热点Key问题,这是一个老生常谈的问题了,今天我们来仔细的去剖析这个问题。
热点key带来的问题
- 流量集中。达到服务器处理上限(CPU,网络IO等)
- 会影响在同一个Redis实例上其他key的读写请求操作
- 热key请求落到同一个Redis实例上,无法通过扩容解决
- 大量Redis请求失败,查询操作可能打到数据库,拖垮数据库,导致整个服务不可用
如何发现热点key
凭借业务经验,预估热点key的出现
这样缺点很明显,就是不准确,无法完美预估。
客户端进行收集
例如我用小根堆,哈希表对热点key进行统计。但是它的缺点是:对代码有一定的入侵,而且无法适应多语言架构,每一种语言的SDK都需要进行开发,后期开发维护成本很高。
在代理层进行收集

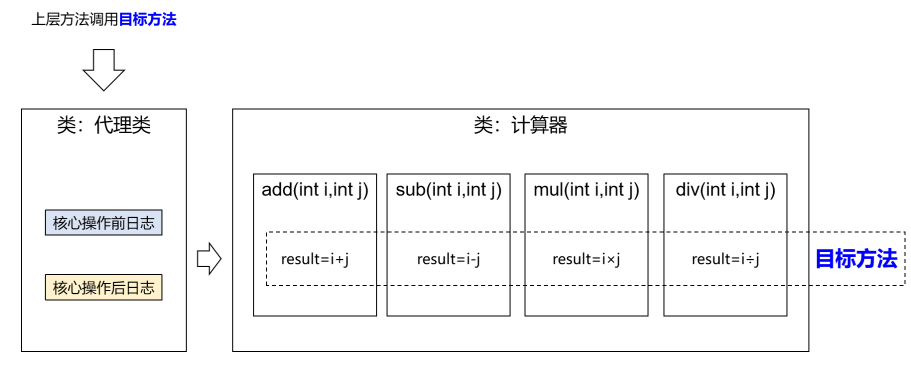
这里我们大概来将一下这个图:
- SLB层做负载均衡
- Proxy层做读写分离自动路由
- Master负责写请求
- ReadOnly负责读请求
- Slave节点和Master节点做高可用
- 实际过程中Client将请求传到SLB,SLB又将其分发至多个Proxy内,通过Proxy对请求的识别,将其进行分类发送
这样做的优点是:
- 对使用方完全透明,能够解决客户端SDK的语言异构和版本升级问题
- 只需要对proxy进行横向拓展,就可以任意增强热点数据的访问能力
缺点也很明显:
- 并不是所有Redis集群架构中都有Proxy代理(使用这种方式必须要部署Proxy)
- 开发成本太高了
使用Redis自带的命令
Redis 在 4.0.3 版本中添加了 hotkeys 查找特性,可以直接利用 redis-cli --hotkeys 获取当前 keyspace 的热点 key,实现上是通过 scan + object freq 完成的。
- 优点:无需进行二次开发,能够直接利用现成的工具;
- 缺点:
- 由于需要扫描整个
keyspace,实时性上比较差; - 扫描时间与
key的数量正相关,如果key的数量比较多,耗时可能会非常长。
- 由于需要扫描整个
Redis节点抓包分析
Redis 客户端使用 TCP 协议与服务端进行交互,通信协议采用的是 RESP 协议。自己写程序监听端口,按照 RESP 协议规则解析数据,进行分析。或者我们可以使用一些抓包工具,比如 tcpdump 工具,抓取一段时间内的流量进行解析。
- 优点:对
SDK或者Proxy代理层没有入侵; - 缺点:
- 有一定的开发成本;
- 热
Key节点的网络流量和系统负载已经比较高了,抓包可能会导致情况进一步恶化。
如何解决热点Key问题
使用二级缓存(本地缓存)
我们使用哈希表做二级缓存就可以,其实不需要那么复杂。
使用本地缓存需要注意两个问题:
- 如果对热
Key进行本地缓存,需要防止本地缓存过大,影响系统性能; - 需要处理本地缓存和
Redis集群数据的一致性问题。
热key备份
Redis 热 Key 问题首先是请求流量过大造成的,但是更深层次原因还是出现了流量倾斜,单个 Redis 实例承担的流量过大造成的,了解到了本质原因,解决的思路也就简单了,就是要想尽一切办法将单个实例承担的流量打散,让每个机器均衡承担热 Key 的流量,不要出现流量倾斜,保证系统的稳定性。
因此,我们需要进行热key备份。
通过前面的分析,我们可以了解到,之所以出现热 Key,是因为有大量的对同一个 Key 的请求落到同一个 Redis 实例上,如果我们可以有办法将这些请求打散到不同的实例上,防止出现流量倾斜的情况,那么热 Key 问题也就不存在了。
那么如何将对某个热 Key 的请求打散到不同实例上呢?我们就可以通过热 Key 备份的方式,基本的思路就是,我们可以给热 Key 加上前缀或者后缀,把一个热 Key 的数量变成 Redis 实例个数 N 的倍数 M,从而由访问一个 Redis Key 变成访问 N * M 个 Redis Key。 N * M 个 Redis Key 经过分片分布到不同的实例上,将访问量均摊到所有实例。
我们来看一下热key备份的伪代码:
// N为Redis实例个数,M为N的2倍
const M = N * 2;
// 生成随机数
random = GetRandom(0, M);
// 构造备份新的key
bakHotKey = hotKey + "_" + random;
data = redis.GET(bakHotKey);
if data == NULL {
data = redis.GET(hotKey);
// 可以利用原子锁写入数据保证数据的一致性
redis.SET(hotKey, data, expireTime);
redis.SET(bakHotKey, data, expireTime + GetRandom(0, 5));
} else {
redis.SET(bakHotKey, data, expireTime + GetRandom(0, 5));
}
在这段代码中,通过一个大于等于 1 小于 M 的随机数,得到一个 bakHotKey,程序会优先访问 bakHotKey,在得不到数据的情况下,再访问原来的 hotkey,并将 hotkey 的内容写回 bakHotKey。值得注意的是,bakHotKey 的过期时间是 hotkey 的过期时间加上一个较小的随机正整数,这是通过坡度过期的方式,保证在 hotkey 过期时,所有 bakHotKey 不会同时过期而造成缓存雪崩。