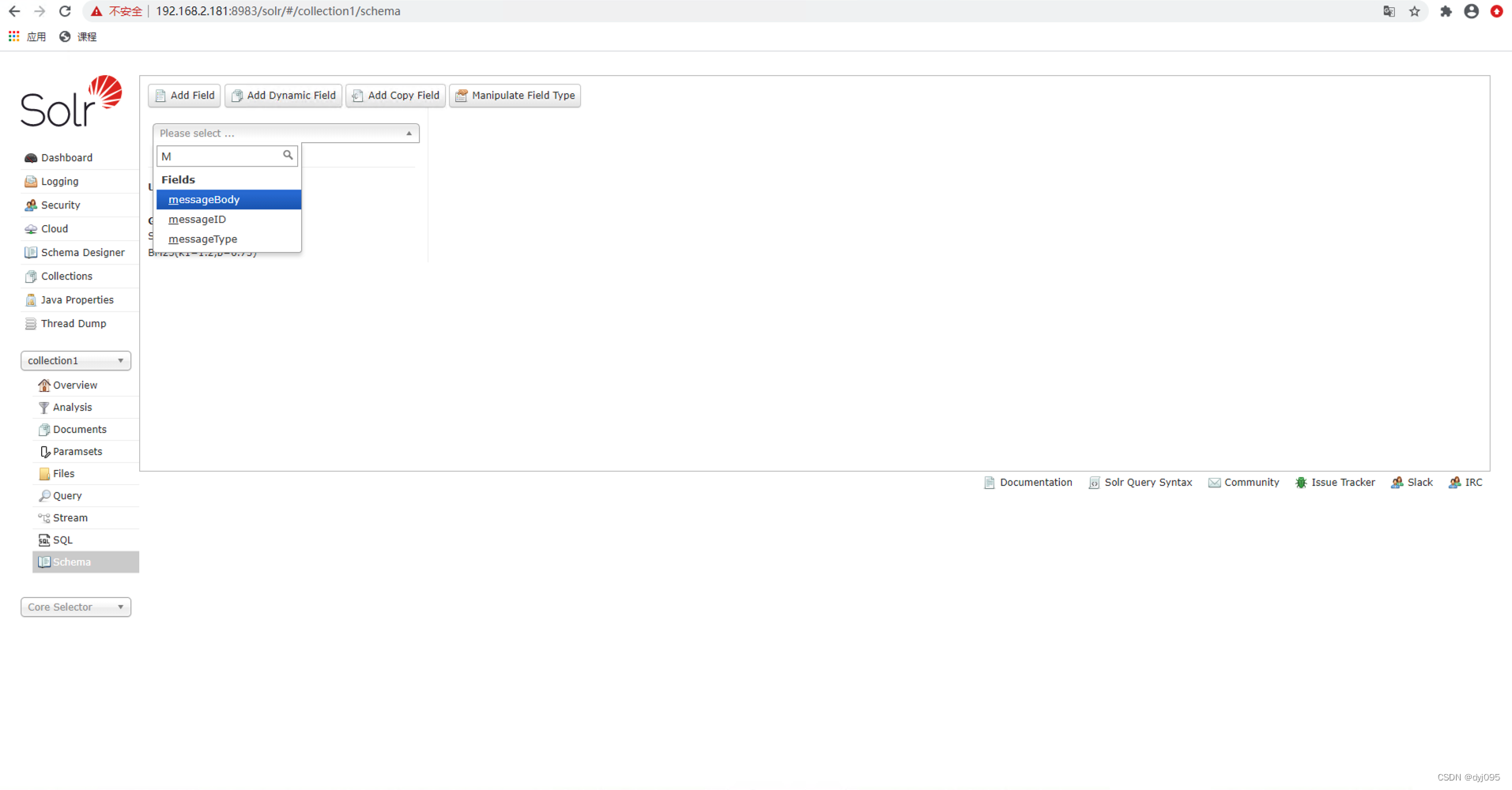
2、验证中文分词