Graph Convolutional Networks 代码详解
- 前言
- 一、数据集介绍
- 二、文件整体架构
- 三、GCN代码详解
- 3.1 utils 模块
- 3.2 layers 模块
- 3.3 models 模块
- 3.4 模型的训练代码
- 总结
前言
在前文中,已经对图卷积神经网络(Graph Convolutional Neural Networks, GCN)的理论基础进行了深入探讨。接下来的章节将会进入新的阶段——将借助PyTorch,这一强大的深度学习框架,通过实战讲解来展示如何构建和训练一个图卷积神经网络。这一过程不仅将帮助读者巩固理论知识,更重要的是,它将引导读者迈出理论到实践的关键一步,从而在处理具有图结构数据的问题上实现质的飞跃。
通过本章节的学习,希望读者能够掌握图神经网络在代码层面的具体实现方法,并通过实际编码练习来加深对图神经网络工作原理的理解。我们将从数据准备开始,逐步深入到模型构建、训练和评估等核心环节,最终实现一个功能完整的图卷积神经网络项目。
一、数据集介绍
在学习模型是如何工作之前要明确模型的任务是什么?本文使用的是使用论文引用数据集中从而完成论文的分类任务。
首先看下数据集的形态,这个目录包含了Cora数据集(www.research.whizbang.com/data)的一个部分选择。
Cora数据集由机器学习论文组成。这些论文被分类为以下七个类别之一:
- 基于案例的(Case_Based)
- 遗传算法(Genetic_Algorithms)
- 神经网络(Neural_Networks)
- 概率方法(Probabilistic_Methods)
- 强化学习(Reinforcement_Learning)
- 规则学习(Rule_Learning)
- 理论(Theory)
选择论文的方式是,最终的语料库中每篇论文至少引用或被至少一篇其他论文引用。整个语料库中共有2708篇论文。
经过词干提取和去除停用词后,我们得到了一个包含1433个唯一词汇的词汇表。所有文档频率小于10的词汇都被移除。
目录包含两个文件:

.content文件包含论文的描述,格式如下:
<paper_id> <word_attributes>+ <class_label>
文件预览入下图:

每行的第一个条目包含论文的唯一字符串ID,后面是二进制值,指示词汇表中的每个单词是否出现在论文中(出现则表示为1,缺乏则表示为0)。最后,行中的最后一个条目包含论文的类别标签。
.cites文件包含语料库的引用图。每行以以下格式描述一个链接:
<ID of cited paper><ID of citing paper>
每行包含两个论文ID。第一个条目是被引用论文的ID,第二个ID代表包含引用的论文。链接的方向是从右向左。如果一行表示为“paper1 paper2”,则链接是“paper2->paper1”。
文件预览形式如下:

二、文件整体架构
为了深入学习图卷积神经网络(GCN)的编码实践,本章节将借助脑图形式,详细总结代码文件中的关键模块及其相互关联。这样做旨在将代码的各个组成部分串联起来,使得学习路径更加系统化。故此讲解的过程中也是按照脑图的顺序进行梳理,从而对代码具备一个全面正确的认识。

模型的训练启动于utils文件,它负责对原始数据执行预处理步骤,生成便于模型训练和操作的格式化数据。接着,在layers文件中,我们按照GCN论文的指导,精心构建了图卷积网络层。这些网络层随后在models文件中被整合起来,形成一个完整的图卷积神经网络架构。最后,在train脚本中,我们执行模型的训练和评估,完成了从数据预处理到模型应用的整个流程。
三、GCN代码详解
接下来,将根据之前提及的不同文件及其顺序,深入剖析整个图卷积神经网络(GCN)的代码实现。这一过程将揭示每个组件的功能及其在整个模型中所扮演的角色。
3.1 utils 模块
import numpy as np
import scipy.sparse as sp
import torch
在模型的初始阶段,首先导入三个关键的库来处理数据和构建模型:
-
numpy:此库非常适合进行高效的**矩阵运算和数学处理。**通过导入为np,调用NumPy库提供的各种数学功能,它是Python科学计算的基石。 -
scipy.sparse:通常简称为sp,这个模块专注于稀疏矩阵的操作。在处理图数据时,邻接矩阵往往是稀疏的,使用稀疏矩阵能够有效地提升存储和计算效率。 -
torch:作为PyTorch框架的核心,它提供了一系列深度学习的基本工具和操作。使用PyTorch中的数据结构和函数,我们可以将数据转换为张量格式,并利用GPU加速计算过程。
通过这三个库的结合,能够高效地处理图数据,并将其转换为适用于PyTorch的格式,为图卷积神经网络的建模打下基础。
def encode_onehot(labels):
classes = set(labels) # a = set('abracadabra') 去除重复元素 >>> a
# {'a', 'r', 'b', 'c', 'd'}
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in enumerate(classes)} # 创建一个字典用来存放所有类别对应的独热编码
'''
import numpy as np
a=np.identity(3)
print(a)
# result
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
'''
labels_onehot = np.array(list(map(classes_dict.get, labels)),
# map() 会根据提供的函数对指定序列做映射。
dtype=np.int32)
return labels_onehot
以上代码展示了将标签转换成独热编码的过程。
def normalize(mx):
"""Row-normalize sparse matrix"""
rowsum = np.array(mx.sum(1)) # 按行求和
r_inv = np.power(rowsum, -1).flatten() # 倒数拉长并且降维
r_inv[np.isinf(r_inv)] = 0. # 将所有无穷∞大的量替换为0
r_mat_inv = sp.diags(r_inv)
'''
diagonals = [[1, 2, 3, 4], [1, 2, 3], [1, 2]]
# 使用diags函数,该函数的第二个变量为对角矩阵的偏移量,
0:代表不偏移,就是(0,0)(1,1)(2,2)(3,3)...这样的方式写
k:正数:代表像正对角线的斜上方偏移k个单位的那一列对角线上的元素。
-k:负数,代表向正对角线的斜下方便宜k个单位的那一列对角线上的元素,
由此看下边输出
diags(diagonals, [0, -1, 2]).toarray()
array([[1, 0, 1, 0],
[1, 2, 0, 2],
[0, 2, 3, 0],
[0, 0, 3, 4]])
'''
mx = r_mat_inv.dot(mx) # 矩阵乘法运算
return mx # 返回归一化后的数据
def sparse_mx_to_torch_sparse_tensor(sparse_mx):
"""Convert a scipy sparse matrix to a torch sparse tensor."""
sparse_mx = sparse_mx.tocoo().astype(np.float32) # 将数据变成稀疏矩阵np类型
indices = torch.from_numpy( # 索引
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
values = torch.from_numpy(sparse_mx.data)# 数值
shape = torch.Size(sparse_mx.shape) # 形状
return torch.sparse.FloatTensor(indices, values, shape) # 变成torch的稀疏矩阵
def load_data(path="../data/cora/", dataset="cora"):
"""Load citation network dataset (cora only for now)"""
print('Loading {} dataset...'.format(dataset))
# 下面的idx_features_labels 打开的文件之所以是索引特征和标签简明文件存放的内容
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset), # 指定文件路径
dtype=np.dtype(str)) # 指定文件类型
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32) # 0是索引-1是标签
# 使用索引取数值的时候左侧一定能取到右侧表示取不到的位置
labels = encode_onehot(idx_features_labels[:, -1]) # 最后一列是标签
# build graph
'''
重点构建图 #######################################################
'''
idx = np.array(idx_features_labels[:, 0], dtype=np.int32) # 取content文件中的第一列,就是找出有类别文件中的索引信息
idx_map = {j: i for i, j in enumerate(idx)} # 对所有论文进行编码 存入字典中。输入论文编码就知道创建的索引信息----现阶段的目的是计算邻接矩阵的行列信息
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset), # 导入边信息
dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),# 将引用信息文件中的论文编码全部换成了索引信息
dtype=np.int32).reshape(edges_unordered.shape) # 一开始展开的目的是需要序列数据,现在再次reshape
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32) # 创建稀疏矩阵coo类型的adj,只需要给存在数据的行和列的数据以及数值,并且定义了类型和shape大小
# build symmetric adjacency matrix
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
这行代码是在构建一个对称的邻接矩阵adj。在图卷积神经网络中,邻接矩阵用于表示图中节点之间的连接关系。对于无向图而言,其邻接矩阵是对称的,即如果节点i与节点j相连,则adj[i, j]和adj[j, i]的值都应该为1。
然而,在创建初始邻接矩阵时,可能会存在一些不对称的情况,即adj[i, j]不等于adj[j, i]。为了纠正这种不对称性并确保邻接矩阵的一致性,需要进行以下操作:
-
adj + adj.T:首先,将邻接矩阵adj与其转置adj.T相加,确保所有的连接是双向的。 -
adj.T.multiply(adj.T > adj):计算adj的转置减去adj只在转置矩阵中的元素大于原矩阵时才计算,这样可以获取所有adj矩阵未能覆盖的对应连接。 -
- adj.multiply(adj.T > adj):从第一个步骤的结果中减去只有在adj的元素小于adj.T时才存在的元素,以避免重复计数任何连接。
最终结果是一个对称的邻接矩阵,完美地表示无向图的连接关系。这保证了当我们在图网络中传播信息时,连接的权重是相互的,并且流向节点i和节点j的信息是等价的。
features = normalize(features) # 特征归一化
adj = normalize(adj + sp.eye(adj.shape[0])) # 邻接矩阵加上对角线
idx_train = range(140) # 划分数据集
idx_val = range(200, 500)
idx_test = range(500, 1500)
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1]) # 取出数值为1的索引,就是真实label
adj = sparse_mx_to_torch_sparse_tensor(adj)
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
def accuracy(output, labels): # 准确率计算
preds = output.max(1)[1].type_as(labels)
correct = preds.eq(labels).double()
correct = correct.sum()
return correct / len(labels)
3.2 layers 模块
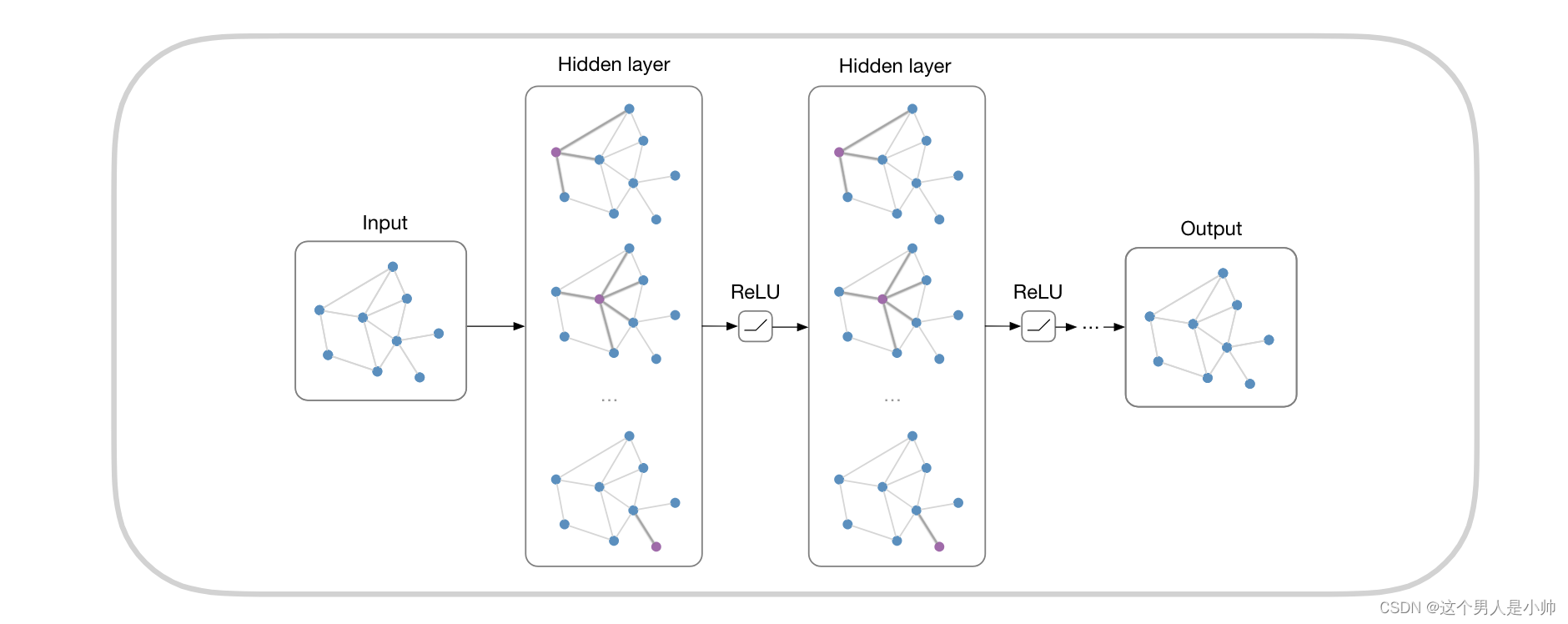
此模块定义了一个简单的图卷积网络层(GCN层),它实现了基本的图卷积操作,类似于在文献中所描述的原始GCN层。主要组件包括权重矩阵和可选偏置,其中权重矩阵通过一定的初始化策略进行参数初始化。在前向传递函数中,输入特征与权重矩阵相乘以获得支持(支持表示节点特征的转换),然后通过图的邻接矩阵进行传播,如果定义了偏置,将其添加到输出中。这样的层可以被堆叠使用来构建深层图神经网络。
import math #提供各种各样的数学擦欧总
import torch
from torch.nn.parameter import Parameter # 构建的参数可以求梯度
from torch.nn.modules.module import Module # 创建神经网络的基类
class GraphConvolution(Module):
def __init__(self, in_features, out_features, bias=True): # 网络的输入和输出大小,是否引入偏置项
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features, out_features)) # 设置权重参数的维度
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self): # 控制权重随机的范围
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input, adj):
support = torch.mm(input, self.weight)
output = torch.spmm(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output
def __repr__(self): # 设置一个魔法方法,用于检测当前对象的输入输出大小,通过输出对象的方式
return self.__class__.__name__ + ' (' \
+ str(self.in_features) + ' -> ' \
+ str(self.out_features) + ')'
def reset_parameters(self): # 控制权重随机的范围,现在解释下:
假设我们在构建一个图卷积网络层,其输入特征维度为100(即每个节点的特征向量长度为100),输出特征维度也设置为100,那么权重矩阵self.weight的大小将是(100, 100),表示从输入特征到输出特征的线性变换。
-
计算标准差 (
stdv):- 首先,
self.weight.size(1)得到的是权重矩阵的第二维大小,即100。 - 然后,
math.sqrt(self.weight.size(1))计算输入特征维度100的平方根,即10。 - 最后,
1. / math.sqrt(self.weight.size(1))计算了10的倒数,得到stdv = 0.1。这个值用作初始化权重和偏置参数的均匀分布的标准差。
- 首先,
-
初始化权重 (
self.weight.data.uniform_(-stdv, stdv)):- 使用上一步计算得到的
stdv = 0.1,权重被初始化为在[-0.1, 0.1]之间的均匀分布。这意味着每个权重值都会随机地从这个区间中选取一个数值。
- 使用上一步计算得到的
-
初始化偏置 (
self.bias.data.uniform_(-stdv, stdv)):- 如果偏置不为
None,即模型选择使用偏置项,偏置也会被初始化为在[-0.1, 0.1]之间的均匀分布。这里的偏置是一个长度为输出特征维度,即100的向量。
- 如果偏置不为
通过这种方式初始化参数,保证了模型参数在一开始不会太大或太小,有利于优化算法更好、更快地找到误差的全局最小值,从而提高模型训练的效率和性能。‘
3.3 models 模块
该模块下的代码,定义了一个使用图卷积层构建的简单图卷积网络(GCN)架构,体现了GCN模型的典型结构和数据流动方式。
import torch.nn as nn
import torch.nn.functional as F # torch.nn 和nn.functional主要区别一个是类一个是函数,类需要实例化调用。
from pygcn.layers import GraphConvolution # 导入自建包
class GCN(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout):
super(GCN, self).__init__()
self.gc1 = GraphConvolution(nfeat, nhid)
self.gc2 = GraphConvolution(nhid, nclass)
self.dropout = dropout
def forward(self, x, adj):
x = F.relu(self.gc1(x, adj))
x = F.dropout(x, self.dropout, training=self.training)
x = self.gc2(x, adj)
return F.log_softmax(x, dim=1)
3.4 模型的训练代码
from __future__ import division # __future__可以理解成一个先行版,在这里得到版本是先行版
from __future__ import print_function
import time
import argparse # 用于参数调用
import numpy as np
import torch
import torch.nn.functional as F
import torch.optim as optim
from pygcn.utils import load_data, accuracy # 两部的都是自己写的
from pygcn.models import GCN
# Training settings
parser = argparse.ArgumentParser() # 对类进行实例化,这个类的特殊在于能够处理命令行的输入
parser.add_argument('--no-cuda', action='store_true', default=False,
help='Disables CUDA training.')
parser.add_argument('--fastmode', action='store_true', default=False,
help='Validate during training pass.')
parser.add_argument('--seed', type=int, default=42, help='Random seed.')
parser.add_argument('--epochs', type=int, default=200,
help='Number of epochs to train.')
parser.add_argument('--lr', type=float, default=0.01,
help='Initial learning rate.')
parser.add_argument('--weight_decay', type=float, default=5e-4,
help='Weight decay (L2 loss on parameters).')
parser.add_argument('--hidden', type=int, default=16,
help='Number of hidden units.')
parser.add_argument('--dropout', type=float, default=0.5,
help='Dropout rate (1 - keep probability).')
args = parser.parse_args() #对参数进行分析
args.cuda = not args.no_cuda and torch.cuda.is_available()
np.random.seed(args.seed) # 随机数种子设置
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
# Load data
adj, features, labels, idx_train, idx_val, idx_test = load_data() # 给地址
# Model and optimizer
model = GCN(nfeat=features.shape[1],# 实例化模型
nhid=args.hidden,
nclass=labels.max().item() + 1,
dropout=args.dropout)
optimizer = optim.Adam(model.parameters(),# 实例化优化器
lr=args.lr, weight_decay=args.weight_decay)
if args.cuda:
model.cuda()
features = features.cuda()
adj = adj.cuda()
labels = labels.cuda()
idx_train = idx_train.cuda()
idx_val = idx_val.cuda()
idx_test = idx_test.cuda()
def train(epoch):
t = time.time()
model.train()
optimizer.zero_grad()
output = model(features, adj)
loss_train = F.nll_loss(output[idx_train], labels[idx_train])
acc_train = accuracy(output[idx_train], labels[idx_train])
loss_train.backward()
optimizer.step()
if not args.fastmode:
# Evaluate validation set performance separately,
# deactivates dropout during validation run.
model.eval()
output = model(features, adj)
loss_val = F.nll_loss(output[idx_val], labels[idx_val])
acc_val = accuracy(output[idx_val], labels[idx_val])
print('Epoch: {:04d}'.format(epoch+1),
'loss_train: {:.4f}'.format(loss_train.item()),
'acc_train: {:.4f}'.format(acc_train.item()),
'loss_val: {:.4f}'.format(loss_val.item()),
'acc_val: {:.4f}'.format(acc_val.item()),
'time: {:.4f}s'.format(time.time() - t))
def test():
model.eval()
output = model(features, adj)
loss_test = F.nll_loss(output[idx_test], labels[idx_test])
acc_test = accuracy(output[idx_test], labels[idx_test])
print("Test set results:",
"loss= {:.4f}".format(loss_test.item()),
"accuracy= {:.4f}".format(acc_test.item()))
# Train model
t_total = time.time()
for epoch in range(args.epochs):
train(epoch)
print("Optimization Finished!")
print("Total time elapsed: {:.4f}s".format(time.time() - t_total))
# Testing
test()
上述部分和其他深度学习代码并无差异如果感兴趣可以参考pytorch模块下的作业代码深入理解。
总结
当前代码主要的工作量就是在数据的处理以及网络的构建,其他并无明显差异,在图卷积网络(GCN)和图神经网络(GNN)的构建与学习过程中,数据的处理和网络架构的设计无疑是占据主要工作量的两大核心领域。这些任务之所以充满挑战,很大程度上在于需要精巧地表征和处理具有图结构的数据,并创新性地构建能够捕捉其复杂模式的网络结构。为了更有效地提高模型性能,学习过程中应着重关注和深入探索网络搭建和数据预处理的相关知识和技术。通过对这些关键部分进行深刻理解和不断练习,可以实现模型效率的显著提升,并且更好地将理论应用于解决实际问题。