关注我们 - 数字罗塞塔计划 -
# 大比武2024
本篇是参加“华夏伟业”杯第二届档案信息化公司业务与技术实力大比武(简称“大比武 2024”)的投稿文章,来自广州龙建达电子股份有限公司,作者:陶宣任。
在这个人工智能技术飞速发展的时代,随着大模型的技术能力逐渐成熟,面向行业的垂直大模型开始在各行各业得到应用,比如在档案的收、管、存、用过程中尝试借助行业垂直大模型来辅助管理者实现高效管理。本文通过分析行业垂直大模型的能力与档案管理需求之间的结合方式,探索行业垂直大模型如何提高档案管理效率。
一. 何为行业垂直大模型?
通用大模型通常指的是能够处理各种领域和主题的大型语言模型,例如ChatGPT和Llama 3。通用大模型在多个领域具有广泛的知识和能力,具备能够回答各种问题、提供多领域的信息与支持、自动编程等能力。而行业垂直大模型是指针对特定行业或领域进行微调训练的大型语言模型,这些模型会基于特定行业的数据和应用场景进行微调,以提供更专业和精确的信息和支持。例如在档案行业中,可以构建一个专门针对档案收集、整理、检索、利用等场景进行微调的档案行业垂直大模型(以下简称“档案大模型”)。
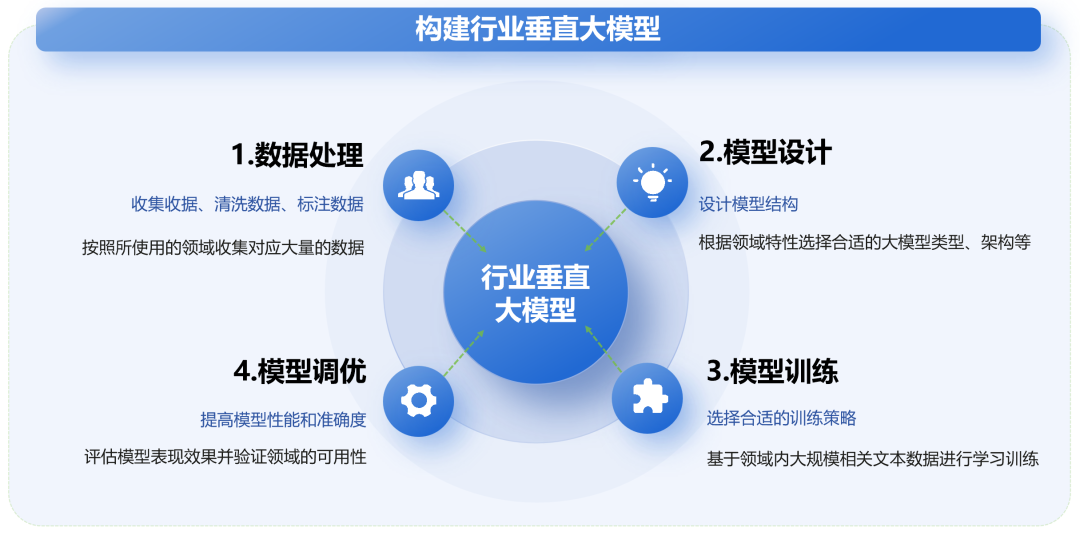
二. 档案管理过程中的创新应用场景
在传统档案管理过程中,随着文件类型、档案数量的增加,对于档案工作者而言,无疑大幅度增加了他们的日常工作压力,从档案的接收、整理、保管,再到检索利用,每份档案的生命周期都需要工作者干预。为此,根据档案管理流程,结合实际业务情况,总结出档案管理过程中可以进行创新建设的应用场景:

01 档案自动化整理
档案整理工作往往是重复而又繁琐,需要对大量待归档的电子文件进行元数据收集、分类、组件、编号、编目、归档等人工操作,希望可以通过技术手段自动化处理档案整理中的一系列任务,人工只需审核整理结果而无需进行整理工作,从而将档案工作者从繁重的档案整理工作中解放出来。
02 构建档案信息“大脑”
在传统的档案检索过程中,由于检索引擎技术限制,且著录信息有限,常用的目录检索或是关键字检索等传统方式,往往只能对档案数据库中的结构化数据信息进行检索,查全率和查准率都不尽如人意。需要借助工具自动学习各类档案中的内容,构建档案信息“大脑”,利用者无需通过检索方式来获取所需信息,只需通过“自然语言交互方式”即可,快速实现有关档案的相关问题解答或是精准全面的档案查询利用。
03 档案智慧编研
传统档案编研受限于档案检索功能的不完善以及编研人员的个人知识结构,许多珍贵、有价值、和主题相关度高的档案无法进入编研范围,进而影响到编研成果。利用先进的AI技术对海量档案数字资源进行智能识别,自动完成档案信息的整理和归集,并智能根据编研主题类型和格式要求生成报告,输出各种格式的编研成果,实现档案编研的智能化。
三. 构建档案行业垂直大模型
档案业务的主要工作有接收、整理、鉴定、保管、检索、利用、编研、统计等,事实上,每个业务过程都可以借助行业垂直大模型来辅助操作,进而实现档案管理的变革创新,提高档案管理效率。
档案大模型具体实现方式如下:
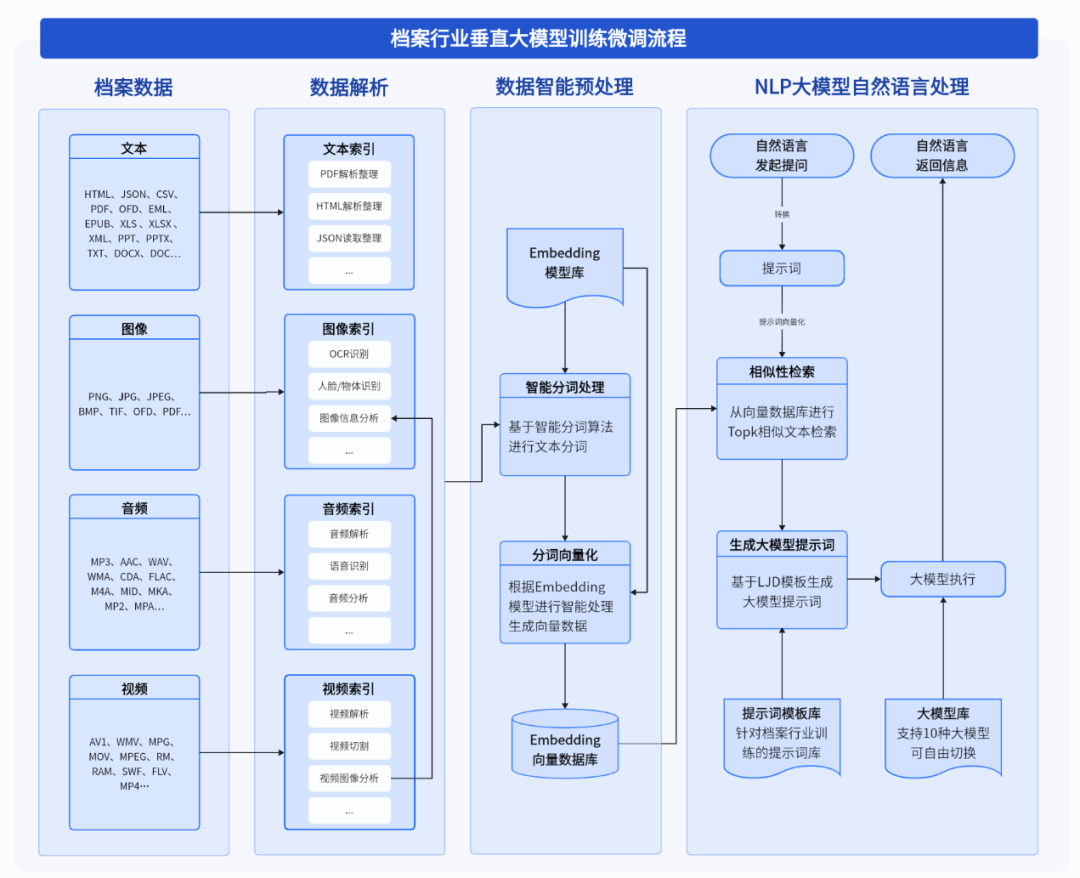
01 行业垂直大模型本地化
不同于通用大模型,行业垂直大模型具备本地化学习的能力。由于档案的特性,档案大模型不能采用互联网模式,需通过NLP等技术对本地档案数据进行不断训练和学习。档案大模型本地应用流程示意图如下:
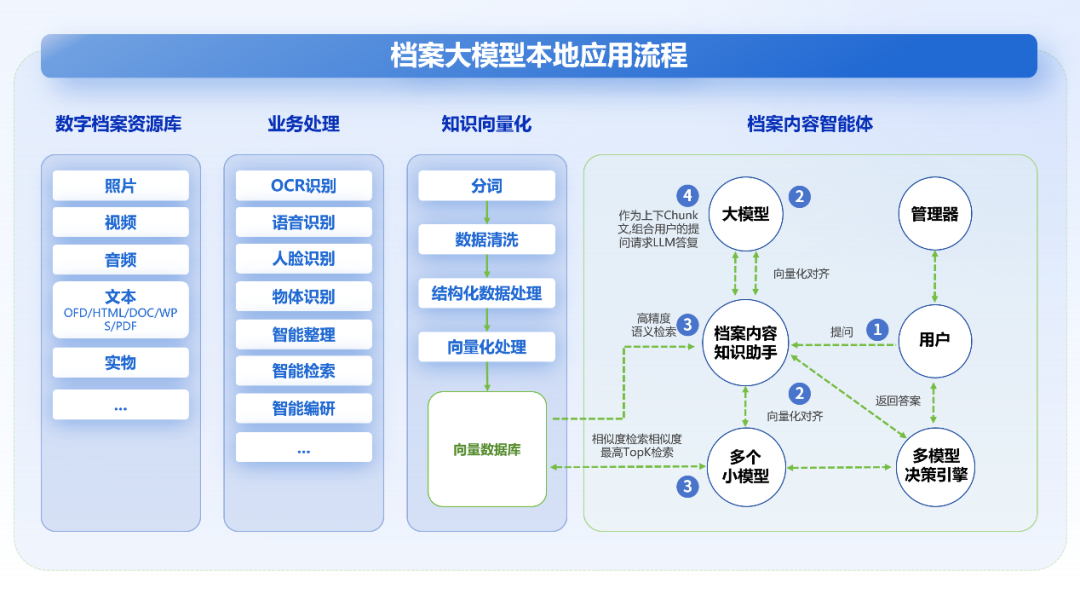
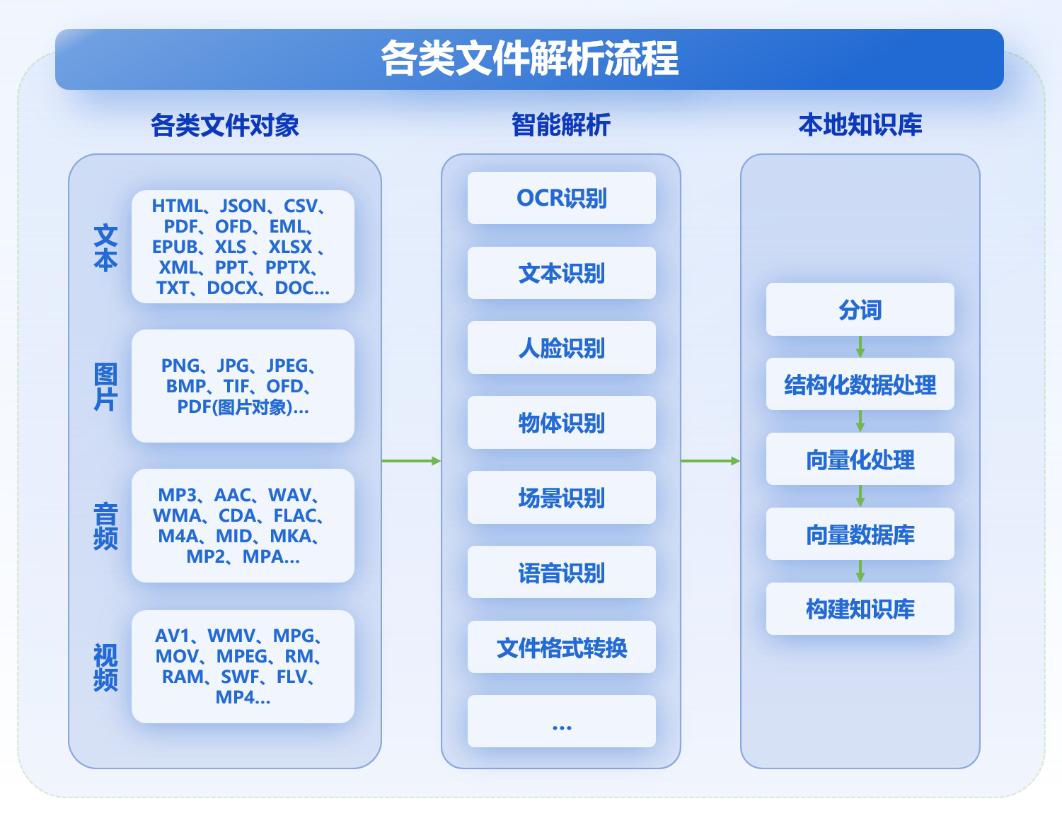
02 支持“学习”各类文件
通用大模型一般只支持纯文本交流,而电子档案的文件格式多种多样,档案大模型本地化后必须做到“不挑食”。其具有强大的各类文件解析学习能力,可对档案库中的常见文件类型进行学习,如文书档案的PDF/OFD/XML格式、照片档案的JPEG格式、音频档案的MP3格式、视频档案的MP4格式等等,这样才能真正辅助管理档案。文件解析流程示意图如下:
03 理解“人话”
基于本地档案数据构建档案知识库,利用档案大模型的自然语言交互能力和理解能力,借助向量数据库的加持,搭建一个“AI智能问答系统”。实现能以自然语言问答方式进行档案的“问答式利用”,要求该系统能理解“人话”,能以人的方式进行思考,并能通过“人话”和管理员进行沟通。
四. 使用行业垂直大模型赋能应用场景
依托档案大模型,就可以赋能档案自动整理、AI智能问答、智慧编研等创新应用场景了,从而实现档案高效管理。
01 档案自动高效整理
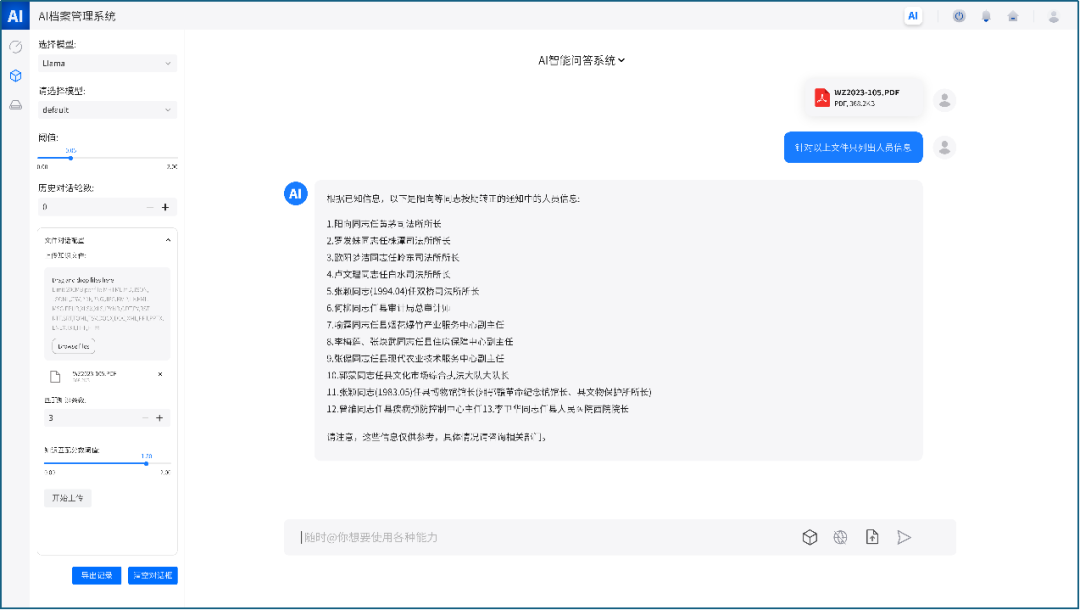
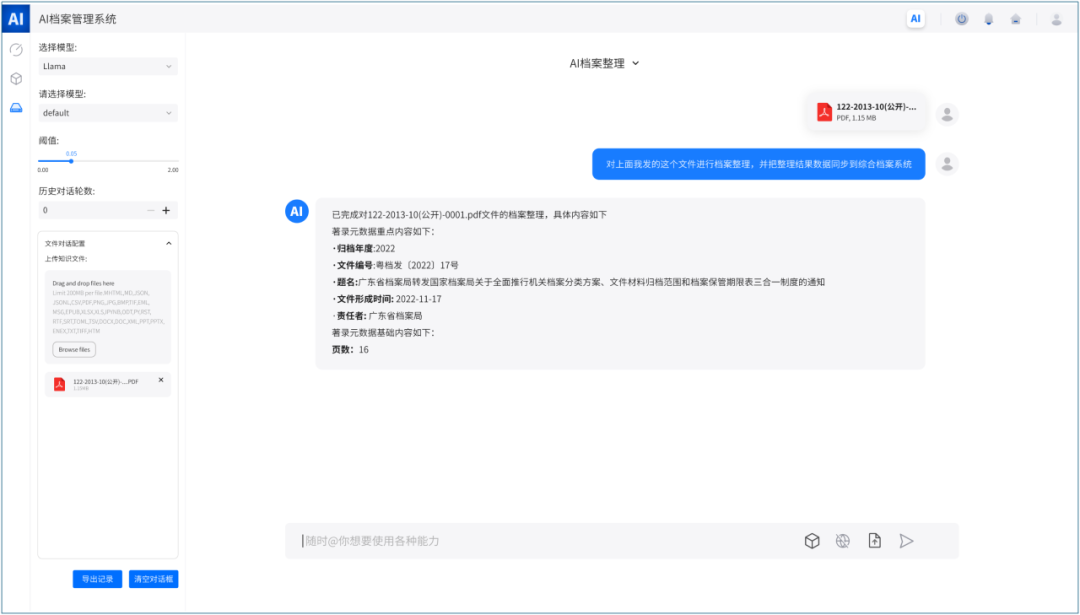
快速针对tif、jpg、ofd、pdf等常见格式的电子档案进行智能档案整理,实现自动分类和元数据信息自动捕获,智能提取电子文件内容中的有效信息,高效完成档案的智能分类、编号、排序等业务操作。比如提取文书类档案中的文号、发文时间、标题、发文单位、抄送、主题词等元数据信息,并对著录项进行自动赋值。档案整理人员只需上传档案到本地库,然后确认大模型输出的整理结果是否无误即可,无需进行繁琐的整理工作。下图是通过大模型对某份文件进行自动整理的系统页面,可以清晰看到这份文件上传后,大模型就能从文件内容中识别并提取出这份文件需要著录的元数据信息:
02 档案AI智能问答
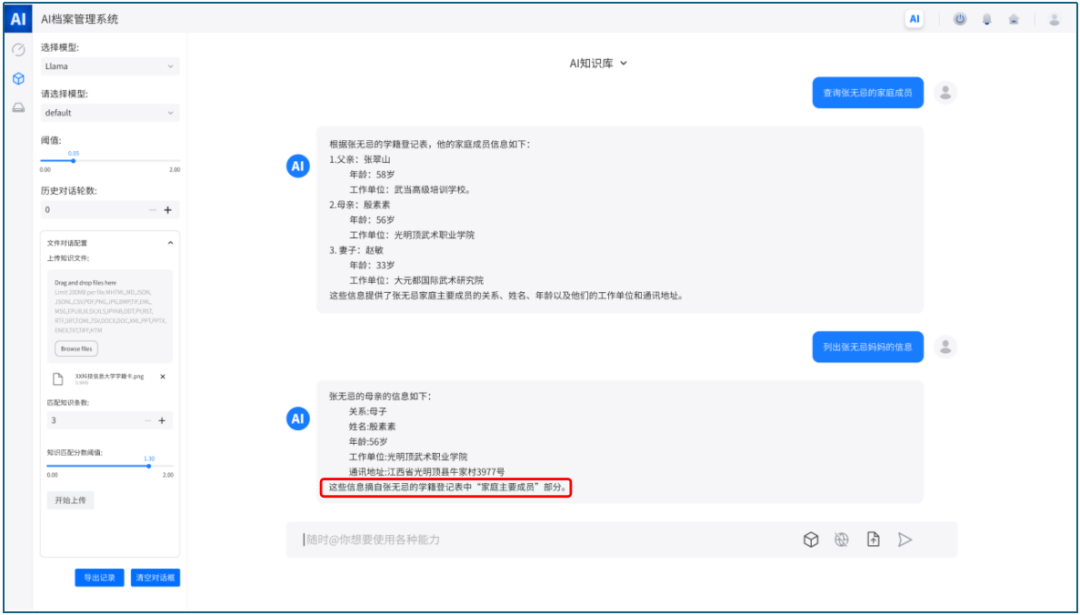
在“AI智能问答系统”中只需输入相应任务要求,大模型会自动理解文本语义并基于AI的思考方式进行数据检索和整理,然后利用强大的自然语言表达能力输出易于理解且匹配任务要求的档案信息结果,从而为用户提供快速、准确、智能的回答和智能检索,提升档案资源的利用效率和管理效率。下图是人工提出两项任务要求后,大模型根据本地档案的实际情况显示智能回答结果的系统页面,且每个回答结果都注明来源,确保需人工确认的时候可以快速判断该结果是否准确。
03 档案智慧编研
选择合适的档案数据对大模型进行训练学习,使其具备一定深度的档案行业语言理解能力以及对话生成、文章创作等能力,编研人员只需要输入编研主题,智慧编研系统即可自动开展档案编研工作,自动生成档案编研成果。
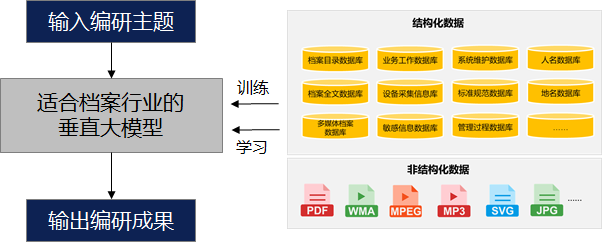
由于编研成果(比如大事记、年鉴、主题展览等)对于内容归纳、总结、提炼的要求较高,现阶段档案大模型赋能智慧编研的效果尚不能达到行业专家的水平,但可以帮助编研人员进行相关材料的汇聚和整理。
五.总 结
总体而言,现阶段行业垂直大模型的应用已经能够在一定程度上提高档案管理的效率,比如实现档案自动整理、快速问答、便捷利用等任务,减轻档案工作者的压力,促进档案信息资源的开发和利用。然而,行业垂直大模型技术离成熟还有一段距离,人工的参与和监督仍是必要的,需对最终输出的结果进行验证和修正,以确保结果的准确性和合规性。未来,随着行业垂直大模型的能力越来越强,赋能档案管理中的应用场景也会越来越丰富,类似于上文中提到的难度相对较大的智慧编研任务,通过大规模、针对性档案数据的训练学习并不断优化模型之后,相信也能输出超越人工整理的优质编研成果。
数字罗塞塔计划公众号致力于成为全国领先的档案信息化知识分享与交流平台。独木难成林,众创力量大!作为中立的第三方平台,我们将努力为广大档案信息化从业企业提供一个展示自身业务与技术专业水平的舞台,共同推动档案行业的进步与发展。
关注我们 - 数字罗塞塔计划 -

![[代码复现]Self-Attentive Sequential Recommendation](https://img-blog.csdnimg.cn/direct/196fac48d6b848fba9abf60f8c7b44bd.png)