(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
流式语音识别模型 Deepspeech2 与 Conformer
1. 前言
1.1 背景知识
语音识别(Automatic Speech Recognition, ASR) 是一项从一段音频中提取出语言文字内容的任务。
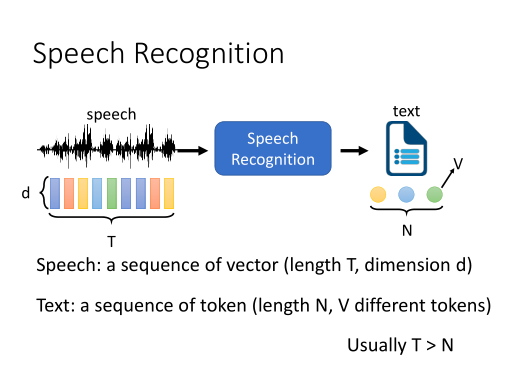
(出处:DLHLP 李宏毅 语音识别课程PPT)
1.2 流式语音识别
用户将一整段语音分段,以流式输入,最后得到识别结果。
实时语音识别引擎在获得分段的输入语音的同时,就可以同步地对这段数据进行特征提取和解码工作,而不用等到所有数据都获得后再开始工作。
因此这样就可以在最后一段语音结束后,仅延迟很短的时间(也即等待处理最后一段语音数据以及获取最终结果的时间)即可返回最终识别结果。
这种流式输入方式能缩短整体上获得最终结果的时间,极大地提升用户体验。
1.3 应用场景
- 人机交互/语音输入法
流式语音识别可以在用户说话的时候实时生成文字,加快了机器对人的反馈速度,使得用户的使用体验得到提升。

(百度智能音箱:https://dumall.baidu.com/)
- 实时字幕/会议纪要
在会议场景,边说话,边转写文本。
将会议、庭审、采访等场景的音频信息转换为文字,由实时语音识别服务实现,降低人工记录成本、提升效率。
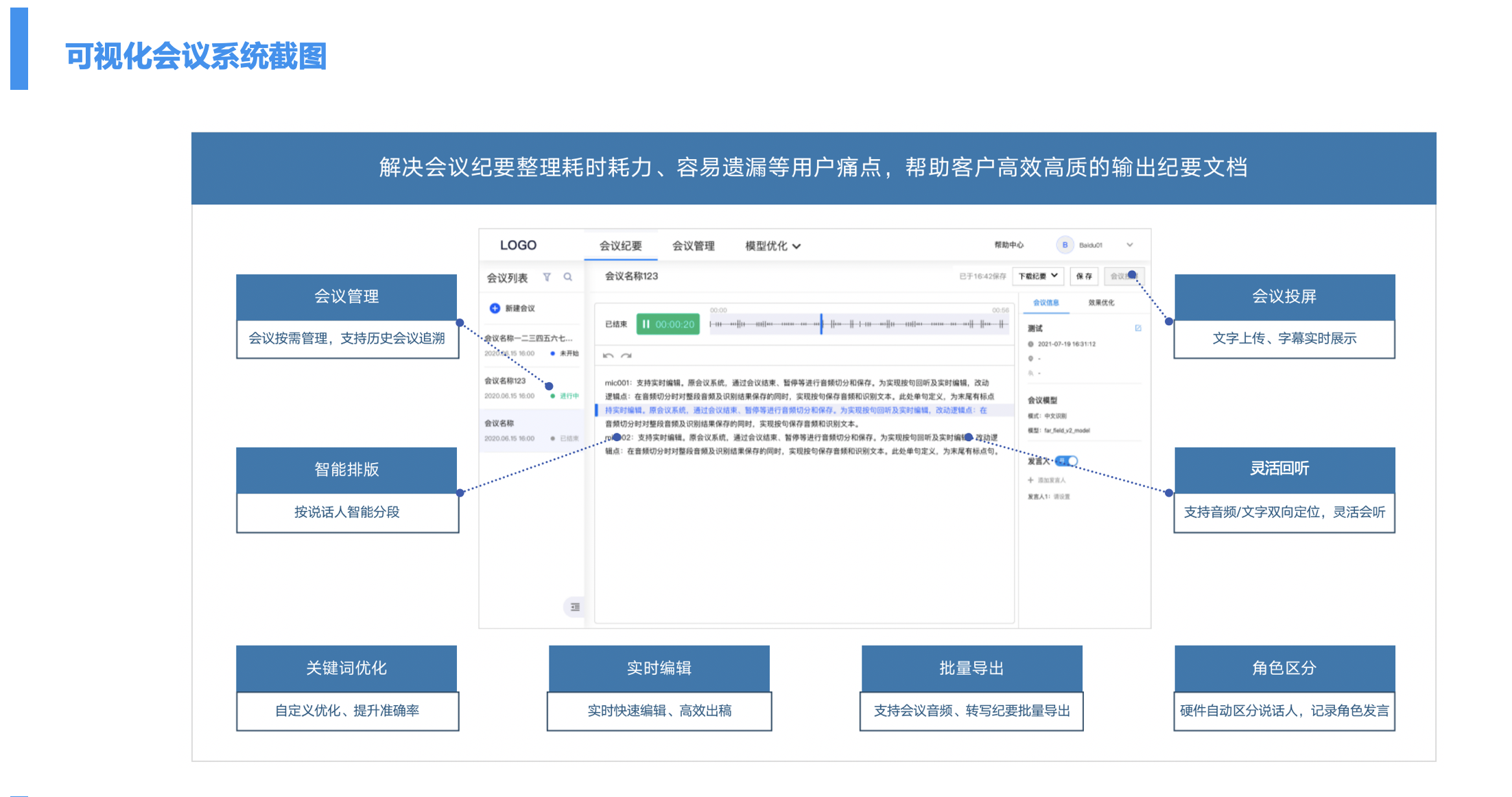
(百度智能会议系统:一指禅)
- 同声翻译
在机器进行同生翻译的时候,机器需要能实时识别出用户的说话内容,才能将说话的内容通过翻译模块实时翻译成别的语言。
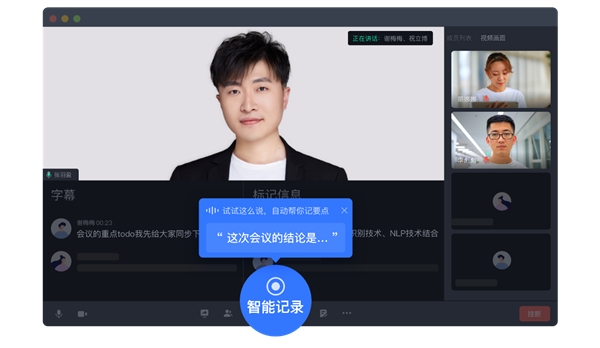
(如流:智能会议 https://infoflow.baidu.com/audio-video/#/)
- 电话质检
将坐席通话转成文字,由实时语音识别服务或录音文件识别服务实现,全面覆盖质检内容、提升质检效率。
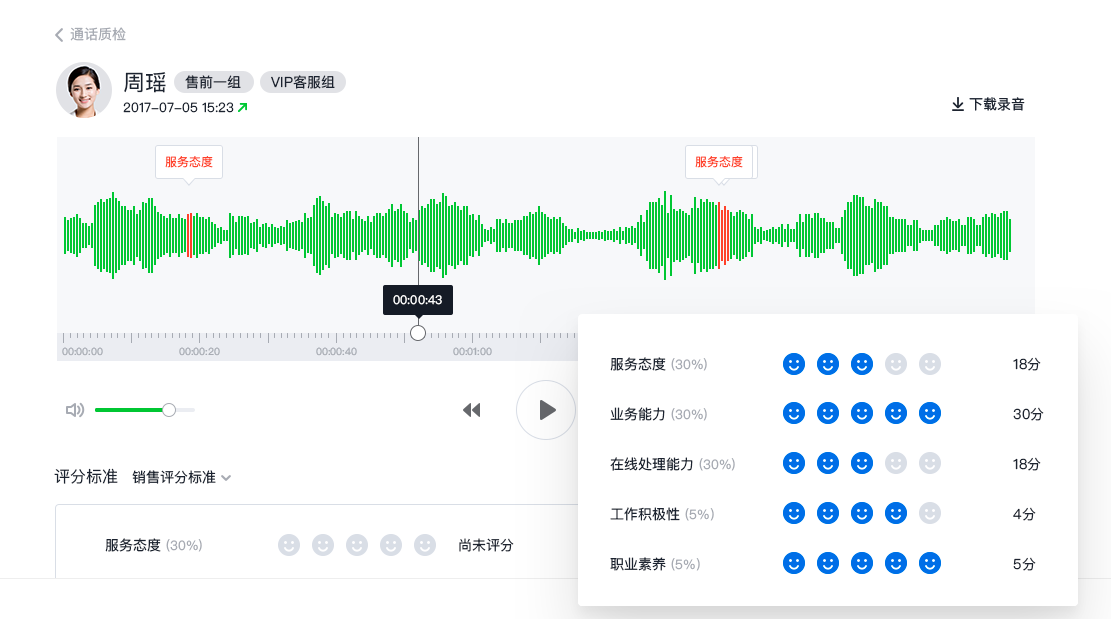
- 语音消息转写
将用户的语音信息转成文字信息,由一句话识别服务实现,提升用户阅读效率。
2. DeepSpeech2 模型流式语音原理
2.1 DeepSpeech2 流式模型
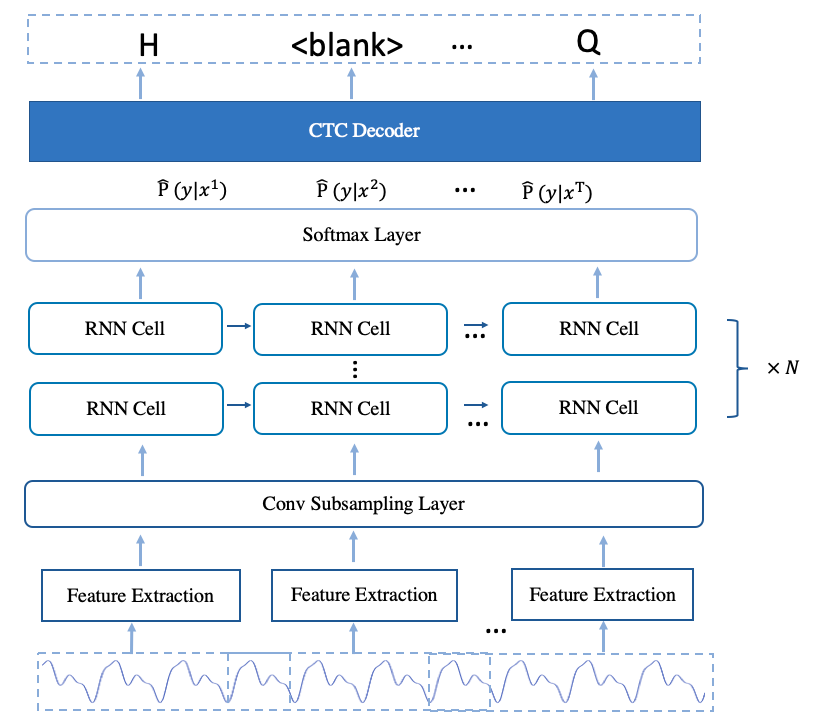
Deepspeech2 模型,其主要分为3个部分:
- 特征提取模块
此处使用 linear/fbank 特征,也就是将音频信息由时域转到频域后的信息。 - Encoder
多层神经网络,用于对特征进行编码。 - CTC Decoder
采用了 CTC 损失函数训练;使用 CTC 解码得到结果。
2.2 流式推理过程
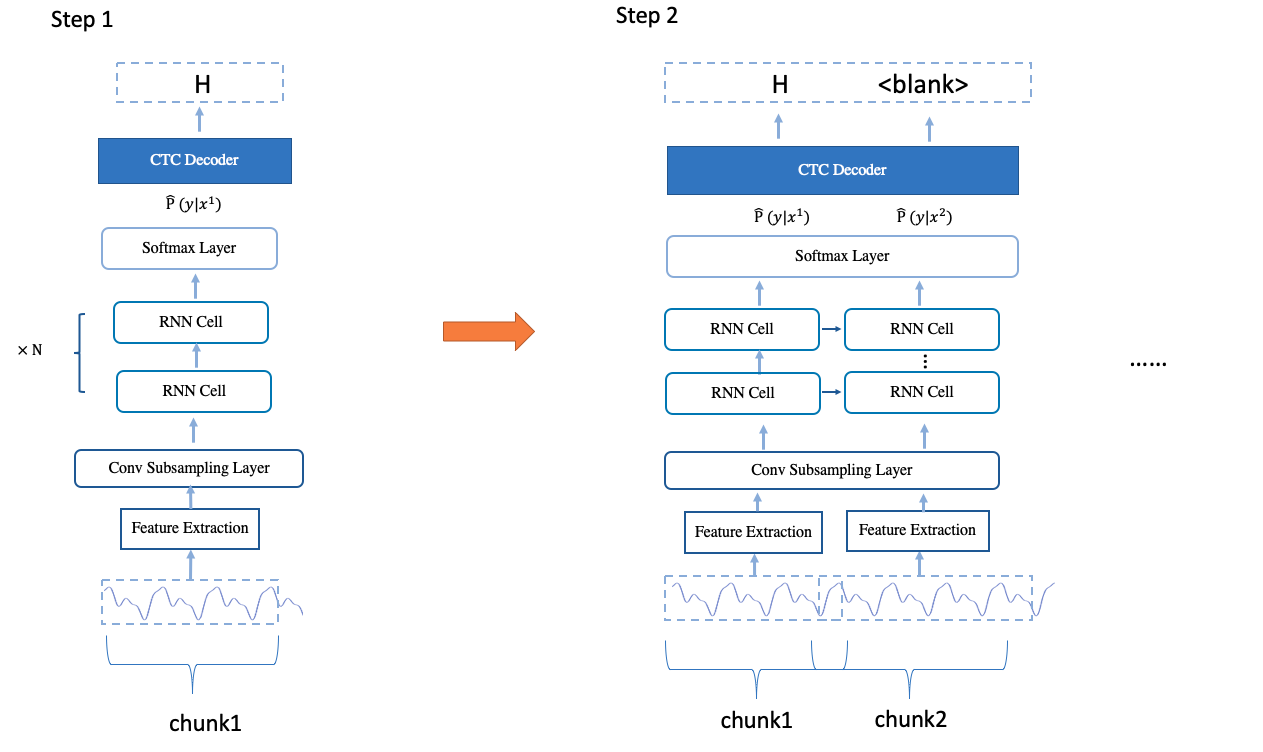
流式语音主要是通过音频 chunk 来实现的。当接收的语音达到了一个chunk的长度后,模型将该 chunk 的语音提取成特征,送入模型当中推理得到结果。
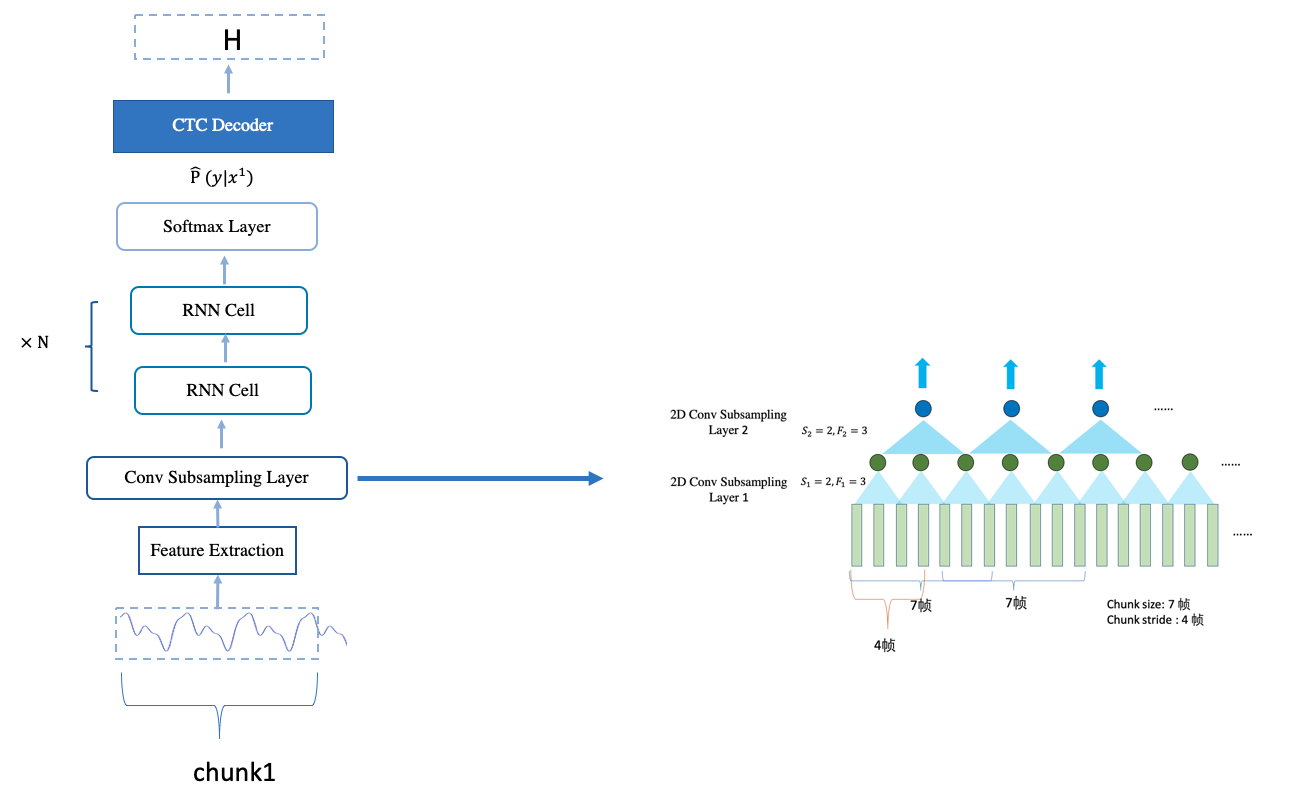
一个chunk 的最小长度与模型本身结构直接相关。 一个 chunk 的长度是模型每一步的输出所需要多长的语音。
对于 DeepSpeech2 模型,其每一步的输出对应 1 步 RNN 的输出 => 1 步 subsampling 层的输出 => 7 帧的输入。 因此,一个chunk的最小长度为7帧数据。
2.3 CTC Decoder
Decoder 的作用主要是将 Encoder 输出的概率解码为最终的文字结果。
对于 CTC 的解码主要有3种方式:
-
CTC greedy search
-
CTC beam search
-
CTC Prefix beam search
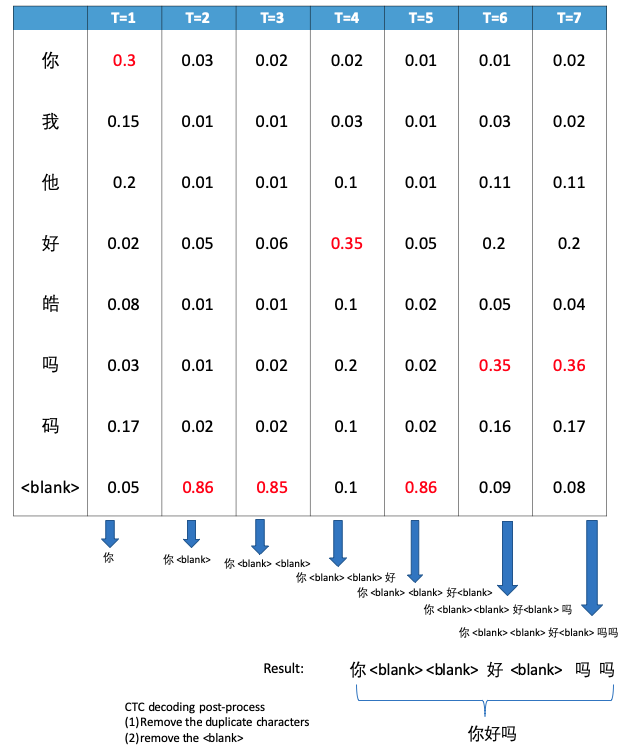
2.3.1 CTC Greedy Search
在每个时间点选择后验概率最大的 label 加入候选序列中,最后对候选序列进行后处理,就得到解码结果。
2.3.2 CTC Beam Search
CTC Beam Search 的方式是有 beam size 个候选序列,并在每个时间点生成新的最好的 beam size 个候选序列。
最后在 beam size 个候选序列中选择概率最高的序列生成最终结果。
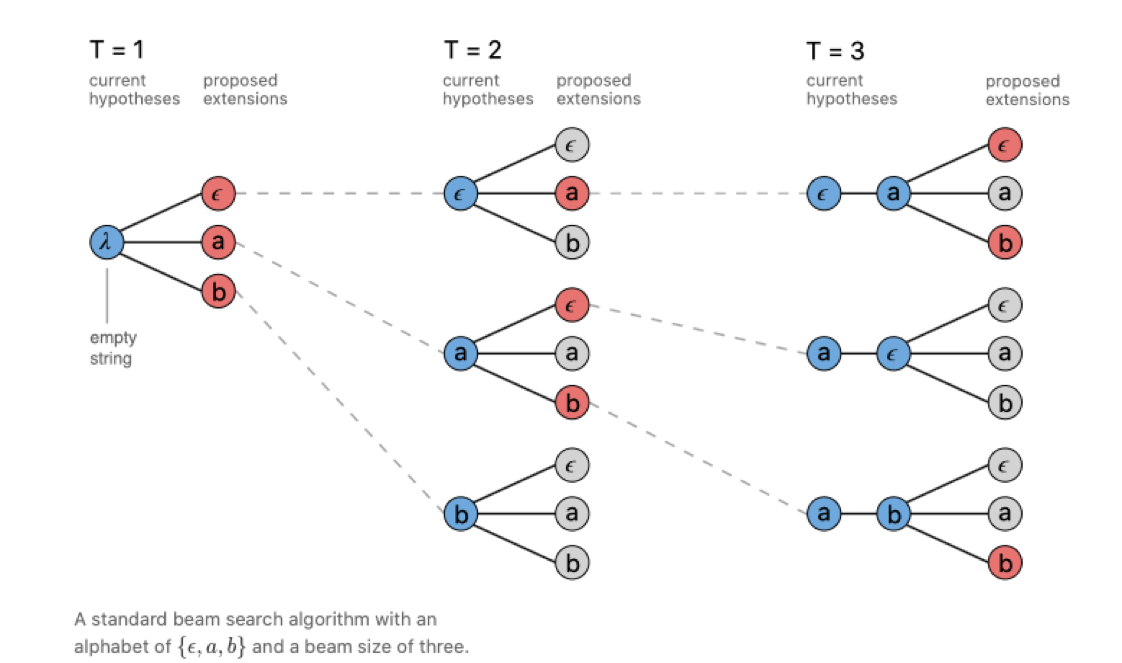
引用自[9]
2.3.3 CTC Prefix Beam Search
CTC prefix beam search和 CTC beam search 的主要区别在于:
CTC beam search 在解码过程中产生的候选有可能产生重复项,而这些重复项在 CTC beam search 的计算过程中是各自独立的,占用了 beam 数,降低解码的多样性和鲁棒性。
而 CTC prefix beam search 在解码过程中合并了重复项的概率,提升解码的鲁棒性和多样性。
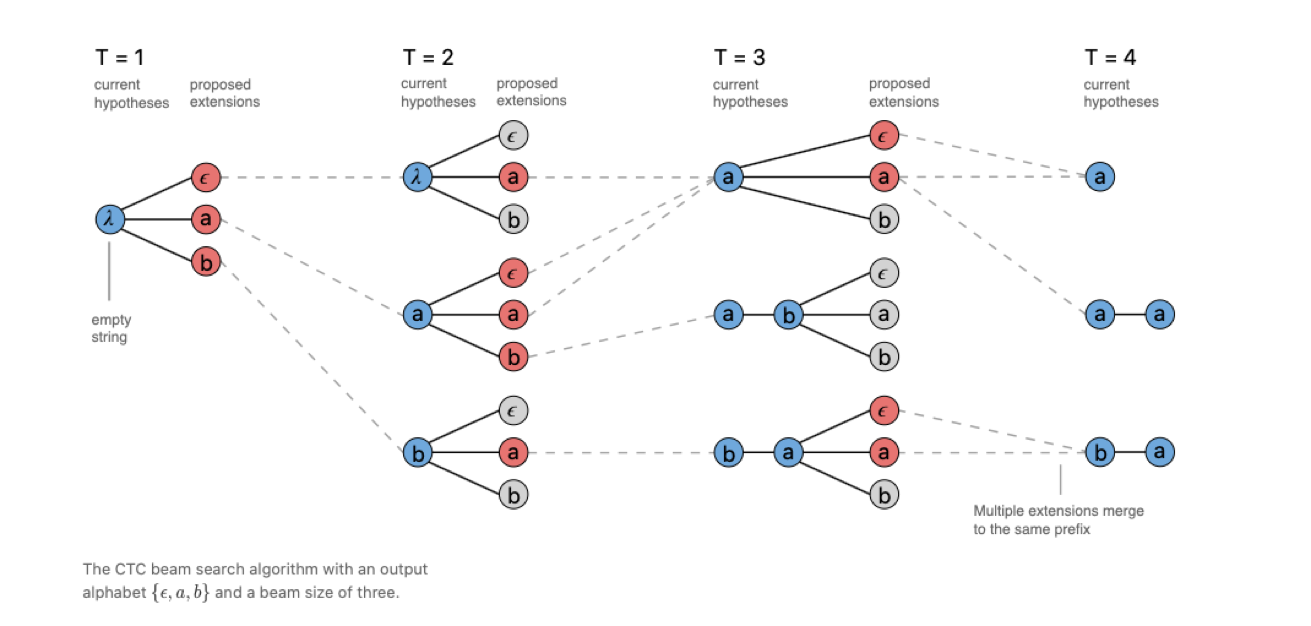
引用自[9]
引用自[9]
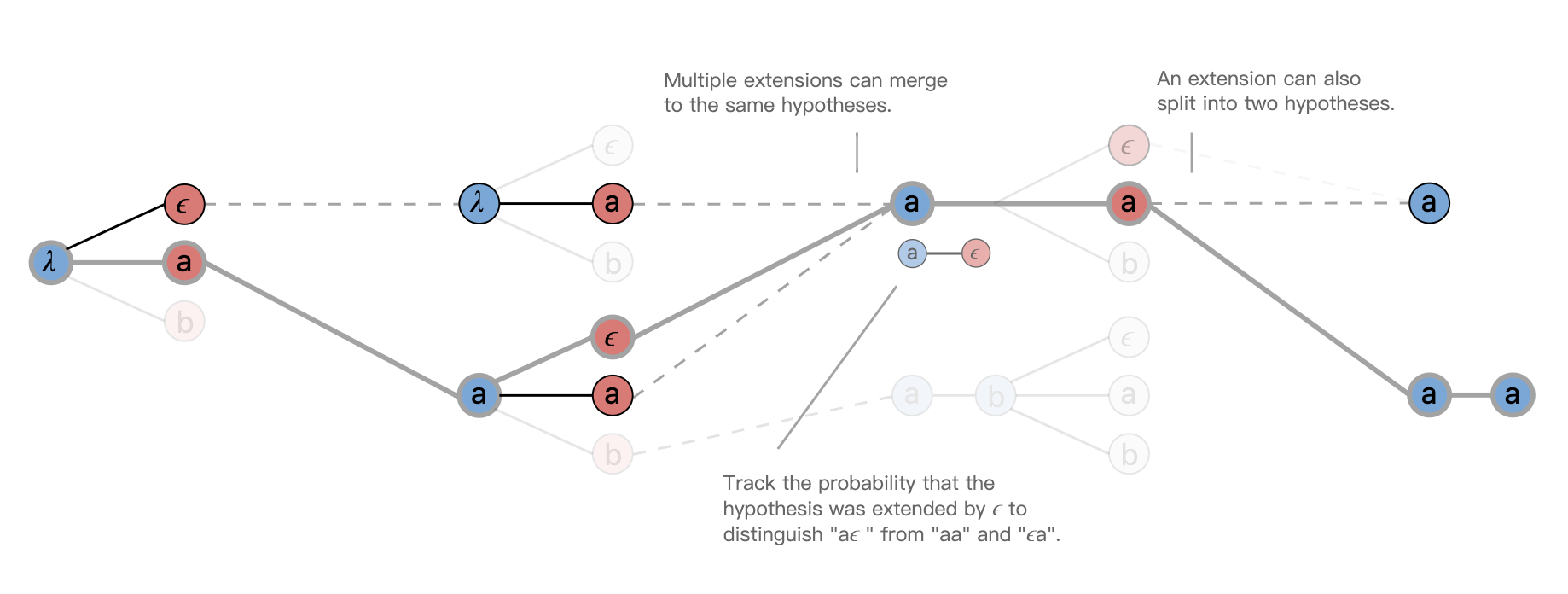
CTC prefix beam search 计算过程如下图所示:

引用自[10]
CTCLoss 相关介绍参看 Topic 内容。
2.3.4 使用 N-gram 语言模型
对于解码的候选结果的打分,除了有声学模型的分数外,还会有额外的语言模型分以及长度惩罚分。
设定
W
W
W 为解码结果,
X
X
X 为输入语音,
α
\alpha
α 和
β
\beta
β 为设定的超参数。
则最终分数的计算公式为:
s
c
o
r
e
=
P
a
m
(
W
∣
X
)
⋅
P
l
m
(
W
)
α
⋅
∣
W
∣
β
score = P_{am}(W \mid X) \cdot P_{lm}(W) ^ \alpha \cdot |W|^\beta
score=Pam(W∣X)⋅Plm(W)α⋅∣W∣β
3. Conformer 流式语音原理
3.1 confomer 模型结构
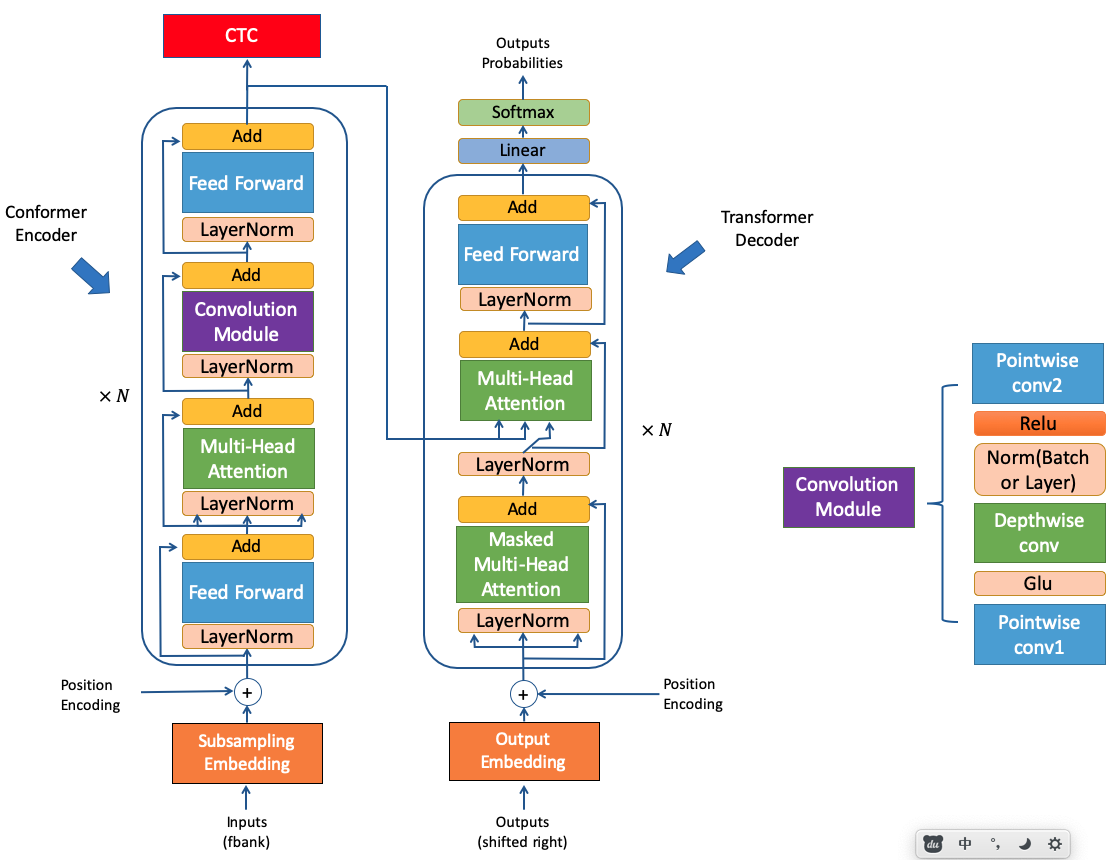
Conformer 主要由 Encoder 和 Decoder 两个部分组成,整体的模型结构和 Transformer 非常相似。
Conformer 和 Transformer 有着相同的 Decoder,主要的区别有2点:
- Conformer 的 Encoder 中包含了 conv 模块。该 conv 模块由 pointwise conv,GLU层,Depthwith conv, RELU层,以及第二层 pointwise conv, 共5个部分组成。
- Conformer 的 Encoder 使用了2层 FeedForward,分别位于每层 encoder的头和尾,并且设置每层输出的权重设置为0.5,整体类似于一个汉堡的结构。
3.2 流式 conformer
流式解码主要分为2个步骤:
- 说话中:使用 CTC prefix beam search 进行解码。
- 说话结束:使用 CTC prefix beam search + attention_rescoring 进行解码。 其中 attention_rescoring 主要是用 decoder 对 ctc 的结果进行重打分,从而改变了 ctc 整句结果的候选排序。
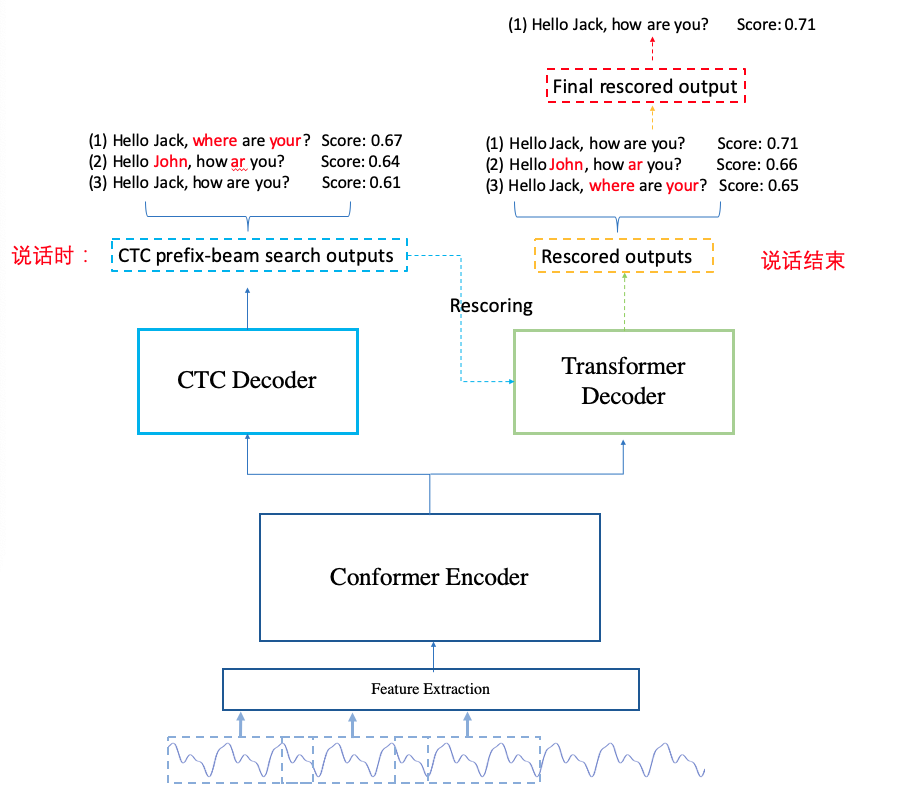
(图片来自"Chao Yang http://placebokkk.github.io/wenet/2021/06/04/asr-wenet-nn-1.html" )
因此,流式解码的核心在于支持流式的 CTC prefix beam search,而流式的 CTC prefix beam search 在于训练一个可以支持流式的 Encoder。
3.2.1 要点1:因果卷积,避免高时延
如果使用通常的卷积网络,如果使用了很多层卷积,网络输出的每一步将会大量依赖当前步后的多帧,从而增大了流式模型的时延,而 conformer 模型中存在大量的 conv 层,因此,如果使用普通的卷积, 流式 conformer 模型的时延会很大。
为了解决这个问题,流式 conformer 使用了 因果卷积。因果卷积的每一步的输出只会依赖之前的时间点,而不会依赖之后的时间点,类似于卷积实现的 RNN 结构。从而避免了 conformer 模型的高时延。
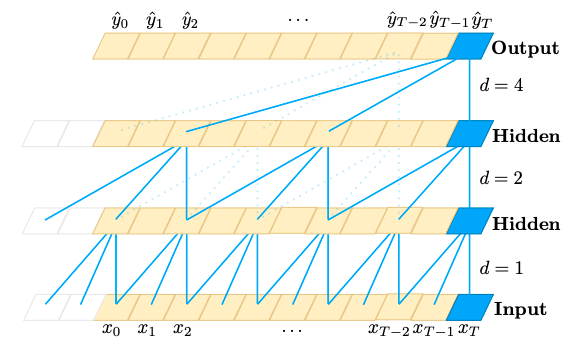
(图片来自"Bai S, Kolter J Z, Koltun V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling" )
3.2.2 要点2:带有 mask 的 attention
实现流式的 Encoder 的主要挑战是 conformer 的 attention 结构通常是使用全局的信息,如下图中第一张子图所示,从而无法实现流式。为了解决这个问题,流式 conformer 在训练的过程中会限制 attention 的作用范围。
关于 attention 的作用范围,主要的策略如下图所示:
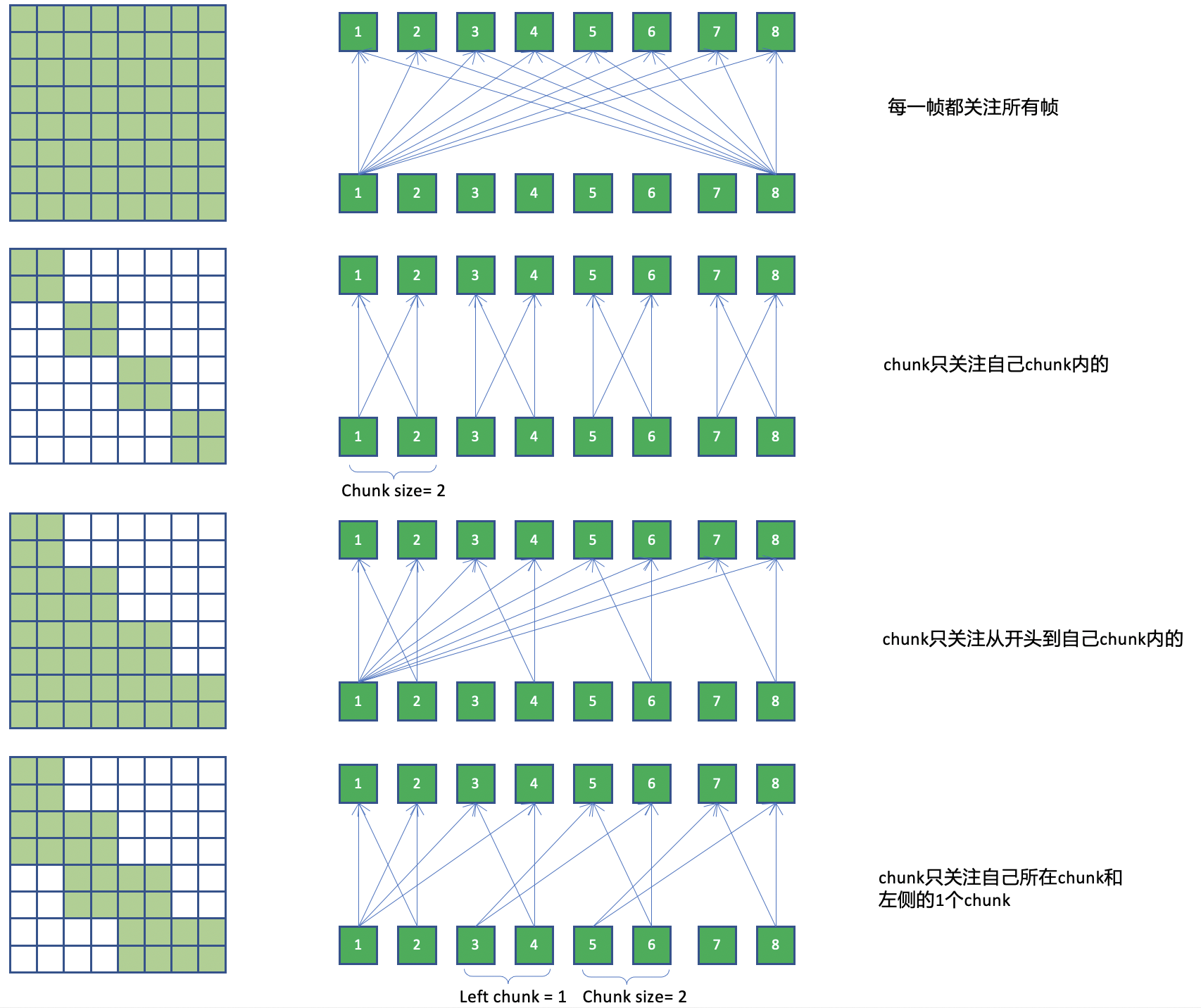
(图片来自"Chao Yang http://placebokkk.github.io/wenet/2021/06/04/asr-wenet-nn-1.html" )
为了尽可能多地使用语音地上下文信息,我们一般使用第三种 attention 作用范围。
在训练的过程中,为了增强模型的健壮性,同时也让模型在解码过程中可以适用于多种 chunk size, 对于每个 batch 的数据,会采用随机的 chunk size 大小进行训练。
而在解码的过程中,我们使用固定的 chunk size 进行解码。
3.2.3 要点 3: cache
conformer 在进行解码的过程中,会使用 cache 来减小冗余的计算量。
conformer Encoder 的 cache 主要分为 3 个 部分:
- subsampling_cache
- conformer_cnn_cache
- elayers_output_cache
# Feed forward overlap input step by step
for cur in range(0, num_frames - context + 1, stride):
end = min(cur + decoding_window, num_frames)
chunk_xs = xs[:, cur:end, :]
(y, subsampling_cache, elayers_output_cache,
conformer_cnn_cache) = self.forward_chunk(
chunk_xs, offset, required_cache_size, subsampling_cache,
elayers_output_cache, conformer_cnn_cache)
outputs.append(y)
offset += y.shape[1]
ys = paddle.cat(outputs, 1)
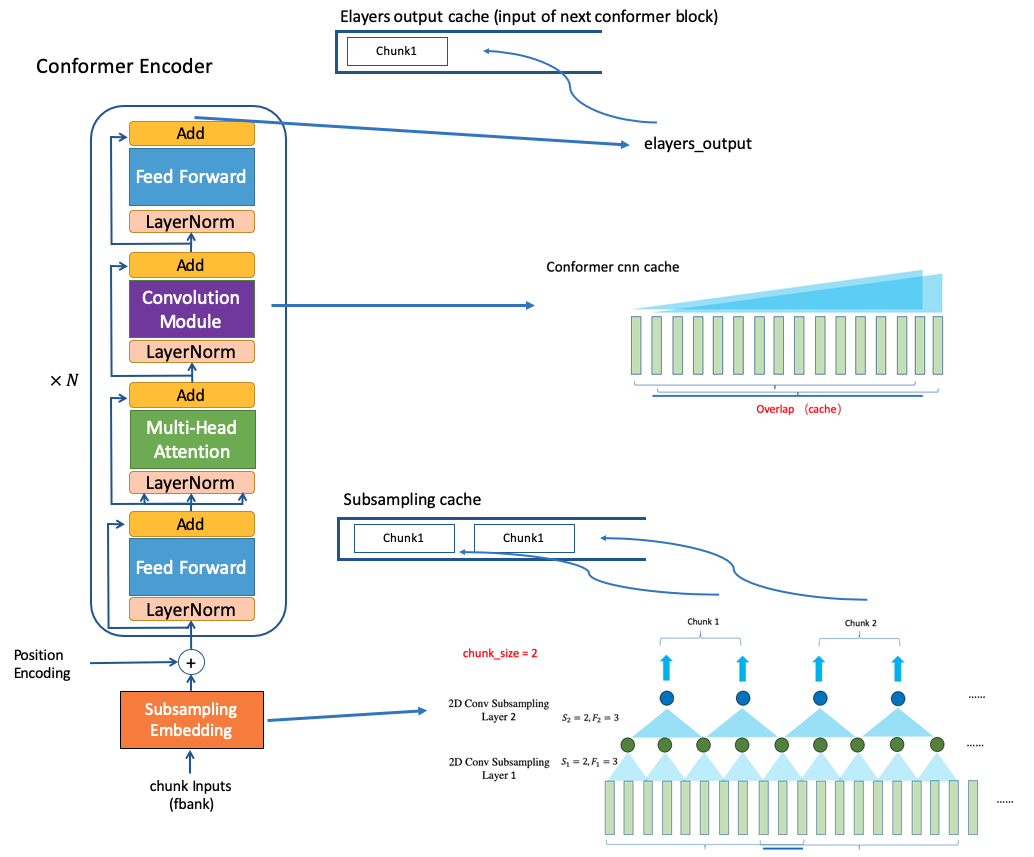
(图片来自"Chao Yang http://placebokkk.github.io/wenet/2021/06/04/asr-wenet-nn-1.html" )
-
subsampling cache: [paddle.Tensor]
subsampling的输出的 cache,即为第一个conformer block 的输入。 用于缓存输入的特征经过 subsampling 模块之后的结果, 而当前的输入 chunk 和 subsampling cache 合并作为 conformer encoder 的输入。conformer 使用的 subsampling 主要由于 2 层 cnn 和一层 linear 构成。 -
conformer_cnn_cache: List[paddle.Tensor]
主要存储每个 conformer block 当中 conv 模块的输入, 由于 conv 模块会依赖之前的帧信息,所以需要对之前的输入进行缓存,节约计算时间。 -
elyaers_output_cache: List[paddle.Tensor]
主要存储当前 conformer block 的历史输出, 从而可与当前 conformer block 的输出拼接后作为作为下一个 conformer block 的输入。
一个非流式的 conformer 模型通过结合以上的 3 个要点,就可以转变为流式的 conformer 模型。
4. 引用
[1] Amodei D, Ananthanarayanan S, Anubhai R, et al. Deep speech 2: End-to-end speech recognition in english and mandarin[C]//International conference on machine learning. PMLR, 2016: 173-182.
[2] Bai S, Kolter J Z, Koltun V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[J]. arXiv preprint arXiv:1803.01271, 2018.
[3] Chao Yang. http://placebokkk.github.io/wenet/2021/06/04/asr-wenet-nn-1.html
[4] Gulati A, Qin J, Chiu C C, et al. Conformer: Convolution-augmented transformer for speech recognition[J]. arXiv preprint arXiv:2005.08100, 2020.
[5] Graves A, Fernández S, Gomez F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks[C]//Proceedings of the 23rd international conference on Machine learning. 2006: 369-376.
5. 作业
- 跑通流式 Deepspeech2 的 serving 部署。
- 跑通流式 Conformer 的 serving 部署。
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。