Deploy an AI Coding Assistant with NVIDIA TensorRT-LLM and NVIDIA Triton | NVIDIA Technical Blog
https://github.com/triton-inference-server/tutorials/blob/main/Conceptual_Guide/Part_1-model_deployment/README.md
1. 想用onnx-runtime来做推理backend;因此先要将模型转换为onnx格式;
2. model repo: 新建一个目录(本地目录、远程目录、Azure Blob都可);存放所有模型的名称(text_detection、text_recognition)、版本(1、2)、配置文件(config.pbtxt)、模型文件(model.onnx)。例如:
model_repository/
├── text_detection
│ ├── 1
│ │ └── model.onnx
│ ├── 2
│ │ └── model.onnx
│ └── config.pbtxt
└── text_recognition
├── 1
│ └── model.onnx
└── config.pbtxt3. config.pbtxt格式
name: "text_detection"
backend: "onnxruntime"
max_batch_size : 256
input [
{
name: "input_images:0"
data_type: TYPE_FP32
dims: [ -1, -1, -1, 3 ]
}
]
output [
{
name: "feature_fusion/Conv_7/Sigmoid:0"
data_type: TYPE_FP32
dims: [ -1, -1, -1, 1 ]
}
]
output [
{
name: "feature_fusion/concat_3:0"
data_type: TYPE_FP32
dims: [ -1, -1, -1, 5 ]
}
]backend、max_batch_size要写; input、output应该可以由triton从模型文件里自动获取,也可不写;
4. 拉取和启动nvcr.io的triton server镜像:
docker run --gpus=all -it --shm-size=256m --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $(pwd)/model_repository:/models nvcr.io/nvidia/tritonserver:<yy.mm>-py35. 启动triton server
tritonserver --model-repository=/models启动成功后,显示如下信息:(哪几个模型READY了;版本、内存、显存等信息;2个推理用的端口和1个状态查询端口)
I0712 16:37:18.246487 128 server.cc:626]
+------------------+---------+--------+
| Model | Version | Status |
+------------------+---------+--------+
| text_detection | 1 | READY |
| text_recognition | 1 | READY |
+------------------+---------+--------+
I0712 16:37:18.267625 128 metrics.cc:650] Collecting metrics for GPU 0: NVIDIA GeForce RTX 3090
I0712 16:37:18.268041 128 tritonserver.cc:2159]
+----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Option | Value |
+----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| server_id | triton |
| server_version | 2.23.0 |
| server_extensions | classification sequence model_repository model_repository(unload_dependents) schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_tensor_data statistics trace |
| model_repository_path[0] | /models |
| model_control_mode | MODE_NONE |
| strict_model_config | 1 |
| rate_limit | OFF |
| pinned_memory_pool_byte_size | 268435456 |
| cuda_memory_pool_byte_size{0} | 67108864 |
| response_cache_byte_size | 0 |
| min_supported_compute_capability | 6.0 |
| strict_readiness | 1 |
| exit_timeout | 30 |
+----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
I0712 16:37:18.269464 128 grpc_server.cc:4587] Started GRPCInferenceService at 0.0.0.0:8001
I0712 16:37:18.269956 128 http_server.cc:3303] Started HTTPService at 0.0.0.0:8000
I0712 16:37:18.311686 128 http_server.cc:178] Started Metrics Service at 0.0.0.0:80026. 可以使用裸curl来发推理请求,也可使用封装的对象来发;
例如使用triton自带的python包tritionclient里的httpclient类(先要pip install tritionclient):
import tritonclient.http as httpclient
client = httpclient.InferenceServerClient(url="localhost:8000")
raw_image = cv2.imread("./img2.jpg")
preprocessed_image = detection_preprocessing(raw_image)
detection_input = httpclient.InferInput("input_images:0", preprocessed_image.shape, datatype="FP32")
detection_input.set_data_from_numpy(preprocessed_image, binary_data=True)
detection_response = client.infer(model_name="text_detection", inputs=[detection_input])
scores = detection_response.as_numpy('feature_fusion/Conv_7/Sigmoid:0')
geometry = detection_response.as_numpy('feature_fusion/concat_3:0')
cropped_images = detection_postprocessing(scores, geometry, preprocessed_image)7. 再将第一个模型输出的cropped_images作为第二个模型的输入;
# Create input object for recognition model
recognition_input = httpclient.InferInput("input.1", cropped_images.shape, datatype="FP32")
recognition_input.set_data_from_numpy(cropped_images, binary_data=True)
# Query the server
recognition_response = client.infer(model_name="text_recognition", inputs=[recognition_input])
# Process response from recognition model
text = recognition_postprocessing(recognition_response.as_numpy('308'))
print(text)https://github.com/triton-inference-server/tutorials/tree/main/Conceptual_Guide/Part_2-improving_resource_utilization
仅修改config.pbtxt,即可enable拼batch和多instance功能;
1. 拼batch
小batch拼成大batch,在throughput和latency上,都可能提升;
可以指定最多等多久就执行已有的;
dynamic_batching {
max_queue_delay_microseconds: 100
}2. 多model instance
在0和1号GPU上启动,每个GPU启动2个实例;
instance_group [
{
count: 2
kind: KIND_GPU
gpus: [ 0, 1 ]
}
]https://github.com/triton-inference-server/tutorials/tree/main/Conceptual_Guide/Part_3-optimizing_triton_configuration
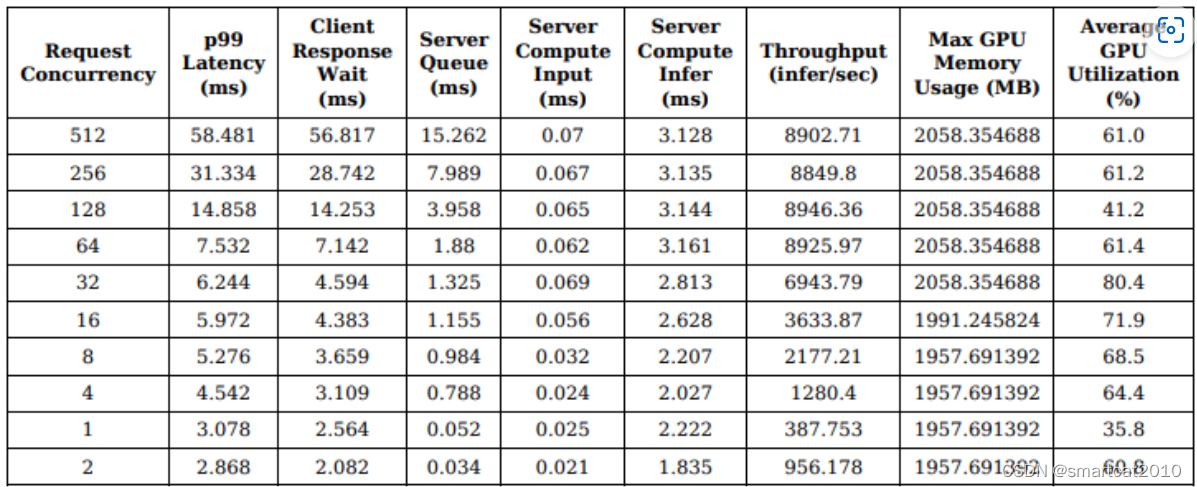
Model Analyzer
其实就是profiler;
用户给出变量,该工具网格搜索遍历每个配置,在Triton上“试跑”;
跑出的结果,画成图或表格;供用户去分析并选取符合他产品需求throughput、latency、硬件资源的最优配置。
主要试跑参数:batching等待延迟上限;model instance数目;