Apache Solr 9.1-(一)初体验单机模式运行
Solr是一个基于Apache Lucene的搜索服务器,Apache Lucene是开源的、基于Java的信息检索库,Solr能为用户提供无论在任何时候都可以根据用户的查询请求返回结果,它被设计为一个强大的文档检索引擎。
目录
- Apache Solr 9.1-(一)初体验单机模式运行
- 一、安装Apache Solr 9.1
- 1、各组件版本说明
- 2、下载Apache Solr 9.1
- 3、解压和配置JDK
- 二、创建Core
- 1、使用solr create命令创建core
- 三、安装中文分词器
- 1、下载IK-Analyzer
- 2、将ik-analyzer-8.5.0.jar放入solr目录下
- 3、将ik-analyzer中文分词类型加入上步新创建的core_test1中
- 4、重启solr服务
- 四、安装solr自带的smartcn中文分词器
- 1、将lucene-analysis-smartcn-9.3.0.jar也要放入solr目录下
- 2、将smartcn中文分词类型加入上步新创建的core_test1中
- 3、重启solr服务
- 4、验证smartcn中文分词器
- 五、解决不能通过其它机器通过http://ip:8983/solr/访问的问题
- 1、编辑solr-9.1.0\bin\solr.cmd
- 2、重启solr服务
- 3、验证
- 六、配置Core中字段
- 1、各数据类型与solr中类型的对应关系
- 2、为core添加字段
- 3、删除core目录下的data目录并重启solr服务
一、安装Apache Solr 9.1
1、各组件版本说明
| 序号 | 软件名称 | 版本 | 说明 |
|---|---|---|---|
| 1 | JDK | 11 | Apache Solr9.1要求JDK的版本最低为11,可以是openjdk |
| 2 | Apache Solr | 9.1 | 基于Apache Lucene搜索服务器 |
| 3 | IK-Analyzer | 8.5.0 | 中文分词器 |
| 4 | Zookeeper | 2.4.15 | 本文中暂时用不到,在后序关与Apache Solr9.1集群部署的文章中会用到 |
2、下载Apache Solr 9.1
JDK11也需要提前下载好,在本文中就不再详述JDK11的下载和安装了,可以选择Oracle JDK11,也可以是OPEN JDK11,无论是哪个JDK,版本最低是11。
Apache Solr官方下载地址
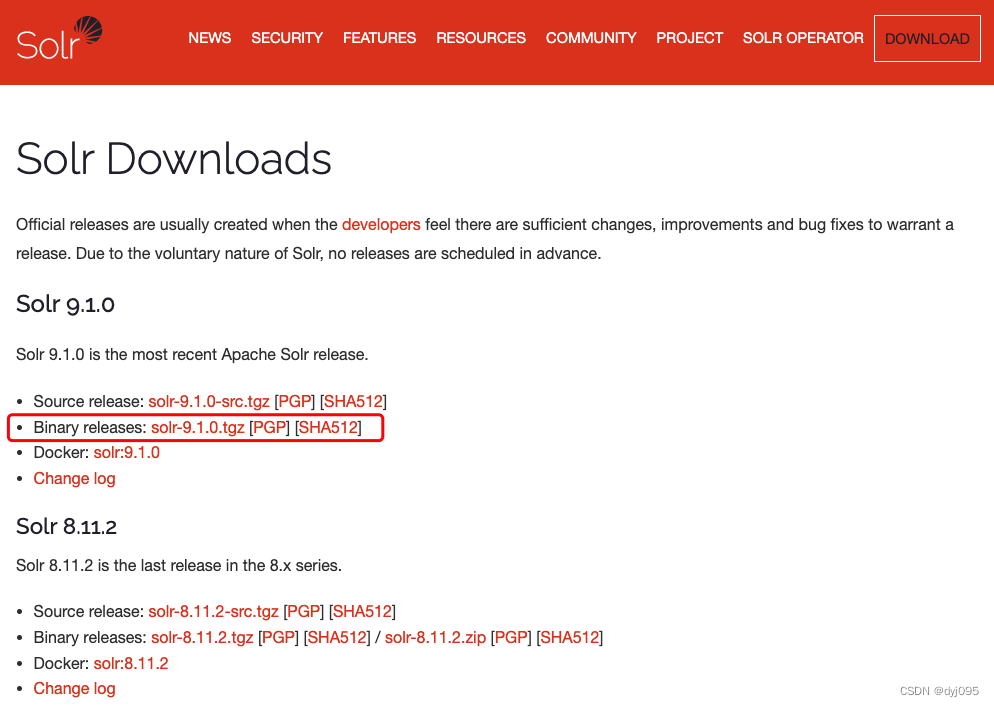
3、解压和配置JDK
1). 解压到目标目录下

2).配置JDK11的环境变量
如果大家已经将JDK11做为默认的JDK版本(JAVA_HOME环境变量指向JDK11的安装目录)了,就可以跳过此步了,该步骤是针对当前系统环境中默认是JDK版本不是JDK11(我的环境目前仍是JDK8),但是solr9.1还需要用于JDK11的场景。
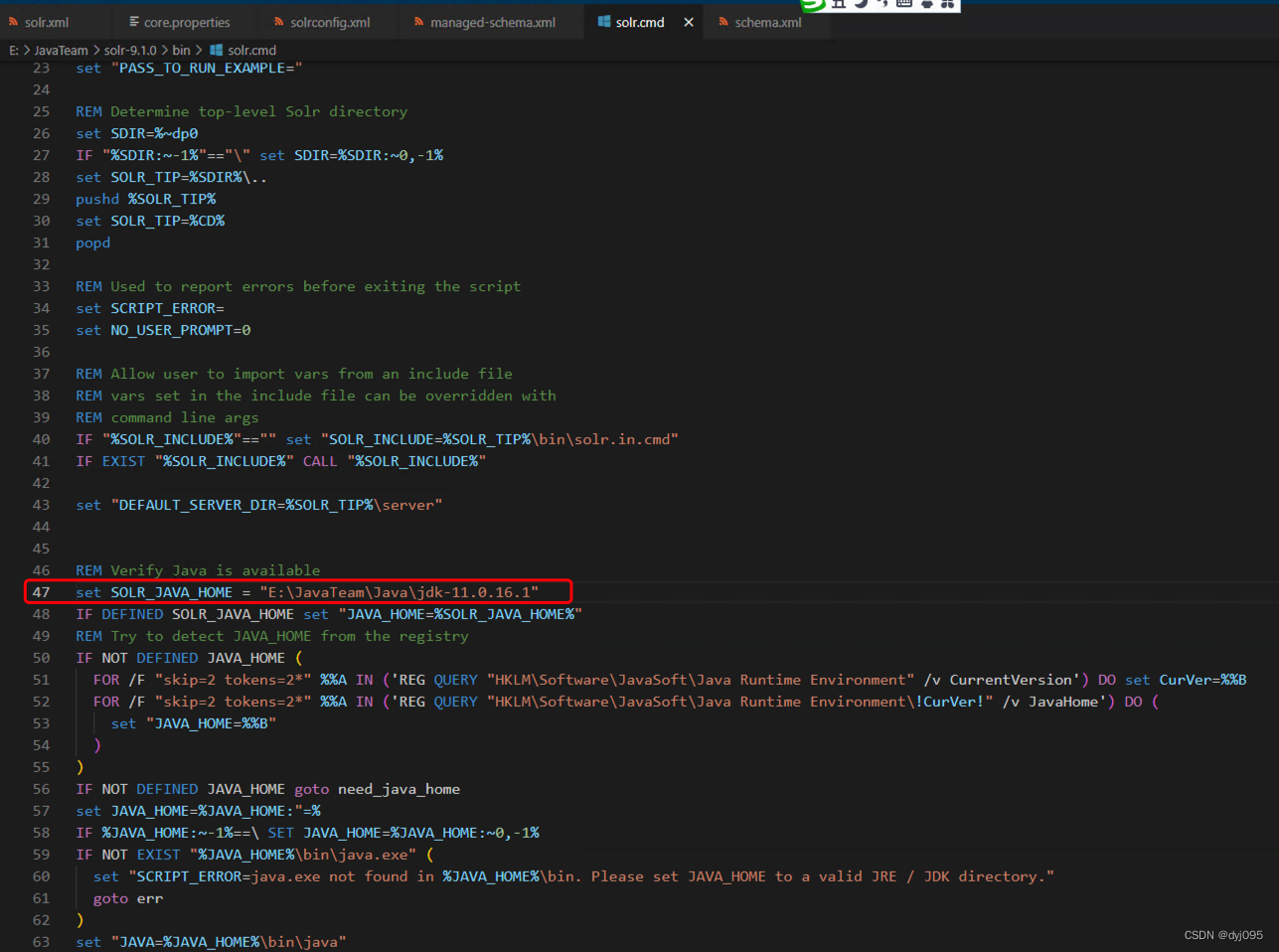
通过编辑solr9.1\bin\solr.cmd脚本,在此脚本中设置JDK11的安装路径。
在solr.cmd脚本增加下面的代码,来设置SOLR_JAVA_HOME环境变量,用于指定solr用到的JDK11的安装目录。
set SOLR_JAVA_HOME = "E:\JavaTeam\Java\jdk-11.0.16.1"
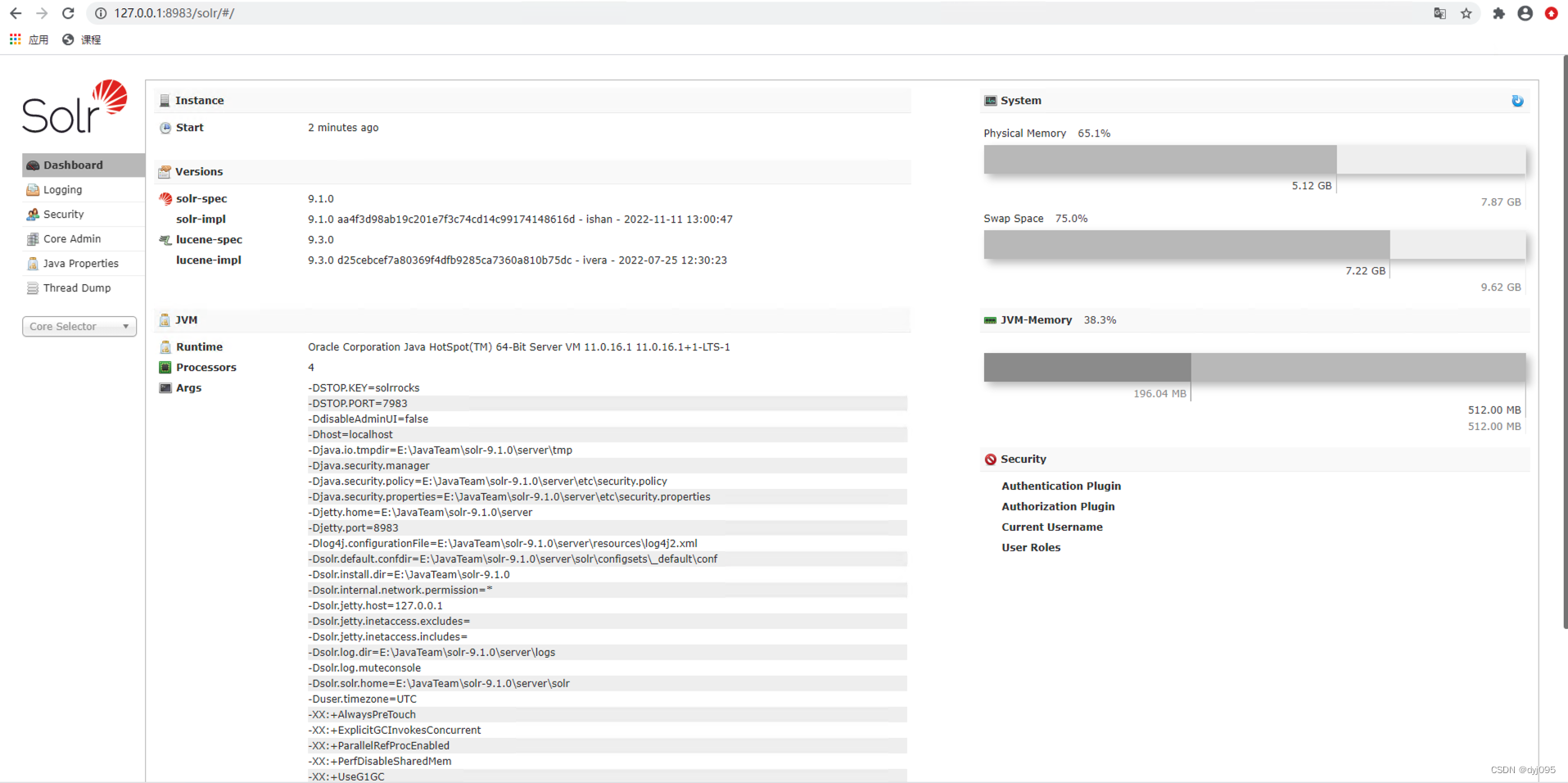
3).启动
solr.cmd start

二、创建Core
通过管理画面http://ip:8983/solr的core Admin模块进行创建会失败,提示在新创建的core目录\conf\下找不到solrconfig.xml和managed-schema.xml,所以我们采用命令行的方式来创建Core。
1、使用solr create命令创建core
solr9.1安装目录\bin>solr create -c core名称

三、安装中文分词器
- Apache Solr中默认没有中文分词器,导致对中文数据做查询时,无法对中文词组做识别和模糊查询,只能将中文每个字做为独立的词组做查询,所以需要为Apache Solr安装中文分词器。
- solr中可用的中文分词器有很多,有IK-Analyzer、Smartcn、Jeasy,庖丁,由于我在Apache Solr4.10版本中使用的就是IK-Analyzer中文分词器(注意与Apache Solr的版本要匹配),所以在Apache Solr9.1还是安装IK-Analyzer中文分词器,大家可以根据自己需要安装需要的中文分词器。
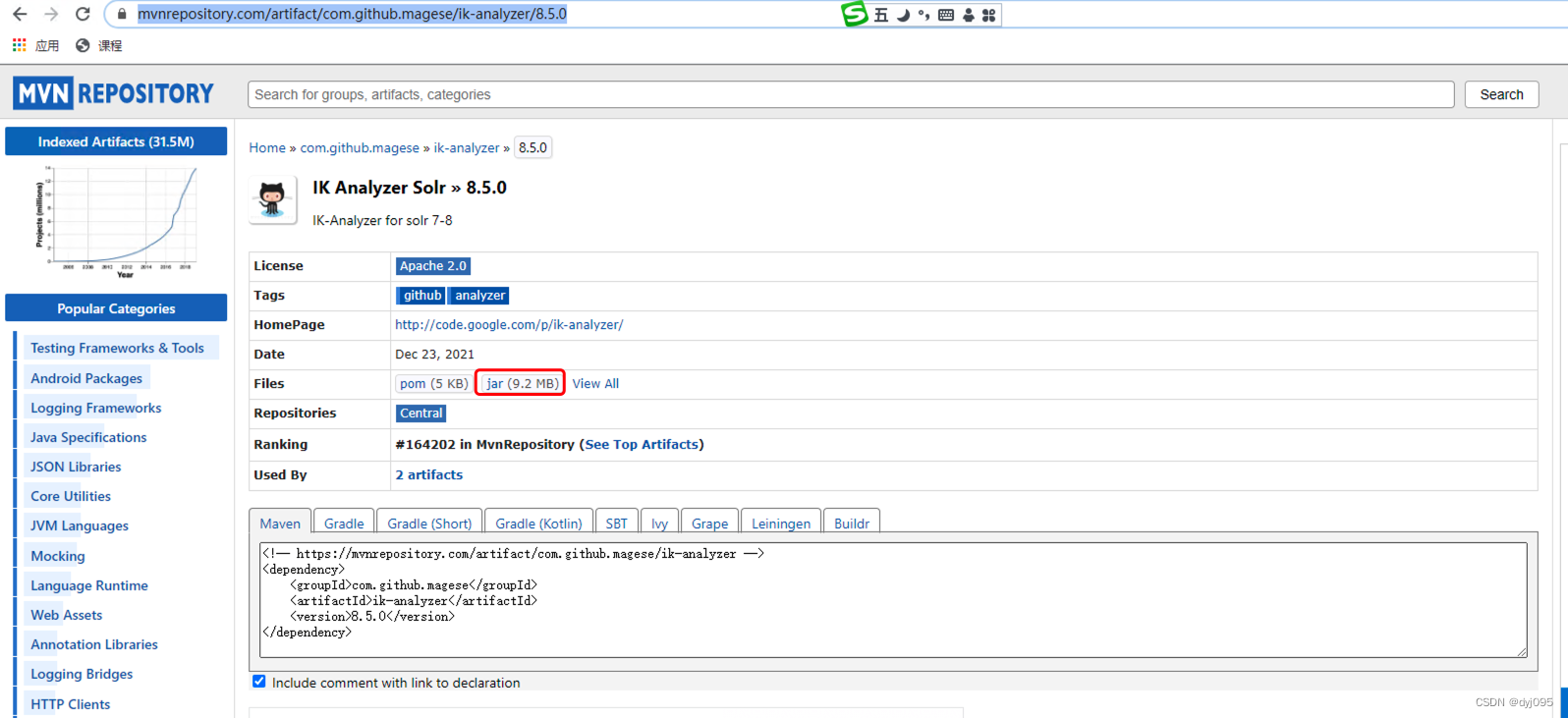
1、下载IK-Analyzer
点击此处【下载地址】下载
2、将ik-analyzer-8.5.0.jar放入solr目录下
存放于 solr-9.1.0\server\solr-webapp\webapp\WEB-INF\lib\ 目录下
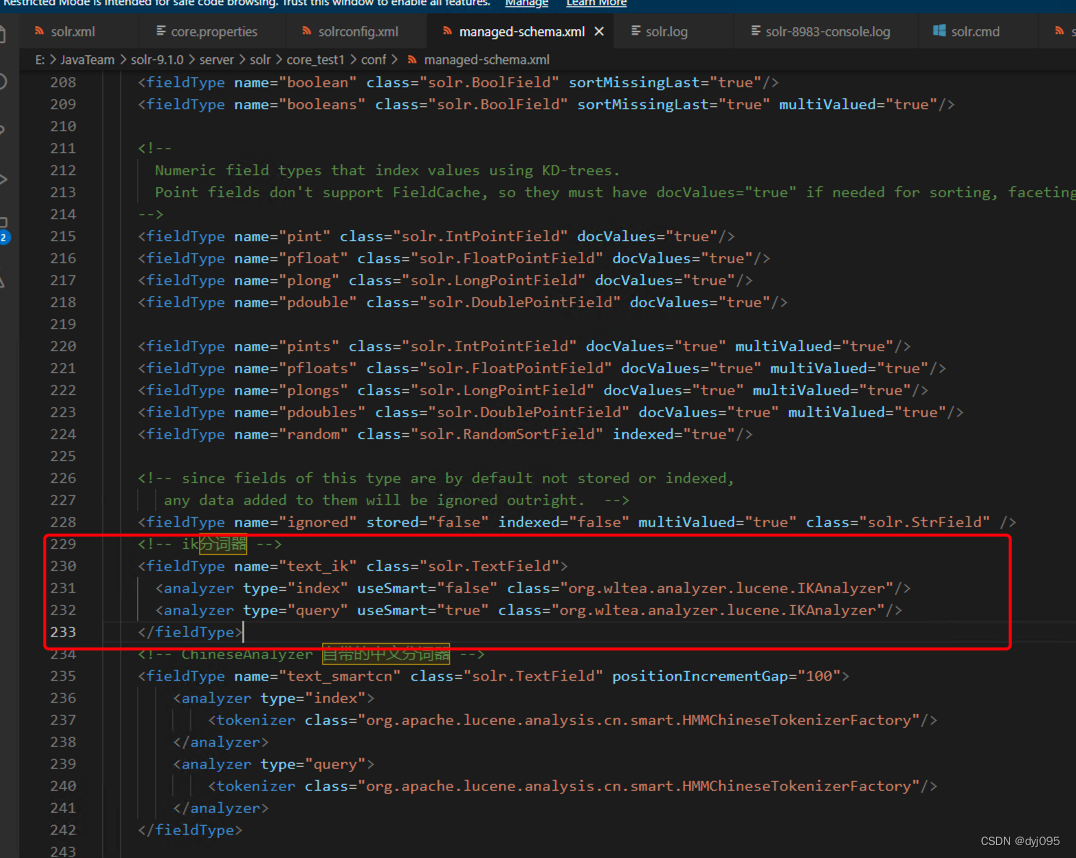
3、将ik-analyzer中文分词类型加入上步新创建的core_test1中
编辑solr-9.1.0\server\solr\core_test1\conf\managed-schema.xml
<!-- ik分词器 -->
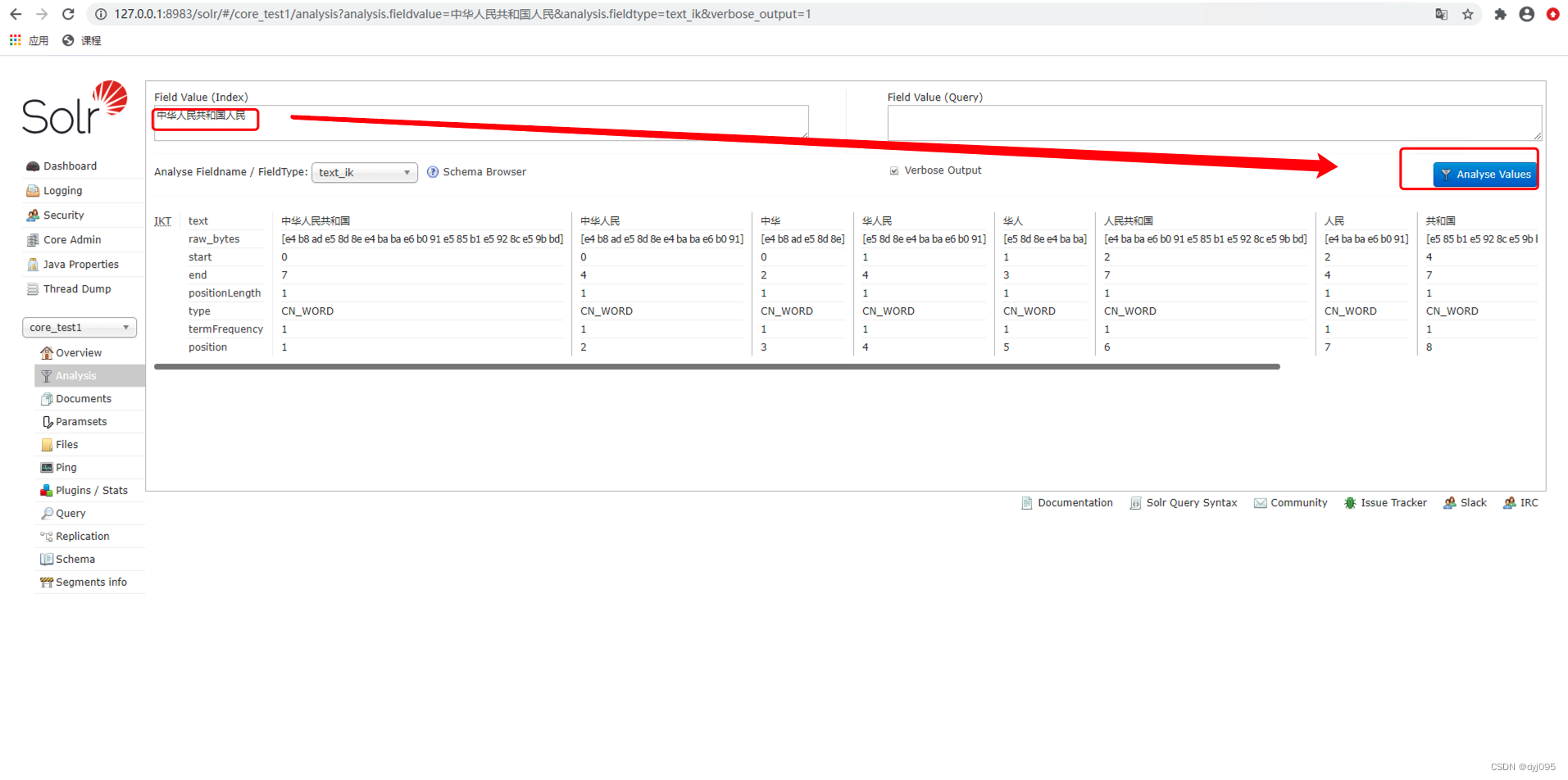
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
4、重启solr服务
1). 通过netstat命令查询占用8983的进程号
netstat -ano | find "8983"
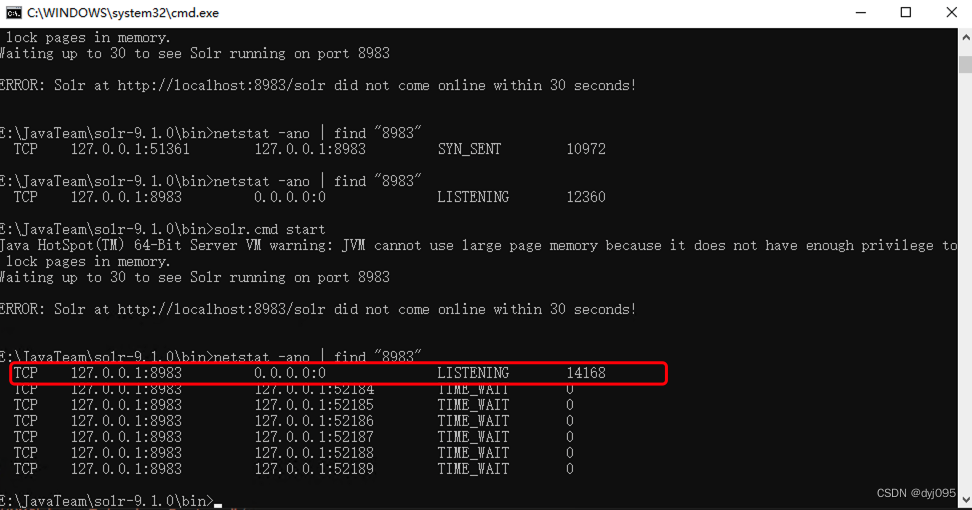
2).结束进程号为14168的进程
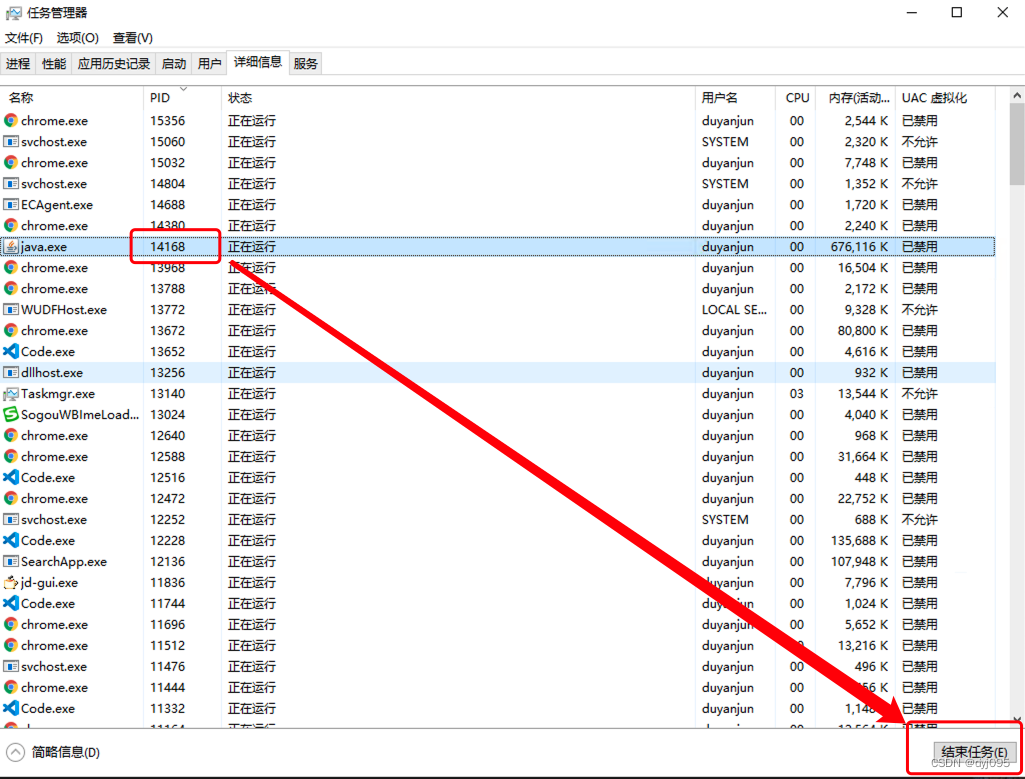
3).启动solr服务
solr.cmd start
4).验证ik-analyzer分词
四、安装solr自带的smartcn中文分词器
1、将lucene-analysis-smartcn-9.3.0.jar也要放入solr目录下
从solr-9.1.0\modules\analysis-extras\lib\目录下复制lucene-analysis-smartcn-9.3.0.jar到solr-9.1.0\server\solr-webapp\webapp\WEB-INF\lib\目录下
2、将smartcn中文分词类型加入上步新创建的core_test1中
编辑solr-9.1.0\server\solr\core_test1\conf\managed-schema.xml
<!-- smartcn分词器 -->
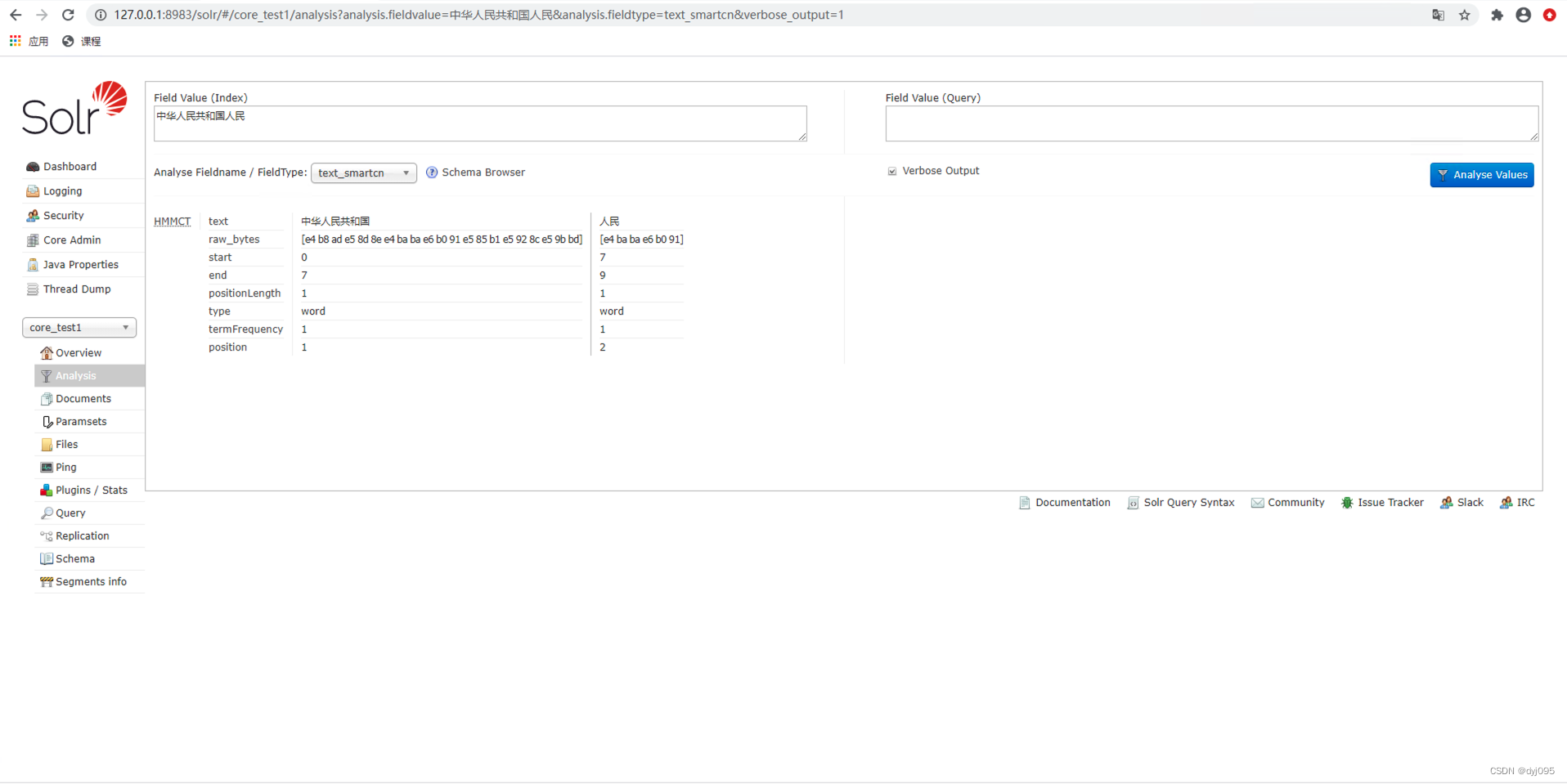
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
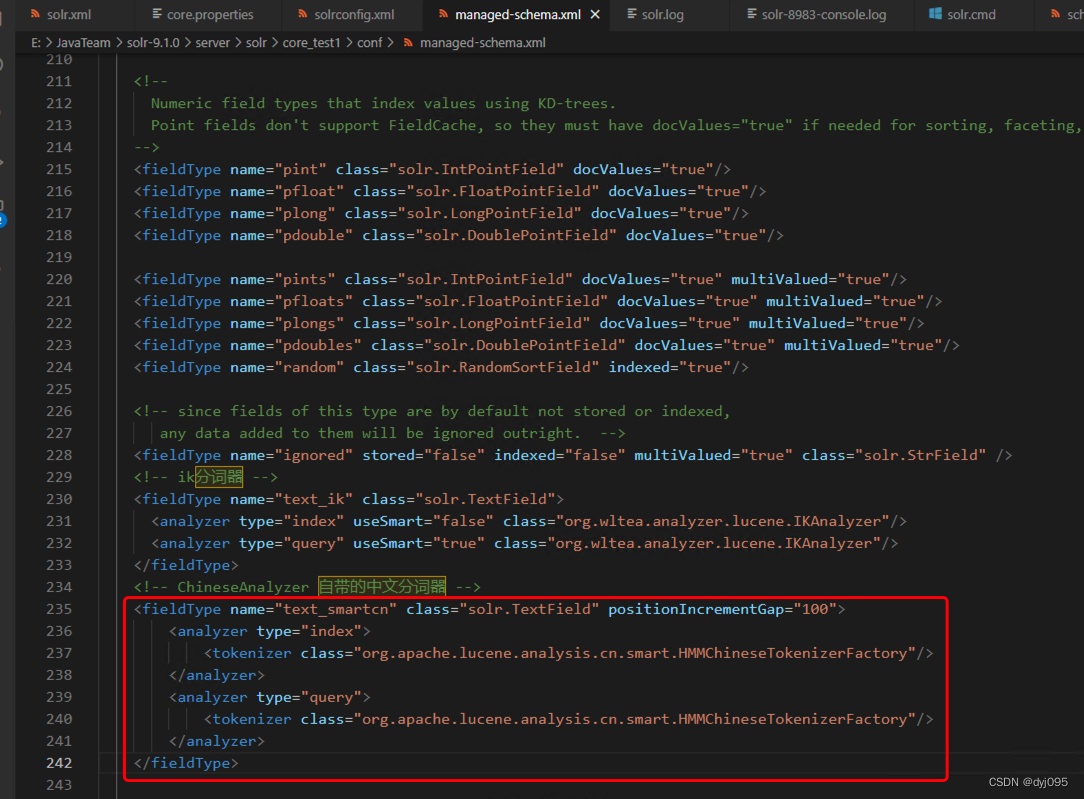
3、重启solr服务
4、验证smartcn中文分词器
五、解决不能通过其它机器通过http://ip:8983/solr/访问的问题
solr默认只能通过http://127.0.0.1:8983/solr来访问,如果要允许其它机器通过网络ip来访问,需要修改设置
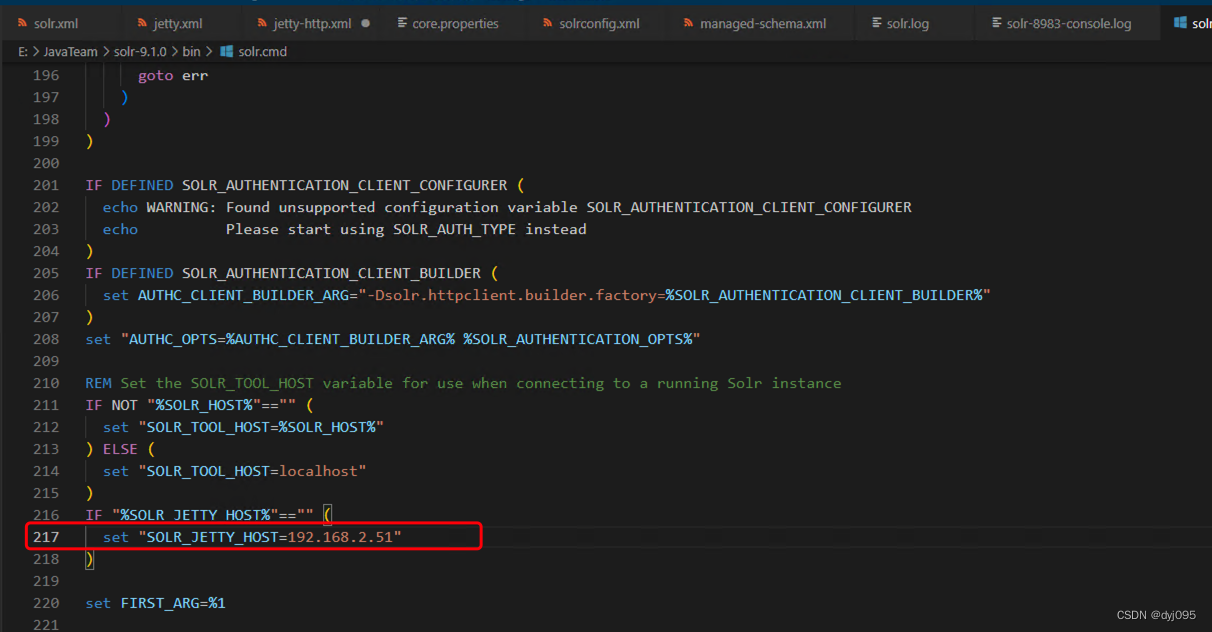
1、编辑solr-9.1.0\bin\solr.cmd
set "SOLR_JETTY_HOST=192.168.2.51"
2、重启solr服务
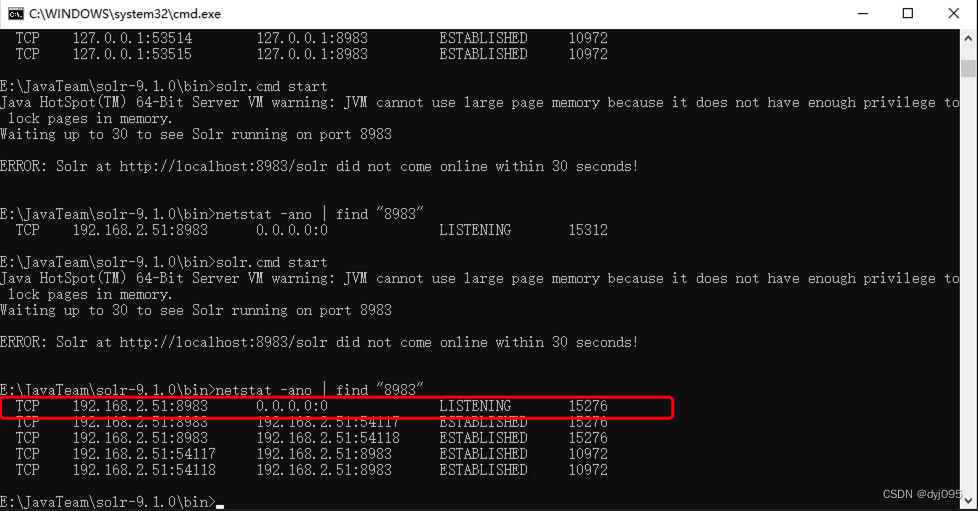
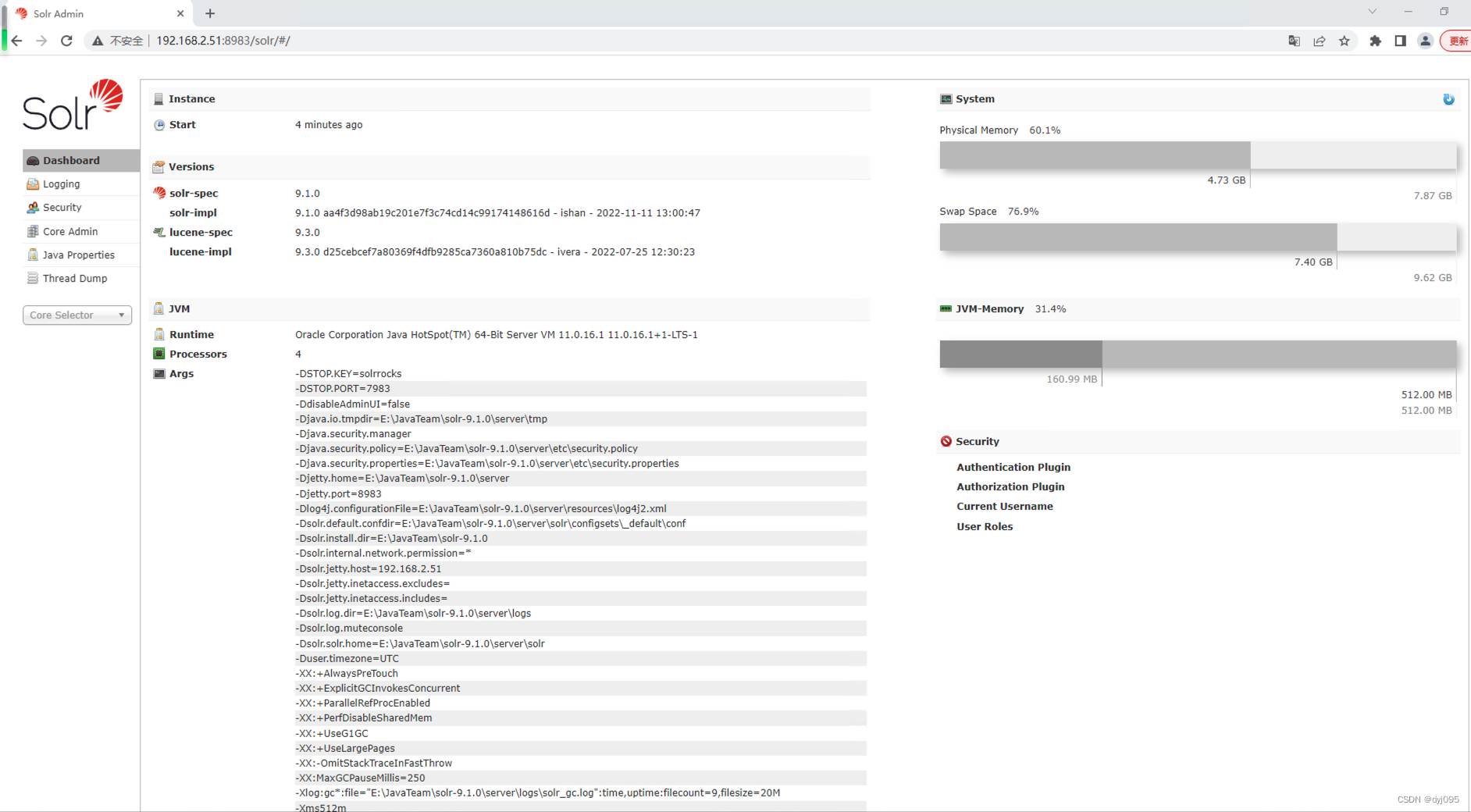
3、验证
然后就可以通过http://ip:8983/solr来访问solr服务了
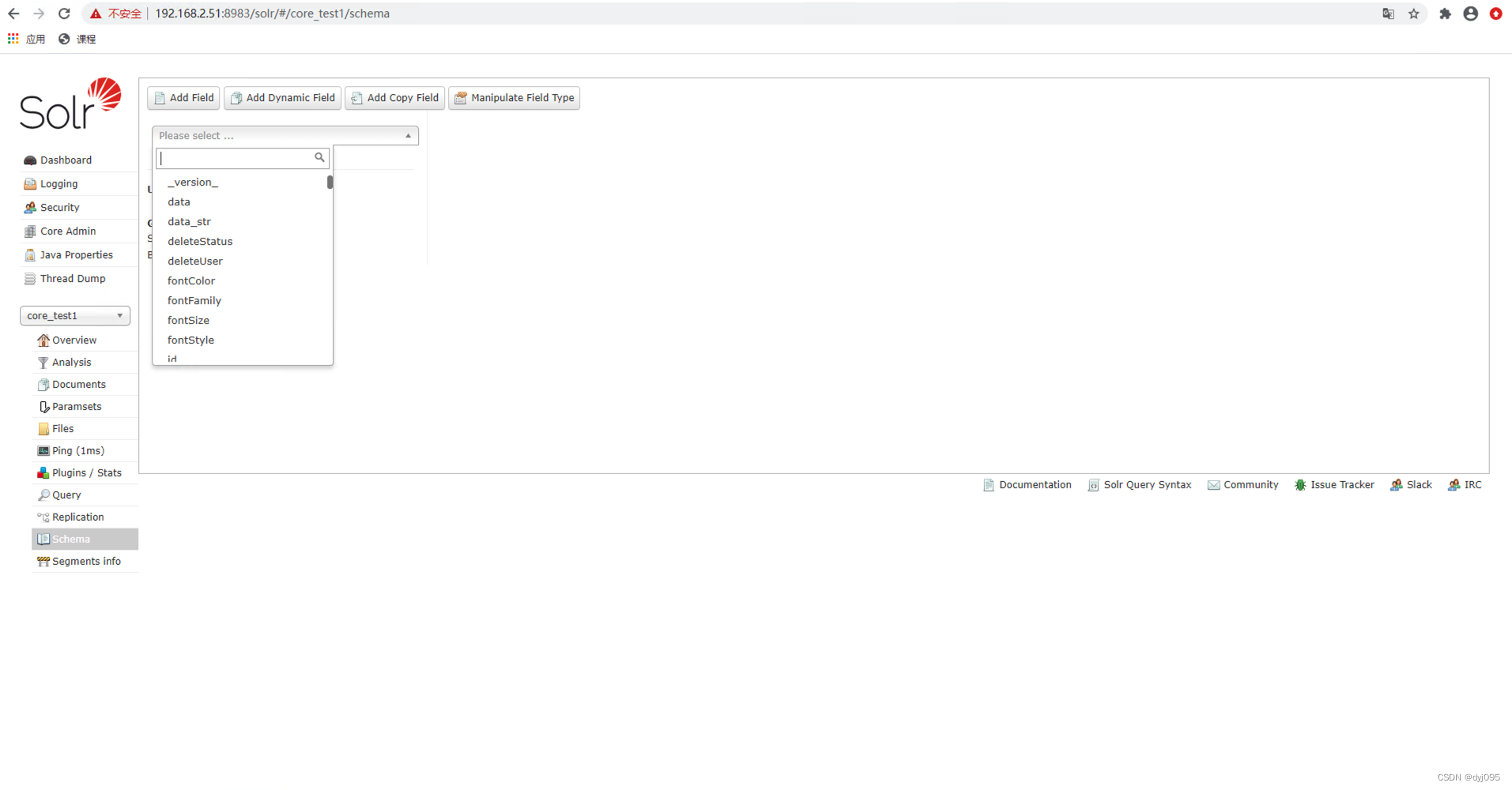
六、配置Core中字段
1、各数据类型与solr中类型的对应关系
| 序号 | 基本数据类型 | Solr中数据类型 | 说明 |
|---|---|---|---|
| 1 | int | pint | |
| 2 | fload | pfloat | |
| 3 | long | plong | |
| 4 | double | pdouble | |
| 5 | String | string | 无需中文分词 |
| 6 | String | text_ik、text_smartcn | 需要中文分词 |
| 7 | date | pdate |
更多的数据类型定义请参阅官方文档或solr-9.1.0\server\solr\core_test1\conf\managed-schema.xml文件中fieldType的定义
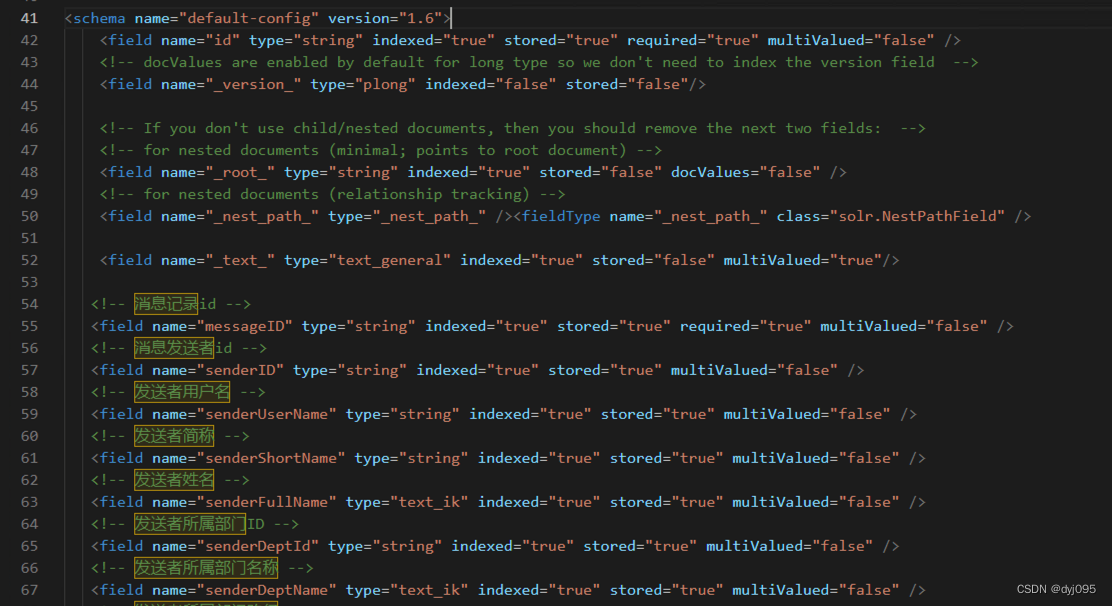
2、为core添加字段
编辑solr-9.1.0\server\solr\core_test1\conf\managed-schema.xml,在文档中schema节点下添加field节点定义
3、删除core目录下的data目录并重启solr服务