title: Deep Imitation Learning for BimanualRobotic Manipulation
date: 2023-01-15T20:54:56Z
lastmod: 2023-01-19T18:31:57Z
Deep Imitation Learning for BimanualRobotic Manipulation
1 Introduction
文中使用的模型是一个深度的、分层的、模块化的架构。与 baselines 相比,该模型泛化能力更强,并且在一些双臂任务中具有更高的准确率。
原文链接:https://zhuanlan.zhihu.com/p/600106788?
github 仓库:https://github.com/Rose-STL-Lab/HDR-IL
双臂相较于单臂的难点:更高维的连续动作-状态空间、更多的对象交互、更高范围的解。
目前大多数的双臂问题都是使用经典的控制方法来解决的,其中环境和动态都是已知的。由于在复杂的交互中,两臂与物体间会产生摩擦、粘附和变形,这些模型很难明确地构建出来,精确度也不是很高。一种有效的方法是模仿学习(imitation learning),即令专家为机器人提供期望行为的演示(输入状态和与状态对应目标动作的感知序列),机器人学习一个策略去模仿专家。另外,最近的深度模仿学习已经成功的只使用图像作为观测信息来学习单臂操作。
文章目标是设计一个模仿学习模型,实现从复杂动态的环境(需要与多个物体交互才能实现目标的任务)中捕获关系信息(如一段轨迹涉及到的与环境中其它物体的关系)。模型需要有足够的泛化能力,以便在不同的变化下完成任务,例如机器人和物体的初始设置的改变。
该文章通过如图所示的两级框架来实现上述目标。该图展示了桌子的装配和移动任务,即抓取桌子的两半,把其中一半插入另一半中,然后放置组装好的桌子。

原语(primitives),一般是指由若干条指令组成的程序段,用来实现某个特定功能,在执行过程中不可被中断。在本文中,指用于实现一个小任务的有序状态序列。
作者没有针对整个轨迹去学习策略,而是将整个过程分成任务原语 (=subsequences of states),如图中最上面一排所展示的一样。作者学习了两个模型:
- a high-level planning model:预测一段原语序列
- a set of low-level primitive dynamics models:预测机器人状态的序列,以完成每段确认的任务原语。
所有的模型都通过递归图神经网络实现参数化,能够明确捕获机器人与机器人之间、机器人与物体之间的交互。
作者完成了以下贡献:
- 提出一个 DIL 框架:Hierarchical Deep Relational Imitation Learning (HDR-IL)。用于双臂操作任务,该模型能够明确捕获多物体环境的关系信息。
- 采用了分层的方法,分别学习 a high-level planning model 和 a set of low-level primitive dynamics models。合并相关特征,使用递归图神经网络来参数化所有模型。
- 评估了两个不同的移桌子任务。结果表明,对于测试集上的任务,分层建模和关系建模都提供了显著改进。对于上图所示的任务,模型达到了 29% 的成功率,而 baselines 只有 1%。
2 相关工作
抽象时间扩展动作的概念已经在层次强化学习(HRL)中被研究了几十年,其目的是减少动作搜索空间和采样复杂度。parameterized skills 和 primitives 的概念是一个不错的例子,skills 是预定义的,skills 序列是学习出来的。这种分层建模的方法已经在机器人和强化学习中广泛地运用,产生了更结构化的离散-连续动作空间。对该动作空间学习能够自然地分解成应用了不同原语的多个阶段。
以前使用专家数据来学习技能序列的工作要么依赖事先定义好的原语函数,要么使用例如隐马尔可夫模型的统计学模型。预定义的原语函数很难去表达复杂的动态过程。最近,文献[24][25]应用预训练的深度神经网络来从输入的状态中识别原语。分层模仿学习从专家数据中学习原语,但不使用相关模型。
本文作者学习了更精准的动态模型来支持双臂模仿学习任务。最近,**图神经网络(graph neural networks ,GNNs)**已在一些应用中被用于建立复杂物体动态模型,图模型已被用于建模两个物体间的物理交互。在机器人领域中,通常把机器人建模成由 关节对应的节点 和 机器人连杆对应的边组成的图。
本文的主要工作:
- 将运动过程分解为多个基本的运动原语;
- 使用**循环图神经网络(recurrent graph neural network)**捕获交互,以参数化每个初值;
- 将按顺序组合原语的高级规划器,和结合动态原语与逆运动学控制的低级控制器结合到一起。
3 Background
我们使用马尔可夫决策过程[^1]的框架来描述模仿学习。MDP 被定义为一个元组(S, A, T, R, γ),S 是状态空间,A 是动作空间, T : S × A → ∆ ( S ) T : S × A → ∆(S) T:S×A→∆(S) 是转移函数, R : S × A → R R : S × A → \mathbb R R:S×A→R 是奖励函数,γ 是折扣因子。在模仿学习中,我们给出一个来自专家策略 π E π_E πE 的演示集 { τ ( i ) = ( s 1 , a 1 , ⋅ ⋅ ⋅ ) } i = 1 D \{τ^{(i)} = (s_1, a_1, · · ·)\}^D_{i=1} {τ(i)=(s1,a1,⋅⋅⋅)}i=1D ,目的是从 { τ ( i ) } i = 1 D \{τ^{(i)} \}^D_{i=1} {τ(i)}i=1D 中学习一个策略 π θ π_θ πθ 来模仿专家策略。模拟学习需要大量的演示来解决长范围问题,可以通过分层模仿学习来缓解。
在分层模仿学习中,有一个典型的两级层次结构:一个高级的规划策略和一个低级的控制策略。高级规划策略 π h π_h πh 生成一段原语序列 ( p 1 , p 2 , ⋅ ⋅ ⋅ ) (p^1 , p^2 , · · ·) (p1,p2,⋅⋅⋅)。在机器人操作中,一个原语 p k ∈ P p^k ∈ P pk∈P 对应一个参数化的策略,该策略将状态映射为动作 π p k : S → A π_{p^k} : S → A πpk:S→A ,常用于实现子目标,如抓取和移动。每个原语 p k p^k pk 会生成一个低级的状态轨迹 ( s 1 k , s 2 k , ⋅ ⋅ ⋅ ) (s^k_1 , s^k_2, · · ·) (s1k,s2k,⋅⋅⋅)。给定一个原语 == p k p^k pk 和初始状态 s t s_t st,==我们打算去学习一个策略来生成一个状态序列,可以使用一个逆运动学(IK)求解器来获得机器人的控制动作 ( a 1 k , a 2 k , ⋅ ⋅ ⋅ ) (a^k_1 , a^k_2, · · ·) (a1k,a2k,⋅⋅⋅)。
4 Methodology
作者提出了一个分层框架,用于双臂操作的规划和控制。如图 2 所示,该框架结合了一个高级规划模型和一个低级的原语动态模型,用来预测包含 N 个状态的序列。该序列分为 K 个原语 == p 1 , ⋅ ⋅ ⋅ , p K p_1, · · · , p_K p1,⋅⋅⋅,pK,每个原语都由一个固定包含 M = N / K M = N/K M=N/K 个状态的轨迹组成==。高级规划模型基于之前的状态 ( s 0 , . . . s t − 1 ) ↦ p t (s_0, ...s_{t−1}) \mapsto p_t (s0,...st−1)↦pt 来选择一个原语。低级原语动态模型使用被选中的原语 p t = p k p_t = p^k pt=pk,预测之后的 M 步(即未来的 M 个状态) s t − 1 ↦ ( s t k . . . s t + M k ) s_{t−1} \mapsto (s^k_t...s^k_{t+M}) st−1↦(stk...st+Mk)。逆运动学求解器将预测出的状态序列转为机器人的控制动作 ( a 1 k , a 2 k , ⋅ ⋅ ⋅ ) (a^k_1 , a^k_2, · · ·) (a1k,a2k,⋅⋅⋅)。
接下来首先介绍低级控制模型和作者对该模型的贡献,高级规划模型和低级控制模型在构建上有许多共同特征。

4.1 Low-level Control Model
在模仿学习方法中,使用**循环神经网络(RNN)的 Sequence to sequence models 已被有效地使用。我们介绍一种通过变分自编码器(variational auto-encoder,VAE)**生成的随机分量来产生一个潜在状态分布 Z t ∼ N ( µ z t , σ z t ) Z_t ∼ N (µ_{z_t} , σ_{z_t} ) Zt∼N(µzt,σzt)。解码器从分布中采样出潜在状态 z t z_t zt,并生成输出序列。作者以此设计为基础,在多个方面进行创新,以执行高精度的双臂操作任务。
关系特征 Relational Features (Int-输入)
传统的 RNN encoder-decoder model 假设不同的输入特征是独立的,而机械臂和物体具有很高的相关性。为了捕获这些依赖关系,作者为 ==编码器 引入了 图注意力 (graph attention,GAT) 层==,从而形成 graph RNN(注:这和 GraphRNN 不是一个东西)。作者构建了一个全连接的图,其每个节点都对应着状态中的特征维度。GAT 模型的注意力机制通过训练来学习边缘权重。给定两个物体的特征 h u h_u hu 和 h v h_v hv,计算边缘注意力系数 e u v e_{uv} euv,根据 GAT 注意力来更新 e u v = a ( W h u , W h v ) e_{uv} = a(Wh_u,Wh_v) euv=a(Whu,Whv),其中 W 是共享的可训练权重。这些系数被用于获得注意力: α u v = s o f t m a x ( e u v ) α_{uv} = softmax(e_{uv}) αuv=softmax(euv)。通过 h u = σ ( ∑ v ∈ N u α u v W h v ) h_u = σ( {\textstyle \sum_{v\in \mathcal{N} _u }^{}}\alpha _{uv}Wh_v ) hu=σ(∑v∈NuαuvWhv) 来更新 GAT 特征,其中 N u \mathcal{N} _u Nu 是 u 的相邻节点。该模型允许我们学习参数,以捕获两个物体间的关系信息。处理关系特征的 GAT 层如图 2 中的 Int 所示。
残差链接 Residual Connection (Res-返回)
该动态模型的另一个重要组成部分是一个 残差链接(residual skip connection),它将目标物体的特征,如要移动的桌子,链接到 encoder GRU 的最后一个隐藏层。使用残差连接有助于学习编码器中的复杂特征。文章中使用残差链接有助于突出目标,在本例中突出的是目标物体的特征,如图二所示。
模块化运动原语 Modular Movement Primitives (Multi)
原语体现了基本的运动模式,如抓取、移动和转动。一个对所有动态原语都通用的模型受限于它的表示能力和对复杂任务的泛化能力。因此,作者采用了模块化方法来建立动态原语模型。另外,作者对每一个原语都设计了一个单独的神经网络模块,每个神经网络捕获特定类型的动态原语。对每个原语模块,作者采用相同的带有残差链接的 Graph RNN 结构。对于由 K 个有序原语组成的任务,每个原语有 M 步,每个模块都近似于原始策略 π p k π_{p^k} πpk,该策略提供了一个状态轨迹 ( s 1 k , s 2 k , ⋅ ⋅ ⋅ ) (s^k_1 , s^k_2, · · ·) (s1k,s2k,⋅⋅⋅)。每个原语的最后一个状态用于作为下一个原语的初始状态,由高级规划模型进行预测。
逆运动学控制器 Inverse Kinematics Controller
逆运动学的介绍在这里不多赘述。在每个时间步长中,将末端执行器的预测状态作为 IK 求解器的输入。
4.2 High-level Planning Model
高级规划模型的目标是要学习一个策略 π h π_h πh,它将观测到的状态序列映射为预定义的原语序列 π h : S → P π_h : S → P πh:S→P。每个确定的原语 p k p^k pk 选择相应的原语动态策略 π p k π_{p^k} πpk,用于之后的 low-level control。总的来说,规划模型输入之前的所有状态,并推断出下一个原语: s 0 , s 1 , . . s t − 1 ↦ p t s_0, s_1, ..s_{t−1} \mapsto p_t s0,s1,..st−1↦pt。
与低级控制模型相似,捕捉环境中的物体交互对原语序列的精准预测很重要。因此,我们使用 Section 4.1 提到的 graph RNN model,并在输入中引入 relational features Int。作者省略了残差链接,因为对于原语识别来说没有必要。该结构的可视化如下图所示:

4.3 Supervised Training
规划模型和控制模型使用监督学习的方式来分别训练。其中规划模型使用手动标注的专家数据来训练,以将状态序列 s 1 , ⋅ ⋅ ⋅ , s t − 1 s_1, · · · , s_{t−1} s1,⋅⋅⋅,st−1 映射成 a primitive label p t = k ∈ [ 1 , . . . , K ] p_t = k ∈ [1, . . . , K] pt=k∈[1,...,K]。我们使用交叉熵损失(cross entropy loss),在正确原语的监督下学习标签。primitive dynamics model 是端到端的训练,使用在所有时间步长上,每个预测状态 s ^ t \hat s_t s^t 上的均方差损失。在多模型框架中,每个原语使用自己的动态模型参数进行训练。
5 Experiments
作者模拟了两个使用双臂的桌子搬运任务,通过测试具有不同桌子起始位置的模型来演示该模型的泛化性。
5.1 Experimental Setup
机械臂:Baxter,仿真器:PyBullet。
Baxter 的每支手臂有七个自由度,导入该机器人的 URDF 文件,其中机械臂连杆无重量。
仿真数据 data 由末端执行器和每个物体的 position(xyz coordinates) 和 orientation(4 quaternions)组成。
在仿真中,专家数据(即演示集)被标注为单独的原语,一起进行排序来生成仿真数据。==每个原语函数都被参数化,因此能适应不同的起始坐标和结束坐标。==原语的选择使其有不同的轨迹动态(如上移和横移),每个原语为末端执行器生成了一个包含 10-12 个状态的序列,状态数量通过仿真实验来选择。对于每个原语,需要让状态数量取最小值,以保证产生平滑的非线性轨迹,因为过多的状态会增加预测的复杂度。之后使用逆运动学方法将状态转为用于机械臂仿真的动作。
后面,作者使用不同的模型测试下列两个任务,对所选模型的仿真结果进行了比较,具体不再赘述。
5.2 Table Lifting Task

5.3 Peg-in-Hole Task

6 Conclusion and Future Work
作者提出了一种新的深度模仿学习框架,用于学习双臂操作任务中的复杂控制策略。该框架引入了一个用于原始选择和原始动态建模的两级层次模型,利用图结构和残差连接来对对象的动态交互进行建模。在仿真中,该模型在两个复杂任务上展示出良好的结果。未来的工作包括直接从视觉输入中估计物体的姿态。另一个有趣的方向是自动原语识别,这将极大地提高在新任务中训练模型的标注效率。
A Model Details
后面是该文章的附录部分,笔者对其中的几个部分进行探讨:
A.2 Data Pre-processing
在 table lift task 中,使用了 2500 个专家数据进行训练,这些数据是起始位置均匀分布在 20-60 cm 范围内的。测试时使用了 127 个起始位置。对于 peg-in-hole 任务,使用了 4700 个专家数据来进行训练,使用 281 个随机位置来进行测试。在预处理中,移除了使任务失败的专家数据。
A.3 Dynamic Model Details
A.3.1 Encoder

baseline encoder 由一个以初始状态作为输入的 GRU (门控循环单元,循环神经网络的一种)组成。GRU 的层数对应预计的状态数。初始状态是一个由每个物体的 xyz 坐标组成的向量,与该对象的四元数连接。在训练过程中,使用 teacher forcing,这样 GRU 每层的输入都可以从仿真中获取状态。在测试过程中,除第一层外每层的输入都来自于前一层的输出。最后一个时间点上,GRU 的隐状态(hidden state)通过了全连接层。全连接层数量的改变取决于模型是否是多模型框架的一部分。作者修改了线性层的数量,使单模型和多模型的设计具有相似数量的参数。最后一层将全连接层的维数加倍,将隐藏状态分解为均值和方差,用于 decoder。
Relational Model Int
使用关系特征(relational features)的模型中使用了 graph attention layers(GAT),在 GAT layers 只使用了一个 attention head。
一个节点对应于该状态下的一个对象特征,即 x、y、z 坐标和四个四元数。我们使用一个上标来索引该图层,初始节点特征 h u ( 0 ) h^{(0)}_u hu(0) 是该特征的值。每一层中,节点 u 和 v 之间的边缘注意力系数(edge attention coeffificient) e u v l e^l_{uv} euvl 由下式给出:
e u v ( l ) = a ( W ( l ) h u ( l ) , W ( l ) h v ( l ) ) e^{(l)}_{uv} = a(W^{(l)}h^{(l)}_u,W^{(l)}h^{(l)}_v) euv(l)=a(W(l)hu(l),W(l)hv(l))
对于学习出的层权矩阵(layer weight matrix) W ( l ) W^{(l)} W(l),注意力机制 a 将 inputs 联系起来,将它们乘以一个学习到的权值向量 a ( l ) a^{(l)} a(l),并应用一个非线性:
e u v ( l ) = L e a k y R e L U ( a ( l ) ( W ( l ) h u ( l ) ∣ ∣ W ( l ) h v ( l ) ) ) e^{(l)}_{uv} = LeakyReLU(a^{(l)}(W^{(l)}h^{(l)}_u||W^{(l)}h^{(l)}_v)) euv(l)=LeakyReLU(a(l)(W(l)hu(l)∣∣W(l)hv(l)))
利用 softmax 函数归一化边缘注意系数,来计算注意权重:
α u v = s o f t m a x ( e u v ) α_{uv} = softmax(e_{uv}) αuv=softmax(euv)
节点特征按邻域进行聚合。对于节点 u 及其连接的相邻节点 N u \mathcal{N} _u Nu 的集合,节点特征通过 GAT 更新规则进行更新:
h u ( l + 1 ) = ∑ v ∈ N u α W ( l ) h v ( l ) \large h^{(l+1)}_u=\sum_{v∈\mathcal{N} _u}\alpha W^{(l)}h^{(l)}_v hu(l+1)=∑v∈NuαW(l)hv(l)
图的构建
下图是对于 table lifting 任务,GRU 的第二层中 attention weights 的图结构可视化。节点颜色体现环境中不同的对象,该图中,R 和 L 代表左右两个末端执行器,T 代表桌子,可见的边是 attention weights 大于 8% 的边。没有训练权重的 图卷积神经网络 (graph convolution network,GCN) 会对全部节点假定 4.77% 的平均 attention weights。这支持我们在 GCN 上使用 GAT 来对交互进行建模。可以看到,接收最大权值的两个节点是右夹持器的 y 坐标和左夹持器上的一个四元数。

A.3.2 Decoder
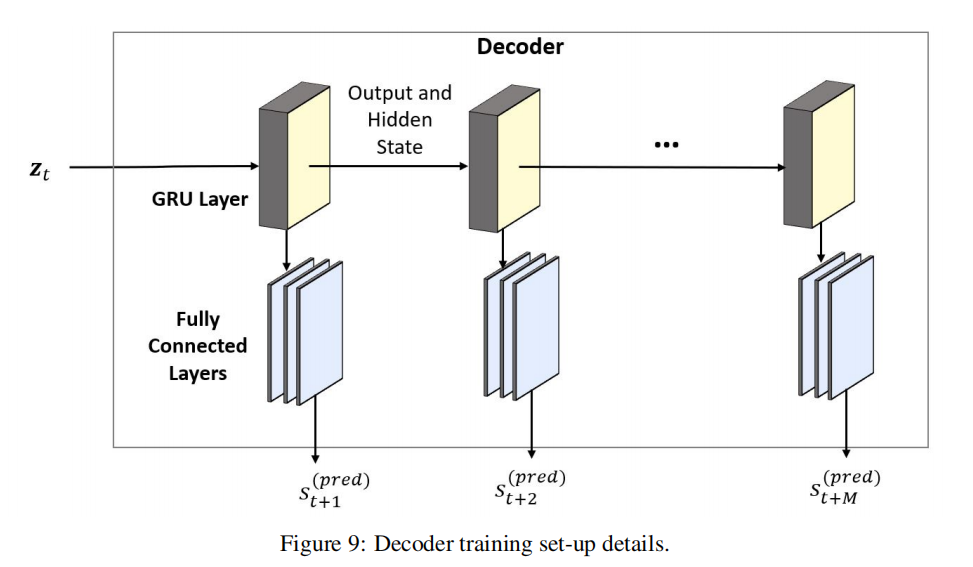
decoder 从 encoder 中获取一个样本潜在空间,该样本是进入 decoder 的 GRU 的初始隐状态。第一层的初始输入是一个张量为零的张量,其余层的输入是来自上一层的输出。在每一层中,GRU 的输出都会经过一系列全连接的层,得到模型的最终输出,该模型体现了每个时间点的状态。