概念
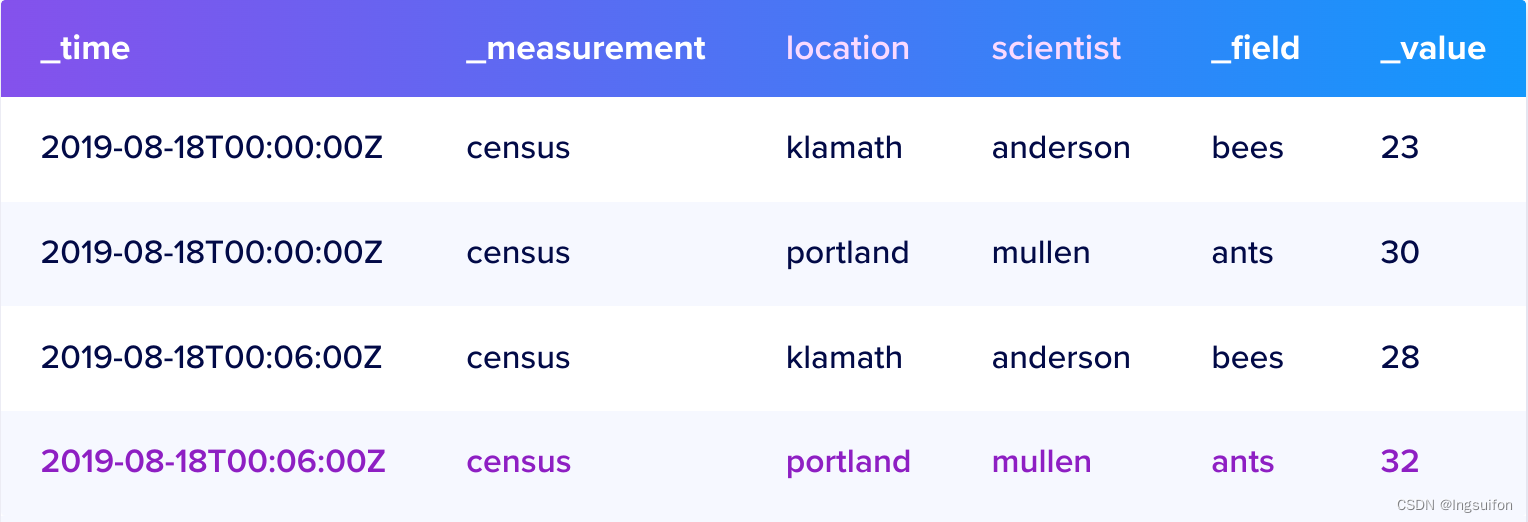
Measurement
类似于表名。
A measurement acts as a container for tags, fields, and timestamps.
Tag
补充描述数据的信息,如示例中的location和scientist描述了该数据的采集地和采集人。这两个称为Tag Key,具体的值则称为Tag Value,文本类型。
Field
用于表示实际的数据,包括Field Key和Field Value,前者描述数据的含义,后者记录具体的值,通常为数字。
Series
Series Key是共享同一 Measurement、Tag set 和 Field Key 的点的集合。例如:

Series包括给定 Series Key 的时间戳和 Field Value。从示例数据中,这里有一个 Series Key 和相应的 Series:
# series key
census,location=klamath,scientist=anderson bees
# series
2019-08-18T00:00:00Z 23
2019-08-18T00:06:00Z 28
Point
一个数据点包括 Series Key、Field Value 和时间戳。例如,样本数据中的单个点如下所示:
2019-08-18T00:00:00Z census ants 30 portland mullen
Write Path
我们从数据的写入路径来一探 InfluxDB 的结构。
写入请求
首先我们看看数据写入请求是如何封装的:
// WritePointsRequest represents a request to write point data to the cluster.
type WritePointsRequest struct {
Database string
RetentionPolicy string
Points []models.Point
}
Database 指明了相应的数据库,RetentionPolicy 指明了保留策略(可以理解为数据的有效期,详情可以看官方文档的解释,这里略),Points 则表示要请求写入的数据点数组,我们来看一下它的结构:
// point is the default implementation of Point.
type point struct {
time time.Time
// text encoding of measurement and tags
// key must always be stored sorted by tags, if the original line was not sorted,
// we need to resort it
key []byte
// text encoding of field data
fields []byte
// text encoding of timestamp
ts []byte
// cached version of parsed fields from data
cachedFields map[string]interface{}
// cached version of parsed name from key
cachedName string
// cached version of parsed tags
cachedTags Tags
it fieldIterator
}
里面出现了很多第一节中介绍过的概念。唯一有所出入的是 fields,这里并没有向第一节里说的那样一个点一个 field tag,而是都集中在一个 point 对象里。
那么这个 request 由谁来处理呢?系统会构造一个 PointsWriter 对象来负责写入,这个类型本身的结构并不重要,重点是它处理如何写数据:
// MapShards maps the points contained in wp to a ShardMapping. If a point
// maps to a shard group or shard that does not currently exist, it will be
// created before returning the mapping.
func (w *PointsWriter) MapShards(wp *WritePointsRequest) (*ShardMapping, error) {
. . .
for _, p := range wp.Points {
// Either the point is outside the scope of the RP, or we already have
// a suitable shard group for the point.
if p.Time().Before(min) || list.Covers(p.Time()) {
continue
}
// No shard groups overlap with the point's time, so we will create
// a new shard group for this point.
sg, err := w.MetaClient.CreateShardGroup(wp.Database, wp.RetentionPolicy, p.Time())
if err != nil {
return nil, err
}
if sg == nil {
return nil, errors.New("nil shard group")
}
list.Add(*sg)
}
mapping := NewShardMapping(len(wp.Points))
for _, p := range wp.Points {
sg := list.ShardGroupAt(p.Time())
if sg == nil {
// We didn't create a shard group because the point was outside the
// scope of the RP.
mapping.Dropped = append(mapping.Dropped, p)
continue
}
sh := sg.ShardFor(p) // 获取该点在该Group中的Shard
mapping.MapPoint(&sh, p) // 点映射到对应的Shard
}
return mapping, nil
}
这里省略了一部分不重要的代码。这个函数将每个 Point 映射到相应的 Shard 中,遍历每一个点。如果当前点的时间戳小于保留策略范围的最小值(即当前点已过期)或已存在覆盖该时间范围的 Shard Group,那么就 continue,否则创建新的 ShardGroup,保存到 list 中。
创建完需要的 ShardGroup 后,重新遍历所有点,获取每个点对应的 ShardGroup 和具体的 Shard,将该点映射到该 Shard。
我们再来看看MapShards是在什么地方使用的:
// WritePoints writes the data to the underlying storage. consistencyLevel and user are only used for clustered scenarios
func (w *PointsWriter) WritePoints(
ctx context.Context,
database, retentionPolicy string,
consistencyLevel models.ConsistencyLevel,
user meta.User,
points []models.Point,
) error {
return w.WritePointsPrivileged(ctx, database, retentionPolicy, consistencyLevel, points)
}
// WritePointsPrivileged writes the data to the underlying storage, consistencyLevel is only used for clustered scenarios
func (w *PointsWriter) WritePointsPrivileged(
ctx context.Context,
database, retentionPolicy string,
consistencyLevel models.ConsistencyLevel,
points []models.Point,
) error {
. . .
shardMappings, err := w.MapShards(&WritePointsRequest{Database: database, RetentionPolicy: retentionPolicy, Points: points})
if err != nil {
return err
}
// Write each shard in it's own goroutine and return as soon as one fails.
ch := make(chan error, len(shardMappings.Points))
for shardID, points := range shardMappings.Points {
go func(shard *meta.ShardInfo, database, retentionPolicy string, points []models.Point) {
err := w.writeToShard(ctx, shard, database, retentionPolicy, points)
if err == nil {
w.stats.pointsWriteOk.Observe(float64(len(points)))
} else {
w.stats.pointsWriteErr.Observe(float64(len(points)))
}
if err == tsdb.ErrShardDeletion {
err = tsdb.PartialWriteError{Reason: fmt.Sprintf("shard %d is pending deletion", shard.ID), Dropped: len(points)}
}
ch <- err
}(shardMappings.Shards[shardID], database, retentionPolicy, points)
}
. . .
return err
}
上面两个函数用于写数据,第一个函数实际上是对第二个函数的包装。可以看到,该函数先获取所有点的 ShardMapping,然后为每个 Shard 开启一个协程,Shard 间并行写入。
再来看看中间的writeToShard:
// writeToShards writes points to a shard.
func (w *PointsWriter) writeToShard(ctx context.Context, shard *meta.ShardInfo, database, retentionPolicy string, points []models.Point) error {
err := w.TSDBStore.WriteToShard(ctx, shard.ID, points)
if err == nil {
return nil
}
// Except tsdb.ErrShardNotFound no error can be handled here
if err != tsdb.ErrShardNotFound {
return err
}
// If we've written to shard that should exist on the current node, but the store has
// not actually created this shard, tell it to create it and retry the write
if err = w.TSDBStore.CreateShard(ctx, database, retentionPolicy, shard.ID, true); err != nil {
w.Logger.Warn("Write failed creating shard", zap.Uint64("shard", shard.ID), zap.Error(err))
return err
}
if err = w.TSDBStore.WriteToShard(ctx, shard.ID, points); err != nil {
w.Logger.Info("Write failed", zap.Uint64("shard", shard.ID), zap.Error(err))
return err
}
return nil
}
这个函数简单来说,就是尝试往 Shard 中写入,如果当前节点相应的 Shard 还未分配,那么就先分配,再重新插入。继续前进:
// WriteToShard writes a list of points to a shard identified by its ID.
func (s *Store) WriteToShard(ctx context.Context, shardID uint64, points []models.Point) error {
. . .
sh := s.shards[shardID]
. . .
return sh.WritePoints(ctx, points)
}
这里的大部分代码都和系统健壮性相关,因此省略。在继续看WritePoints前,我们先看看Shard的结构:
// Shard represents a self-contained time series database. An inverted index of
// the measurement and tag data is kept along with the raw time series data.
// Data can be split across many shards. The query engine in TSDB is responsible
// for combining the output of many shards into a single query result.
type Shard struct {
path string
walPath string
id uint64
database string
retentionPolicy string
sfile *SeriesFile
options EngineOptions
mu sync.RWMutex
_engine Engine
index Index
enabled bool
stats *ShardMetrics
baseLogger *zap.Logger
logger *zap.Logger
metricUpdater *ticker
EnableOnOpen bool
// CompactionDisabled specifies the shard should not schedule compactions.
// This option is intended for offline tooling.
CompactionDisabled bool
}
这里比较重要的是engine和index,前者是管理数据的核心,后者是索引。
继续看在 Shard 上写入数据:
// WritePoints will write the raw data points and any new metadata to the index in the shard.
func (s *Shard) WritePoints(ctx context.Context, points []models.Point) (rErr error) {
. . .
engine, err := s.engineNoLock()
. . .
points, fieldsToCreate, err := s.validateSeriesAndFields(points)
. . .
s.stats.fieldsCreated.Add(float64(len(fieldsToCreate)))
// add any new fields and keep track of what needs to be saved
if err := s.createFieldsAndMeasurements(fieldsToCreate); err != nil {
return err
}
// Write to the engine.
if err := engine.WritePoints(ctx, points); err != nil {
return fmt.Errorf("engine: %s", err)
}
return writeError
}
中间的validateSeriesAndFields较长,这里就不贴源码了,简单讲一下该函数的功能。它首先遍历所有点,检查它们的 Tag 是否包含 “time”字段、Measurement 和所有 Tag 的字符是否为合理的 unicode,保留所有合法的点,并创建丢失的 Field等,总体上是在做完整性检查的工作,不展开讲,我们直接看engine.writePoints。
// WritePoints writes metadata and point data into the engine.
// It returns an error if new points are added to an existing key.
func (e *Engine) WritePoints(ctx context.Context, points []models.Point) error {
values := make(map[string][]Value, len(points))
var (
keyBuf []byte
baseLen int
seriesErr error
)
for _, p := range points {
keyBuf = append(keyBuf[:0], p.Key()...)
keyBuf = append(keyBuf, keyFieldSeparator...) //分隔符:#~#
baseLen = len(keyBuf)
iter := p.FieldIterator()
t := p.Time().UnixNano()
for iter.Next() {
// Skip fields name "time", they are illegal
if bytes.Equal(iter.FieldKey(), timeBytes) {
continue
}
// 构造我们第一节讲过的Series Key,注意一个Field Key对应一个Series Key
keyBuf = append(keyBuf[:baseLen], iter.FieldKey()...)
// 检查当前插入数据的类型是否与同一Series的不一致
if e.seriesTypeMap != nil {
// Fast-path check to see if the field for the series already exists.
if v, ok := e.seriesTypeMap.Get(keyBuf); !ok {
if typ, err := e.Type(keyBuf); err != nil {
// Field type is unknown, we can try to add it.
} else if typ != iter.Type() {
// Existing type is different from what was passed in, we need to drop
// this write and refresh the series type map.
seriesErr = tsdb.ErrFieldTypeConflict
e.seriesTypeMap.Insert(keyBuf, int(typ))
continue
}
// Doesn't exist, so try to insert
vv, ok := e.seriesTypeMap.Insert(keyBuf, int(iter.Type()))
// We didn't insert and the type that exists isn't what we tried to insert, so
// we have a conflict and must drop this field/series.
if !ok || vv != int(iter.Type()) {
seriesErr = tsdb.ErrFieldTypeConflict
continue
}
} else if v != int(iter.Type()) {
// The series already exists, but with a different type. This is also a type conflict
// and we need to drop this field/series.
seriesErr = tsdb.ErrFieldTypeConflict
continue
}
}
var v Value
// 此处省略的代码为根据具体类型构造v
// 将v追加到对应的Series中
values[string(keyBuf)] = append(values[string(keyBuf)], v)
}
}
e.mu.RLock()
defer e.mu.RUnlock()
// first try to write to the cache
if err := e.Cache.WriteMulti(values); err != nil {
L return err
}
if e.WALEnabled {
if _, err := e.WAL.WriteMulti(ctx, values); err != nil {
return err
}
}
return seriesErr
}
简单概括下,就是验证插入数据的类型是否和它所属Series一致,然后再插入。最后将所有Series写入Cache和WAL中。注意这里先写Cache,其他说先写WAL的博客,可以肯定是抄的,没有自己看过源码。
写入过程到这里就差不多结束了,接下来详细介绍一下存储引擎中的重要数据结构。
数据结构
我们知道,InfluxDB 采用了类似 LSM-Tree 的结构,在内存和磁盘上都有相应的组件。
Cache
这个相当于 memtable,是 InfluxDB 用于内存中的数据结构。Cache 以 TSM 文件的形式定期写入磁盘。
type Cache struct {
// Due to a bug in atomic size needs to be the first word in the struct, as
// that's the only place where you're guaranteed to be 64-bit aligned on a
// 32 bit system. See: https://golang.org/pkg/sync/atomic/#pkg-note-BUG
size uint64
snapshotSize uint64
mu sync.RWMutex
store storer // 实际存放数据的结构
maxSize uint64
// snapshots are the cache objects that are currently being written to tsm files
// they're kept in memory while flushing so they can be queried along with the cache.
// they are read only and should never be modified
snapshot *Cache
snapshotting bool
// This number is the number of pending or failed WriteSnaphot attempts since the last successful one.
snapshotAttempts int
stats *cacheMetrics
lastWriteTime time.Time
// A one time synchronization used to initial the cache with a store. Since the store can allocate a
// large amount memory across shards, we lazily create it.
initialize atomic.Value
initializedCount uint32
}
初始化一个 Cache:
// init initializes the cache and allocates the underlying store. Once initialized,
// the store re-used until Freed.
func (c *Cache) init() {
if !atomic.CompareAndSwapUint32(&c.initializedCount, 0, 1) {
return
}
c.mu.Lock()
c.store, _ = newring(ringShards)
c.mu.Unlock()
}
newring 返回一个 ring 对象,该对象的结构为哈希环,具体细节先不展开,总之写入到 Cache 中的数据实际上就保存到了这里。
Compactor
执行LSM-Tree中的合并操作。
// Compactor merges multiple TSM files into new files or
// writes a Cache into 1 or more TSM files.
type Compactor struct {
Dir string
Size int
FileStore interface {
NextGeneration() int
TSMReader(path string) *TSMReader
}
// RateLimit is the limit for disk writes for all concurrent compactions.
RateLimit limiter.Rate
formatFileName FormatFileNameFunc
parseFileName ParseFileNameFunc
mu sync.RWMutex
snapshotsEnabled bool
compactionsEnabled bool
// lastSnapshotDuration is the amount of time the last snapshot took to complete.
lastSnapshotDuration time.Duration
snapshotLatencies *latencies
// The channel to signal that any in progress snapshots should be aborted.
snapshotsInterrupt chan struct{}
// The channel to signal that any in progress level compactions should be aborted.
compactionsInterrupt chan struct{}
files map[string]struct{}
}