前言
由于工作原因使用到了 Kafka,而现有的代码并不能满足性能需求,所以需要开发高效读写 Kafka 的工具,本文是一个 Python Kafka Client 的性能测试记录,通过本次测试,可以知道选用什么第三方库的性能最高,选用什么编程模型开发出来的工具效率最高。
第三方库性能测试
1.第三方库
此次测试的是三个主要的 Python Kafka Client:pykafka、kafka-python 和 confluent-kafka,具体介绍见官网:
- pykafka:pykafka · PyPI
- kafka-python:kafka-python · PyPI
- confluent_kafka:confluent-kafka · PyPI
测试环境
此次测试使用的 Python 版本是2.7,第三方库的版本为:
- pykafka:2.8.0
- kafka-python:2.0.2
- confluent-kafka:1.5.0
使用的数据总量有50万,每条数据大小为2KB,总共为966MB。
测试过程
(1)Kafka Producer 测试
分别使用 pykafka、kafka-python 和 confluent-kafka 实例化一个 Kafka 的 Producer 对象,然后调用相应的 produce 方法将数据推送给 Kafka,数据总条数为50万,比较三个库所耗费的时间,并计算每秒钟可以推送的数据条数和大小,比较得出性能最优的。
代码示例(以 pykafka 为例):
import sys
from datetime import datetime
from pykafka import KafkaClient
class KafkaProducerTool():
def __init__(self, broker, topic):
client = KafkaClient(hosts=broker)
self.topic = client.topics[topic]
self.producer = self.topic.get_producer()
def send_msg(self, msg):
self.producer.produce(msg)
if __name__ == '__main__':
producer = KafkaProducerTool(broker, topic)
print(datetime.now())
for line in sys.stdin:
producer.send_msg(line.strip())
producer.producer.stop()
print(datetime.now())(2)Kafka Consumer 测试
分别使用 pykafka、kafka-python 和 confluent-kafka 实例化一个 Kafka 的 Consumer 对象,然后调用相应的 consume 方法从 Kafka 中消费数据,要消费下来的数据总条数为50万,比较三个库所耗费的时间,并计算每秒钟可以消费的数据条数和大小,比较得出性能最优的。
代码示例(以 pykafka 为例):
from datetime import datetime
from pykafka import KafkaClient
class KafkaConsumerTool():
def __init__(self, broker, topic):
client = KafkaClient(hosts=broker)
self.topic = client.topics[topic]
self.consumer = self.topic.get_simple_consumer()
def receive_msg(self):
count = 0
print(datetime.now())
while True:
msg = self.consumer.consume()
if msg:
count += 1
if count == 500000:
print(datetime.now())
return
if __name__ == '__main__':
consumer = KafkaConsumerTool(broker, topic)
consumer.receive_msg()
consumer.consumer.stop()测试结果
- Kafka Producer 测试结果:
| 总耗时/秒 | 每秒数据量/MB | 每秒数据条数 | |
| confluent_kafka | 35 | 27.90 | 14285.71 |
| pykafka | 50 | 19.53 | 10000 |
| kafka-python | 532 | 1.83 | 939.85 |
- Kafka Consumer 测试结果:
| 总耗时/秒 | 每秒数据量/MB | 每秒数据条数 | |
| confluent_kafka | 39 | 25.04 | 12820.51 |
| kafka-python | 52 | 18.78 | 9615.38 |
| pykafka | 335 | 2.92 | 1492.54 |
测试结论
经过测试,在此次测试的三个库中,生产消息的效率排名是:confluent-kafka > pykafka > kafka-python,消费消息的效率排名是:confluent-kafka > kafka-python > pykafka,由此可见 confluent-kafka 的性能是其中最优的,因而选用这个库进行后续开发。
多线程模型性能测试
编程模型
经过前面的测试已经知道 confluent-kafka 这个库的性能是很优秀的了,但如果还需要更高的效率,应该怎么办呢?当单线程(或者单进程)不能满足需求时,我们很容易想到使用多线程(或者多进程)来增加并发提高效率,考虑到线程的资源消耗比进程少,所以打算选用多线程来进行开发。那么多线程消费 Kafka 有什么实现方式呢?我想到的有两种:
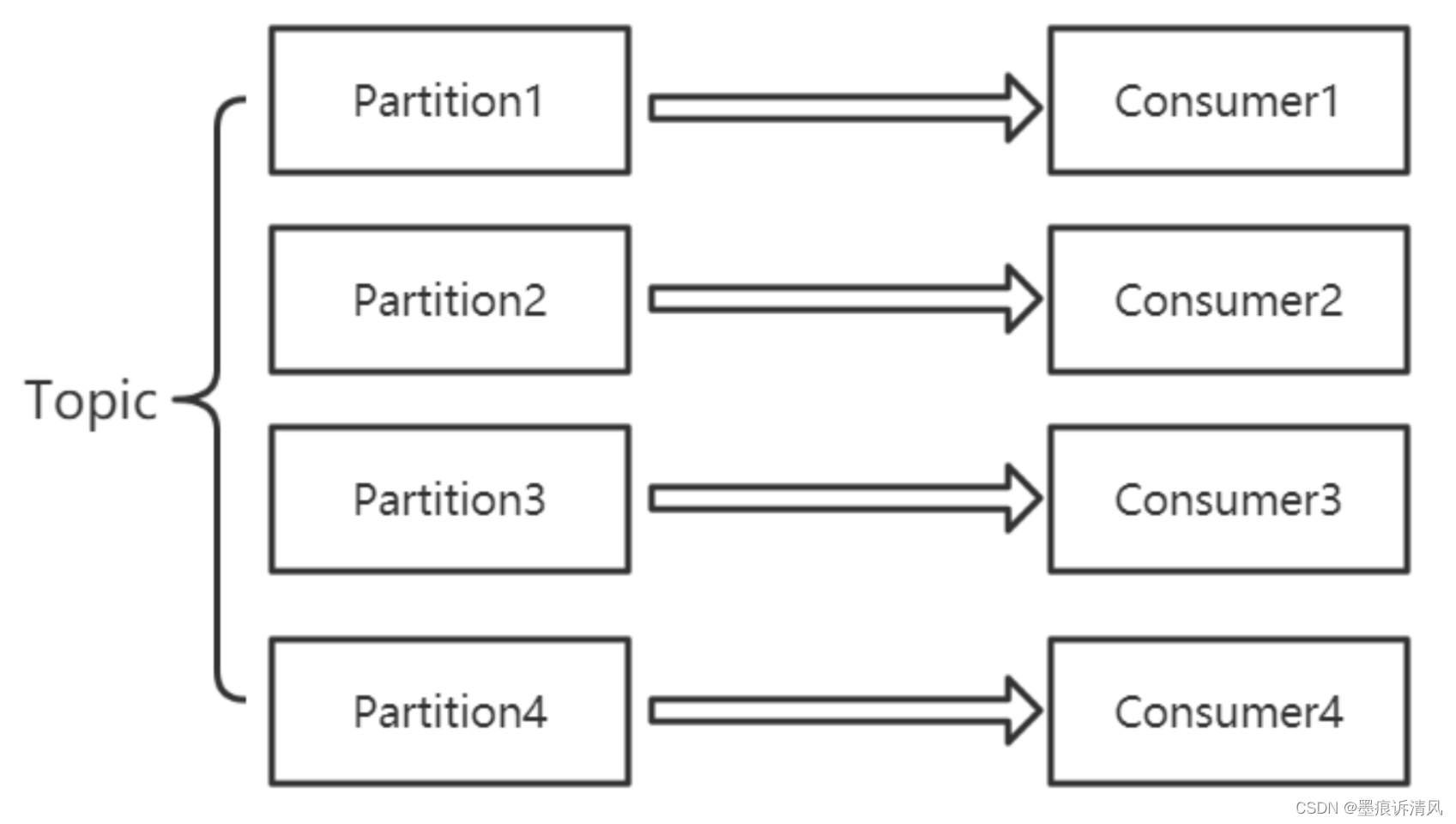
1. 一个线程实现一个 Kafka Consumer,最多可以有 n 个线程同时消费 Topic(其中 n 是该 Topic 下的分区数量);
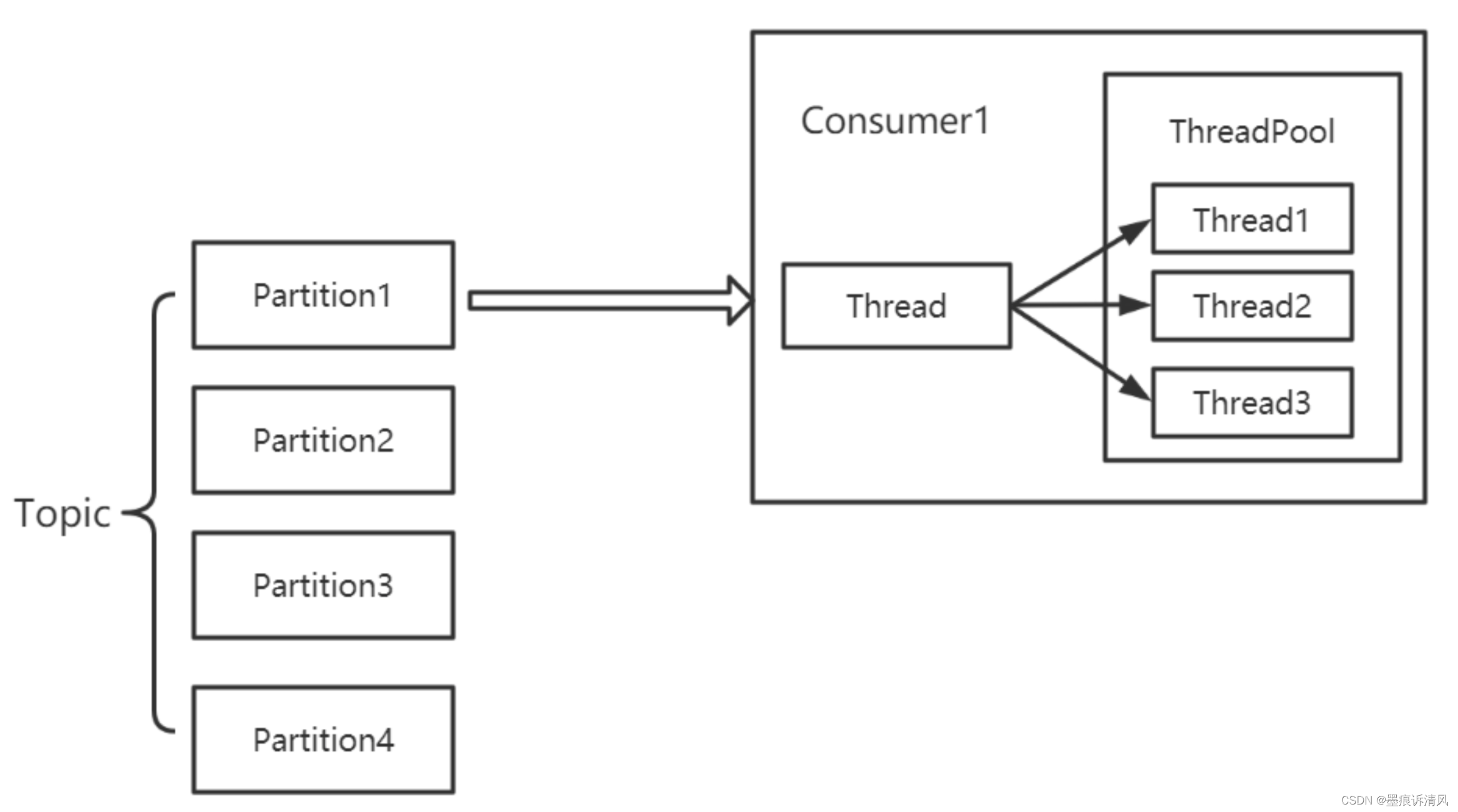
2. 多个线程共用一个 Kafka Consumer,此时也可以实例化多个 Consumer 同时消费。
对比这两种多线程模型:
- 模型1实现方便,可以保证每个分区有序消费,但 Partition 数量会限制消费能力;
- 模型2并发度高,可扩展能力强,消费能力不受 Partition 限制。
测试过程
(1)多线程模型1
测试代码:
import time
from threading import Thread
from datetime import datetime
from confluent_kafka import Consumer
class ChildThread(Thread):
def __init__(self, name, broker, topic):
Thread.__init__(self, name=name)
self.con = KafkaConsumerTool(broker, topic)
def run(self):
self.con.receive_msg()
class KafkaConsumerTool:
def __init__(self, broker, topic):
config = {
'bootstrap.servers': broker,
'session.timeout.ms': 30000,
'auto.offset.reset': 'earliest',
'api.version.request': False,
'broker.version.fallback': '2.6.0',
'group.id': 'test'
}
self.consumer = Consumer(config)
self.topic = topic
def receive_msg(self):
self.consumer.subscribe([self.topic])
print(datetime.now())
while True:
msg = self.consumer.poll(timeout=30.0)
print(msg)
if __name__ == '__main__':
thread_num = 10
threads = [ChildThread("thread_" + str(i + 1), broker, topic) for i in ge(thread_num)]
for i in range(thread_num):
threads[i].setDaemon(True)
for i in range(thread_num):
threads[i].start()因为我使用的 Topic 共有8个分区,所以我分别测试了线程数在5个、8个和10个时消费50万数据所需要的时间,并计算每秒可消费的数据条数。
(2)多线程模型2
测试代码:
import time
from datetime import datetime
from confluent_kafka import Consumer
from threadpool import ThreadPool, makeRequests
class KafkaConsumerTool:
def __init__(self, broker, topic):
config = {
'bootstrap.servers': broker,
'session.timeout.ms': 30000,
'auto.offset.reset': 'earliest',
'api.version.request': False,
'broker.version.fallback': '2.6.0',
'group.id': 'mini-spider'
}
self.consumer = Consumer(config)
self.topic = topic
def receive_msg(self, x):
self.consumer.subscribe([self.topic])
print(datetime.now())
while True:
msg = self.consumer.poll(timeout=30.0)
print(msg)
if __name__ == '__main__':
thread_num = 10
consumer = KafkaConsumerTool(broker, topic)
pool = ThreadPool(thread_num)
for r in makeRequests(consumer.receive_msg, [i for i in range(thread_num)]):
pool.putRequest(r)
pool.wait()主要使用 threadpool 这个第三方库来实现线程池,此处当然也可以使用其他库来实现,这里我分别测试了线程数量在5个和10个时消费50万数据所需要的时间,并计算每秒可消费的数据条数。
测试结果
- 多线程模型1
| 总数据量/万 | 线程数量 | 总耗时/秒 | 每秒数据条数 |
| 50 | 5 | 27 | 18518.51 |
| 50 | 8 | 24 | 20833.33 |
| 50 | 10 | 26 | 19230.76 |
- 多线程模型2
| 总数据量/万 | 线程数量 | 总耗时/秒 | 每秒数据条数 |
| 50 | 5 | 17 | 29411.76 |
| 50 | 10 | 13 | 38461.53 |
测试结论
使用多线程可以有效提高 Kafka 的 Consumer 消费数据的效率,而选用线程池共用一个 KafkaConsumer 的消费方式的消费效率更高。