大纲
- Postgresql数组
- 案例
- 常规写法
- 定义结构体
- 查询数据
- 问题
- 反射+泛型写法
- 结构体定义
- 接口
- Tag
- 实现逻辑
- 泛型设计
- 实例化模型结构体
- 获取表名
- 过滤字段
- 组装SQL语句
- 查询
- 遍历读取结果
- 实例化模型结构体
- 组装Scan方法的参数
- 调用Scan方法并保存结果
- 完整代码
- 小结
Postgresql数组
Postgresql有个很好的功能:可以设置字段为数组。这样我们就不用存储使用特定字符连接的数据,更不需要在取出数据后使用代码逻辑进行切分。举一个例子,我们需要存储一个数组[1,2,3,4]。常规做法是我们将该字段设计为字符串或者文本类型,存储“1,2,3,4”;在业务逻辑中,数据取出后,我们使用“,”进行切分,并将字符串“1”“2”“3”转换为整型,最后组成数组[1,2,3,4]。
为了更好表述这个问题,我们看个Demo。
案例
假设我们要新建一张用来保存员工信息的表——employee
CREATE TABLE "public"."employee" (
"id" int8 NOT NULL,
"name" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
"address" varchar(255) COLLATE "pg_catalog"."default",
"title" varchar(255)[] COLLATE "pg_catalog"."default",
"salary" float8 NOT NULL,
"leader_id" int8,
"subordinate_id" int8[],
"valid" bool NOT NULL
)
;
ALTER TABLE "public"."employee" ADD CONSTRAINT "employee_pkey" PRIMARY KEY ("id");
title字段是头衔,一个员工可能有多个头衔。
subordinate_id是下属员工的ID。
上述两者都是数组类型。
我们再构建部分数据。
-- ----------------------------
-- Records of employee
-- ----------------------------
INSERT INTO "public"."employee" VALUES (3, '丁', '北京', '{Assistant}', 1234.5, 1, NULL, 't');
INSERT INTO "public"."employee" VALUES (0, '甲', '北京望京', '{CEO}', 12345.6, NULL, '{1,2}', 't');
INSERT INTO "public"."employee" VALUES (4, '戊', NULL, '{Assistant}', 234.5, 2, NULL, 't');
INSERT INTO "public"."employee" VALUES (1, '乙', '北京', '{CTO,VP}', 2345.6, 0, '{3}', 't');
INSERT INTO "public"."employee" VALUES (2, '丙', '北京', '{CFO,VP}', 3456.7, 0, '{4}', 't');
更直观的展现是
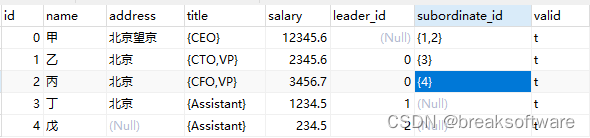
常规写法
定义结构体
type Employee struct {
Id int64
Name string
Address sql.NullString
Title []string
Salary float64
LeaderId sql.NullInt64
SubordinateId []int64
Valid bool
}
查询数据
func Select(conditions string, sqlDB *sql.DB) (models []Employee, err error) {
sql := `SELECT employee.id,
name,
address,
title,
salary,
leader_id,
subordinate_id,
valid
FROM employee`
if conditions != "" {
sql += " WHERE " + conditions
}
rows, errQuerySql := sqlDB.Query(sql)
if errQuerySql != nil {
err = errQuerySql
return
}
defer rows.Close()
for rows.Next() {
employee := Employee{}
scanErr := rows.Scan(
&employee.Id,
&employee.Name,
&employee.Address,
pq.Array(&employee.Title),
&employee.Salary,
&employee.LeaderId,
pq.Array(&employee.SubordinateId),
&employee.Valid,
)
if scanErr != nil {
err = errQuerySql
return
}
models = append(models, employee)
}
return
}
问题
对于数组类型的Title和SubordinateId,我们使用pq.Array进行转换。
这种写法算是硬编码。因为如果对查询字段进行新增或者删除,都要对Scan方法的调用进行调整。比如我们不需要Address,则需要同时调整SQL语句和Scan方法。
反射+泛型写法
结构体定义
type Model interface {
GetTableName() string
}
type Employee struct {
Id int64 `column:"id"`
Name string `column:"name"`
Address sql.NullString `column:"address"`
Title []string `column:"title"`
Salary float64 `column:"salary"`
LeaderId sql.NullInt64 `column:"leader_id"`
SubordinateId []int64 `column:"subordinate_id"`
Valid bool `column:"valid"`
}
func (d Employee) GetTableName() string {
return "employee"
}
接口
定义一个接口Model。所有数据库模型结构体都实现它的接口方法,返回表名。后续我们通过返回Model数组,将不同模型结构体数据在同一个函数中返回出来。
Tag
因为数据库字段名和模型结构体结构体名不一定一样,所以我们需要另外一个位置来做衔接。比如模型结构体Employee的Id首字母要大写,以表示它可以直接访问。而在数据库中我们要求字段都是小写命名,即id。
实现逻辑
泛型设计
func Select[T Model](conditions string, ignoreColumns []string, sqlDB *sql.DB) (models []Model, err error) {
调用Select方法时,可以指明T是哪个具体的模型结构体。同时也限制了模型结构体必须实现Model接口的方法。
返回值models是Model数组。这样我们就可以使用一种写法,返回各种模型结构体的查询结果了。
ignoreColumns 是忽略的字段名字。这样就可以动态调整查询语句和结果了。
实例化模型结构体
model := new(T)
后面泛型会使用这个实例
获取表名
modelValue := reflect.ValueOf(model)
getTableNameOut := modelValue.MethodByName("GetTableName").Call([]reflect.Value{})
if len(getTableNameOut) != 1 {
err = fmt.Errorf(fmt.Sprintf("%s GetTableName Return %d values, need only 1", modelValue.Type().Name(), len(getTableNameOut)))
return
}
tableName := getTableNameOut[0].String()
这个地方使用了反射的方法进行了GetTableName方法的调用。
过滤字段
modelType := reflect.TypeOf(model)
var columnNamesInSql []string
var selectedColumnsIndex []int
for i := 0; i < modelType.Elem().NumField(); i++ {
field := modelType.Elem().Field(i)
columnName := field.Tag.Get("column")
if columnName == "" {
continue
}
if In(columnName, ignoreColumns) {
continue
}
columnNamesInSql = append(columnNamesInSql, columnName)
selectedColumnsIndex = append(selectedColumnsIndex, i)
}
columnsCount := len(selectedColumnsIndex)
if columnsCount == 0 {
err = fmt.Errorf(fmt.Sprintf("%s Selected columns is 0", tableName))
return
}
columnNamesInSql用来存储所有通过过滤的字段名;selectedColumnsIndex用来保存通过过滤的字段索引号。
组装SQL语句
columnsInSql := strings.Join(columnNamesInSql, ",")
sql := fmt.Sprintf("SELECT %s FROM %s", columnsInSql, tableName)
if len(conditions) != 0 {
sql = fmt.Sprintf("%s WHERE %s", sql, conditions)
}
查询
rows, errQuerySql := sqlDB.Query(sql)
if errQuerySql != nil {
err = errQuerySql
return
}
defer rows.Close()
遍历读取结果
for rows.Next() {
实例化模型结构体
singleRow := new(T)
后面我们需要用这个实例去接收数据。
组装Scan方法的参数
paramsIn := make([]reflect.Value, columnsCount)
for i := 0; i < len(selectedColumnsIndex); i++ {
selectedColumnIndex := selectedColumnsIndex[i]
elem := modelType.Elem().Field(selectedColumnIndex)
if !refValue.Field(selectedColumnIndex).CanAddr() {
err = fmt.Errorf(fmt.Sprintf("%s Field %s can't addr", modelValue.Type().Name(), elem.Name))
return
}
columnType := elem.Type.Name()
if columnType == "" {
kindString := elem.Type.Kind().String()
if strings.Compare("slice", kindString) == 0 {
param := reflect.NewAt(refValue.Field(selectedColumnIndex).Type(), unsafe.Pointer(refValue.Field(selectedColumnIndex).UnsafeAddr()))
paramsIn[i] = reflect.ValueOf(pq.Array(param.Interface()))
} else {
err = fmt.Errorf(fmt.Sprintf("%s Field %s Type is unkown:%s", modelValue.Type().Name(), elem.Name, kindString))
return
}
} else {
paramsIn[i] = reflect.NewAt(refValue.Field(selectedColumnIndex).Type(), unsafe.Pointer(refValue.Field(selectedColumnIndex).UnsafeAddr()))
}
}
这儿有一个非常重要的函数:reflect.NewAt。因为Scan函数的参数需要对结构体成员进行取址,而refValue.Field(selectedColumnIndex)的类型是reflect.Value,对它取址并不是对模型结构体成员取址,所以要使用它的裸指针。而裸指针的类型是uintptr,就需要使用reflect.NewAt函数对其进行转换。
调用Scan方法并保存结果
errScan := reflect.ValueOf(rows).MethodByName("Scan").Call(paramsIn)
if errScan[0].Interface() != nil {
err = errScan[0].Interface().(error)
return
}
models = append(models, *singleRow)
}
return
}
完整代码
type Model interface {
GetTableName() string
}
type Employee struct {
Id int64 `column:"id"`
Name string `column:"name"`
Address sql.NullString `column:"address"`
Title []string `column:"title"`
Salary float64 `column:"salary"`
LeaderId sql.NullInt64 `column:"leader_id"`
SubordinateId []int64 `column:"subordinate_id"`
Valid bool `column:"valid"`
}
func (d Employee) GetTableName() string {
return "employee"
}
func In[T string | int | float64 | float32 | int64 | int32, A []T](target T, arr A) bool {
for _, v := range arr {
if target == v {
return true
}
}
return false
}
func Select[T Model](conditions string, ignoreColumns []string, sqlDB *sql.DB) (models []Model, err error) {
model := new(T)
modelValue := reflect.ValueOf(model)
getTableNameOut := modelValue.MethodByName("GetTableName").Call([]reflect.Value{})
if len(getTableNameOut) != 1 {
err = fmt.Errorf(fmt.Sprintf("%s GetTableName Return %d values, need only 1", modelValue.Type().Name(), len(getTableNameOut)))
return
}
tableName := getTableNameOut[0].String()
modelType := reflect.TypeOf(model)
var columnNamesInSql []string
var selectedColumnsIndex []int
for i := 0; i < modelType.Elem().NumField(); i++ {
field := modelType.Elem().Field(i)
columnName := field.Tag.Get("column")
if columnName == "" {
continue
}
if In(columnName, ignoreColumns) {
continue
}
columnNamesInSql = append(columnNamesInSql, columnName)
selectedColumnsIndex = append(selectedColumnsIndex, i)
}
columnsCount := len(selectedColumnsIndex)
if columnsCount == 0 {
err = fmt.Errorf(fmt.Sprintf("%s Selected columns is 0", tableName))
return
}
columnsInSql := strings.Join(columnNamesInSql, ",")
sql := fmt.Sprintf("SELECT %s FROM %s", columnsInSql, tableName)
if len(conditions) != 0 {
sql = fmt.Sprintf("%s WHERE %s", sql, conditions)
}
rows, errQuerySql := sqlDB.Query(sql)
if errQuerySql != nil {
err = errQuerySql
return
}
defer rows.Close()
for rows.Next() {
singleRow := new(T)
refValue := reflect.ValueOf(singleRow).Elem()
paramsIn := make([]reflect.Value, columnsCount)
for i := 0; i < len(selectedColumnsIndex); i++ {
selectedColumnIndex := selectedColumnsIndex[i]
elem := modelType.Elem().Field(selectedColumnIndex)
if !refValue.Field(selectedColumnIndex).CanAddr() {
err = fmt.Errorf(fmt.Sprintf("%s Field %s can't addr", modelValue.Type().Name(), elem.Name))
return
}
columnType := elem.Type.Name()
if columnType == "" {
kindString := elem.Type.Kind().String()
if strings.Compare("slice", kindString) == 0 {
param := reflect.NewAt(refValue.Field(selectedColumnIndex).Type(), unsafe.Pointer(refValue.Field(selectedColumnIndex).UnsafeAddr()))
paramsIn[i] = reflect.ValueOf(pq.Array(param.Interface()))
} else {
err = fmt.Errorf(fmt.Sprintf("%s Field %s Type is unkown:%s", modelValue.Type().Name(), elem.Name, kindString))
return
}
} else {
paramsIn[i] = reflect.NewAt(refValue.Field(selectedColumnIndex).Type(), unsafe.Pointer(refValue.Field(selectedColumnIndex).UnsafeAddr()))
}
}
errScan := reflect.ValueOf(rows).MethodByName("Scan").Call(paramsIn)
if errScan[0].Interface() != nil {
err = errScan[0].Interface().(error)
return
}
models = append(models, *singleRow)
}
return
}
小结
泛型+反射的方案虽然复杂,但是后续其他表的查询则会变得非常简单。我们只要新增表对应的模板结构体,实现Model接口的方法。就不用**“硬编码”**般去写查询语句了。