参考代码:SASRec.pytorch
可参考资料:SASRec代码解析
前言:文中有疑问的地方用?表示了。可以通过ctrl+F搜索’?'。
环境
conda create -n SASRec python=3.9
pip install torch torchvision
因为我是mac运行的,所以device是
mps
下面的代码可以测试mps是否可以正常运行python # 进入python环境 >>> import torch >>> print(torch.backends.mps.is_available()) # 输出为True则说明可以正常运行
测试
python main.py --device=mps --dataset=ml-1m --train_dir=default --state_dict_path='ml-1m_default/SASRec.epoch=601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth' --inference_only=true --maxlen=200
### average sequence length: 163.50
### ............................................................test (NDCG@10: 0.5662, HR@10: 0.8056)
main.py
str2bool
def str2bool(s):
if s not in {'false', 'true'}:
raise ValueError('Not a valid boolean string')
return s == 'true'
将字符串’true’转化为逻辑1,字符串’false’转化为逻辑0,其他字符串输入则抛出错误。
这个函数用于命令行解析。
命令行解析:argparse.ArgumentParser()
# 1.导入argparse模块
import argparse
# 2.创建一个解析对象
parser = argparse.ArgumentParser()
# 3.向对象parser中添加要关注的命令行参数和选项
# 参数名前加'--'表示这是“关键词参数”(不同于位置参数)
parser.add_argument('--dataset', required=True) # 必选项:数据集dataset
parser.add_argument('--train_dir', required=True) # 必选项
parser.add_argument('--batch_size', default=128, type=int) # type的参数:会将str类型转化为对应的type类型
parser.add_argument('--lr', default=0.001, type=float)
parser.add_argument('--maxlen', default=50, type=int)
parser.add_argument('--hidden_units', default=50, type=int)
parser.add_argument('--num_blocks', default=2, type=int)
parser.add_argument('--num_epochs', default=201, type=int)
parser.add_argument('--num_heads', default=1, type=int)
parser.add_argument('--dropout_rate', default=0.5, type=float)
parser.add_argument('--l2_emb', default=0.0, type=float)
parser.add_argument('--device', default='cpu', type=str)
parser.add_argument('--inference_only', default=False, type=str2bool)
parser.add_argument('--state_dict_path', default=None, type=str)
# 4.调用parse_args()方法进行解析
args = parser.parse_args()
命令行输入
python main.py --device=mps --dataset=ml-1m --train_dir=default --state_dict_path='ml-1m_default/SASRec.epoch=601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth' --inference_only=true --maxlen=200时调用
结果:
dataset: ml-1m
train_dir: default
batch_size: 128(默认)
lr: 0.001(默认)
maxlen: 200
hidden_units: 50(默认)
num_blocks: 2(默认)
num_epochs: 201(默认)
num_heads: 1(默认)
dropout_rate: 0.5(默认)
l2_emb: 0.0
device: mps
inference_only: True
state_dict_path: ml-1m_default/SASRec.epoch=601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth
PS:
1.命令行参数解析模块:解析命令行代码的参数。
参考:argparse.ArgumentParser()用法解析
2.关键词参数设定的时候需要--,在命令行中也需要。但是在代码中使用时候不需要。即:
- 向对象parser中添加
关键词参数:parser.add_argument('--dataset', required=True)- 命令行传参:
python main.py --device=mps --dataset=ml-1m- 代码中使用:
args.dataset
参数写入args.txt
# args.dataset + '_' + args.train_dir如果不是现有目录就创建
if not os.path.isdir(args.dataset + '_' + args.train_dir):
os.makedirs(args.dataset + '_' + args.train_dir)
# 拼接上面的目录和args.txt路径,并打开对应文件'写入'
# vars返回对象的__dict__属性
with open(os.path.join(args.dataset + '_' + args.train_dir, 'args.txt'), 'w') as f:
f.write('\n'.join([str(k) + ',' + str(v) for k, v in sorted(vars(args).items(), key=lambda x: x[0])]))
# f.close()不需要,因为上面使用的是with open
以上面的测试为例
args.dataset =ml-1m
args.train_dir=default
这行代码的目的是将args参数按行逐个写入到ml-1m-default/args.txt文件中。
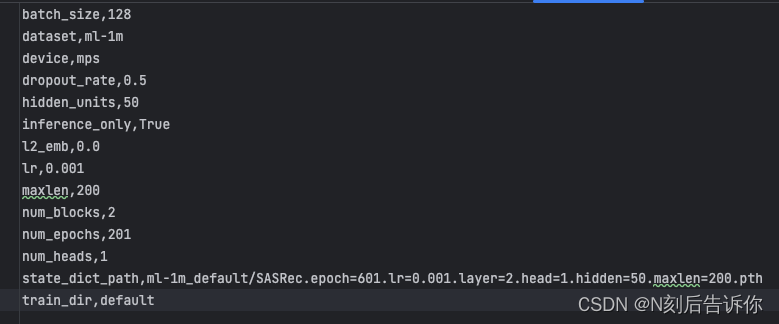
PS:
vars返回对象的__dict__属性。可以参考:Python vars函数
dict.items()返回视图对象:将字典转化为元组的列表。
sorted(vars(args).items(), key=lambda x: x[0])# 根据元组的第一个元素升序
[str(k) + ',' + str(v) for k, v in sorted(vars(args).items(), key=lambda x: x[0])]:列表生成器
str.join(iterable):返回一个由 iterable 中的字符串拼接而成的字符串,str作为中间的分隔符。
下面开始是main的主要内容(以下都用测试的代码的参数为例)。
参数列表:
batch_size,128
dataset,ml-1m
device,mps
dropout_rate,0.5
hidden_units,50
inference_only,True
l2_emb,0.0
lr,0.001
maxlen,200
num_blocks,2
num_epochs,201
num_heads,1
state_dict_path,ml-1m_default/SASRec.epoch=601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth
train_dir,default
数据集划分
# 利用utils.data_partition函数对数据集进行划分
from utils import data_partition
dataset = data_partition(args.dataset) # 传参"ml-1m"
[user_train, user_valid, user_test, usernum, itemnum] = dataset
num_batch = len(user_train) // args.batch_size # 计算训练批次
# 计算平均sequence长度
cc = 0.0
for u in user_train:
cc += len(user_train[u])
print('average sequence length: %.2f' % (cc / len(user_train)))
f = open(os.path.join(args.dataset + '_' + args.train_dir, 'log.txt'), 'w')
这部分主要是进行数据集划分,得到训练集、验证集、测试集
关于data_partition需要看utils.py文件
结果:
user_train:{1: [1,2,3,4…], 2:[80, 81,…], …}
user_valid:{1: [78], 2:[137], 3:[248], …}
user_test:{1: [79], 2: [138], 3: [249], …}
usernum: 6040
itemnum: 3416
num_batch: 47
average sequence length: 163.50
疑问:这里代码注释里写了
tail? + ((len(user_train) % args.batch_size) != 0),是否需要考虑不足batch_size的部分?
log.txt文件,每20轮次,用于存放valid和test上的评价。
采样
sampler = WarpSampler(user_train, usernum, itemnum, batch_size=args.batch_size, maxlen=args.maxlen, n_workers=3)
实例化WarpSampler类。这个类主要是用来通过采样用户,生成数据的。
模型类实例化
model = SASRec(usernum, itemnum, args).to(args.device) # no ReLU activation in original SASRec implementation?
模型参数初始化
for name, param in model.named_parameters():
try:
torch.nn.init.xavier_normal_(param.data)
except:
pass
model.named_parameters()是返回模型所有参数及其名称的迭代器。
详细参考:model.named_parameters()与model.parameters()函数的区别
模型训练
# 将模型设置为训练模式,确保”Batch Normalization”和“Dropout“正常工作
model.train()
epoch_start_idx = 1
if args.state_dict_path is not None:
try:
model.load_state_dict(torch.load(args.state_dict_path, map_location=torch.device(args.device)))
tail = args.state_dict_path[args.state_dict_path.find('epoch=') + 6:]
epoch_start_idx = int(tail[:tail.find('.')]) + 1
except: # in case your pytorch version is not 1.6 etc., pls debug by pdb if load weights failed
print('failed loading state_dicts, pls check file path: ', end="")
print(args.state_dict_path)
print('pdb enabled for your quick check, pls type exit() if you do not need it')
import pdb; pdb.set_trace()
本部分用到的变量:
arg.state_dict_path:ml-1m_default/SASRec.epoch=601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth
tail:601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth
tail[:tail.find('.')]:601
epoch_start_idx:602
这一部分的作用是:读取已经训练了601个epoch的模型参数,然后将epoch_start_idx设置为602
PS:
1.model.load_state_dict:加载模型参数。
详细参考:【PyTorch】基础学习:一文详细介绍 load_state_dict() 的用法和应用
2.str.find:查询目标字符(串),并返回第一个查询到的字符串的首位索引。
详细参考:python查找目标字符(串)——str.find()用法及实例
inference_only=True
if args.inference_only:
# 模型设置为评估模式,参数不再更新,dropout不启用,batchnorm使用全局统计数据
model.eval()
t_test = evaluate(model, dataset, args)
print('test (NDCG@10: %.4f, HR@10: %.4f)' % (t_test[0], t_test[1]))
这一部分的作用是:当inference_only设置为True时,评估数据集,返回NDCG和HT
损失函数
bce_criterion = torch.nn.BCEWithLogitsLoss() # torch.nn.BCELoss()
使用二元交叉损失函数
BCEWithLogitsLoss() = sigmoid+torch.nn.BCELoss()
详细参考:Pytorch常用的函数(十)交叉熵损失函数nn.BCELoss()、nn.BCELossWithLogits()、nn.CrossEntropyLoss()详解
优化器
adam_optimizer = torch.optim.Adam(model.parameters(), lr=args.lr, betas=(0.9, 0.98))
Adam优化器
详细参考:Adam
模型训练
T = 0.0
t0 = time.time()
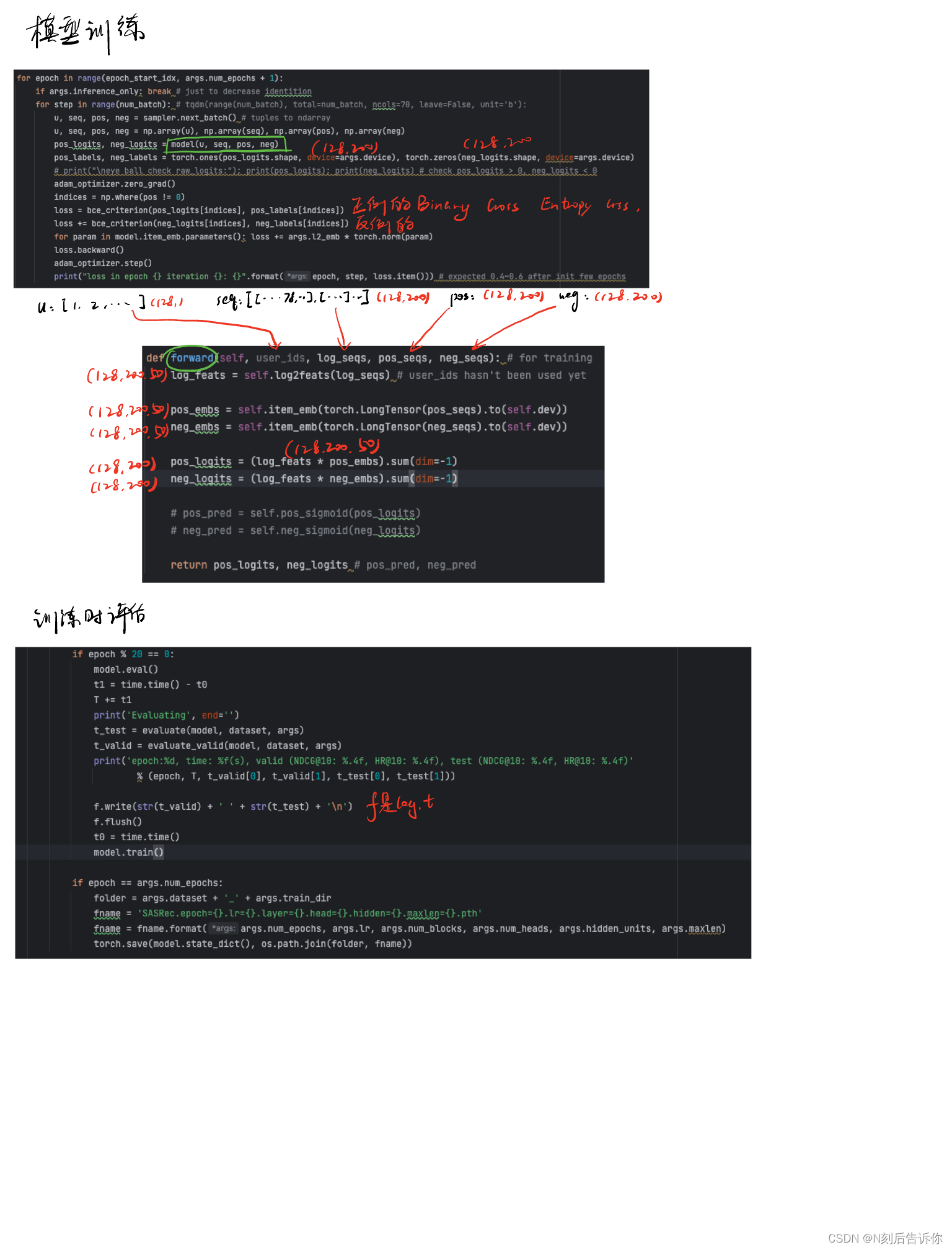
for epoch in range(epoch_start_idx, args.num_epochs + 1):
if args.inference_only: break # just to decrease identition
for step in range(num_batch): # tqdm(range(num_batch), total=num_batch, ncols=70, leave=False, unit='b'):
u, seq, pos, neg = sampler.next_batch() # 获得batch数据
u, seq, pos, neg = np.array(u), np.array(seq), np.array(pos), np.array(neg)
pos_logits, neg_logits = model(u, seq, pos, neg)
pos_labels, neg_labels = torch.ones(pos_logits.shape, device=args.device), torch.zeros(neg_logits.shape, device=args.device)
# print("\neye ball check raw_logits:"); print(pos_logits); print(neg_logits) # check pos_logits > 0, neg_logits < 0
adam_optimizer.zero_grad()
indices = np.where(pos != 0)
loss = bce_criterion(pos_logits[indices], pos_labels[indices])
loss += bce_criterion(neg_logits[indices], neg_labels[indices])
for param in model.item_emb.parameters(): loss += args.l2_emb * torch.norm(param)
loss.backward()
adam_optimizer.step()
print("loss in epoch {} iteration {}: {}".format(epoch, step, loss.item())) # expected 0.4~0.6 after init few epochs
从epoch_start_idx开始继续训练,直到args.num_epochs
看pos_logits, neg_logits = model(u, seq, pos, neg)前需要查看SASRec的forward函数。
PS:
np.where(condition): 返回每个符合condition条件元素的坐标,返回的是以元组的形式
详细参考:Python np.where()的详解以及代码应用
torch.norm(): 详细参考:【深度学习框架-torch】torch.norm函数详解用法
模型评估(训练时)
# 每过20个epoch,评估一次
if epoch % 20 == 0:
model.eval()
t1 = time.time() - t0
T += t1
print('Evaluating', end='')
t_test = evaluate(model, dataset, args)
t_valid = evaluate_valid(model, dataset, args)
print('epoch:%d, time: %f(s), valid (NDCG@10: %.4f, HR@10: %.4f), test (NDCG@10: %.4f, HR@10: %.4f)'
% (epoch, T, t_valid[0], t_valid[1], t_test[0], t_test[1]))
f.write(str(t_valid) + ' ' + str(t_test) + '\n')
f.flush()
t0 = time.time()
model.train()
if epoch == args.num_epochs:
folder = args.dataset + '_' + args.train_dir
fname = 'SASRec.epoch={}.lr={}.layer={}.head={}.hidden={}.maxlen={}.pth'
fname = fname.format(args.num_epochs, args.lr, args.num_blocks, args.num_heads, args.hidden_units, args.maxlen)
torch.save(model.state_dict(), os.path.join(folder, fname))
f.flush(): 确保数据立即被写入磁盘,而不是在内存中缓冲一段时间。
完成训练后
f.close() # 关闭文件
sampler.close() # 关闭子进程
print("Done")
utils.py
fun: data_partition
from collections import defaultdict
def data_partition(fname):
usernum = 0
itemnum = 0
User = defaultdict(list) # 创建key-list的字典
user_train = {}
user_valid = {}
user_test = {}
# assume user/item index starting from 1
f = open('data/%s.txt' % fname, 'r')
# 构建"user-对应item的列表"的字典,获得usernum, itemnum
for line in f:
u, i = line.rstrip().split(' ') # rstrip():去掉右边的空格,split(' '): 根据空格拆分得到字符串列表
u = int(u) # str->int
i = int(i)
usernum = max(u, usernum) # usernum记录user的最大值,即user数
itemnum = max(i, itemnum) # itemnum记录item的最大值,即item数
User[u].append(i) # User的key是user的index,value是item的index组成的list
# 构建user_train, user_valid, user_test
for user in User:
nfeedback = len(User[user]) # 计算user对应的item数量
# item数量<3的user, 则对应的item列表直接作为user_train[user]的value
# item数量>=3的user,对应的item列表的
# 最后一个item作为user_test[user]的value
# 倒数第二个item作为user_valid[user]的value
# 剩下前面的item作为user_train[user]的value
if nfeedback < 3:
user_train[user] = User[user]
user_valid[user] = []
user_test[user] = []
else:
user_train[user] = User[user][:-2]
user_valid[user] = []
user_valid[user].append(User[user][-2])
user_test[user] = []
user_test[user].append(User[user][-1])
return [user_train, user_valid, user_test, usernum, itemnum]
实际调用:
dataset = data_partition('ml-1m')
1.data_partition目的是将data/fname.txt文件中的user-item对转化为user-item列表字典,最终返回了[user_train, user_valid, user_test, usernum, itemnum]。
2.user_train形如{1: [1, 2, 3, 4, …], 2:[…], …}, user_valid形如{1: [78], 2: [137], …}, user_test形如{1: [79], 2: [138], …}
PS:
1.defaultdict创建的字典,传入的”工厂函数"可以表明字典value的类型和默认值,这使得这种字典很方便地将(键-值)序列转化为对应的字典。具体可以参考:
python中defaultdict用法详解
defaultdict 例子
2.事实上,经过测试,"m1-1m"这个例子里面,并没有某个user的对应item列表数量小于3。
class: WarpSampler
from multiprocessing import Process, Queue
class WarpSampler(object):
def __init__(self, User, usernum, itemnum, batch_size=64, maxlen=10, n_workers=1):
self.result_queue = Queue(maxsize=n_workers * 10) # 创建一个最多存放n_workers*10个数据的消息队列,用于支持进程之间的通信
self.processors = [] # 存放子进程的列表
# 列表中添加进程操作对象,其中,sample_function作为任务交给子进程执行,执行要用到的参数是args
for i in range(n_workers):
self.processors.append(
Process(target=sample_function, args=(User,
usernum,
itemnum,
batch_size,
maxlen,
self.result_queue,
np.random.randint(2e9)
)))
self.processors[-1].daemon = True # 设置进程为守护进程(必须在进程启动前设置)
self.processors[-1].start() # 创建进程
def next_batch(self):
return self.result_queue.get() # 从消息队列中取出数据并返回
def close(self):
for p in self.processors:
p.terminate() # 杀死进程
p.join() # 等待进程结束
实际调用:
sampler = WarpSampler(user_train, usernum, itemnum, batch_size=128, maxlen=200, n_workers=3)
这里相当于有3个子进程在生产batch数据
中间要用到sample_function,遇到可以跳转查看sample_function讲解。
WarpSampler类:
初始化:生成大小为30的消息队列,创建3个子进程,每个子进程生成一批数据,并存入消息队列
next_batch方法:从消息队列中取数据
close方法:杀死所有子进程
PS:
1.关于守护进程,可以参考:守护进程 - 《Python零基础到全栈系列》。具体地:p.daemon默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,p.daemon必须在p.start()之前设置。
fun: sample_function
import numpy as np
def sample_function(user_train, usernum, itemnum, batch_size, maxlen, result_queue, SEED):
# 采样
def sample():
user = np.random.randint(1, usernum + 1) # 随机返回1-usernum之间的一个整数
# 如果user_train的序列长度小于等于1,则重新随机取1-usernum之间的一个整数
while len(user_train[user]) <= 1: user = np.random.randint(1, usernum + 1)
seq = np.zeros([maxlen], dtype=np.int32) # 长为maxlen的ndarray
pos = np.zeros([maxlen], dtype=np.int32)
neg = np.zeros([maxlen], dtype=np.int32)
nxt = user_train[user][-1] # 最后一个item序号
idx = maxlen - 1 # 199
ts = set(user_train[user])
for i in reversed(user_train[user][:-1]):
seq[idx] = i
pos[idx] = nxt
if nxt != 0: neg[idx] = random_neq(1, itemnum + 1, ts)
nxt = i # 当前轮次的i,实际上是下一轮次的nxt
idx -= 1 # 轮次加1,索引-1
if idx == -1: break # 意味着item序列长度超出maxlen,索引溢出,跳出循环
return (user, seq, pos, neg)
np.random.seed(SEED) # 设置随机数种子
while True:
one_batch = []
for i in range(batch_size):
one_batch.append(sample()) # one_batch是元组(user, seq, pos, neg)的列表
result_queue.put(zip(*one_batch)) # 结果写入消息队列
实际调用:
sample_function(user_train, usernum, itemnum, batch_size=128, maxlen=200, self.result_queue, np.random.randint(2e9))
中间要用到random_neq,遇到可以跳转查看random_neq讲解。
sample的目的是:采样,返回某user的id,并根据其user_train序列生成对应的输入序列seq,正例序列pos,反例序列neg
sample_function的目的是:多次采样,并组合得到一批次的数据。同时,它将在WarpSampler类中作为进程活动的方法。
这里找个例子:user=1, user_train=[1, 2, 4, 6]
则初始:nxt=6,idx=199,reversed(user_train[user][:-1])=[4, 2, 1]
第1次循环:i=4,seq[199]=i=4,pos[199]=nxt=6,neg[199]=100,nxt=i=4,idx=idx-1=198
第2次循环:i=2,seq[198]=i=2,pos[198]=nxt=4,neg[198]=200,nxt=i=2,idx=idx-1=197
第3次循环:i=1,seq[197]=i=4,pos[197]=nxt=2,neg[197]=300,nxt=i=1,idx=idx-1=196
此时seq=[0, 0, ..., 1, 2, 4]
此时pos=[0, 0, ..., 2, 4, 6]
此时neg=[0, 0, ..., 300, 200, 100]
PS:
1.sample中的if nxt != 0似乎没有用?因为nxt一定不会等于0
2.zip(*one_batch)是将元组(user, seq, pos, neg)中的对应元素组成元组,即user和user组成元组。具体可以参考:一文看懂Python(十)-- zip与zip(*)函数
fun: random_neq
def random_neq(l, r, s):
t = np.random.randint(l, r)
while t in s:
t = np.random.randint(l, r)
return t
实际调用:
random_neq(1, itemnum + 1, ts),其中ts是用户对应的item集合
random_neq的目的是:在所有item序号中,找一个没有出现在用户的item集合中的item作为反例item序号。
fun: evaluate
def evaluate(model, dataset, args):
[train, valid, test, usernum, itemnum] = copy.deepcopy(dataset)
NDCG = 0.0
HT = 0.0
valid_user = 0.0
# 采样users列表
if usernum>10000:
users = random.sample(range(1, usernum + 1), 10000)
else:
users = range(1, usernum + 1)
for u in users:
# 去掉没有train或者没有test的user
if len(train[u]) < 1 or len(test[u]) < 1: continue
seq = np.zeros([args.maxlen], dtype=np.int32)
idx = args.maxlen - 1
seq[idx] = valid[u][0] # seq列表的最后一位用valid[u][0]
idx -= 1
for i in reversed(train[u]):
seq[idx] = i
idx -= 1
if idx == -1: break
rated = set(train[u])
rated.add(0)
item_idx = [test[u][0]]
# 挑选100个不在train[u]的itemnum放如item_idx
for _ in range(100):
t = np.random.randint(1, itemnum + 1) # 1-itemnum之间的随机整数
while t in rated: t = np.random.randint(1, itemnum + 1)
item_idx.append(t)
predictions = -model.predict(*[np.array(l) for l in [[u], [seq], item_idx]]) # 返回1*101维度的近似度得分(加了负号,所以是越小越好)
predictions = predictions[0] # - for 1st argsort DESC
rank = predictions.argsort().argsort()[0].item()
valid_user += 1
if rank < 10:
NDCG += 1 / np.log2(rank + 2)
HT += 1
if valid_user % 100 == 0:
print('.', end="")
sys.stdout.flush()
return NDCG / valid_user, HT / valid_user
0.整体作用:评估数据集,返回NDCG和HT
1.评估时,将valid[u][0]也放到seq的最后,也构成序列。
2.item_idx包含正例target和100个反例target。
3.model.predict间model.py文件
4.predictions的计算中加了负号,所以是越小越好
5.predictions.argsort().argsort()[0].item()是为了获得预期结果的排名,详细看下面的草稿
6.HT: 前10预测中有ground_truch的次数,每次计数为1
7.NDCG: ground_truth出现在更高位次会富裕更大权重,每次为带权计数
PS:
1.random.sample(sequence, k):返回从序列中选择的项目的特定长度列表。
详细参考:【python】 random.sample()
2.在列表前面加*是将将列表解开成几个独立的参数,传入函数。
详细参考:python中在列表前面加星号(*)的作用
3.torch.argsort:返回数组元素排序后的索引。
详细参考:torch.argsort
4.sys.stdout.flush(): 显示地让缓冲区的内容输出。(但我感觉好像没啥用。可以去掉?)
详细参考:sys.stdout.flush的作用

fun: evaluate_valid
def evaluate_valid(model, dataset, args):
[train, valid, test, usernum, itemnum] = copy.deepcopy(dataset)
NDCG = 0.0
valid_user = 0.0
HT = 0.0
if usernum>10000:
users = random.sample(range(1, usernum + 1), 10000)
else:
users = range(1, usernum + 1)
for u in users:
if len(train[u]) < 1 or len(valid[u]) < 1: continue
seq = np.zeros([args.maxlen], dtype=np.int32)
idx = args.maxlen - 1
for i in reversed(train[u]):
seq[idx] = i
idx -= 1
if idx == -1: break
rated = set(train[u])
rated.add(0)
item_idx = [valid[u][0]] # 和上面的evaluate函数的区别之2
for _ in range(100):
t = np.random.randint(1, itemnum + 1)
while t in rated: t = np.random.randint(1, itemnum + 1)
item_idx.append(t)
predictions = -model.predict(*[np.array(l) for l in [[u], [seq], item_idx]])
predictions = predictions[0]
rank = predictions.argsort().argsort()[0].item()
valid_user += 1
if rank < 10:
NDCG += 1 / np.log2(rank + 2)
HT += 1
if valid_user % 100 == 0:
print('.', end="")
sys.stdout.flush()
return NDCG / valid_user, HT / valid_user
在验证集上评估,总体上和上面的evaluate函数差不多,只是
1.不需要seq[idx] = valid[u][0]
2.item_idx = [valid[u][0]]
model.py
class: SASRec
主体结构:
class SASRec(torch.nn.Module):
def __init__(self, user_num, item_num, args):
...
def log2feats(self, log_seqs):
...
def forward(self, user_ids, log_seqs, pos_seqs, neg_seqs): # for training
...
def predict(self, user_ids, log_seqs, item_indices): # for inference
...
SASRec.__init__
def __init__(self, user_num, item_num, args):
super(SASRec, self).__init__()
self.user_num = user_num
self.item_num = item_num
self.dev = args.device
# TODO: loss += args.l2_emb for regularizing embedding vectors during training
# https://stackoverflow.com/questions/42704283/adding-l1-l2-regularization-in-pytorch
# 构造item的embedding表,pos的embedding表
# padding_idx=0,说明索引0对应的embedding不参与梯度运算,不在训练时更新
self.item_emb = torch.nn.Embedding(self.item_num+1, args.hidden_units, padding_idx=0)
self.pos_emb = torch.nn.Embedding(args.maxlen, args.hidden_units)
self.emb_dropout = torch.nn.Dropout(p=args.dropout_rate)
self.attention_layernorms = torch.nn.ModuleList()
self.attention_layers = torch.nn.ModuleList()
self.forward_layernorms = torch.nn.ModuleList()
self.forward_layers = torch.nn.ModuleList()
self.last_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)
for _ in range(args.num_blocks):
new_attn_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)
self.attention_layernorms.append(new_attn_layernorm)
new_attn_layer = torch.nn.MultiheadAttention(args.hidden_units,
args.num_heads,
args.dropout_rate)
self.attention_layers.append(new_attn_layer)
new_fwd_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)
self.forward_layernorms.append(new_fwd_layernorm)
new_fwd_layer = PointWiseFeedForward(args.hidden_units, args.dropout_rate)
self.forward_layers.append(new_fwd_layer)
# self.pos_sigmoid = torch.nn.Sigmoid()
# self.neg_sigmoid = torch.nn.Sigmoid()
实际调用:
model = SASRec(usernum, itemnum, args).to(args.device)
PS:
1.torch.nn.Embedding:生成Embedding实例,该实例作用在tensor上,会对其中的每个元素做embedding。
详细可参考: 无脑入门pytorch系列(一)—— nn.embedding
2.torch.nn.Dropout:生成Dropout实例,该实例作用在tensor上,会以一定概率使输出变0。
详细可参考:torch.nn.Dropout官网
3.torch.nn.ModuleList:存放子模块的列表
4.torch.nn.LayerNorm:生成LayerNorm实例,该实例作用在tensor上,以最后一个/几个维度求均值和标准差,最后做layer norm。
详细可参考:torch.nn.LayerNorm官网
5.torch.nn.MultiheadAttention:生成多头注意力实例。由于没有设置"batch_first=True",所以要求输入的维度是(seq, batch, feature)。
详细可参考:torch.nn.MultiheadAttention官网;torch.nn.MultiheadAttention的使用和参数解析
SASRec.log2feats
import numpy as np
def log2feats(self, log_seqs):
# 这部分将输入序列embedding,并加入了位置embedding,最后应用了dropout
seqs = self.item_emb(torch.LongTensor(log_seqs).to(self.dev))
seqs *= self.item_emb.embedding_dim ** 0.5 # 为何要乘以根号d?
positions = np.tile(np.array(range(log_seqs.shape[1])), [log_seqs.shape[0], 1])
seqs += self.pos_emb(torch.LongTensor(positions).to(self.dev))
seqs = self.emb_dropout(seqs)
# seq列表中0对应的embeeding全部置于0
timeline_mask = torch.BoolTensor(log_seqs == 0).to(self.dev)
seqs *= ~timeline_mask.unsqueeze(-1) # broadcast in last dim
tl = seqs.shape[1] # time dim len for enforce causality
attention_mask = ~torch.tril(torch.ones((tl, tl), dtype=torch.bool, device=self.dev))
for i in range(len(self.attention_layers)):
# 为了匹配MultiheadAttention,所以需要换维度
seqs = torch.transpose(seqs, 0, 1)
Q = self.attention_layernorms[i](seqs)
mha_outputs, _ = self.attention_layers[i](Q, seqs, seqs,
attn_mask=attention_mask)
# key_padding_mask=timeline_mask
# need_weights=False) this arg do not work?
seqs = Q + mha_outputs
seqs = torch.transpose(seqs, 0, 1)
seqs = self.forward_layernorms[i](seqs)
seqs = self.forward_layers[i](seqs)
seqs *= ~timeline_mask.unsqueeze(-1)
log_feats = self.last_layernorm(seqs) # (U, T, C) -> (U, -1, C)
return log_feats
输入
log_seqs是形如:([0, 0, 3, ...], ..., [0, 2, ...])的元组,元素是某个user_id对应的seq列表(seq列表见sample_function的例子),size为batch_size*maxlen
log2feats里基本包含了模型主体网络的构建,包括embedding,attention,ffn等。
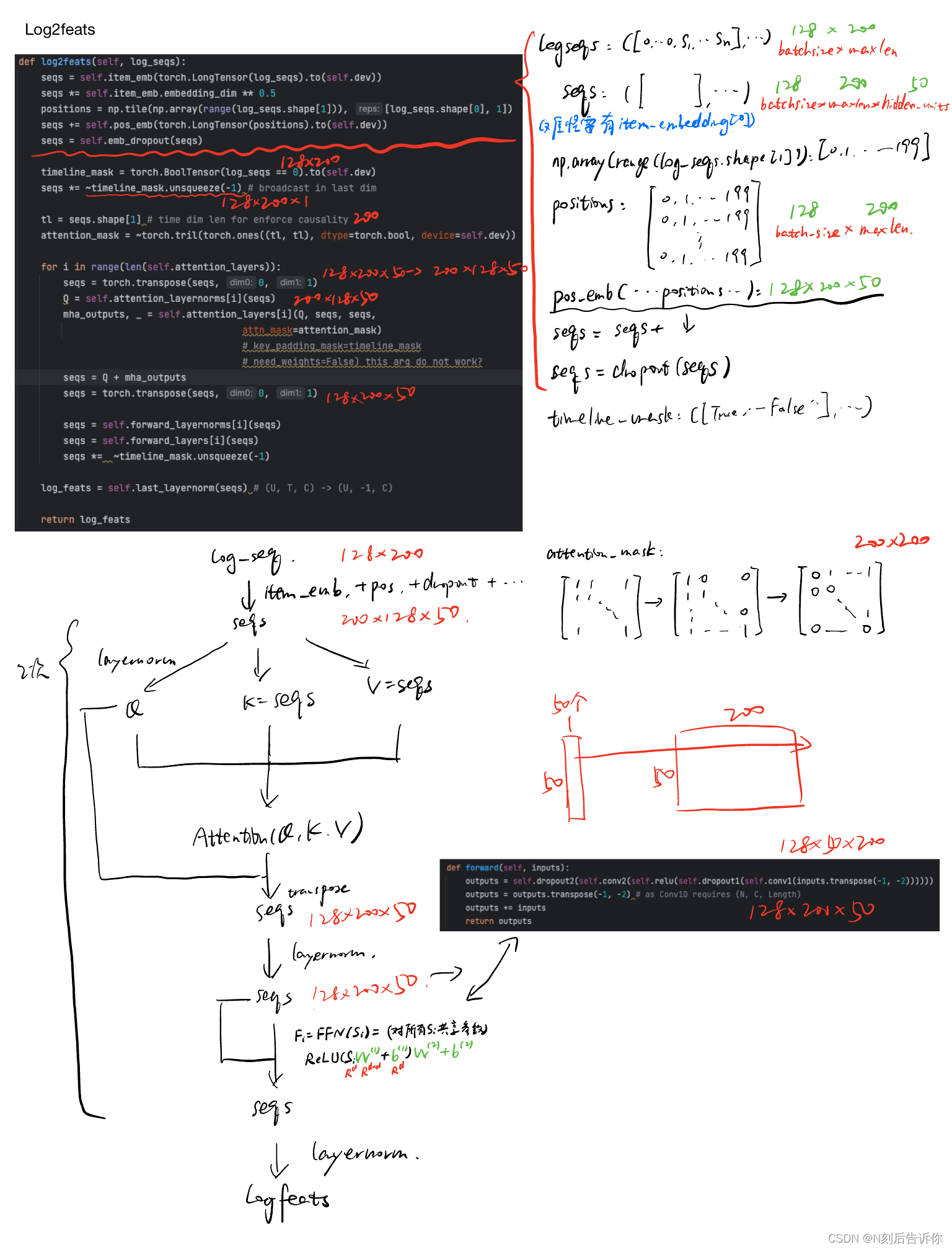
PS:
0.源代码seqs *= self.item_emb.embedding_dim ** 0.5,为什么要乘以根号d。一种解释是nn.embedding使用xavier init初始化,方差为 1 / d 1/\sqrt{d} 1/d,为了方便收敛所以要乘以根号d。
详细参考:Transformer 3. word embedding 输入为什么要乘以 embedding size的开方
1.torch.LongTensor是Pytorch的一个数据类型,用于表示包含整数(整型数据)的张量(tensor)。其元素都是整数。需要注意的是,torch.LongTensor 在 PyTorch 1.6 版本之后被弃用,推荐使用 torch.tensor 并指定 dtype=torch.long 来创建相同类型的张量。如torch.tensor(data, dtype=torch.long)。
详细参考:torch.LongTensor使用方法
2.np.tile(A, reps)的作用是将沿指定轴重复数组A。
详细参考:Numpy|np.tile|处理数组复制扩展小帮手
3.torch.tensor.unsqueeze(dim):在指定的位置增加一个维度。
详细参考:pytorch中tensor的unsqueeze()函数和squeeze()函数的用处
4.torch.tril():返回下三角矩阵。
详细参考:pytorch中tril函数介绍
5.torch.nn.MultiheadAttention的实例的forward方法中,有key_padding_mask参数和attn_mask参数,前者作用是”屏蔽计算注意力时key的填充位置“,后者的作用是”屏蔽自注意力计算时query的未来位置“。
详细参考:pytorch的key_padding_mask和参数attn_mask有什么区别?;PyTorch的Transformer
疑问:为什么这里不需要key_padding_mask?这里,似乎是利用
~timeline_mask.unsqueeze(-1)将padding的序列遮盖。
SASRec.forward
def forward(self, user_ids, log_seqs, pos_seqs, neg_seqs): # for training
log_feats = self.log2feats(log_seqs) # user_ids hasn't been used yet
pos_embs = self.item_emb(torch.LongTensor(pos_seqs).to(self.dev))
neg_embs = self.item_emb(torch.LongTensor(neg_seqs).to(self.dev))
pos_logits = (log_feats * pos_embs).sum(dim=-1)
neg_logits = (log_feats * neg_embs).sum(dim=-1)
# pos_pred = self.pos_sigmoid(pos_logits)
# neg_pred = self.neg_sigmoid(neg_logits)
return pos_logits, neg_logits # pos_pred, neg_pred
输入:
user_ids:(1, 2, ...),元素是user_id
log_seqs:([0, 0, 3, ...], ..., [0, 2, ...])∈ R 128 × 200 \in R^{128\times 200} ∈R128×200,元素是某user_id对应的item序列。
pos_seqs:([78], ..., [137])∈ R 128 × 1 \in R^{128\times 1} ∈R128×1,元素是某user_id对应的item序列的预测值正例
neq_seqs:([79], ..., [138])∈ R 128 × 1 \in R^{128\times 1} ∈R128×1,元素是某user_id对应的item序列的预测值反例
PS:
1.user_ids并没有被用到
SASRec.predict
def predict(self, user_ids, log_seqs, item_indices): # for inference
log_feats = self.log2feats(log_seqs) # user_ids hasn't been used yet
final_feat = log_feats[:, -1, :] # 只用log_feats的最后一个输出
item_embs = self.item_emb(torch.LongTensor(item_indices).to(self.dev)) # (U, I, C)
logits = item_embs.matmul(final_feat.unsqueeze(-1)).squeeze(-1)
# preds = self.pos_sigmoid(logits) # rank same item list for different users
return logits # preds # (U, I)
计算log_feats和item_indices之间的相似度分数,没有经过softmax。
class:PointWiseFeedForward
class PointWiseFeedForward(torch.nn.Module):
def __init__(self, hidden_units, dropout_rate):
super(PointWiseFeedForward, self).__init__()
self.conv1 = torch.nn.Conv1d(hidden_units, hidden_units, kernel_size=1)
self.dropout1 = torch.nn.Dropout(p=dropout_rate)
self.relu = torch.nn.ReLU()
self.conv2 = torch.nn.Conv1d(hidden_units, hidden_units, kernel_size=1)
self.dropout2 = torch.nn.Dropout(p=dropout_rate)
def forward(self, inputs):
outputs = self.dropout2(self.conv2(self.relu(self.dropout1(self.conv1(inputs.transpose(-1, -2))))))
outputs = outputs.transpose(-1, -2) # as Conv1D requires (N, C, Length)
outputs += inputs
return outputs
实际调用:
PointWiseFeedForward(args.hidden_units, args.dropout_rate)
PS:
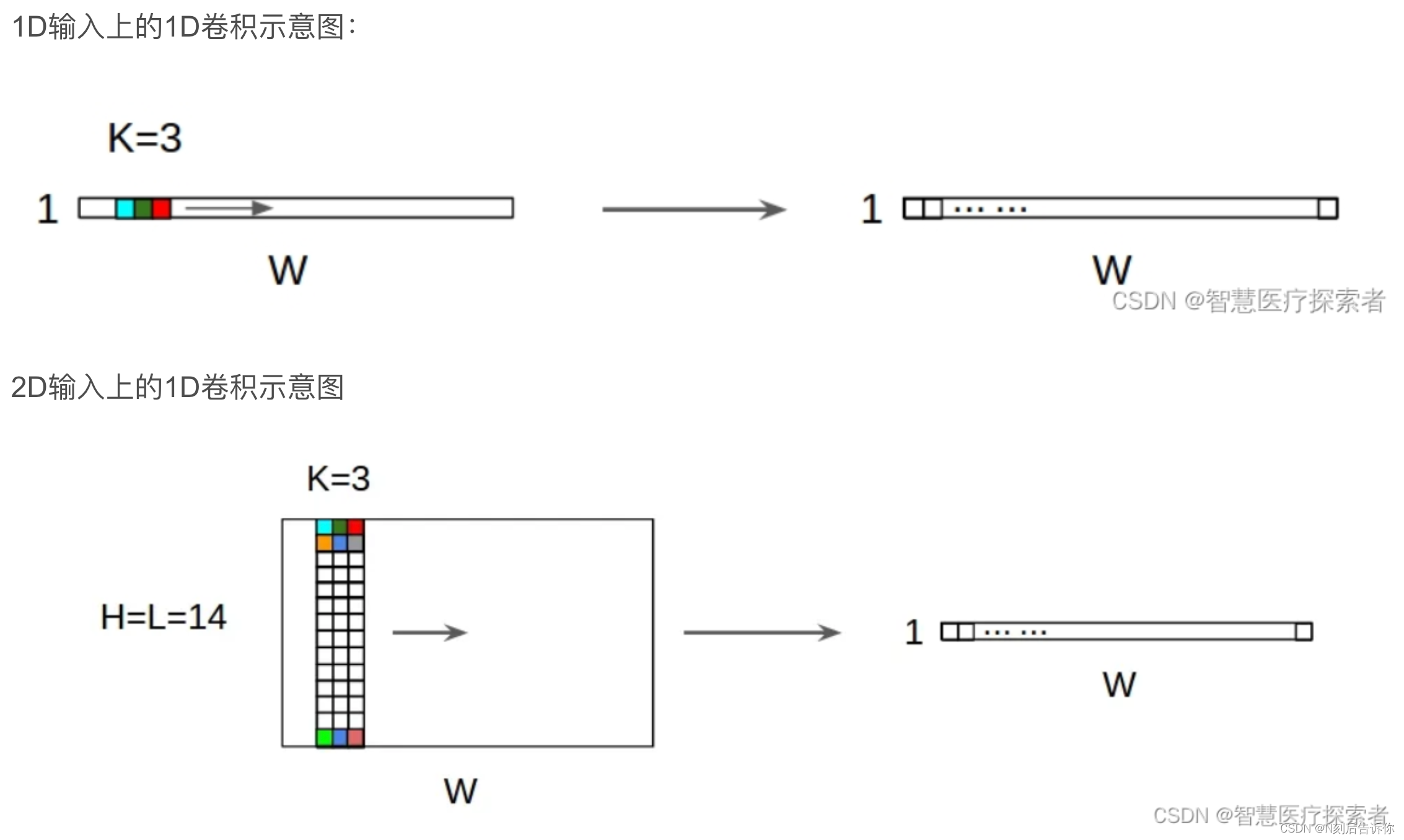
1.Conv1d:一维卷积。这里用了d个一维卷积,本质上是一个带共享权重的d*d矩阵的线性层。
详细可参考:pytorch之nn.Conv1d详解
2.input.transpose(dim0, dim1)等价于torch.transpose(input, dim0, dim1):将这两个给定维度互换。
详细可参考:torch.transpose()